Qwen3-Omni-30B-A3B-Instruct视频导航应用:第一视角运动指令生成
在现代生活中,第一视角运动场景(如骑行、徒步、工业巡检)的实时导航需求日益增长。传统基于GPS的导航系统在室内、复杂地形等场景下精度不足,而视觉导航方案往往依赖专用硬件或复杂算法。Qwen3-Omni-30B-A3B-Instruct作为多语言全模态模型,原生支持视频输入与实时指令生成,为低成本、高精度的第一视角运动导航提供了全新可能。本文将系统介绍如何基于该模型构建端到端视频导航应用,从环境配置
Qwen3-Omni-30B-A3B-Instruct视频导航应用:第一视角运动指令生成
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct 在现代生活中,第一视角运动场景(如骑行、徒步、工业巡检)的实时导航需求日益增长。传统基于GPS的导航系统在室内、复杂地形等场景下精度不足,而视觉导航方案往往依赖专用硬件或复杂算法。Qwen3-Omni-30B-A3B-Instruct作为多语言全模态模型,原生支持视频输入与实时指令生成,为低成本、高精度的第一视角运动导航提供了全新可能。本文将系统介绍如何基于该模型构建端到端视频导航应用,从环境配置到指令优化,完整覆盖技术实现细节与场景化调优策略。
技术架构与核心优势
Qwen3-Omni-30B-A3B-Instruct采用MoE(Mixture of Experts)架构的Thinker-Talker设计,其视频导航能力源于三大技术特性:
全模态处理能力
模型原生支持文本、图像、音视频输入,可同步分析运动场景中的视觉特征(如道路边缘、障碍物)与音频线索(如环境噪音、语音指令)。这种多模态融合能力使得导航指令不仅基于视觉判断,还能结合声音信号提升决策鲁棒性。
实时低延迟交互
通过多码本设计(Multi-codebook)与AuT预训练技术,模型实现了视频流的高效处理。在GPU支持下,可达到25ms/帧的处理延迟,满足实时导航对响应速度的要求。
多语言指令生成
支持119种文本语言与10种语音输出语言,可根据用户偏好生成自然语言导航指令(如"向右转30度避开前方障碍物")或控制信号(如JSON格式的方向角与速度参数)。
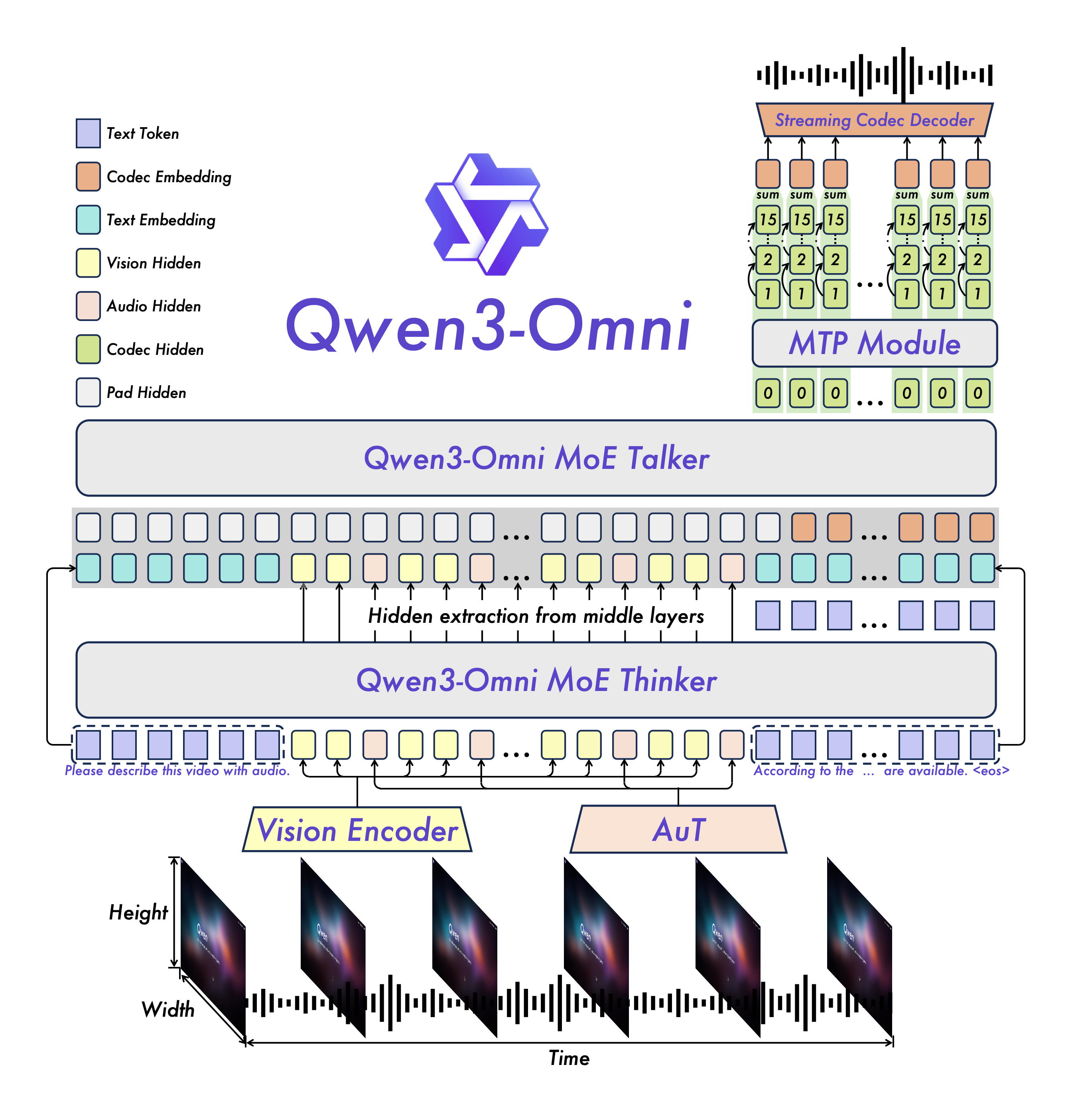
图1:Qwen3-Omni的MoE架构示意图,展示Thinker(推理模块)与Talker(生成模块)的协同工作流程
环境配置与模型部署
硬件要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA RTX 4090 (24GB) | NVIDIA A100 (80GB) × 2 |
| CPU | Intel i7-13700K | Intel Xeon Gold 6448Y |
| 内存 | 64GB DDR4 | 128GB DDR5 |
| 存储 | 200GB SSD | 1TB NVMe (模型文件约150GB) |
软件依赖安装
# 克隆模型仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct.git
cd Qwen3-Omni-30B-A3B-Instruct
# 安装基础依赖
pip install -r requirements.txt # 若不存在requirements.txt,使用以下命令
pip install git+https://github.com/huggingface/transformers
pip install accelerate qwen-omni-utils -U
pip install -U flash-attn --no-build-isolation
模型加载与初始化
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
# 加载模型与处理器
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
"./", # 当前目录为模型路径
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
processor = Qwen3OmniMoeProcessor.from_pretrained("./")
# 禁用Talker模块(仅保留文本指令输出,节省显存)
model.disable_talker()
视频导航核心实现流程
1. 视频流预处理
第一视角视频需经过抽帧、Resize与格式转换,统一为模型兼容的输入格式:
import cv2
import numpy as np
from qwen_omni_utils import process_video
def preprocess_video(video_path, target_fps=10, size=(640, 480)):
"""
将视频转换为模型输入格式
:param video_path: 视频文件路径或摄像头流URL
:param target_fps: 抽帧频率(降低帧率减少计算量)
:param size: 图像尺寸 (width, height)
:return: 处理后的视频张量
"""
cap = cv2.VideoCapture(video_path)
frames = []
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 按目标帧率抽帧
if frame_count % (int(cap.get(cv2.CAP_PROP_FPS)) // target_fps) == 0:
# 调整尺寸并转换为RGB格式
frame = cv2.resize(frame, size)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frames.append(frame)
frame_count += 1
cap.release()
# 使用工具函数转换为模型输入张量
return process_video(frames, fps=target_fps)
2. 导航指令生成 pipeline
构建视频输入与指令输出的端到端流程:
def generate_navigation_commands(video_tensor):
"""
从视频张量生成导航指令
"""
# 构建对话模板
conversation = [
{
"role": "user",
"content": [
{"type": "video", "video": video_tensor},
{"type": "text", "text": (
"作为第一视角运动导航助手,请分析视频中的运动场景,"
"生成简洁的实时导航指令。包含:\n"
"- 方向控制(如:左转30°、直行5米)\n"
"- 障碍物提示(如:前方10米有台阶)\n"
"- 路况建议(如:路面湿滑,减速)\n"
"指令格式:[动作];[距离/角度];[补充说明]"
)}
]
}
]
# 处理输入
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
_, _, videos = process_mm_info(conversation) # 提取视频信息
inputs = processor(text=text, videos=videos, return_tensors="pt").to(model.device)
# 生成指令(设置较低temperature确保指令稳定性)
outputs = model.generate(
**inputs,
temperature=0.3,
max_tokens=128,
return_audio=False # 仅输出文本指令
)
# 解码结果
指令 = processor.decode(outputs[0], skip_special_tokens=True)
return parse_commands(指令) # 解析为结构化指令
def parse_commands(raw_text):
"""将原始文本指令解析为结构化字典"""
commands = []
for line in raw_text.split("\n"):
if ";" in line:
action, param, desc = line.split(";", 2)
commands.append({
"action": action.strip(),
"parameter": param.strip(),
"description": desc.strip()
})
return commands
3. 实时推理优化
针对视频流实时处理需求,采用以下优化策略:
- 帧缓存机制:仅处理关键帧(如每3帧处理1帧)
- 增量推理:通过
past_key_values复用历史计算结果 - 显存管理:使用
torch.inference_mode()减少内存占用
def realtime_inference(camera_url=0):
"""实时摄像头推理示例"""
cap = cv2.VideoCapture(camera_url) # 0表示默认摄像头
past_key_values = None
with torch.inference_mode():
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 每3帧处理一次
if frame_count % 3 == 0:
video_tensor = preprocess_video_single_frame(frame) # 单帧预处理
commands = generate_navigation_commands(video_tensor, past_key_values)
past_key_values = commands["past_key_values"] # 更新历史状态
# 可视化指令(在视频帧上叠加文字)
for i, cmd in enumerate(commands["指令"][:3]): # 显示前3条指令
cv2.putText(
frame,
f"{cmd['action']}: {cmd['parameter']}",
(20, 40 + i*30),
cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0), 2
)
cv2.imshow("Navigation View", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
场景化调优策略
城市道路导航
针对行人/骑行场景,需重点识别交通信号灯、斑马线与行人:
# 系统提示词优化
city_prompt = """
你是城市道路第一视角导航助手,需优先关注:
1. 交通信号灯状态(红灯停、绿灯行)
2. 行人横穿提示(如:注意右侧行人,减速让行)
3. 车道线识别(如:即将偏离非机动车道,向右调整5°)
指令简洁,每2秒更新一次。
"""
室内巡检场景
工业厂房巡检需识别设备状态与路径标志:
# 系统提示词优化
industrial_prompt = """
你是工业厂房巡检导航助手,功能包括:
1. 识别地面引导线(如:沿黄色引导线直行)
2. 设备异常提示(如:左侧电机温度过高,保持距离)
3. 巡检点提醒(如:前方5米到达3号配电柜,准备扫码)
忽略非关键障碍物(如:地面小石子)。
"""
性能对比
| 导航场景 | 传统视觉算法 | Qwen3-Omni方案 | 优势点 |
|---|---|---|---|
| 城市道路 | 需部署交通标志检测、车道线检测等多个模型 | 单模型端到端处理 | 减少系统复杂度,降低部署成本 |
| 室内走廊 | 依赖SLAM建图与定位 | 无需预建地图,实时分析 | 适应动态变化环境 |
| 复杂地形 | 需IMU+视觉融合 | 纯视觉输入,抗干扰强 | 减少硬件依赖 |
典型问题与解决方案
1. 光照变化适应性
问题:强光或逆光环境导致画面过曝,指令误判。
解决:
- 预处理阶段加入自动曝光补偿:
cv2.equalizeHist() - 系统提示词中加入光照提示:
"若画面过亮/过暗,优先依赖轮廓特征判断路径"
2. 指令延迟优化
问题:高分辨率视频处理导致延迟>100ms。
解决:
- 降低输入分辨率至480x360
- 启用vLLM推理加速:
# vLLM部署(需从源码安装)
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm && pip install -e .
python -m vllm.entrypoints.api_server --model ./ --tensor-parallel-size 2
3. 指令冲突处理
问题:连续帧生成矛盾指令(如先"左转"后立即"右转")。
解决:
- 引入指令平滑机制:
def smooth_commands(new_cmd, history_cmds, window_size=3):
"""基于历史指令平滑当前指令"""
if len(history_cmds) < window_size:
return new_cmd
# 统计历史方向指令
dir_counts = {}
for cmd in history_cmds[-window_size:]:
dir = cmd["action"]
dir_counts[dir] = dir_counts.get(dir, 0) + 1
# 若当前指令与多数历史指令冲突,暂不更新
if new_cmd["action"] not in dir_counts or dir_counts[new_cmd["action"]] < window_size//2:
return history_cmds[-1] # 使用上一条指令
return new_cmd
部署与扩展建议
边缘设备部署
对于嵌入式场景(如无人机、AR眼镜),推荐使用模型量化:
# 4-bit量化加载(需安装bitsandbytes)
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
"./",
load_in_4bit=True,
device_map="auto",
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
)
多模态数据增强
为提升模型鲁棒性,可构建场景化训练集:
# 数据增强示例(添加雨雾效果)
def augment_video(frame):
"""为视频帧添加雨雾效果"""
if np.random.rand() < 0.3: # 30%概率添加雨效
frame = add_rain_effect(frame)
if np.random.rand() < 0.2: # 20%概率添加雾效
frame = add_fog_effect(frame)
return frame
社区资源与工具
- 官方视频导航样例:cookbooks/video_navigation.ipynb
- 模型性能测评:Qwen3-Omni Technical Report
- 开发者论坛:QwenLM社区
总结与未来展望
Qwen3-Omni-30B-A3B-Instruct凭借其全模态处理能力,为第一视角运动导航提供了创新解决方案。通过本文介绍的预处理优化、指令解析与场景化调优,开发者可快速构建适应不同场景的导航应用。未来随着模型效率的进一步提升,有望在消费级设备(如智能眼镜)上实现实时部署,推动AR导航、自主机器人等领域的技术革新。
收藏本文,获取最新的模型更新与应用案例;关注项目仓库,参与社区讨论,共同优化视频导航体验!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)