Neurlps2024论文解析|D-LLM A Token Adaptive Computing Resource Allocation Strategy for Large Languag
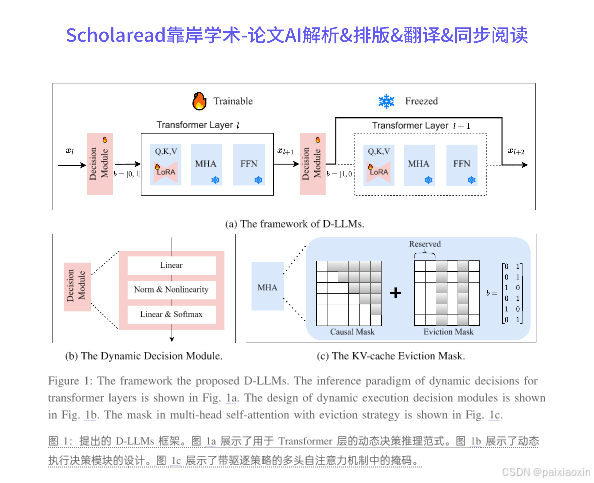
本文提出了一种名为D-LLM的新型动态推理机制,旨在为大型语言模型(LLMs)自适应地分配计算资源。当前,LLMs对每个词元的处理是等同的,但作者认为并非所有词语都同等重要,某些词语在简单问题中并不需要过多的计算资源。D-LLM通过为每个Transformer层设计动态决策模块,决定是否执行或跳过该层,从而提高推理速度。此外,本文还提出了一种有效的驱逐策略,以解决跳过层时KV缓存缺失的问题。
论文标题
D-LLM: A Token Adaptive Computing Resource Allocation Strategy for Large Language Models
D-LLM: 一种面向大型语言模型的令牌自适应计算资源分配策略
论文链接
D-LLM: A Token Adaptive Computing Resource Allocation Strategy for Large Language Models论文下载
论文作者
Yikun Jiang, Huanyu Wang, Lei Xie, Hanbin Zhao, Chao Zhang, Hui Qian, John C.S. Lui
内容简介
本文提出了一种名为D-LLM的新型动态推理机制,旨在为大型语言模型(LLMs)自适应地分配计算资源。当前,LLMs对每个词元的处理是等同的,但作者认为并非所有词语都同等重要,某些词语在简单问题中并不需要过多的计算资源。D-LLM通过为每个Transformer层设计动态决策模块,决定是否执行或跳过该层,从而提高推理速度。此外,本文还提出了一种有效的驱逐策略,以解决跳过层时KV缓存缺失的问题。实验结果表明,D-LLM在问答、摘要和数学解题任务中可减少高达45%的计算成本和KV存储,在常识推理任务中可减少50%,且性能未受影响。
分点关键点
-
动态推理机制
- D-LLM通过动态决策模块为每个Transformer层分配计算资源,决定是否执行或跳过该层。此机制使得在处理可有可无的词元和简单任务时,使用更少的层,从而提高推理效率。
-
驱逐策略
- 为了解决跳过层时KV缓存缺失的问题,D-LLM提出了一种驱逐策略,通过设计注意力矩阵的掩码来忽略未计算的特征,减少存储开销。这一策略确保了D-LLM与现有应用的兼容性。
-
实验结果
- D-LLM在多个基准测试中表现出色,能够在不降低性能的情况下,显著减少计算成本和KV存储。具体而言,在问答、摘要和数学解题任务中,计算成本和KV存储可减少45%,在常识推理任务中可减少50%。
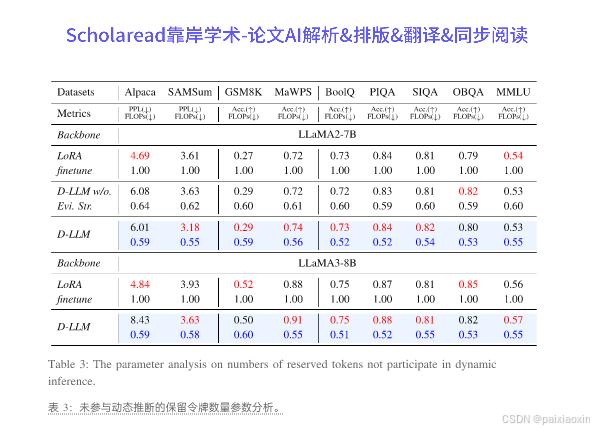
- D-LLM在多个基准测试中表现出色,能够在不降低性能的情况下,显著减少计算成本和KV存储。具体而言,在问答、摘要和数学解题任务中,计算成本和KV存储可减少45%,在常识推理任务中可减少50%。
-
与现有方法的比较
- D-LLM与传统的静态推理网络相比,能够根据输入的不同动态调整计算资源分配,避免了静态方法中对所有词元分配相同资源的低效问题。
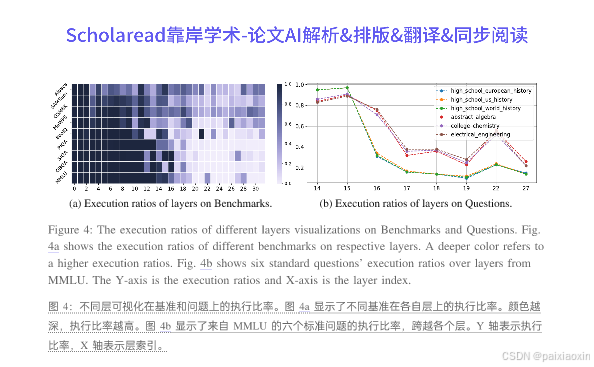
- D-LLM与传统的静态推理网络相比,能够根据输入的不同动态调整计算资源分配,避免了静态方法中对所有词元分配相同资源的低效问题。
论文代码
代码链接:https://github.com/Jyk-122/D-LLM
中文关键词
- 大型语言模型
- 动态推理
- 计算资源分配
- KV缓存
- 驱逐策略
- 计算成本
Neurlps2024论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)