Batch Normalization vs Layer Normalization:深度解析与对比
BatchNormalization(BN)和LayerNormalization(LN)都是用于标准化神经网络激活值的技术,但二者在归一化维度和适用场景上存在显著差异。BN沿着批处理维度进行标准化,适合图像任务(如CNN),但对batch size敏感;LN则在特征维度进行归一化,适用于NLP和Transformer等序列建模任务,且不受batch size影响。主要区别包括:BN训练/测试行为
🔍 Batch Normalization(BN) 和 Layer Normalization(LN) 都是用于标准化神经网络中间激活值的技术,其核心目的是:
-
缓解“内部协变量偏移”(Internal Covariate Shift)
-
加快训练速度
-
提高模型稳定性
-
有助于更深网络的训练
尽管目的相似,它们的归一化维度不同、使用场景不同,也表现出不同的效果。
🧠 一、核心思想对比
| 特性 | Batch Normalization (BN) | Layer Normalization (LN) |
|---|---|---|
| 归一化维度 | 在 Batch 维度(N)上做归一化 | 在 特征维度(C 或 embedding)上做归一化 |
| 应用位置 | 常用于 CNN、全连接网络 | 常用于 Transformer、RNN、NLP任务等 |
| 对 batch size 敏感 | 是 | 否 |
| 训练/推理差异 | 有(推理时需使用 moving average) | 无(训练和推理使用相同公式) |
🧪 二、标准化公式对比
1. BatchNorm 标准化过程
对于一个 mini-batch 中的特征 x∈RN×C×H×Wx \in \mathbb{R}^{N \times C \times H \times W}x∈RN×C×H×W,BN 会在 每一个特征通道(C)上做归一化,统计的是 batch 中该通道的所有样本、所有空间位置。
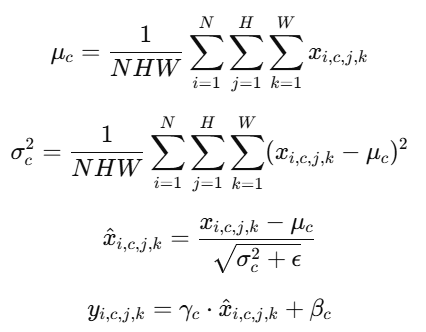
-
γc,βc是可学习的缩放和平移参数
-
依赖 batch 中多个样本的数据 → 对 batch size 敏感
2. LayerNorm 标准化过程
对每个样本单独计算,在通道维度(特征维)做归一化。例如在 Transformer 中,对每个位置的 token 向量进行归一化。
对于输入向量 x∈R^d:
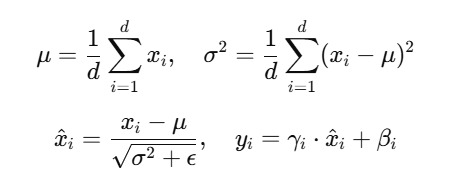
-
每个样本单独归一化
-
与 batch size 无关,适合序列任务和小 batch 场景
🧭 三、主要区别总结
| 对比维度 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化轴 | N(样本)方向 + 空间(HW)方向 | 特征(channel 或 embedding)方向 |
| 对 batch size 敏感 | 是(小 batch size 会影响稳定性) | 否(可用于 batch size=1 的情况) |
| 训练/测试行为差异 | 有(测试阶段使用移动平均) | 无(训练和测试一致) |
| 应用场景 | 图像模型(CNN)、结构简单的 MLP | NLP、Transformer、RNN、Transformer-based 模型 |
| 计算开销 | 较小 | 稍大(但不明显) |
🧪 四、实际使用建议
| 场景 | 建议使用 |
|---|---|
| 图像分类、卷积网络(如 ResNet) | ✅ BatchNorm |
| NLP、Transformer、语言模型 | ✅ LayerNorm |
| RNN、LSTM 等序列模型 | ✅ LayerNorm(或 LayerNorm + WeightNorm) |
| 小 batch size(例如 batch=1) | ❌ BatchNorm,✅ LayerNorm |
| 推理阶段不希望行为变化 | ✅ LayerNorm(BN 会引入额外 moving average 机制) |
📌 五、可视化理解(举个例子)
假设你有一个输入矩阵:
样本 1: [3.0, 1.0, 2.0]
样本 2: [4.0, 5.0, 6.0]
-
BatchNorm 是在所有样本的同一维度上标准化:即第1维是 [3,4],第2维是 [1,5],第3维是 [2,6]
-
LayerNorm 是对每个样本自身做标准化:即样本1 的 [3,1,2] 和样本2 的 [4,5,6] 各自计算均值方差
🧠 六、补充:其他相关 Normalization
| 名称 | 归一化维度 | 特点 |
|---|---|---|
| BatchNorm | 跨 batch(按通道) | 图像任务效果好,依赖 batch size |
| LayerNorm | 跨特征 | NLP 常用,不依赖 batch size |
| InstanceNorm | 每个样本的每个通道独立归一化 | 风格迁移中常用 |
| GroupNorm | 把通道分组,每组做 BN | CNN 中适用于小 batch,兼具 BN 和 LN 特性 |
✅ 总结一句话:
BatchNorm 是“跨样本”标准化,适合 图像任务;
LayerNorm 是“跨特征”标准化,适合 序列建模任务(如 NLP、Transformer),并且在小 batch 情况下更加鲁棒。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)