扩散模型与强化学习(7):用DPO改进音频驱动视频生成实践
前言:本文提出了一种创新的人类偏好对齐扩散框架,用于生成音频和骨骼运动驱动的高质量肖像动画。该框架包含两个核心技术:1)针对肖像动画的定向偏好优化,通过构建人类偏好数据集优化生成结果;2)时间运动调制机制,将不同采样率的运动信号有效整合到扩散模型中,保持高频运动细节。实验表明,该方法在唇音同步、表情自然度和运动连贯性方面显著优于现有基线方法,同时提升了人类偏好评价指标。研究还发布了专门构建的肖像动画偏好数据集,为相关研究提供了新基准。
目录
动机
生成高度动态化和逼真的肖像动画,这些动画由音频和骨骼运动驱动,仍然具有挑战性,因为需要精确的唇部同步、自然的面部表情和高保真的身体运动动态。我们提出了一种与人类偏好对齐的扩散框架,通过两个关键创新来解决这些挑战。首先,我们引入了针对以人为中心的动画的定向偏好优化,利用精心策划的人类偏好数据集,将生成的结果与肖像运动视频对齐和表情自然度的感知指标对齐。其次,所提出的时序运动调制通过时序通道重新分配和比例特征扩展,将运动条件重塑为维度对齐的潜在特征,从而解决了时空分辨率不匹配的问题,保持了基于扩散的合成中高频运动细节的保真度。所提出的机制是对现有的基于UNet和DiT的肖像扩散方法的补充,实验表明在唇音同步、表情生动性、身体运动连贯性方面相比基线方法有明显的改进,同时在人类偏好指标上也有显著的提升。
相关工作:人类偏好对齐
人类偏好对齐。将生成模型与人类偏好对齐的研究横跨视觉理解和合成任务。在视频理解中,早期的工作[ 29 ]采用了带有人类反馈的强化学习来减轻幻觉,而随后的工作通过语言模型奖励[ 44 ],AI反馈[ 1 ]和时间背景优化[ 17 ]引入了自监督对齐。在图像生成方面,Diffusion-DPO [ 34 ]改进了DPO,使文本到图像的输出与人类的判断保持一致。视频生成方法进一步扩展了DPO以优化视觉-文本语义( VideoDPO [ 21 ] )。实现在线训练( OnlineVPO [ 42 ] ),并细化运动动力学( Flow-DPO )。虽然这些工作建立了DPO作为偏好感知合成的可扩展范例,但没有解决音频驱动的人像动画的独特挑战。据我们所知,这项工作提出了第一个精心策划的人类偏好数据集和定制的DPO框架,以提高肖像动画领域的对口型准确性和面部自然度。
方法
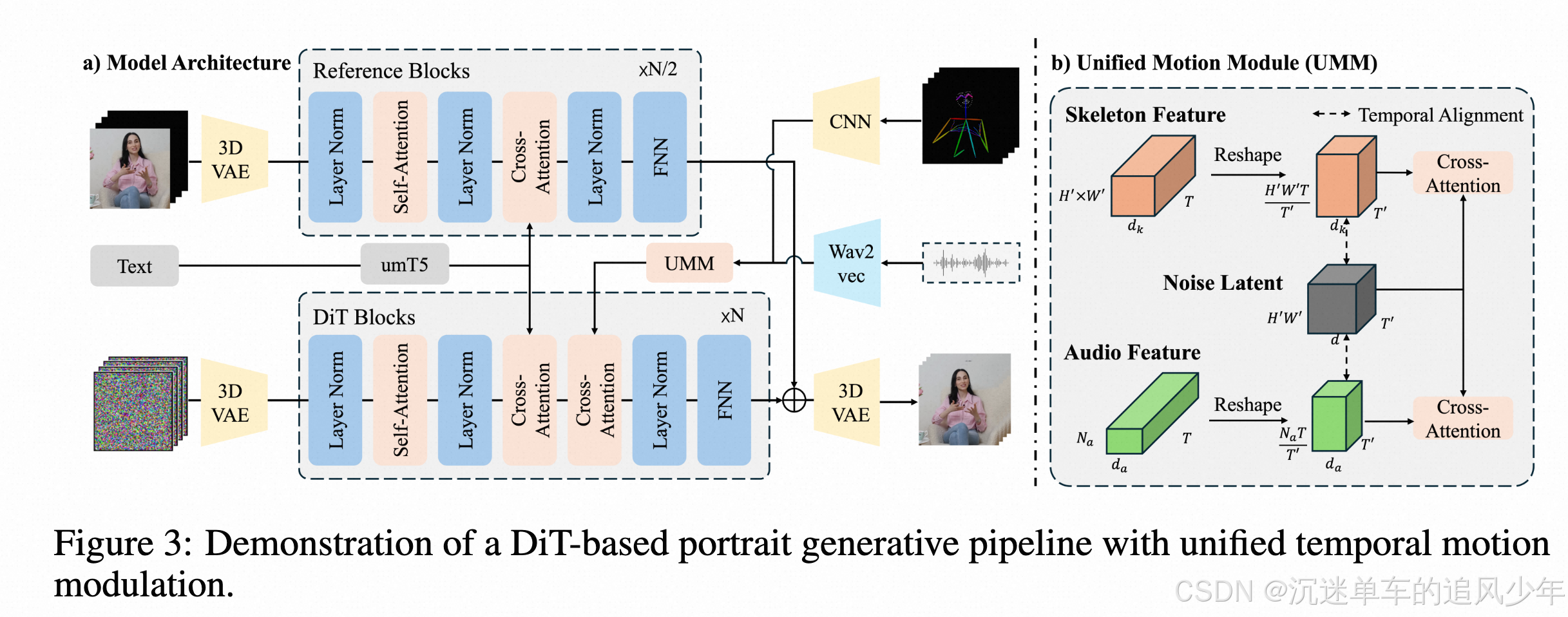
我们介绍了第一个专门为以人为中心的动画而设计的音频驱动的肖像DPO数据集,它沿着两个关键的轴捕捉人类的偏好。( 1 )人像-运动-视频同步的准确性;( 2 )人脸表情和姿态的自然性。通过使用KL约束的奖励函数对比偏好和不偏好样本的轨迹概率,我们的方法优化了生成策略,以最大化轨迹级别的奖励余量,同时规则化了对基本扩散模型去噪动态的偏差。该方法在唇同步精度(在对口型分数中匹配真实数据基准)上取得了可测量的提升,并增强了面部表现力,为偏好对齐的人像动画建立了新的基线。
虽然基于DiT的扩散模型在真实感人像动画中表现出优于UNet架构的潜力- -特别是在跨不同场景和角色身份的泛化、实现自然主义的人物渲染以及将人像与环境上下文无缝集成方面- -但它们对基于VAE的时间降采样特征的依赖引入了一个关键的限制。具体来说,时间下采样运动条件(例如,唇部发音,面部表情和骨骼运动)与潜在视频时间维度对齐的标准做法不可避免地丢弃了对同步快速嘴唇和手势运动至关重要的高频和细粒度运动细节。为了解决这些挑战,我们提出了一种时间运动条件调制机制,统一所有运动条件以匹配视频潜在的时间维度,同时按比例扩展特征维度以保持运动粒度。该机制为将具有不同采样频率的多样化运动信号集成到预训练的扩散转换器中奠定了可扩展的基础,解决了由潜在空间时间压缩引起的保真度下降问题。
所提出的机制在与UNet和DiT架构集成时表现出互补优势。我们的框架,将直接偏好优化与统一偏好优化相结合的时序运动调制,为高保真的人像动画奠定了坚实的基础。综合实验表明,与基线方法相比,我们的方法在唇音同步和表情自然性方面取得了显著的改善,同时在人类偏好度量方面也有显著的提高,同时在复杂的上半身姿势中保持出色的运动连贯性-特别是在涉及快速语音、突变的面部表情和姿态变化以及快速变化的身体动作的挑战性场景中。为了便于在偏好对齐的画像生成中进行可复制的研究,我们将在发布时同时发布代码库和策展偏好数据集。
偏好数据集构建
为了为人像动画中的直接偏好优化奠定坚实的基础,我们制作了一个多模态数据集,该数据集捕获了两个关键维度的人类偏好:( 1 )运动-视频对齐和( 2 )人像保真度。
偏好度量( Preference Metrics )。运动-视频对齐和肖像逼真度是评价合成肖像动画的两个重要指标。运动-视频对齐量化了生成动画与人体运动状态之间的时间一致性,强调与音频输入的唇动同步和与节律节拍同步的身体动作。人像保真度评价合成内容的感知质量,特别强调面部表情和头部姿态相对于语音内容(例如,表达喜悦、愤怒或惊讶等情绪)的语义连贯性,以及渲染输出的整体自然性和真实感。这些指标共同保证了动态肖像生成中的感知准确性和以人为中心的合理性。
直接偏好优化利用成对偏好数据D = { ( x , yw , yl) }将人类偏好对齐建模为策略优化问题,其中yw优先于yl;这里,yw和yl分别表示"赢"和"输"的样本[ 34 ]。为了构建该数据集,我们使用注释器在两个维度上对生成的样本进行评估,并将其与" best-vs-worst "选择策略相结合,以获得最终的偏好数据集。
对于每个输入的音频片段,我们使用五种代表性的方法生成候选视频,这些方法跨越了基于GAN ( SadTalker ),基于UNet的扩散( AniPortrait、EchoMimic - v2)和基于DiT的扩散( FantasyTalking , Hallo3)架构。遵循独立的一代人类注释器在两个关键轴上评估每个视频:运动-视频对齐(唇部/身体同步)和人像保真度(表达自然,渲染质量高),在5点李克特量表上分配分数。
成对偏好数据( yw , yl)是通过基于复合奖励r的" best-vs-worst "策略对样本进行排序得到的。我们将奖励最高的样本定义为yw,奖励最低的样本定义为yl。该策略最大化了yw和yl样本之间的奖励差距,鼓励了在唇部同步性和表情质量等细微方面的明显区别。为保持数据集的可判别性,剔除奖励差异最小的案例。
生成policy 和 有监督的微调扩散模型初始化。
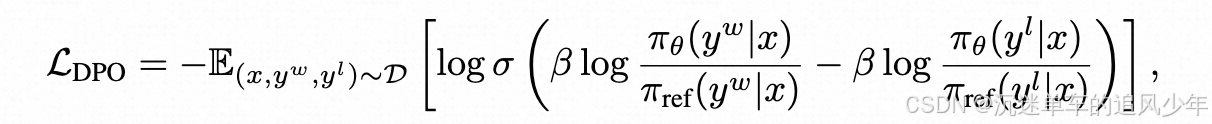
通过利用成对偏好数据集绕过显式奖励建模。
follow matching 的 DPO损失被重写为:
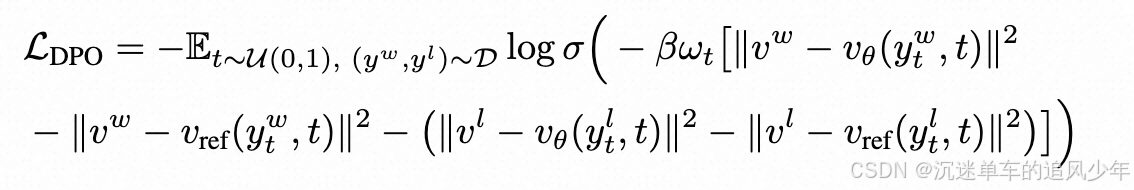
其中ωt为加权函数,vw和vl分别表示由优选样本yw和非优选样本yl得到的速度场。在偏好数据集D = {(x , yw , yl) }和噪声时间步长t上取期望。通过最小化L_DPO,预测的速度场vθ变得更接近vw (与人类偏好一致),并进一步偏离vl,促进了相干运动轨迹,并产生更自然和真实的表达式。
在训练过程中,LDPO的梯度调整去噪方向,在保留参考策略时间动态性的同时,在轨迹空间中偏向高奖励区域。优化可以在不影响预训练扩散模型固有稳定性的前提下,实现偏好感知的生成。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)