【RL】DAPO的后续:VAPO算法
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks1、研究背景研究问题:这篇文章要解决的问题是如何在长链推理任务(long chain-of-thought reasoning)中提高基于价值模型的强化学习(RL)方法的效率和可靠性。研究难点:该问题的研究难点包括:价值模型偏差、异
note
- 解决关键挑战:VAPO系统地解决了价值模型偏差、异构序列长度和奖励信号稀疏性这三个困扰基于价值模型方法的关键问题。
- 创新技术集成:VAPO集成了多项先前研究的技术,并通过消融研究验证了它们的必要性,如Clip-Higher、Token-level Loss、Value-Pretraining、Decoupled-GAE、自我模仿学习和Group-Sampling。
- 自适应长度GAE:提出了Length-Adaptive GAE,能够根据响应长度动态调整GAE参数,从而优化优势估计的准确性和稳定性,特别是在数据序列长度变化广泛的情况下。
- 增强探索与利用的平衡:通过Clip-Higher、Positive Example LM Loss和Group-Sampling三种方法,增强了在基于验证器的任务中探索与利用之间平衡的效率。
- 正例语言模型损失:Positive Example LM Loss,增加正确样本的利用效率
- Value-Pretraining:减少价值模型的偏差在长cot的影响
- 价值预训练旨在减轻价值初始化偏差。如果简单地将PPO应用于长连贯对话任务(CoT),会导致输出长度坍塌和性能下降等失败现象。原因是价值模型是从奖励模型初始化的,而奖励模型与价值模型存在目标不匹配的问题
- 蒙特卡洛方法高方差、无偏差,而时序差分低方差、高偏差。为了权衡方差与偏差,广义优势估计(Generalized advantage Estimation,GAE)方法将优势函数定义 k 步优势的指数平均
- VAPO通过一个动态的λ参数来调解偏差-方差的权衡。具体策略是:在生成长序列(复杂轨迹)时,让λ接近1,优先保证奖励信号无衰减地传回(降低偏差),宁可承受一些高方差;在生成短序列时,让λ变小,优先获得更稳定的学习信号(降低方差)。
文章目录
一、VAPO强化学习
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
1、研究背景
- 研究问题:这篇文章要解决的问题是如何在长链推理任务(long chain-of-thought reasoning)中提高基于价值模型的强化学习(RL)方法的效率和可靠性。
- 研究难点:该问题的研究难点包括:价值模型偏差、异构序列长度、奖励信号稀疏性。
- 相关工作:该问题的研究相关工作有:OpenAI O1、DeepSeek R1、DAPO等。这些工作展示了强化学习在大规模语言模型(LLMs)中的成功应用,但在处理长链推理任务时仍存在挑战。
二、VAPO框架
这篇论文提出了VAPO(Value-model-based Augmented Proximal Policy Optimization)框架,用于解决长链推理任务中的强化学习问题。
1、价值预训练
价值预训练
首先,使用固定策略生成响应并更新价值模型,直到关键训练指标(如价值损失和解释方差)达到足够低的值。然后保存价值检查点并在后续实验中加载。
2、解耦GAE和自适应GAE
(1)解耦GAE
采用解耦GAE技术,价值网络从λ=1.0的回报中学习,而策略网络则从单独的λ值中获得优势。该方法有效解决了长链任务中的奖励衰减问题。
(2)自适应GAE
提出一种长度自适应的GAE方法,根据序列长度动态调整GAE参数,以实现对不同长度序列的自适应优势估计。公式如下:
λ policy = 1 − 1 α l , 其中 α = 0.05 \lambda_{\text{policy}} = 1 - \frac{1}{\alpha l}, \quad \text{其中 } \alpha = 0.05 λpolicy=1−αl1,其中 α=0.05
该方法确保了时序差分误差在长短序列之间更均匀地分布。
3、token级策略梯度损失
token级策略梯度损失
修改策略梯度损失的计算方法,使所有令牌在单个训练批次中具有相同的权重,从而增强对长序列问题的处理效率。
4、正例语言模型损失
正例语言模型损失
引入额外的负对数似然损失,以增强强化学习训练过程中正确样本的利用效率。公式如下:
L = − ∑ i ∈ T log p ( y i ∣ θ ) L = -\sum_{i \in \mathcal{T}} \log p(y_i \mid \theta) L=−i∈T∑logp(yi∣θ)
其中 T \mathcal{T} T 表示正确答案的集合,最终NLL损失与策略梯度损失通过权重系数 μ \mu μ 结合,作为更新策略模型的目标。
5、组采样
组采样
使用组采样在同一提示内生成更具对比性的正负样本,从而提高策略模型的学习能力。
三、实验设计
-
数据集
实验使用AIME 2024数据集,基准测试模型为Qwen 32B。 -
训练细节
基本PPO使用AdamW优化器,演员学习率为 1 × 1 0 − 6 1\times10^{-6} 1×10−6,评论家学习率为 2 × 1 0 − 6 2\times10^{-6} 2×10−6,批量大小为8192个提示,每个提示采样一次,小批量大小为512。 -
参数调整
与vanilla PPO相比,VAPO进行了以下参数调整:- 价值网络预热50步
- 使用解耦GAE,价值网络从 λ = 1.0 \lambda=1.0 λ=1.0 的回报中学习,策略网络从单独的 λ \lambda λ 值中获得优势
- 根据序列长度自适应设置 λ \lambda λ,公式如下:
λ p o l i c y = 1 − 1 α l , 其中 α = 0.05 \lambda_{policy}=1-\frac{1}{\alpha l},\quad\text{其中}\ \alpha=0.05 λpolicy=1−αl1,其中 α=0.05 - 调整剪辑范围为 ϵ h i g h = 0.28 \epsilon_{high}=0.28 ϵhigh=0.28 和 ϵ l o w = 0.2 \epsilon_{low}=0.2 ϵlow=0.2
- 使用令牌级策略梯度损失
- 添加正例语言模型损失,权重为0.1
- 每个采样使用512个提示,每个提示采样16次,小批量大小为512
四、模型效果
- 性能提升:VAPO在AIME 2024数据集上达到了60.4的最新得分,比之前的最优方法DAPO高出10分以上。
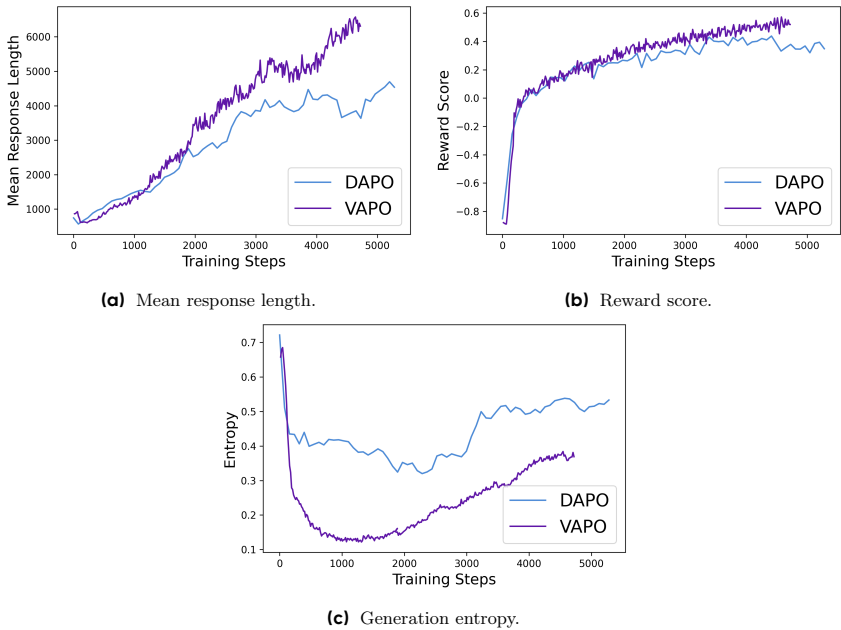
- 训练稳定性:VAPO在训练过程中没有出现崩溃现象,多次运行的结果一致,显示出其可靠性。
- 消融实验:通过逐个移除VAPO的七个修改部分,验证了每个修改的有效性。结果显示,移除任何一个修改都会导致性能显著下降。
五、论文评价
1、优点与创新
- 显著超越现有方法:VAPO在长链推理任务中显著超越了现有的无价值模型方法,如DeepSeek-R1-Zero-Qwen-32B和DAPO,达到了60.4的最新得分。
- 训练稳定性和效率:VAPO的训练过程非常稳定,能够在短短5000步内达到最先进性能,并且在多次独立运行中没有出现训练崩溃,展示了其可靠性。
- 解决关键挑战:VAPO系统地解决了价值模型偏差、异构序列长度和奖励信号稀疏性这三个困扰基于价值模型方法的关键问题。
- 创新技术集成:VAPO集成了多项先前研究的技术,并通过消融研究验证了它们的必要性,如Clip-Higher、Token-level Loss、Value-Pretraining、Decoupled-GAE、自我模仿学习和Group-Sampling。
- 自适应长度GAE:提出了Length-Adaptive GAE,能够根据响应长度动态调整GAE参数,从而优化优势估计的准确性和稳定性,特别是在数据序列长度变化广泛的情况下。
- 增强探索与利用的平衡:通过Clip-Higher、Positive Example LM Loss和Group-Sampling三种方法,增强了在基于验证器的任务中探索与利用之间平衡的效率。
2、论文不足
- 局限性:论文中没有明确提到具体的局限性,但可以推测在处理极长序列时,Length-Adaptive GAE可能仍然存在一定的偏差问题。
- 下一步工作:虽然VAPO已经取得了显著的性能提升,但未来的研究可以进一步优化和调整算法参数,以在不同任务和更长序列上进一步提升性能。
Reference
[1] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
[2] 字节新作 VAPO:使用基于价值的强化学习框架进行长思维链推理

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)