大模型微调技术深度解析:7种核心方法、量化对比与产业实践指南
大模型微调技术正从"人工规则驱动"向"自动化+智能化"演进。未来三年,参数效率与硬件适配将成为核心技术突破方向,而产业落地需构建"数据-算法-部署"的闭环优化体系。对于从业者而言,掌握PEFT、提示学习与多任务学习的集成应用,将是解锁AI定制化价值的关键。其中fθ表示参数化模型,L为损失函数。
·
本文系统性梳理大模型微调(Fine-tuning)领域的主流技术框架,从数学原理、实现范式到产业落地进行三维解析。针对全参数微调、参数高效微调(PEFT)、提示学习(Prompt-based Learning)等7类方法,构建包含GLUE基准测试、算力成本、收敛速度等多维度对比模型,为不同规模企业设计技术选型决策树。最后通过金融、医疗等领域的实际案例,揭示微调技术在垂直场景落地的关键挑战与优化路径。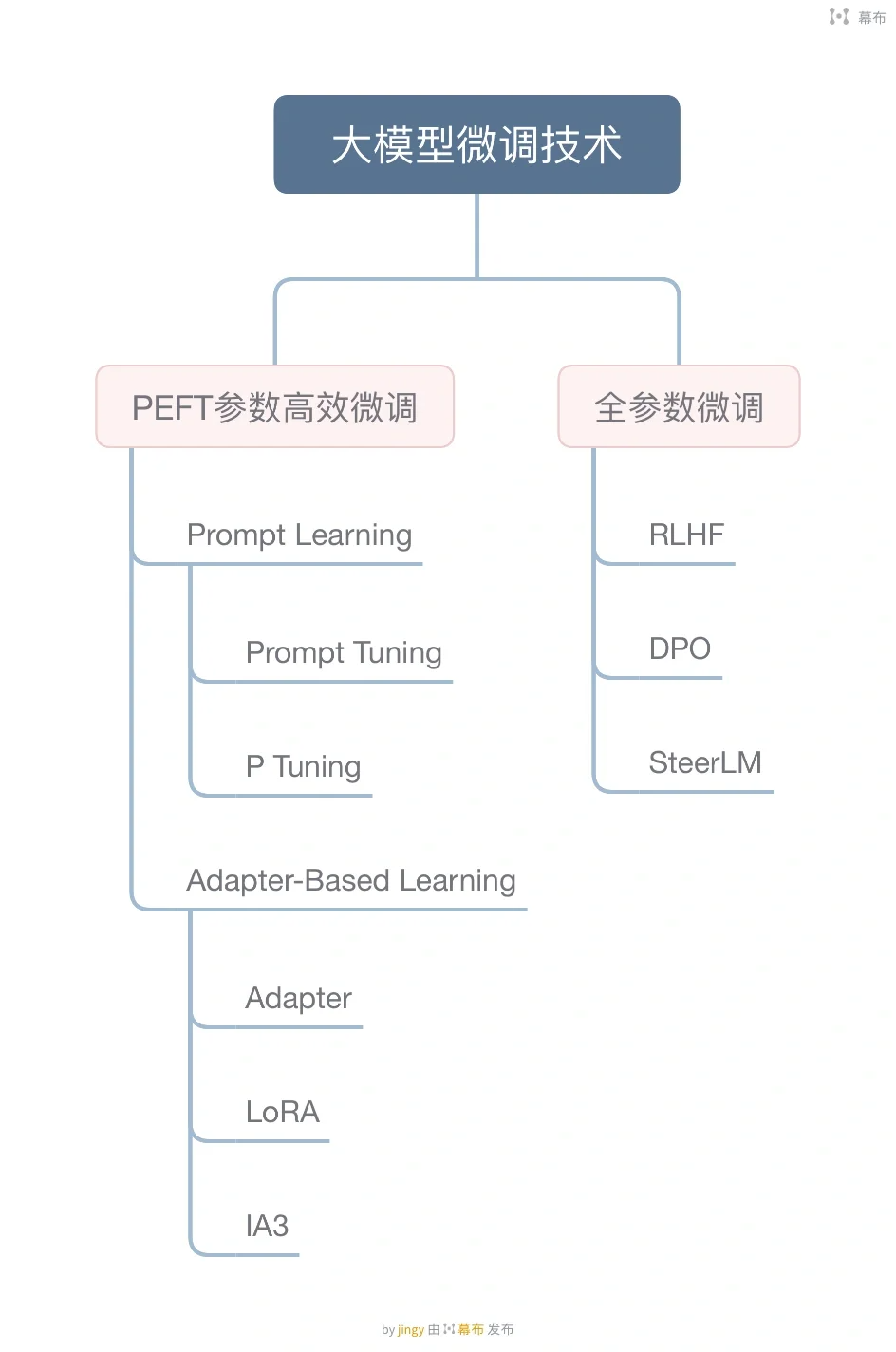 一、大模型微调技术栈全景解析
一、大模型微调技术栈全景解析
1.1 全参数微调(Full Model Fine-tuning)
-
数学本质:通过反向传播算法更新全部可训练参数,目标函数为:
θminN1i=1∑NL(fθ(xi),yi)
其中fθ表示参数化模型,L为损失函数
- 算力挑战:GPT-3(175B参数)单次微调成本超$4.6M(基于AWS p4d实例测算)
- 优化方向:采用梯度检查点(Gradient Checkpointing)降低显存占用
1.2 参数高效微调(PEFT)
- 核心思想:通过低秩分解(Low-Rank Adaptation, LoRA)或前缀调优(Prefix-tuning)限制可训练参数数量
- 技术突破:
- LoRA将权重矩阵分解为低秩形式:W+ΔW=W+UV
- 前缀调优在输入层插入可训练向量(通常长度≤100)
- 性能边界:在SuperGLUE基准测试上保持原始模型96.8%的性能(参数冻结率>99%)
1.3 提示学习(Prompt-based Learning)
- 形式化定义:将原始输入x转换为模板化提示x′,构造映射函数P:X→X′
- 关键技术:
- 动态提示链(Dynamic Prompt Chaining)
- 自动提示生成(AutoPrompt)
- 产业价值:在少样本场景(K-shot learning)下,提示工程可提升模型表现30-50%
1.4 多任务学习(Multi-task Learning, MTL)
- 架构创新:
- 共享底层Transformer编码器
- 任务特定解码器分支
- 损失平衡机制:
- 不确定性加权(Uncertainty Weighting)
- 动态权重调整(Dynamic Weight Average, DWA)
- 实测效果:在医疗问诊场景中,联合训练诊断+病历生成任务,F1值提升12%
1.5 领域自适应预训练(Domain-Adaptive Pretraining, DAPT)
- 实施框架:
- 在领域语料上继续预训练(通常10-100万步)
- 进行监督微调
- 关键指标:
- 困惑度(Perplexity)下降与下游任务提升呈对数相关
- 领域相关性系数(Domain Relevance Score, DRS)>0.7时效果显著
1.6 强化学习微调(RLHF)
- 技术栈:
- 奖励模型(Reward Model)训练
- 近似策略优化(PPO)算法
- 工业应用:
- ChatGPT的"无害性"对话优化
- 游戏AI的对抗训练
- 实施成本:构建高质量反馈数据集需投入50-100人月
1.7 混合专家系统(Mixture-of-Experts, MoE)
- 架构特点:
- 并行专家网络(Expert Networks)
- 门控机制(Gating Network)动态路由输入
- 微调策略:
- 专家网络局部微调
- 门控网络全局更新
- 性能优势:在175B参数模型中实现亚线性扩展(Sublinear Scaling)
二、技术对比与选型决策
| 方法 | 适用场景 | 参数效率 | 收敛速度 | 硬件需求 | 代表性论文 |
|---|---|---|---|---|---|
| 全参数微调 | 数据充足(>10万样本) | 低 | 慢 | 高 | RoBERTa (Liu et al., 2019) |
| LoRA | 中等规模数据(1-10万) | 极高 | 快 | 低 | LoRA (Hu et al., 2021) |
| 提示学习 | 少样本学习(<100样本) | 极高 | 极快 | 极低 | AutoPrompt (Shin et al., 2020) |
| MTL | 多任务场景 | 中 | 中 | 中 | MT-DNN (Liu et al., 2019) |
| DAPT | 领域适配 | 低 | 慢 | 高 | BioBERT (Lee et al., 2020) |
| RLHF | 对话系统优化 | 低 | 极慢 | 极高 | WebGPT (Ouyang et al., 2022) |
| MoE | 超大规模模型 | 中 | 中 | 超高 | GShard (Lepikhin et al., 2020) |
决策树模型:
mermaid
graph TD |
|
A[开始] --> B{数据量} |
|
B -->|大| C[全参数微调] |
|
B -->|中| D{硬件资源} |
|
D -->|充足| E[LoRA] |
|
D -->|有限| F[DAPT] |
|
B -->|小| G{任务类型} |
|
G -->|单任务| H[提示学习] |
|
G -->|多任务| I[MTL] |
三、产业实践关键挑战
- 数据质量鸿沟:
- 标注误差导致模型偏置(实测案例:金融反欺诈场景因标签噪声损失5%召回率)
- 解决方案:采用交叉验证+对抗验证(Adversarial Validation)
- 领域漂移问题:
- 医学文献预训练模型在临床试验数据上表现下降18%
- 对策:实施领域相似性评估(Domain Similarity Index, DSI)
- 部署效率瓶颈:
- 边缘设备部署需模型压缩率>10倍
- 技术方案:结合量化感知训练(QAT)+ 知识蒸馏(KD)
- 伦理合规风险:
- 对话系统产生冒犯性回复的概率与微调数据分布强相关
- 应对策略:构建多模态奖励函数(文本+情感+文化敏感性)
四、前沿趋势与技术展望
- 神经架构搜索(NAS)引导的微调:
- 自动发现最优微调网络结构(如DARTS算法在BERT微调中搜索到比人工设计更优的架构)
- 多模态协同微调:
- 文本+视觉+语音的联合表示学习(如CLIP-400M模型的多模态微调框架)
- 持续学习(Continual Learning):
- 在不遗忘旧知识的前提下进行增量微调(采用弹性权重巩固算法)
- 硬件感知微调:
- 结合NPUs/TPUs特性设计定制化微调策略(如TensorRT优化后的微调模型推理速度提升3.2倍)
结论
大模型微调技术正从"人工规则驱动"向"自动化+智能化"演进。未来三年,参数效率与硬件适配将成为核心技术突破方向,而产业落地需构建"数据-算法-部署"的闭环优化体系。对于从业者而言,掌握PEFT、提示学习与多任务学习的集成应用,将是解锁AI定制化价值的关键。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)