ElasticSearch 聚合之Java客户端实现聚合
ElasticSearch 聚合之Java客户端实现聚合
·
文章目录
一、聚合请求构建
1. 核心工具类
SearchRequest:构建搜索请求对象AggregationBuilders:提供各类聚合的静态方法
2. 聚合三要素
| 要素 | 描述 | 代码示例 |
|---|---|---|
| 聚合名称 | 自定义标识符 | "brand_agg" |
| 聚合类型 | 如terms/stats等 | AggregationBuilders.terms() |
| 聚合字段 | 需为keyword/数值/日期类型 | "brand.keyword" |
3. 基础桶聚合示例
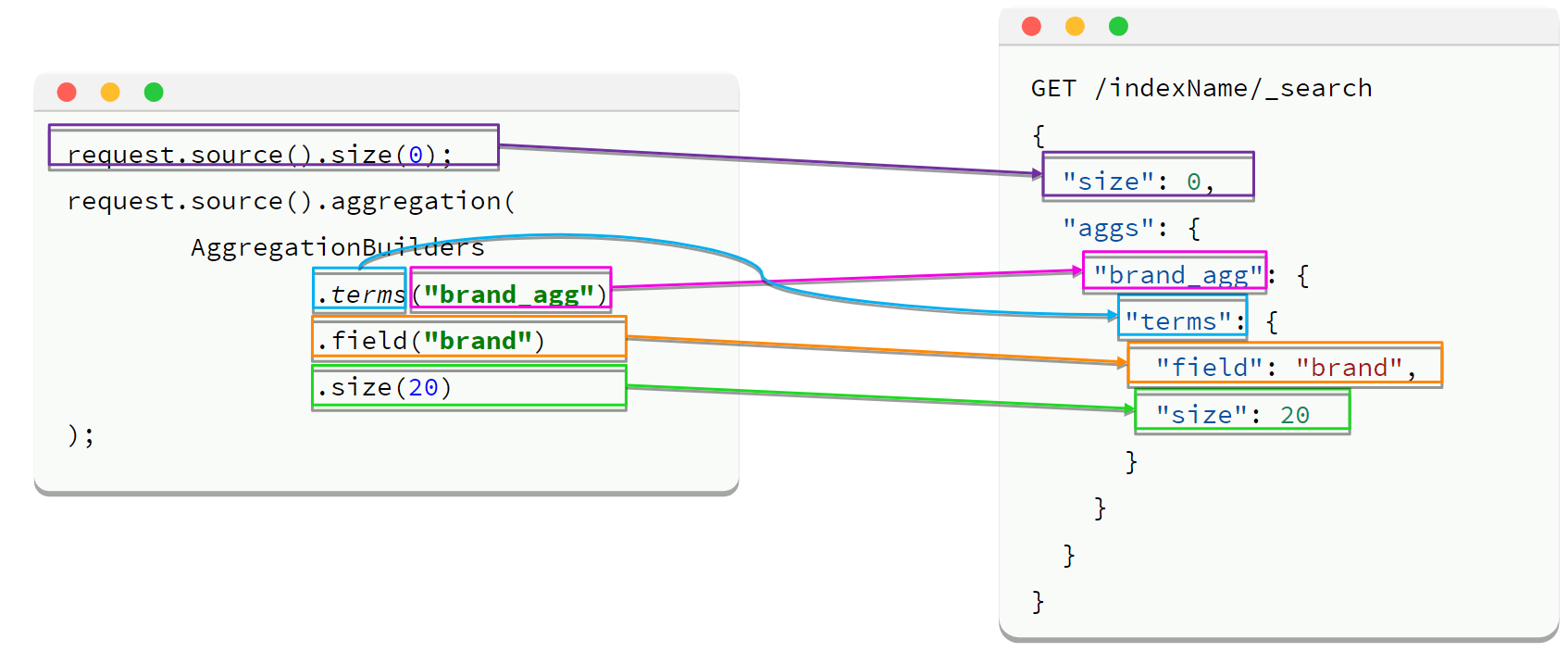
// 创建请求对象
SearchRequest request = new SearchRequest("items");
request.source()
.size(0) // 不返回文档数据
.aggregation(
AggregationBuilders.terms("brand_agg") // 聚合名称+类型
.field("brand") // 聚合字段
.size(20) // 返回前20个品牌
);
二、聚合结果解析
1. 解析流程
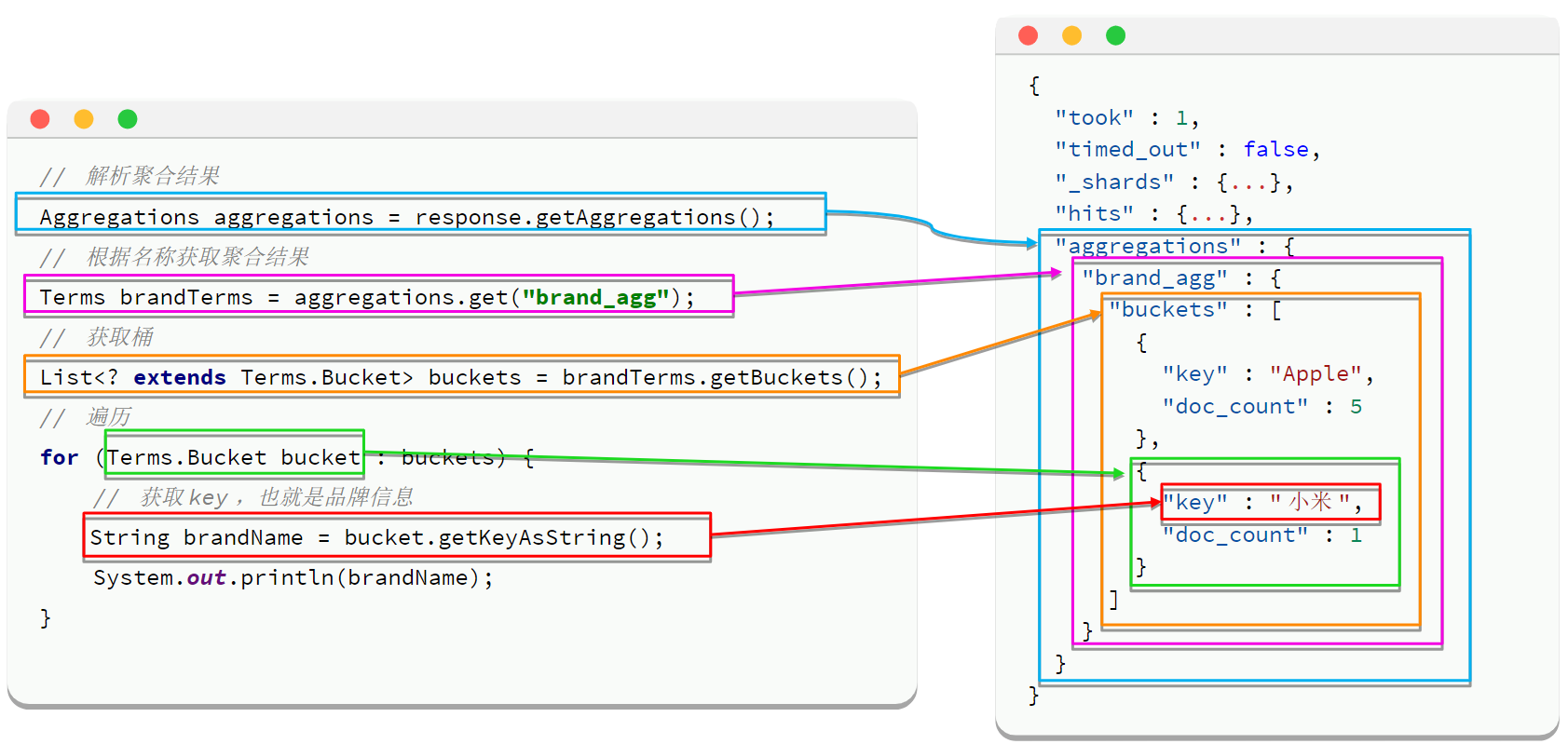
// 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 1. 获取聚合根节点
Aggregations aggregations = response.getAggregations();
// 2. 根据名称获取指定聚合结果
Terms brandTerms = aggregations.get("brand_agg");
// 3. 提取桶列表
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 4. 遍历处理每个桶
for (Terms.Bucket bucket : buckets) {
String brand = bucket.getKeyAsString(); // 品牌名称
long docCount = bucket.getDocCount(); // 文档数量
System.out.println(brand + ": " + docCount);
}
2. 关键API说明
response.getAggregations():获取所有聚合结果aggregations.get("聚合名称"):按名称获取具体聚合Terms.Bucket:代表单个分组结果,包含:getKeyAsString():分组字段值getDocCount():组内文档数量
三、嵌套聚合示例(桶聚合+度量聚合)
1. 统计各品牌价格指标
SearchRequest request = new SearchRequest("items");
request.source()
.size(0)
.aggregation(
AggregationBuilders.terms("brand_agg")
.field("brand")
.subAggregation( // 嵌套子聚合
AggregationBuilders.stats("price_stats")
.field("price")
)
);
2. 解析嵌套结果
Terms brandTerms = aggregations.get("brand_agg");
for (Terms.Bucket bucket : brandTerms.getBuckets()) {
String brand = bucket.getKeyAsString();
// 获取子聚合结果
Stats priceStats = bucket.getAggregations().get("price_stats");
System.out.println("品牌: " + brand);
System.out.println("平均价格: " + priceStats.getAvg());
System.out.println("最高价格: " + priceStats.getMax());
}
四、完整代码模板
@Test
void testAggregation() throws IOException {
// 1. 创建请求
SearchRequest request = new SearchRequest("index_name");
// 2. 构建聚合条件
request.source()
.size(0)
.aggregation(
AggregationBuilders.terms("聚合名称")
.field("字段名.keyword")
.size(返回数量)
.subAggregation( // 可选嵌套
AggregationBuilders.avg("avg_price")
.field("price")
)
);
// 3. 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. 解析结果
Aggregations aggs = response.getAggregations();
Terms terms = aggs.get("聚合名称");
terms.getBuckets().forEach(bucket -> {
String key = bucket.getKeyAsString();
long count = bucket.getDocCount();
// 处理嵌套聚合...
});
}
五、常见问题排查
1. 获取不到聚合结果
- 检查字段是否为keyword类型(需
.keyword后缀) - 确认聚合名称拼写一致
- 验证聚合字段是否存在映射
2. 类型转换异常
// 错误:直接强制转换
Stats stats = (Stats) aggregation;
// 正确:通过名称获取
Stats stats = aggregations.get("price_stats");
3. 性能优化
- 对高频聚合字段设置
fielddata: true - 限制返回桶数量(
.size(100)) - 避免在大文本字段上聚合
六、最佳实践建议
- 封装工具方法:将聚合解析逻辑封装成可复用方法
- 异常处理:添加空指针检查
if (aggregations != null) {
Terms terms = aggregations.get("brand_agg");
if (terms != null) {
// 处理逻辑...
}
}
- 结果格式化:将聚合结果转为DTO对象方便前端展示
List<BrandStatDTO> results = terms.getBuckets().stream()
.map(bucket -> new BrandStatDTO(
bucket.getKeyAsString(),
bucket.getDocCount()
))
.collect(Collectors.toList());

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)