【LLM大模型组件】大模型上下文窗口扩展技术
上下文窗口(Context Window)指模型单次前向传播可处理的最大输入序列长度,直接影响长文本理解、多轮对话连贯性与复杂推理能力。简单来说就是,上下文窗口:就是大模型的“短期记忆力”——它能一次性处理多少文本内容。4K tokens:约3页A4纸的内容(传统模型)32K tokens:一篇完整学术论文或中篇小说:整本《三体》或专业技术手册1M+ tokens:你过去一年的所有聊天记录或整套法
文章优先发布在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
不是所有“加长”都叫进步! 为什么扩展上下文这么难?哪些技术真能解决问题?怎么选才不踩坑?
上下文窗口的扩展,终将使大模型从“瞬时反应者”蜕变为“持久思考者”,为通用人工智能奠定时间维度的认知基础。
核心:“轻量微调打基础,架构创新破极限,记忆系统提效率,跨模态压缩开新路。”
一、概念与问题
1.1 什么是上下文窗口?
上下文窗口(Context Window) 指模型单次前向传播可处理的最大输入序列长度,直接影响长文本理解、多轮对话连贯性与复杂推理能力。
简单来说就是,上下文窗口:就是大模型的“短期记忆力”——它能一次性处理多少文本内容。
- 4K tokens:约3页A4纸的内容(传统模型)
- 32K tokens:一篇完整学术论文或中篇小说
- 128K+ tokens:整本《三体》或专业技术手册
- 1M+ tokens:你过去一年的所有聊天记录或整套法律条文
1.2 为什么扩展上下文如此困难?三大核心挑战
| 挑战类型 | 通俗解释 | 技术本质 | 数学表达 | 后果 |
|---|---|---|---|---|
| 位置泛化失效 | 模型在训练时没见过这么长的文本,不知道第100001个词和第100002个词的区别 | 位置编码在训练长度外无法有效表示相对/绝对位置 | RoPE: θm=10000−2i/d\theta_m = 10000^{-2i/d}θm=10000−2i/d,当 m>Ltrainm > L_{\text{train}}m>Ltrain 时高频分量失真 | 模型“迷失”于长序列,注意力分布混乱 |
| 计算复杂度爆炸 | 128K长度需要的内存是4K长度的1024倍!普通GPU直接“爆内存” | 自注意力机制需计算全连接注意力矩阵 | 计算量 ∝n2d\propto n^2 d∝n2d,显存 ∝n2\propto n^2∝n2 | 硬件资源成为瓶颈 |
| 数据-架构错配 | 模型从小看的都是小短文,突然让它读长篇小说,能适应吗? | 预训练语料多为短文本(平均 <2K tokens),缺乏长程依赖监督信号 | 无显式长程依赖监督信号 | 模型未学习跨万级 token 的语义关联 |
上下文扩展的本质是重建模型对“时间”“距离”与“重要性”的感知能力,而非简单延长输入。
二、五大核心技术路线深度解析
2.1 位置编码外推技术(Positional Extrapolation)
核心思想:不改变模型结构,只调整“位置感知”方式
三种主流方法对比:
| 方法 | 核心机制 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 位置插值(PI) | 将新位置索引 m∈[0,Lnew)m \in [0, L_{\text{new}})m∈[0,Lnew) 线性映射至原训练范围 [0,Ltrain)[0, L_{\text{train}})[0,Ltrain): m′=m⋅LtrainLnewm' = \frac{m \cdot L_{\text{train}}}{L_{\text{new}}}m′=Lnewm⋅Ltrain |
无需训练,即插即用 | 高频位置信息被压缩,局部细节建模能力下降 | 快速验证、小规模扩展 |
| NTK-aware RoPE | 动态调整 RoPE 基频 θ\thetaθ: θi′=θi⋅sα,s=LnewLtrain\theta_i' = \theta_i \cdot s^{\alpha}, \quad s = \frac{L_{\text{new}}}{L_{\text{train}}}θi′=θi⋅sα,s=LtrainLnew |
比PI更好保留高频细节 | 需要专业知识调参 | 中等长度扩展(32K-64K) |
| YaRN | PI + 温度缩放 + 轻量微调的“三合一”方案 | 行业首选,128K内效果最佳,短上下文性能退化<1% | 需要少量微调数据 | 90%商用场景 |
YaRN核心技术细节
关键创新点:
- 位置插值:将新位置 mmm 线性映射至训练范围
- 温度缩放:通过调节 softmax 温度 TTT 平滑注意力分布:
Attention(Q,K,V)=softmax(QKTdk⋅T)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k} \cdot T}\right)V Attention(Q,K,V)=softmax(dk⋅TQKT)V
其中 T=0.5+0.5×LnewLtrainT = 0.5 + 0.5 \times \frac{L_{\text{new}}}{L_{\text{train}}}T=0.5+0.5×LtrainLnew 是自适应温度 - 轻量微调:在1-2%的长文本数据上微调,修复性能损失
实际经验:YaRN已成为工业界事实标准,Qwen、DeepSeek、Llama-3社区版均采用,扩展到128K只需2000步微调。
2.2 注意力机制重构
核心思想:改变模型“关注信息”的方式,降低计算负担
主流技术对比:
| 技术 | 核心机制 | 计算复杂度 | 内存占用 | 优势场景 |
|---|---|---|---|---|
| 稀疏注意力 | Longformer(滑动窗口 + 全局token)、BigBird(随机 + 滑动 + 全局) | O(nw+ng)O(nw + ng)O(nw+ng) | 中 | 结构化文本(代码、表格) |
| FlashAttention 1-4 | 层级内存调度 + IO感知计算 + Blackwell GPU指令级优化 | O(n2)O(n^2)O(n2) (优化后) | 极低 | 所有场景的基础设施 |
| WindowAttentionV3 | 动态重叠窗口(overlap = 256 tokens)+ 全局token混合 | O(nn)O(n\sqrt{n})O(nn) | 低 | 32K-100K中长文本 |
FlashAttention 1-4 为何如此重要?
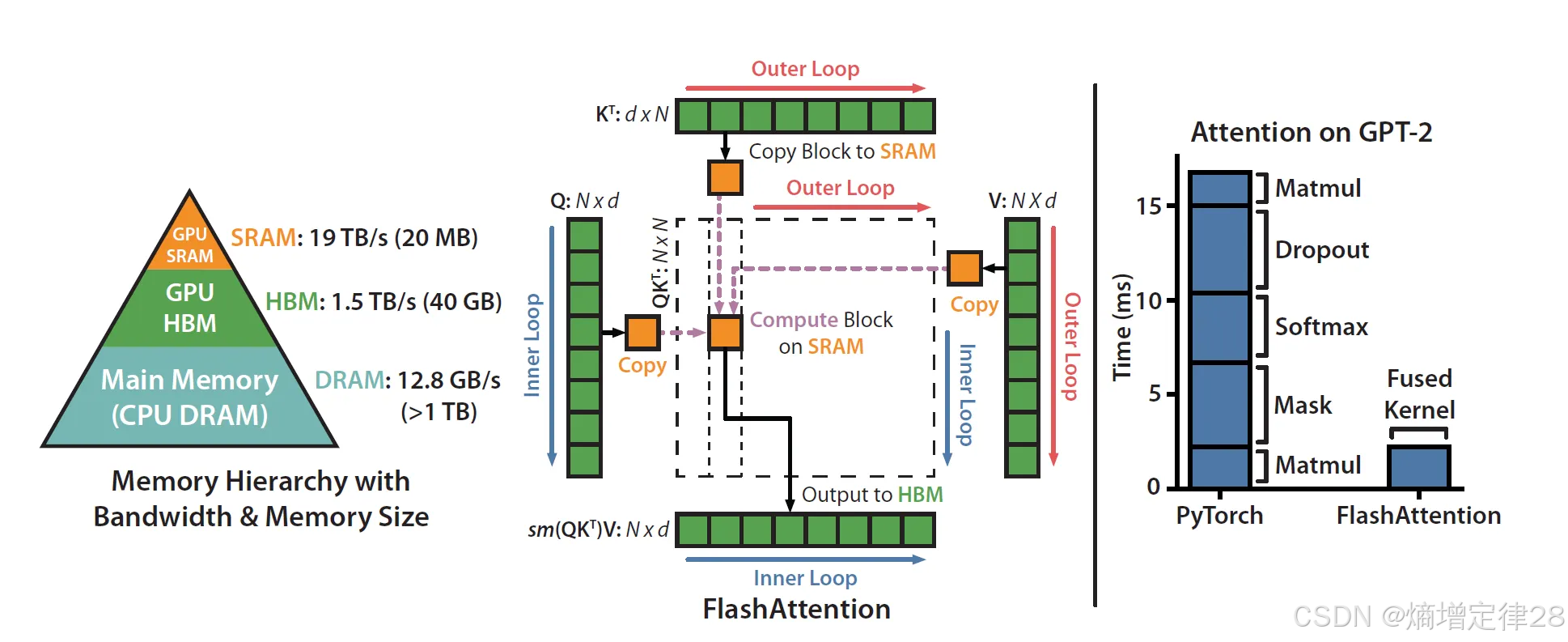
关键技术:
- 层级内存调度:利用GPU的寄存器、共享内存、全局内存三级存储
- IO感知计算:将softmax与矩阵乘融合,避免中间结果写回显存
- v4新增:Blackwell GPU指令级优化、自适应分块
效果:
- 显存占用 ↓ 3×
- 训练速度 ↑ 1.8×
- 支持更长序列(相同硬件下长度 ↑ 3–5×)
FlashAttention 1-4是所有扩展技术的必备底层优化,如同“地基”一般重要。
2.3 架构级创新
核心思想:彻底改变模型处理长文本的方式
主流技术对比:
| 技术 | 核心机制 | 扩展能力 | 是否需训练 | 保持全注意力 | 适用场景 |
|---|---|---|---|---|---|
| RingAttention | 环形拓扑多GPU协同,分块处理序列 | 1M+ tokens | 否 | ✅ | 超大规模部署 |
| Mamba/Jamba | 选择性状态空间方程替代注意力: ht=Aht−1+Bxt,yt=Chth_t = A h_{t-1} + B x_t, \quad y_t = C h_tht=Aht−1+Bxt,yt=Cht |
256K-1M | 是 | ❌ | 结构化长序列 |
| CEPE | 外挂轻量编码器压缩长上下文为memory tokens | 128K | 轻量 | ❌(交叉注意) | 内存受限场景 |
RingAttention
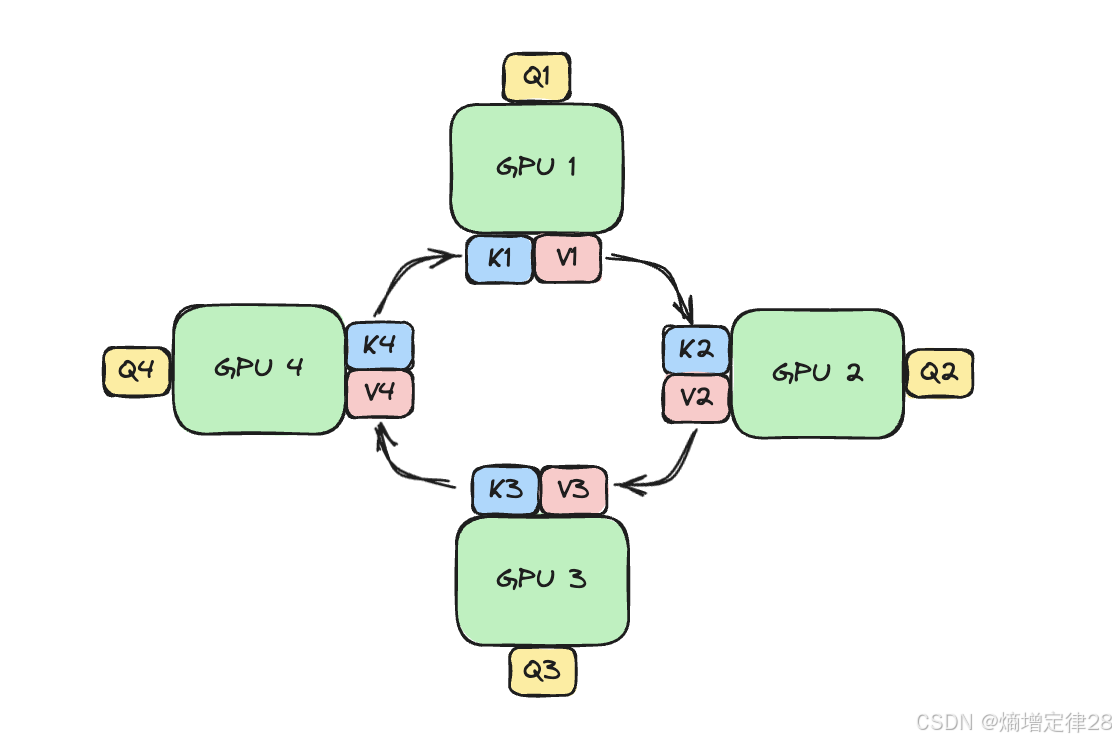
数学表达:
对于长度为 nnn 的序列,使用 PPP 个设备,每个设备处理 b=n/Pb = n/Pb=n/P 个token:
Attention(Qi,K,V)=∑j=1Psoftmax(QiKjTdk)Vj \text{Attention}(Q_i, K, V) = \sum_{j=1}^{P} \text{softmax}\left(\frac{Q_i K_j^T}{\sqrt{d_k}}\right) V_j Attention(Qi,K,V)=j=1∑Psoftmax(dkQiKjT)Vj
其中 QiQ_iQi 是第 iii 个设备的查询,通过环形通信聚合所有结果。
实现优势:
- 显存占用 ∝n/P\propto n / P∝n/P
- 支持百万级 tokens且保持全注意力表达能力
2.4 记忆增强系统
核心思想:不指望模型记住一切,而是给它一个外部记忆系统
MemOS三层记忆架构:
| 记忆层 | 存储内容 | 访问速度 | 技术实现 |
|---|---|---|---|
| Working Memory | 当前上下文(≤128K) | 毫秒级 | 原生Transformer |
| Episodic Memory | 关键事件摘要 | 秒级 | 向量数据库 + 自动摘要 |
| Semantic Memory | 结构化知识 | 秒级 | 知识图谱 |
ACE(Autonomous Context Evolution)创新:
- 模型自我生成、反思、优化提示词
- 实现上下文自主演进,无需微调
实际应用:客服机器人用MemOS记住用户历史偏好;研究助手用ACE自动摘要长论文关键点。
2.5 跨模态压缩技术(DeepSeek-OCR / Glyph)
核心思想:文本不是唯一载体,图像也能承载语义信息
DeepSeek-OCR(DeepSeek, 2025)核心思想: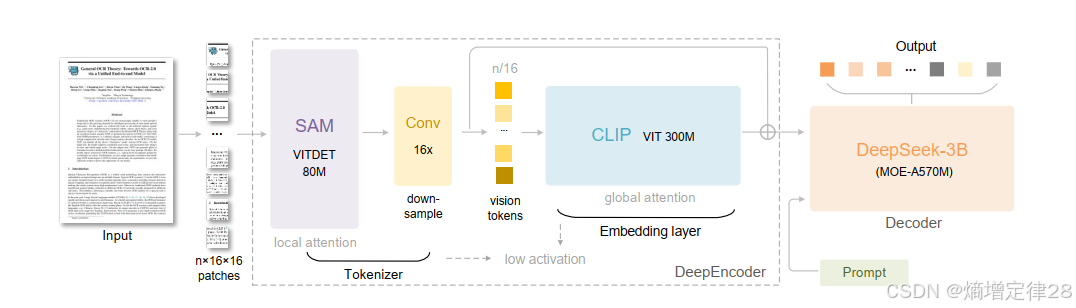
Glyph(智谱AI, 2025)工作流程:
- 将长文本渲染为高分辨率图像
- 用视觉语言模型(VLM)编码图像
- LLM基于VLM输出进行推理
- 遗传算法优化字体、布局、颜色以最大化语义保真度
效果对比:
| 指标 | 传统文本 | Glyph压缩 | 提升 |
|---|---|---|---|
| 128K窗口内容量 | 128K tokens | 500K+ tokens | 4× |
| 内存占用 | 100% | 25% | 4×节省 |
| LongBench得分 | 65.2 | 62.8 | 仅降3.7% |
突破性意义:Glyph证明了“上下文不必是文本序列”,特别适合PDF、代码库等静态长文档。
三、技术选型
3.1 综合对比
| 技术类别 | 代表方法 | 扩展能力 | 复杂度 | 是否需训练 | 内存效率 | 保持全注意力 | 适用长度 |
|---|---|---|---|---|---|---|---|
| 轻量化微调 | YaRN | 128K–256K | O(n2)O(n^2)O(n2) | 轻量微调 | 高 | ✅ | ≤256K |
| 架构创新 | RingAttention | ∞(1M+) | O(n)O(n)O(n) | 否 | 极高 | ✅ | >256K |
| 架构创新 | Mamba / Jamba | 1M+ | O(n)O(n)O(n) | 是 | 高 | ❌ | 结构化长序列 |
| 注意力优化 | FlashAttention-4 | 3–5×原长度 | O(n2)O(n^2)O(n2) | 否 | 极高 | ✅ | 所有场景(基建) |
| 跨模态压缩 | DeepSeek-OCR / Glyph | 百万级语义 | 视觉 O(n)O(n)O(n) | 是(渲染优化) | 极高 | 间接支持 | 静态文档 |
| 外挂编码器 | CEPE | 128K | O(n)O(n)O(n) | 轻量 | 极高 | ❌(交叉注意) | ≤128K |
四、评估体系与性能指标
4.1 主流基准测试
- LongBench / InfiniteBench:多任务综合评估
- Needle-in-a-Haystack (NIAH):关键信息检索能力
- BookQA / GovReport:长程一致性与结构化理解
4.2 新兴指标:Context Utilization Efficiency (CUE)
CUE=有效信息提取率输入长度 \text{CUE} = \frac{\text{有效信息提取率}}{\text{输入长度}} CUE=输入长度有效信息提取率
注意:“用得准”比“输得长”更实用更重要,避免盲目追求长度数字。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)