OmniMamba:通过状态空间模型高效和统一的多模态理解和生成
成功需要站在巨人的肩膀上:本文观察到基于自回归范式的Emu3模型虽使用了海量数据和80亿参数,但其最终性能仍逊于数据与参数更少的混合生成范式模型JanusFlow。许多研究在保留LLM文本生成范式的同时,探索整合扩散模型、基于流的生成模型和矢量量化自回归模型等多样化视觉生成范式的影响。其中[MMU]/[T2I]为预定义任务token,[SOT]/[EOT]标记文本起止,[SOI]/[EOI]标记图
OmniMamba: Efficient and Unified Multimodal Understanding and Generation via State Space Models
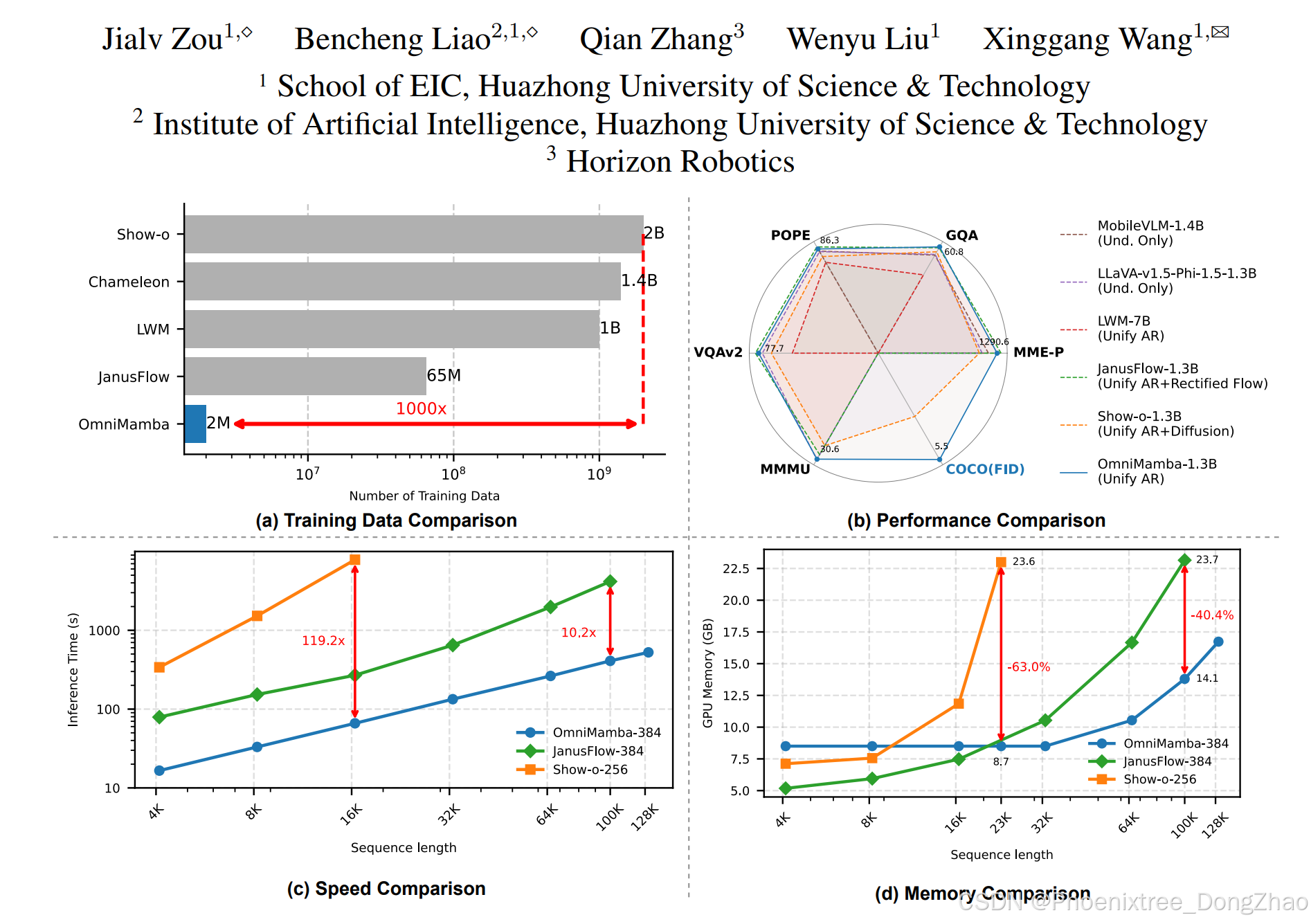
Figure 1. Comprehensive comparison between OmniMamba and other unified understanding and generation models. (a) Our OmniMamba is trained on only 2M image-text pairs, which is 1000 times less than Show-o. (b) With such limited data for training, our OmniMamba significantly outperforms Show-o across a wide range of benchmarks and achieves competitive performance with JanusFlow. Black metrics are for the multimodal understanding benchmark, while the blue metric is for the visual generation task. (c)-(d) We compare the speed and memory of OmniMamba with other unified models on the same single NVIDIA 4090 GPU. OmniMamba demonstrates up to a 119.2× speedup and 63% GPU memory reduction for long-sequence generation.
Abstract
Recent advancements in unified multimodal understanding and visual generation (or multimodal generation) models have been hindered by their quadratic computational complexity and dependence on large-scale training data. We present OmniMamba, the first linear-architecture-based multimodal generation model that generates both text and images through a unified next-token prediction paradigm. The model fully leverages Mamba-2's high computational and memory efficiency, extending its capabilities from text generation to multimodal generation. To address the data inefficiency of existing unified models, we propose two key innovations: (1) decoupled vocabularies to guide modality-specific generation, and (2) task-specific LoRA for parameter-efficient adaptation. Furthermore, we introduce a decoupled two-stage training strategy to mitigate data imbalance between two tasks. Equipped with these techniques, OmniMamba achieves competitive performance with JanusFlow while surpassing Show-o across benchmarks, despite being trained on merely 2M image-text pairs, which is 1,000 times fewer than Show-o. Notably, OmniMamba stands out with outstanding inference efficiency, achieving up to a 119.2 times speedup and 63% GPU memory reduction for long-sequence generation compared to Transformer-based counterparts.
统一多模态理解与视觉生成(或多模态生成)模型的最新进展一直受限于其二次计算复杂度与大规模训练数据的依赖性。本文提出了OmniMamba——首个基于线性架构的多模态生成模型,通过统一的下一词元预测范式实现文本与图像的联合生成。该模型充分继承Mamba-2的高计算与内存效率优势,将其能力从文本生成扩展至多模态生成。针对现有统一模型数据利用率低的问题,本文提出了两项关键创新:(1)解耦词表机制引导模态特定生成;(2)任务特定LoRA实现参数高效适配。此外,本文设计了双阶段解耦训练策略以缓解任务间数据失衡。在这些技术加持下,OmniMamba仅需200万图文对训练(比Show-o少1000倍),即达到与JanusFlow相当的性能,并在多项基准测试中超越Show-o。尤其值得注意的是,相比基于Transformer的同类模型,OmniMamba在长序列生成中展现出卓越的推理效率,最高可实现119.2倍加速与63%的GPU内存占用降低。
1. Introduction
【背景和研究现状】
In recent years, Large Language Models (LLMs) [2, 5, 15, 59, 60] have achieved remarkable advancements, igniting significant research interest in extending their fundamental capabilities to the visual domain. Consequently, researchers have developed a series of Multimodal Large Language Models (MLLMs) for tasks such as multimodal understanding [42, 43, 75, 77] and visual generation [31, 55].
Recent studies have emerged that seek to integrate multimodal understanding with visual generation, aiming to develop unified systems capable of handling both tasks simultaneously. Such designs hold the potential to foster mutual enhancement between generation and understanding, offering a promising pathway toward truly unifying all modalities. Numerous studies have sought to preserve the text generation paradigm of LLMs while exploring the impact [46, 64, 66, 67] of integrating diverse visual generation paradigms, such as diffusion models [24], flow-based generative models [16, 40], and vector-quantized autoregressive models [56].
近年来,大型语言模型(LLMs)取得了显著进展,激发了研究者将其核心能力扩展至视觉领域的兴趣。为此,研究者开发了一系列多模态大型语言模型(MLLMs),用于多模态理解和视觉生成等任务。
近期研究开始探索将多模态理解与视觉生成相融合,旨在构建能同时处理双重任务的统一系统。这种设计有望促进生成与理解能力的相互增强,为实现真正的全模态统一提供可能。许多研究在保留LLM文本生成范式的同时,探索整合扩散模型、基于流的生成模型和矢量量化自回归模型[56]等多样化视觉生成范式的影响。
【提出问题】
Unfortunately, the significant domain gap between image and text presents a critical challenge for unified multimodal generative models: preserving generation capabilities without degrading understanding performance requires an extensive volume of image-text pairs for training, as illustrated in Fig. 1. This not only leads to poor training efficiency but also creates a substantial barrier to the broader development of such models, as only a small fraction of researchers possess the resources to undertake such computationally demanding studies. Moreover, most existing unified multimodal generative models rely on Transformer-based LLMs [61]. However, their quadratic computational complexity results in slow inference speeds, rendering them less practical for real-time applications.
The challenges faced by existing unified multimodal generative models naturally lead us to ponder: can a model be developed that achieves both training efficiency and inference efficiency?
然而,图像与文本间的显著领域鸿沟为统一多模态生成模型带来了严峻挑战:要在保持生成能力的同时不损害理解性能,需要海量图文对进行训练(如图1所示)。这不仅导致训练效率低下,更因仅有少数研究者具备开展此类高计算需求研究的资源,极大阻碍了该领域的广泛发展。此外,现有统一多模态生成模型多基于Transformer架构的LLMs,其二次计算复杂度导致推理速度缓慢,难以满足实时应用需求。
针对现有统一多模态生成模型的困境,不禁思考:能否开发出兼具训练效率和推理效率的模型?
【解决方法】
To address this, we introduce OmniMamba, a novel unified multimodal generative model that requires only 2M image-text pairs for training. Built on the Mamba-2-1.3B [10] model as the foundational LLM with a unified next token prediction paradigm to generate all modalities, OmniMamba leverages the linear computational complexity of state space models (SSMs) to achieve significantly faster inference speeds. Furthermore, to empower the Mamba-2 LLM—whose foundational capabilities are relatively weaker compared to the extensively studied Transformer models—to efficiently learn mixed-modality generation with limited training data, we propose novel model architectures and training strategies.
To enhance the model’s capability in handling diverse tasks, we incorporate task-specific LoRA [25]. Specifically, within each Mamba-2 layer’s input linear projection, we introduce distinct LoRA modules for multimodal understanding and visual generation. During task execution, the features are modulated by both the linear projection and the corresponding task-specific LoRA, while the irrelevant LoRA components are deactivated. Furthermore, we propose the decoupled vocabularies to guide the model in generating the appropriate modality, which requires more data for the model to learn. On the data front, we further propose a novel two-stage decoupled training strategy to address the data imbalance between the two tasks, significantly improving training efficiency.
为此,本文提出OmniMamba——一个仅需200万图文对训练的新型统一多模态生成模型。基于Mamba-2-1.3B作为基础LLM,通过统一的下一词元预测范式生成所有模态,OmniMamba利用状态空间模型(SSM)的线性计算复杂度实现显著提速。针对Mamba-2相较于广泛研究的Transformer模型基础能力较弱的现状,本文提出创新性架构设计和训练策略,使其能在有限训练数据下高效学习跨模态生成。
为增强模型多任务处理能力,本文引入任务特定LoRA。具体而言,在Mamba-2各层的输入线性投影中,分别部署多模态理解和视觉生成专用的LoRA模块。任务执行时,特征通过线性投影和对应任务LoRA联合调节,非相关LoRA模块则关闭。此外,本文提出解耦词表机制指导模型生成目标模态,该设计需要更多数据支持模型学习。针对数据层面,本文进一步提出两阶段解耦训练策略,有效缓解任务间数据失衡问题,显著提升训练效率。
【结果和贡献】
Trained on only 2M image-text pairs, our proposed OmniMamba outperforms Show-o [67] on multiple multimodal understanding benchmarks and also matches the performance of JanusFlow [46], which was introduced by DeepSeek AI. Moreover, it achieves the best visual generation performance on the MS-COCO dataset [39]. Notably, OmniMamba demonstrates a 119.2× speedup at a sequence length of 16k and a 63% GPU memory reduction at a sequence length of 23k, compared to Show-o. Furthermore, at a sequence length of 100k, it achieves a 10.2× speedup and 40.4% memory savings compared to JanusFlow. Our main contributions can be summarized as follows:
• We introduce OmniMamba, the first Mamba-based unified multimodal understanding and visual generation model to the best of our knowledge. By novelly adopting decoupled vocabularies and task-specific LoRA, OmniMamba achieves effective training and inference.
• We propose a novel decoupled two-stage training strategy to address the issue of data imbalance between tasks. With this strategy and our model design, OmniMamba achieves competitive performance using only 2M image-text pairs for training-up to 1,000 times fewer than previous SOTA models.
• Comprehensive experimental results show that OmniMamba achieves competitive or even superior performance across a wide range of vision-language benchmarks and MS-COCO generation benchmark, with significantly improved inference efficiency, achieving up to a 119.2× speedup and 63% GPU memory reduction for long-sequence generation on NVIDIA 4090 GPU.
在仅200万图文对训练下,OmniMamba在多项多模态理解基准测试中超越Show-o,并与深度求索AI提出的JanusFlow性能相当。在MS-COCO视觉生成基准上取得最优表现。值得注意的是,相比Show-o,OmniMamba在16k序列长度下实现119.2倍加速,23k序列长度下减少63%显存占用;相较JanusFlow,在100k序列长度下实现10.2倍加速和40.4%显存节省。主要贡献如下:
• 提出首个基于Mamba架构的统一多模态理解与生成模型OmniMamba。通过创新的解耦词表机制和任务特定LoRA设计,实现高效训练与推理。
• 设计两阶段解耦训练策略,有效解决任务间数据失衡问题。结合模型架构创新,仅用200万图文对(比现有SOTA模型少1000倍)即达竞争性性能。
• 实验表明,OmniMamba在视觉语言理解基准和MS-COCO生成基准上取得竞争性或更优表现,在NVIDIA 4090 GPU上实现最高119.2倍长序列生成加速和63%显存节省。
【关键技术创新】
(1)解耦词表机制:通过独立视觉/语言词表指导模态特定生成
(2)动态任务LoRA:基于任务类型激活相应参数模块
(3)两阶段训练策略:首阶段强化多模态理解,次阶段专注视觉生成
(4)线性计算架构:基于Mamba-2的状态空间模型突破Transformer的二次复杂度瓶颈
该研究为多模态生成模型的高效训练与部署提供了新范式,显著降低了大规模多模态模型的研究门槛。
2. Related Works (略)
3. Method
3.1. Overall Architecture
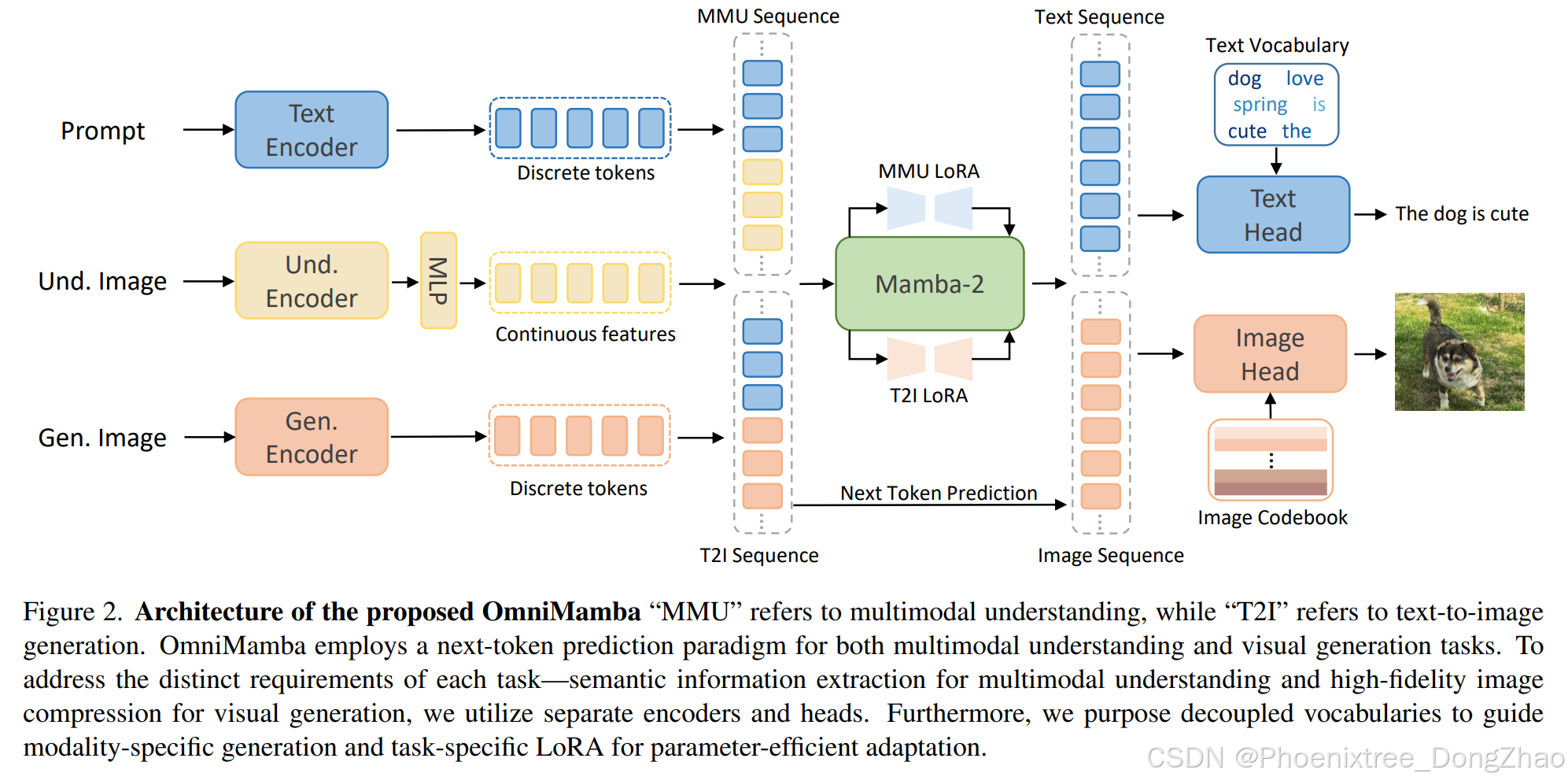
Our ultimate goal is to design a unified multimodal understanding and visual generation model that achieves both training and inference efficiency using only 2M image-text pairs for training. We believe the key to realizing this goal can be summarized in one word: decoupling. To this end, we propose OmniMamba, the architecture of which is illustrated in Fig. 2. Success necessitates standing on the shoulders of giants. We observe Emu3 [64], an autoregressive-based model which employs vast amounts of data and 8 billion model parameters. Despite these advantages, its final performance remains suboptimal, falling short of JanusFlow [46], a hybrid generative paradigm-based model with significantly less data and fewer parameters. We argue that this discrepancy stems not from the inherent superiority of the hybrid generative paradigm but from Emu3’s tight coupling design, it uses the same vocabulary and encoder for all tasks and modalities. While this design aligns with the original intention of a unified model, it may lead to inefficient data utilization. In the following, we will introduce our model by focusing on the concept of decoupling.
3.1 整体架构
本文的终极目标是设计一个统一的多模态理解与视觉生成模型,该模型仅需200万图文对即可实现训练与推理的高效性。本文认为实现这一目标的关键可归结于一个核心理念:解耦。为此,本文提出了如图2所示的OmniMamba架构。成功需要站在巨人的肩膀上:本文观察到基于自回归范式的Emu3模型虽使用了海量数据和80亿参数,但其最终性能仍逊于数据与参数更少的混合生成范式模型JanusFlow。分析表明,这种差距并非源于混合范式的固有优势,而是Emu3采用的紧耦合设计——所有任务和模态共享同一词表与编码器。虽然这种设计符合统一模型的初衷,但可能导致数据利用效率低下。下文将围绕解耦理念展开模型设计的详细阐述。
3.2. Decoupling Encoders for the Two Tasks
Previous works have explored using a single vision encoder for both tasks. For example, Show-o [67] employs MAGVIT-v2 [70] to encode images into discrete tokens for both understanding and generation tasks. TransFusion [76] utilizes a shared U-Net or a linear encoder to map images into a continuous latent space for both tasks. Emu3 trains its vision encoder based on SBER-MoVQGAN5, enabling the encoding of video clips or images into discrete tokens.
However, JanusFlow [46] has shown that such a unified encoder design is suboptimal. We believe this is primarily because multimodal understanding requires rich semantic representations for complex reasoning, whereas visual generation focuses on precisely encoding the spatial structure and texture of images. The inherent conflict between these two objectives suggests that a unified encoder design may not be the optimal choice. Therefore, OmniMamba adopts a decoupled vision encoder design.
Following prismatic VLMs [30], we fuse DINOv2 [48] and SigLIP [73] as an encoder to extract continuous features for multimodal understanding. The key idea is that integrating visual representations from DINOv2, which capture low-level spatial properties, with the semantic features provided by SigLIP leads to further performance improvements. For visual generation, we use an image tokenizer trained with LlamaGen [56] to encode images into discrete representations. This tokenizer was pretrained on ImageNet [11] and further fine-tuned on a combination of 50M LAION-COCO [33] and 10M internal high aesthetic quality data.
3.2 双任务解耦编码器
先前研究普遍采用单一视觉编码器处理双重任务。例如Show-o使用MAGVIT-v2将图像编码为离散token,TransFusion采用共享U-Net或线性编码器将图像映射至连续隐空间,Emu3则基于SBER-MoVQGAN5训练视觉编码器。
然而JanusFlow证实这种统一编码器设计存在局限性。究其原因,多模态理解需要丰富的语义表征支持复杂推理,而视觉生成更关注图像空间结构与纹理的精确编码。二者目标的本质冲突表明统一编码器并非最优选择。为此,OmniMamba采用解耦式视觉编码方案:
• 多模态理解编码器:借VLMs视觉语言模型,融合DINOv2与SigLIP提取连续特征。DINOv2捕捉低层空间属性,SigLIP提供语义特征,二者协同实现性能跃升。
• 视觉生成编码器:采用基于LlamaGen训练的图像分词器,将图像编码为离散表征。该分词器先在ImageNet预训练,后于5000万LAION-COCO及1000万内部高美学质量数据微调。
3.3. Decoupling Vocabularies for the Two Tasks
Unlike Emu3 and Show-o, which use a large unified vocabulary to represent both text and image modalities, to disentangle modality-specific semantics, we employ two separate vocabularies for each modality. This design explicitly separates the two modalities, providing additional modality-level prior knowledge. As a result, the model does not need to learn whether the output should be text or image, instead, it ensures the correct output modality by indexing the corresponding vocabulary. Our subsequent ablation experiments also confirm that OmniMamba’s dual-vocabulary design is one of the key factors for efficient training.
3.3 双任务解耦词表
区别于Emu3和Show-o采用统一大词表表征图文模态的方案,本文为各模态部署独立词表以解耦模态特定语义。这种设计显式分离两种模态,注入模态级先验知识。模型无需学习输出应为文本或图像,而是通过索引对应词表确保正确输出模态。后续消融实验证实,双词表设计是高效训练的关键因素之一。
3.4. Task Specific LoRA
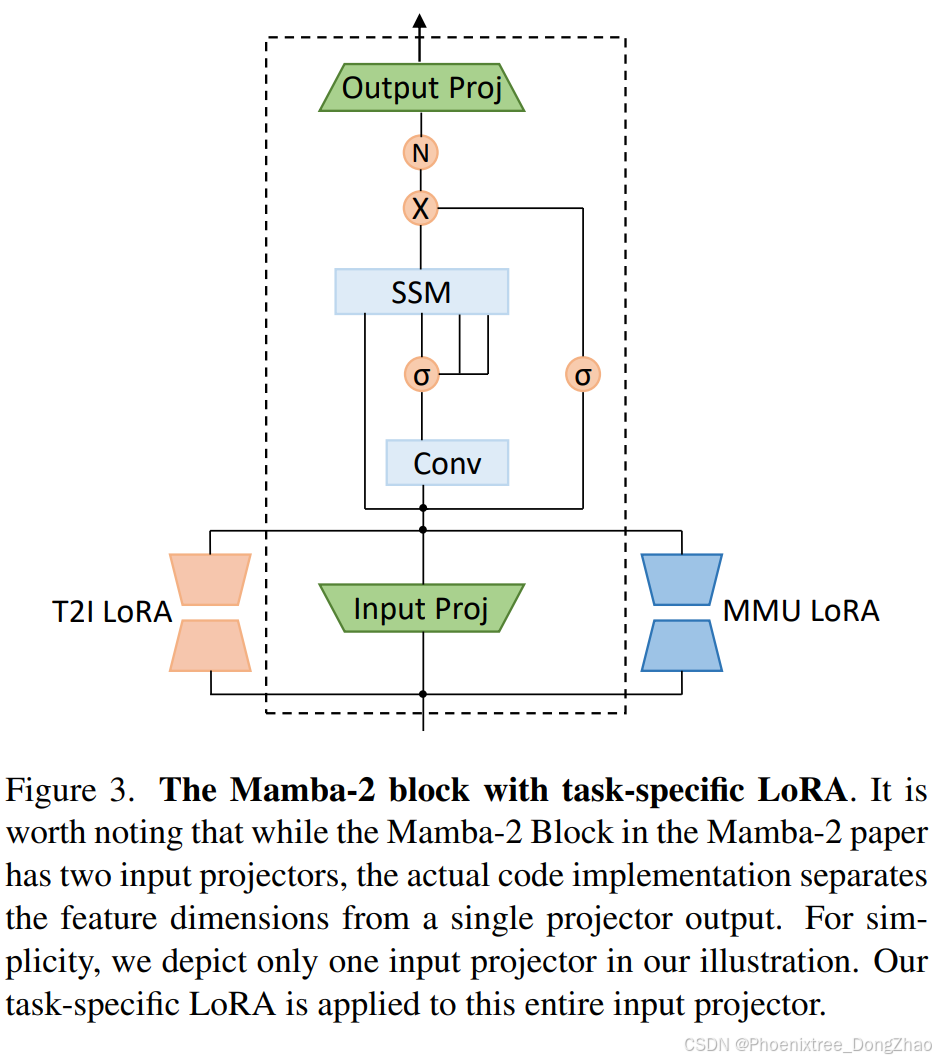
To enhance the model’s adaptability to specific tasks, we introduce task-specific adapters. We hypothesize that explicitly parameterizing the selection in SSMs based on task can enhance the data efficiency of multimodal training [14]. Specifically, to avoid introducing excessive parameters, we use LoRA [25] as the adapter. In OmniMamba, task-specific LoRA is applied only to the input projection of each Mamba-2 layer, as illustrated in Fig 3. When performing a specific task, the input linear projection and task-specific LoRA work together to effectively address the task. For instance, when the model performs a multimodal understanding (MMU) task, the MMU LoRA route is activated, while the text-to-image (T2I) LoRA route is dropped. Explicitly activating the corresponding adapter to assist in task execution helps improve data efficiency in training [14, 63].
3.4 任务特定LoRA
为增强模型任务适应能力,本文引入任务特定适配器。 假设在状态空间模型(SSM)中基于任务显式参数化选择能提升多模态训练的数据效率。具体实现上,为避免参数量激增,采用 LoRA 作为适配器。 如图3所示,OmniMamba仅在Mamba-2各层的输入线性投影层部署任务特定LoRA。 执行特定任务时,输入线性投影与任务LoRA协同作用:例如执行多模态理解(MMU)任务时激活MMU LoRA路径,同时屏蔽文生图(T2I)LoRA路径。 这种显式激活对应适配器的机制有效提升训练数据效率。
3.5. Decoupled Training Strategy
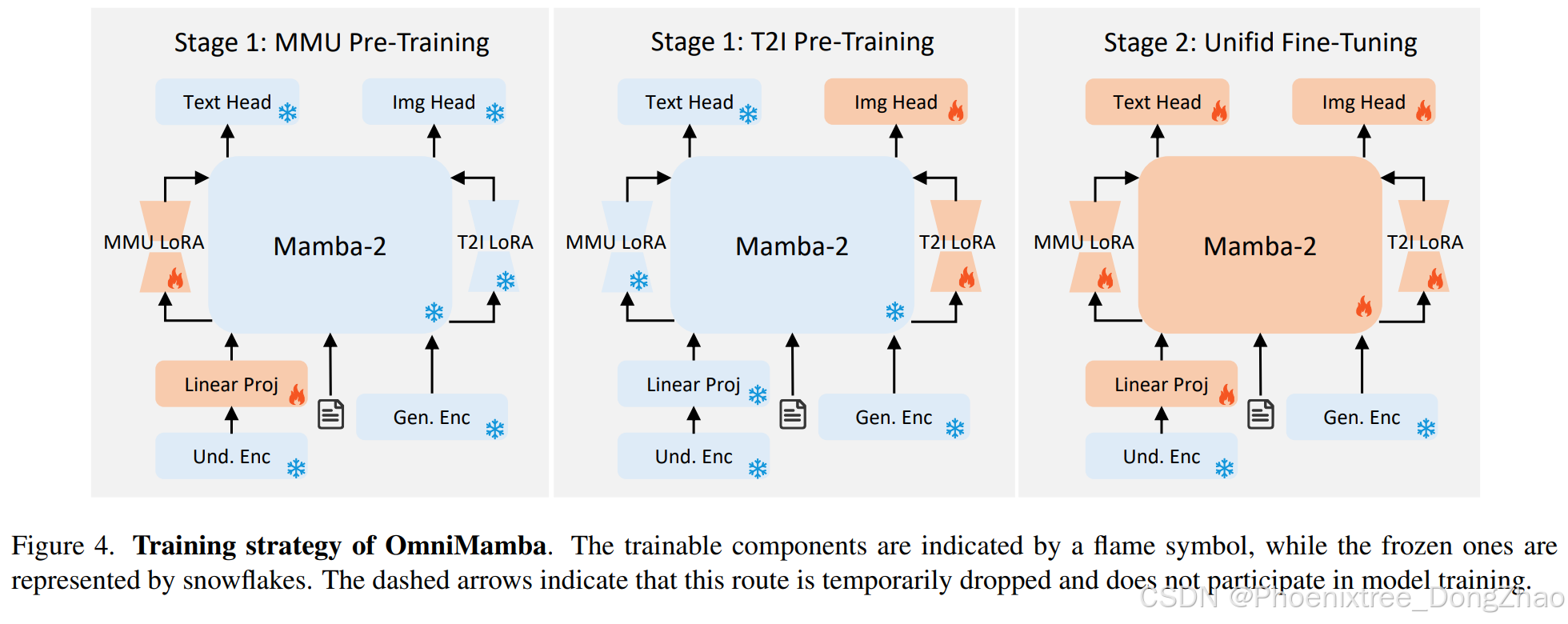
We propose a decoupled two-stage training strategy to address data imbalance between understanding and generation tasks while improving training efficiency, as illustrated in Fig. 4. This approach consists of (1) a Task-Specific Pre-Training stage for module-specific initialization and modality alignment, and (2) a Unified Fine-Tuning stage for unified multi-task training.
Decoupling Rationale
The first stage separates multimodal understanding (MMU) and text-to-image (T2I) generation tasks to prioritize modality alignment without data ratio constraints. Unlike joint pre-training methods (e.g., JanusFlow [46] with a fixed 50:50 MMU-T2I data ratio), our approach trains task-specific modules independently, enabling flexible dataset scaling (665K MMU vs. 83K T2I samples). Only randomly initialized components—linear projection and MMU LoRA for understanding, T2I LoRA and image head for generation—are trained, while the core Mamba-2 model remains frozen. This eliminates competition between tasks during early learning and allows asymmetric data utilization.
Stage 1: Task-Specific Pre-Training
It contains: MMU Pre-Training: Trains the linear projection and MMU LoRA to align visual-textual representations. The T2I LoRA path is disabled to isolate understanding-task learning. T2I Pre-Training: Optimizes the T2I LoRA and image decoder for visual synthesis. The MMU LoRA path is disabled to focus on generation capabilities.
Stage 2: Unified Fine-Tuning
Inspired by multi-task frameworks [30, 79], we freeze the visual encoder and train all other modules while preserving task-specific LoRA independence. During each forward pass: (1) MMU and T2I computations use their respective LoRA branches; (2) Losses from both tasks are summed for a unified backward pass. This balances parameter sharing (via the frozen backbone) and task specialization (via isolated LoRA paths), enabling synergistic learning while mitigating interference between understanding and generation objectives.
3.5 解耦训练策略
如图4所示,本文提出两阶段解耦训练策略,在缓解理解与生成任务数据失衡的同时提升训练效率。该策略包含:(1)任务特定预训练阶段实现模块初始化与模态对齐;(2)统一微调阶段完成多任务联合训练。
解耦理论依据
首阶段分离多模态理解(MMU)与文生图(T2I)任务,优先实现无数据比例约束的模态对齐。区别于JanusFlow等采用固定50:50 MMU-T2I数据比例的联合预训练方法,本方案独立训练任务特定模块,支持灵活数据扩展(665K MMU vs 83K T2I样本)。仅训练随机初始化组件——理解任务的线性投影与MMU LoRA、生成任务的T2I LoRA与图像头,而冻结核心Mamba-2模型。这种设计消除早期学习阶段的任务竞争,实现非对称数据利用。
阶段1:任务特定预训练
包含:
• MMU预训练:训练线性投影与 MMU LoRA 完成视觉-文本表征对齐,禁用 T2I LoRA 路径以隔离理解任务学习。
• T2I预训练:优化T2I LoRA与图像解码器实现视觉合成,禁用 MMU LoRA 路径以专注生成能力。
阶段2:统一微调
受多任务框架 [30, 79] 启发,冻结视觉编码器并训练其余模块,同时保持任务 LoRA 独立性。前向传播时:(1)MMU 与 T2I 计算使用各自 LoRA 分支;(2)双任务损失求和后统一反向传播。这种设计平衡参数共享(冻结主干)与任务专精(独立 LoRA 路径),在抑制理解-生成目标冲突的同时实现协同学习。
3.6. Training Details
Data Formats
Following Show-o [67], we use special tokens to unify the data formats for both multimodal understanding and visual generation tasks. The multimodal understanding data is structured as:
[MMU][SOI]{image tokens}[EOI][SOT]{text tokens}[EOT].
While the visual generation data is:
[T2I][SOT]{text tokens}[EOT][SOI]{image tokens}[EOI].
Specifically, [MMU] and [T2I] is a pre-defined task token used to guide the model in performing the corresponding task. [SOT] and [EOT] are used to represent the beginning and end of text tokens, respectively. Similarly, [SOI] and [EOI] represent the beginning and end of image tokens.
Training Objective
Since OmniMamba uses the auto-regressive paradigm to handle both multimodal understanding and visual generation tasks, we only need to use the standard cross-entropy loss for next-token prediction during training.
3.6 训练细节
数据格式
沿用Show-o方案,采用特殊token统一多模态理解与视觉生成任务的数据格式:
• 多模态理解数据格式:
[MMU][SOI]{图像token}[EOI][SOT]{文本token}[EOT]
• 视觉生成数据格式:
[T2I][SOT]{文本token}[EOT][SOI]{图像token}[EOI]
其中[MMU]/[T2I]为预定义任务token,[SOT]/[EOT]标记文本起止,[SOI]/[EOI]标记图像起止。
训练目标
由于OmniMamba采用自回归范式统一处理多模态理解与视觉生成,训练时仅需使用标准的下一token预测交叉熵损失。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)