AAAI2025 | MPVG | 通过全局平均池化最大化视觉 Transformer 位置嵌入的效用
本文 “Maximizing the Position Embedding for Vision Transformers with Global Average Pooling” 提出 MPVG 方法,用于解决视觉 Transformer 中全局平均池化(GAP)与分层结构结合时位置嵌入(PE)的问题。
Maximizing the Position Embedding for Vision Transformers with Global Average Pooling

本文 “Maximizing the Position Embedding for Vision Transformers with Global Average Pooling” 提出 MPVG 方法,用于解决视觉 Transformer 中全局平均池化(GAP)与分层结构结合时位置嵌入(PE)的问题。视觉 Transformer 在计算机视觉任务表现出色,GAP 和分层结构分别能提升性能,但二者结合会降低性能。研究发现 PE 在分层结构各层有平衡 token 嵌入值的作用,MPVG 通过将 PE 传递到最后一层的层归一化(LN),最大化 PE 的有效性。实验表明,在 ImageNet1K、CIFAR-100 等数据集的图像分类、目标检测和语义分割任务中,MPVG 均优于现有方法,证明其能有效提升视觉 Transformer 性能。
摘要-Abstract
In vision transformers, position embedding (PE) plays a crucial role in capturing the order of tokens. However, in vision transformer structures, there is a limitation in the expressiveness of PE due to the structure where position embedding is simply added to the token embedding. A layer-wise method that delivers PE to each layer and applies independent Layer Normalizations for token embedding and PE has been adopted to overcome this limitation. In this paper, we identify the conflicting result that occurs in a layer-wise structure when using the global average pooling (GAP) method instead of the class token. To overcome this problem, we propose MPVG, which maximizes the effectiveness of PE in a layer-wise structure with GAP. Specifically, we identify that PE counterbalances token embedding values at each layer in a layer-wise structure. Furthermore, we recognize that the counterbalancing role of PE is insufficient in the layer-wise structure, and we address this by maximizing the effectiveness of PE through MPVG. Through experiments, we demonstrate that PE performs a counterbalancing role and that maintaining this counterbalancing directionality significantly impacts vision transformers. As a result, the experimental results show that MPVG outperforms existing methods across vision transformers on various tasks.
在视觉 Transformer 中,位置嵌入(PE)在捕捉 token 顺序方面起着至关重要的作用。然而,在视觉 Transformer 结构中,由于位置嵌入只是简单地添加到 token 嵌入上,这限制了 PE 的表达能力。为了克服这一限制,采用了一种逐层的方法,将 PE 传递到每一层,并对 token 嵌入和 PE 分别应用独立的层归一化。在本文中,我们发现当在分层结构中使用全局平均池化(GAP)方法代替类别 token 时,会出现相互矛盾的结果。为了解决这个问题,我们提出了 MPVG 方法,该方法在使用 GAP 的分层结构中最大化 PE 的有效性。具体而言,我们发现 PE 在分层结构的每一层中都对 token 嵌入值起到平衡作用。此外,我们认识到在分层结构中 PE 的平衡作用并不充分,因此我们通过 MPVG 方法最大化 PE 的有效性来解决这一问题。通过实验,我们证明了 PE 具有平衡作用,并且保持这种平衡方向对视觉 Transformer 有显著影响。结果表明,实验结果显示 MPVG 在各种视觉 Transformer 的不同任务上均优于现有方法。
引言-Introduction
该部分主要阐述了视觉 Transformer 的研究背景,介绍了图像表示方法和位置嵌入(PE)两个研究方向,并指出其中存在的问题,进而提出本文的研究内容,具体如下:
- 视觉 Transformer 的发展与地位:视觉 Transformer 在计算机视觉领域发展迅速,凭借卓越性能在图像分类、目标检测和语义分割等任务中超越 CNNs,成为关键架构,引发了对其架构元素的深入研究。
- 图像表示方法的研究
- 类 token 与 GAP 的应用:ViT 中使用类 token 进行图像表示和分类预测,而 GAP 因具有平移不变性和优越性能,在部分视觉 Transformer 中更受青睐,已被广泛应用于多个模型中。
- 存在的问题:在使用层状结构传递 PE 时,GAP 与层状结构结合出现了性能下降的冲突结果,即单独使用 GAP 方法和层状结构都能提升性能,但二者结合却导致性能降低。
- 位置嵌入的研究
- PE的重要性:自注意力机制在捕捉输入 token 顺序方面存在不足,PE 为视觉Transformer 中的 token 提供位置信息,发挥着关键作用。
- PE的局限性与改进:原始视觉 Transformer 中,PE 直接加到 token 嵌入上再输入第一层,这种结构限制了 PE 的表现力。为解决此问题,引入层状结构,对 token 嵌入和PE 分别进行层归一化(LN),并逐层传递 PE,增强了其表现力。
- 本文的研究内容:针对 GAP 和层状结构结合出现的冲突结果,提出一种在 GAP 方法中最大化 PE 效果的方法。通过研究发现,在层状结构中 PE 不仅提供位置信息,还能平衡 token 嵌入值,且这种平衡作用随层数加深更明显。基于此提出两个假设,并通过对比 PVG 和 MPVG 两种方法进行验证,实验证明 MPVG 能有效最大化 PE 效果,提升视觉 Transformer 性能。
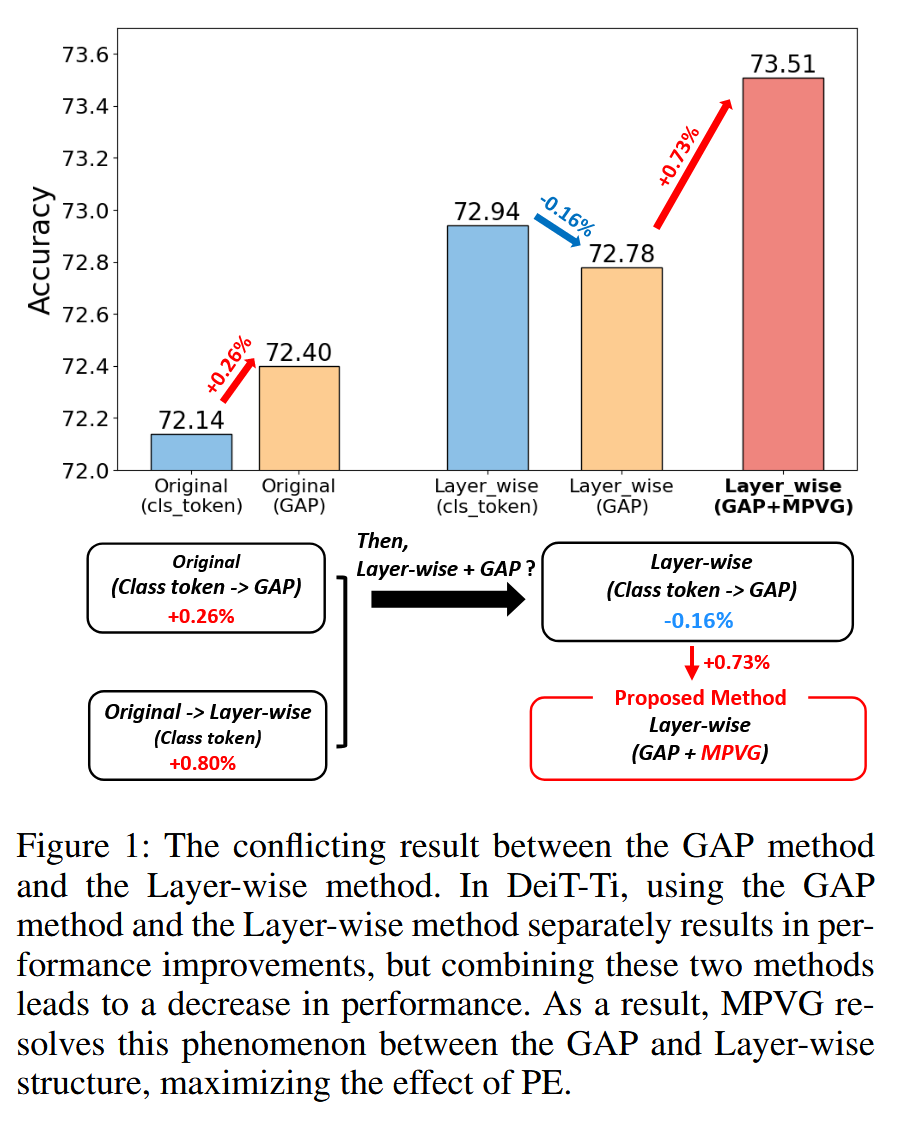
图1:全局平均池化(GAP)方法和层状结构方法之间的冲突结果。在 DeiT-Ti 模型中,单独使用 GAP 方法和层状结构方法都能提升性能,但将这两种方法结合使用时,性能却会下降。因此,MPVG 方法解决了 GAP 和层状结构之间的这一现象,最大化了位置嵌入(PE)的效果。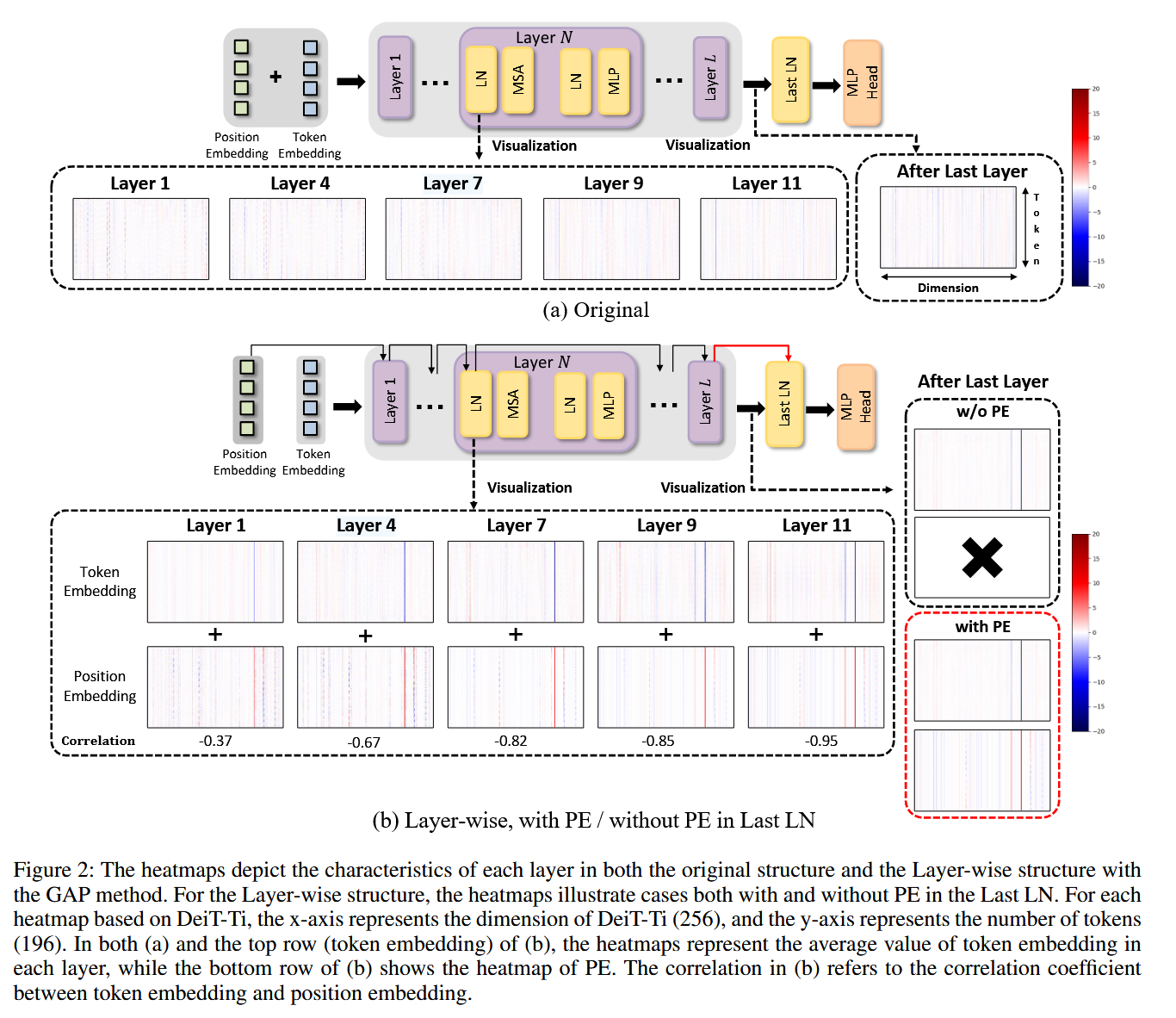
图2:热图展示了原始结构和采用全局平均池化(GAP)方法的层状结构中各层的特征。对于层状结构,热图展示了最后一个层归一化(Last LN)中有无位置嵌入(PE)的两种情况。每张基于 DeiT-Ti 的热图中,x 轴代表 DeiT-Ti 的维度(256),y 轴代表 token 的数量(196)。在图(a)和图(b)的顶行(token 嵌入)中,热图表示各层中token 嵌入的平均值,而图(b)的底行展示了 PE 的热图。图(b)中的相关性指的是 token 嵌入和位置嵌入之间的相关系数。
相关工作-Related Work
该部分主要介绍了视觉 Transformer 相关的三个方面的研究工作,分别是视觉 Transformer 本身、类 Token 与全局平均池化(GAP),以及视觉 Transformer 中的位置嵌入,具体内容如下:
- 视觉 Transformer:其设计源于自然语言处理的 Transformer,经改进后适用于计算机视觉任务,如在图像分类、目标检测和语义分割等领域广泛应用。
- 类 Token 与全局平均池化(GAP):ViT 对类 Token 和 GAP 进行了对比消融研究,其他研究也在探索它们在视觉 Transformer 中的应用。部分模型(如 CeiT、T2T-ViT )使用类 Token,而 Swin Transformer、CPVT 等采用 GAP。GAP 因具有平移不变性,在图像分类任务中表现更优,且计算复杂度更低。
- 视觉 Transformer 中的位置嵌入
- 绝对位置嵌入:通过正弦函数生成,添加到输入 token 嵌入中,能使模型有效聚焦于输入序列中相近的 token,增强捕捉空间关系和模式的能力。此外,位置嵌入也可以是可学习的,通过训练参数生成,许多模型因其在编码位置信息方面的有效性而采用。
- 相对位置嵌入:用于编码 token 之间的相对位置信息,在计算机视觉中,2-D 相对位置编码在图像分类任务中表现优于传统的 2-D 正弦嵌入,能更有效地捕捉 token 之间的空间关系。相关研究如 iRPE、RoPE 分别通过不同方式对相对位置嵌入进行改进 。
方法-Methodology
该部分介绍了绝对位置嵌入、层状结构等基础知识,进而提出 MPVG 和 PVG 两种方法来验证假设,具体内容如下:
- 绝对位置嵌入:在视觉 Transformer 中,绝对位置嵌入在输入层前与 token 嵌入相加,公式为 x 0 = [ x c l s ; p 1 ; p 2 ; . . . p N ; ] + p o s x_{0}=[x_{cls};p^{1};p^{2};...p^{N};]+pos x0=[xcls;p1;p2;...pN;]+pos. 之后,特征经过多层处理,其中包含多头自注意力(MSA)、层归一化(LN)和多层感知机(MLP)等操作,公式分别为 x l ′ = M S A ( L N l ( x l ) ) + x l x_{l}'=MSA\left(LN_{l}\left(x_{l}\right)\right)+x_{l} xl′=MSA(LNl(xl))+xl 、 x l + 1 = M L P ( L N l ′ ( x l ′ ) ) + x l ′ x_{l+1}=MLP\left(LN_{l}'\left(x_{l}'\right)\right)+x_{l}' xl+1=MLP(LNl′(xl′))+xl′ 、 y = L N ( x L + 1 ) y=LN\left(x_{L+1}\right) y=LN(xL+1) , x L + 1 x_{L+1} xL+1 表示经过最后一层 L L L 后的输出值。
- 层状结构(Layer-wise Structure):传统位置嵌入与 token 嵌入的连接方式存在问题,二者在 LN 中共享仿射参数,限制了 PE 的表现力。层状结构针对此问题进行改进,使用独立的 LN 分别处理 token 嵌入和 PE,修改后的公式为 x 0 = [ x c l s ; p 1 ; p 2 ; . . . p N ; ] x_{0}=[x_{cls};p^{1};p^{2};...p^{N};] x0=[xcls;p1;p2;...pN;] 、 x l ′ = M S A ( L N l ( x l ) + L N l ′ ( p o s l ) ) + x l x_{l}' = MSA(LN_{l}(x_{l})+LN_{l}'(pos_{l}))+x_{l} xl′=MSA(LNl(xl)+LNl′(posl))+xl. PE 按 p o s 0 = p o s pos_{0}=pos pos0=pos , p o s l = L N l − 1 ′ ( p o s l − 1 ) ( l = 1 , . . . , L ) pos_{l}=LN_{l - 1}'(pos_{l - 1})(l = 1,...,L) posl=LNl−1′(posl−1)(l=1,...,L) 的方式在各层传递。
- MPVG 和 PVG 方法:为验证假设,提出 MPVG 和 PVG 两种方法。在采用 GAP 方法的情况下,去除类 token 并对层状结构的细节进行修改,结合 “在输入层前添加 token 嵌入和 PE” 以及 “除第 0 层外逐层传递 PE” 这两种结构方式,得到 PVG 方法,相关公式为:
x 0 = [ p 1 ; p 2 ; . . . p N ; ] + p o s x_{0}=[p^{1};p^{2};...p^{N};]+pos x0=[p1;p2;...pN;]+pos
x l ′ = { M S A ( L N 0 ( x 0 ) ) + x 0 i f l = 0 M S A ( L N l ( x l ) + L N l ′ ( p o s l − 1 ) ) + x l i f 1 ≤ l ≤ L x_{l}' = \begin{cases}MSA\left(LN_{0}\left(x_{0}\right)\right)+x_{0} & if\quad l=0 \\ MSA\left(LN_{l}\left(x_{l}\right)+LN_{l}'\left(pos_{l-1}\right)\right)+x_{l} & if \quad 1 \leq l \leq L \end{cases} xl′={MSA(LN0(x0))+x0MSA(LNl(xl)+LNl′(posl−1))+xlifl=0if1≤l≤L
p o s 0 = p o s pos_{0}=pos pos0=pos
p o s l = L N l ′ ( p o s l − 1 ) ( l = 1... L ) pos_{l}=LN_{l}'(pos_{l - 1}) \quad (l = 1...L) posl=LNl′(posl−1)(l=1...L).
在 PVG 基础上,将 PE 传递到最后的 LN,得到 MPVG 方法,公式为 y = L N ( x L + 1 ) + L N ′ ( p o s 0 ) y=LN\left(x_{L+1}\right)+LN'\left(pos_{0}\right) y=LN(xL+1)+LN′(pos0),通过对比这两种方法来验证 PE 的平衡作用及对模型性能的影响。
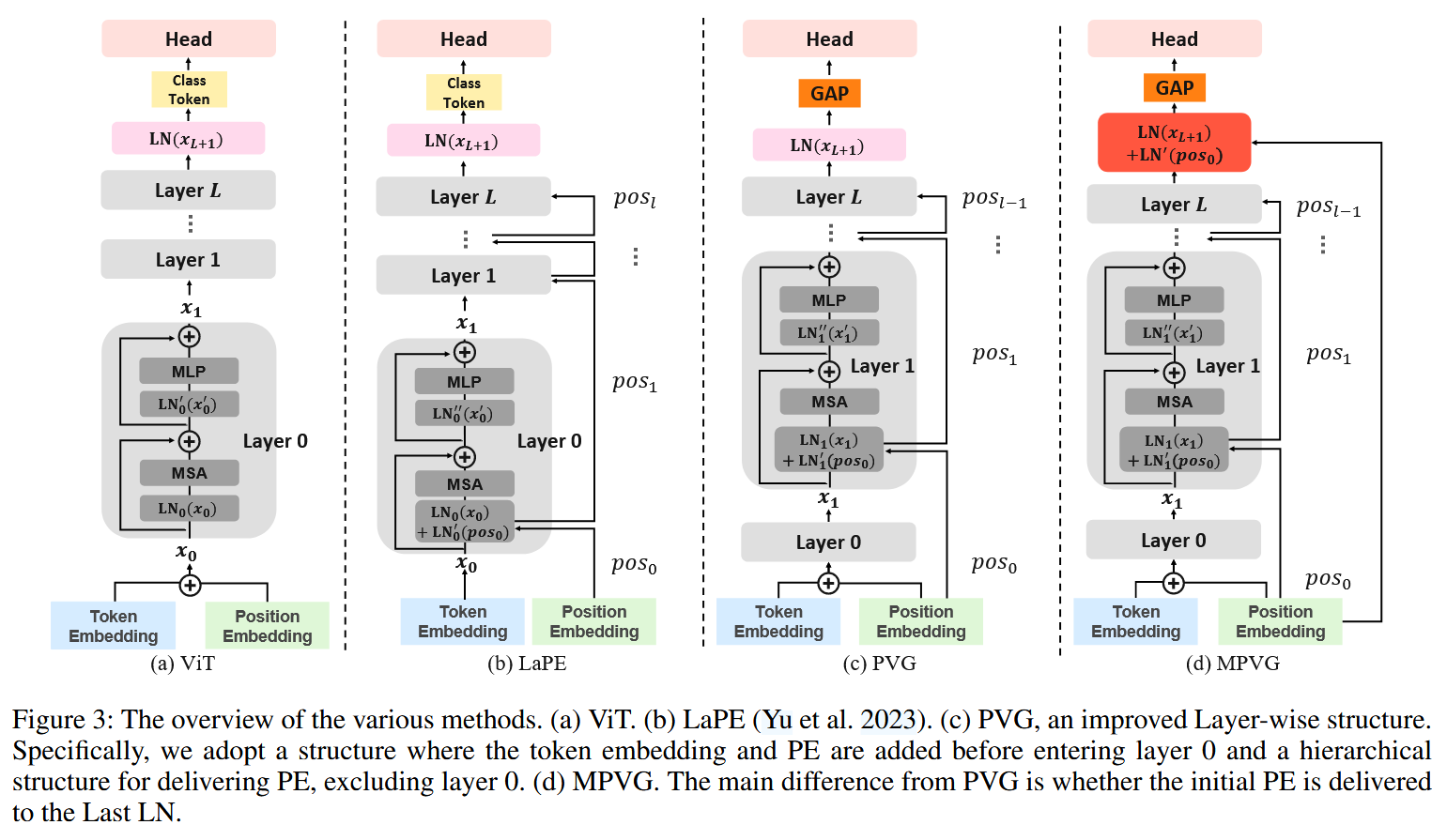
图3:各种方法的概述。(a) ViT。(b) LaPE(Yu等人,2023年)。© PVG,一种改进的层状结构。具体来说,我们采用在进入第 0 层之前添加 token 嵌入和位置嵌入(PE)的结构,以及除第 0 层外分层传递 PE 的结构。(d) MPVG。它与 PVG 的主要区别在于是否将初始 PE 传递到最后的层归一化(Last LN)。
实验-Experiment
该部分主要对提出的 MPVG 方法进行了多方面实验验证,涵盖训练设置、在不同任务(图像分类、目标检测、语义分割)上的性能评估、相关分析以及消融研究,具体内容如下:
- 训练设置:使用 RTX 4090 GPU 进行实验,多数模型用 4 个 GPU,DeiT-B 用 8 个GPU,优化器采用 AdamW。不同数据集和模型的训练超参数(如学习率、权重衰减、批大小、训练轮数等)设置不同,且针对不同任务的模型,其训练细节也有所差异。
- 图像分类
- 数据集与模型选择:在 ImageNet1K 和 CIFAR-100 数据集上评估方法性能。ImageNet1K 上选用 DeiT、Swin、CeiT、T2T-ViT 等模型;CIFAR-100 上选用 ViT-Lite 和 T2T-ViT-7 模型。
- 实验结果:MPVG 在各模型上均有性能提升。在ImageNet1K 上,DeiT-Ti 的 Top-1 准确率从 72.14% 提升到 73.51%,DeiT-S 从 79.81% 提升到 80.61% 等;在 CIFAR-100上,ViT-Lite 从 74.90% 提升到 76.87%,T2T-ViT-7 从 83.22% 提升到 83.51%。且 MPVG 在所有情况下均优于现有方法,与 PVG 相比也展现出明显优势。
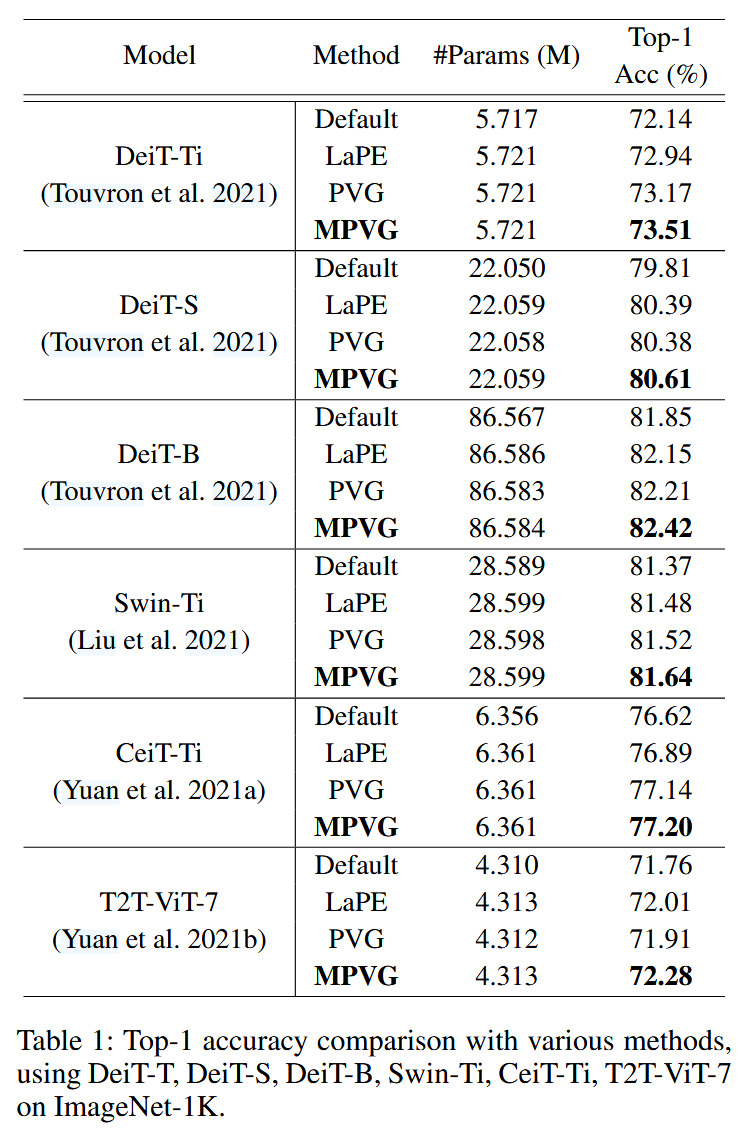
表1:在 ImageNet-1K 数据集上,使用 DeiT-T、DeiT-S、DeiT-B、Swin-Ti、CeiT-Ti、T2T-ViT-7 模型,对多种方法的 Top-1 准确率进行比较。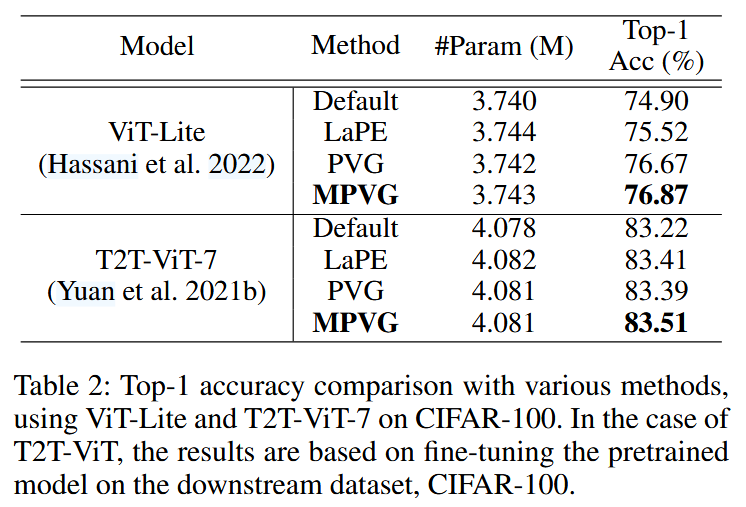
表2:在 CIFAR-100 数据集上,使用 ViT-Lite 和 T2T-ViT-7 模型,对多种方法的 Top-1 准确率进行比较。对于 T2T-ViT 模型,其结果是基于在下游数据集 CIFAR-100 上对预训练模型进行微调得到的。
- 目标检测
- 数据集与模型选择:在 COCO 2017 数据集上,基于 Mask RCNN 框架选择 ViTAdapter-Ti 模型进行评估。
- 实验结果:MPVG 相较于默认设置,box AP 提高了0.6,mask AP 提高了0.5;相较于 PVG,box AP 提高了0.5,mask AP 提高了0.4,证明了 MPVG 在目标检测任务上的有效性。
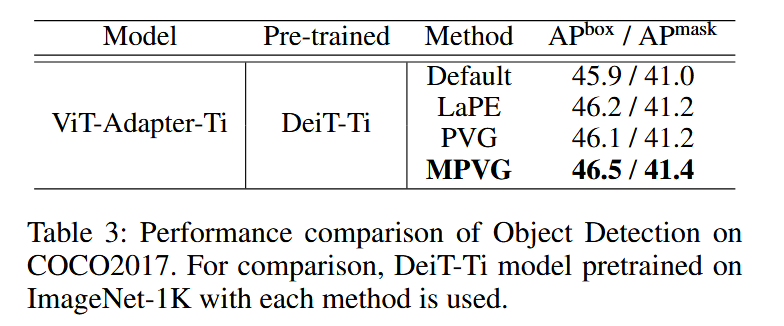
表3:在 COCO2017 数据集上目标检测的性能对比。为作比较,使用了在 ImageNet-1K 上用每种方法预训练的 DeiT-Ti 模型。
- 语义分割
- 数据集与模型选择:在 ADE20K 数据集上,基于 UperNet 框架选择 ViT-AdapterTi 模型进行评估。
- 实验结果:MPVG 相比默认设置,平均交并比(mIoU)提高了1.14;相比 PVG, mIoU 提高了0.62,表明 MPVG 在语义分割任务上同样表现出色。

表4:在 ADE20K 数据集上语义分割的性能对比。为进行对比,采用了在 ImageNet-1K 上用各方法预训练的 DeiT-Ti 模型。
- 分析
- PE 的作用验证:通过实验证明了 MPVG 的有效性,验证了假设,即 PE 在层状结构中不仅提供位置信息,还起到平衡 token 嵌入的作用,且这种平衡作用对视觉 Transformer 性能影响显著。
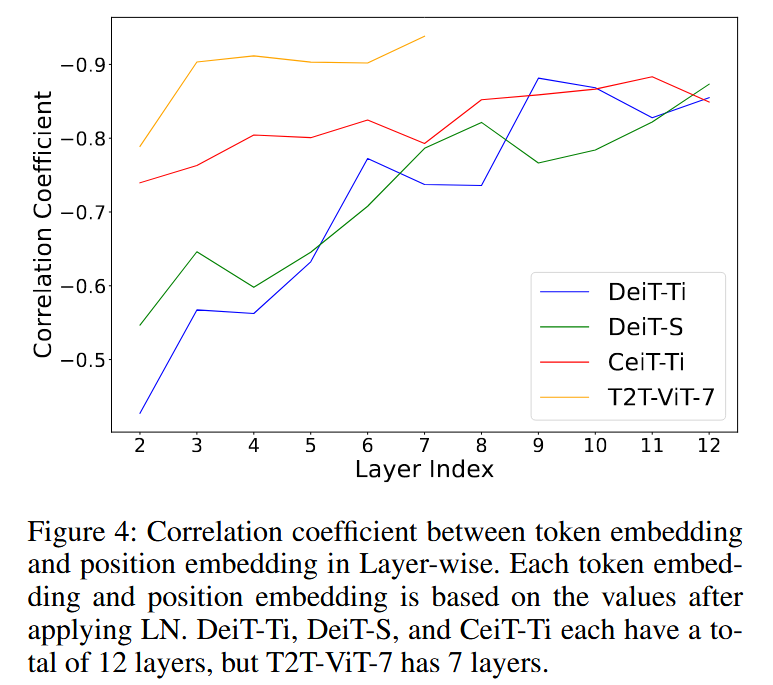
图4:层状结构中 token 嵌入与位置嵌入之间的相关系数。每个 token 嵌入和位置嵌入均基于应用层归一化(LN)后的数值。DeiT-Ti、DeiT-S 和 CeiT-Ti 均总共有 12 层,而 T2T-ViT-7 有 7 层。 - 对比实验分析:对比 PVG 和 MPVG 发现,PE的平衡作用对模型性能有重要影响。在层状结构中,随着层数加深,token 嵌入和位置嵌入方向逐渐相反,维持 PE 的平衡方向对模型有益。
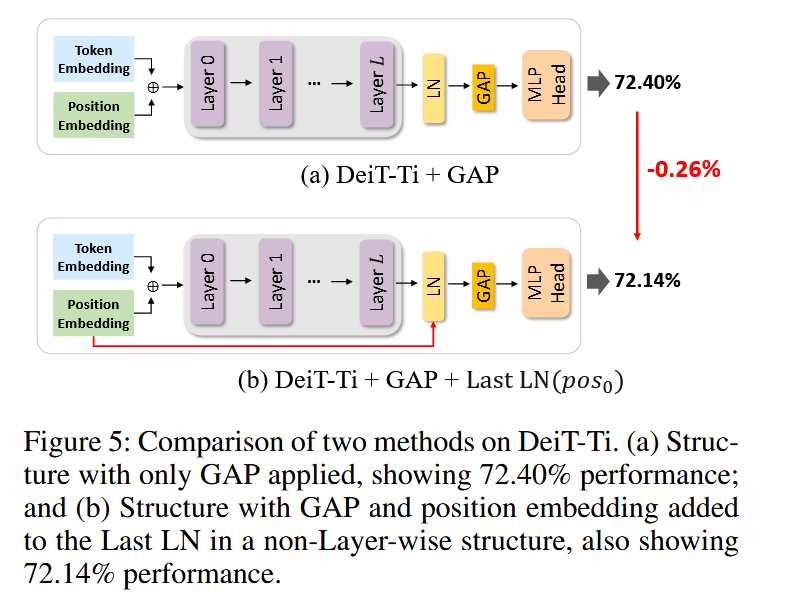
图5:基于 DeiT-Ti 的两种方法的比较。(a) 仅应用全局平均池化(GAP)的结构,性能为 72.40%;(b) 在非层状结构中,将 GAP 和位置嵌入添加到最后一层归一化(Last LN)的结构,性能为 72.14%。
- PE 的作用验证:通过实验证明了 MPVG 的有效性,验证了假设,即 PE 在层状结构中不仅提供位置信息,还起到平衡 token 嵌入的作用,且这种平衡作用对视觉 Transformer 性能影响显著。
- 消融研究
- PE 值对 Last LN 的影响:研究不同 PE 值传递到 Last LN 对模型性能的影响,实验表明无论传递何种 PE 值,MPVG 均优于 PVG,采用 p o s 0 pos_{0} pos0 时 MPVG 性能最佳,说明将 PE 传递到 Last LN 对视觉 Transformer 性能有积极影响。
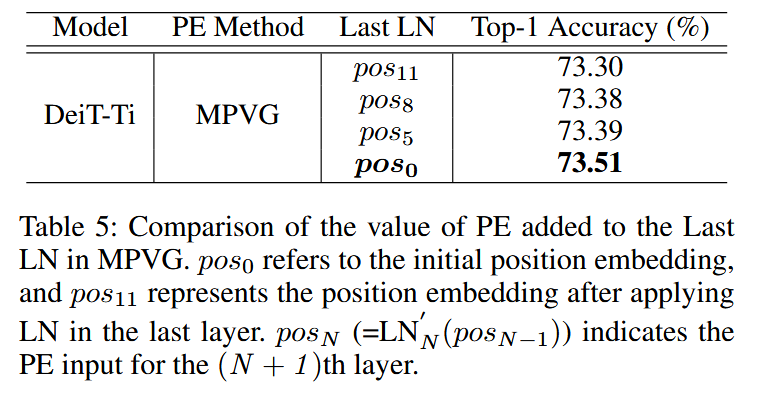
表5:MPVG 中添加到最后一层归一化(Last LN)的位置嵌入(PE)值的比较。 p o s 0 pos_0 pos0 指的是初始位置嵌入, p o s 11 pos_{11} pos11 表示在最后一层应用层归一化(LN)后的位置嵌入。 p o s N pos_N posN( = L N N ′ ( p o s N − 1 ) =LN_{N}'(pos_{N - 1}) =LNN′(posN−1))表示第 ( N + 1 ) (N + 1) (N+1) 层的 PE 输入。 - MPVG结构差异影响:对 MPVG 的架构结构进行实验,对比不同结构设置(是否包含层 0、PE传递方式、是否分层等)对性能的影响。结果表明排除层 0 传递 PE、在进入层0前添加PE且采用分层结构时,MPVG 性能最优 。
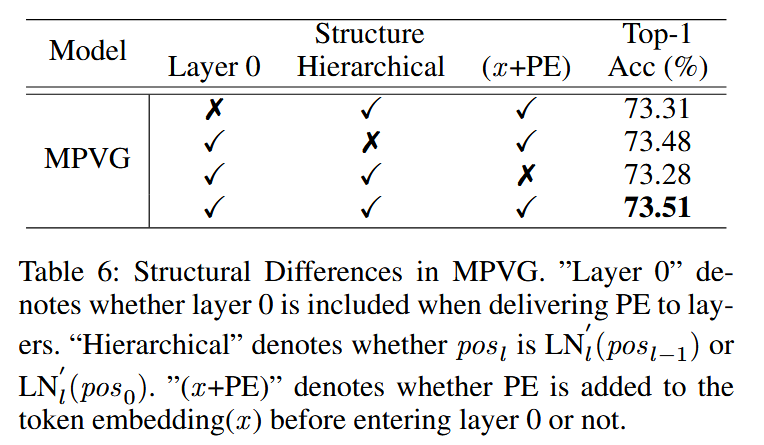
表6:MPVG 中的结构差异。“Layer 0” 表示在向各层传递位置嵌入(PE)时是否包含第 0层。“Hierarchical” 表示 p o s l pos _{l} posl 是 L N l ′ ( p o s l − 1 ) LN_{l}'(pos_{l-1}) LNl′(posl−1) 还是 L N l ′ ( p o s 0 ) LN_{l}'(pos_{0}) LNl′(pos0),“( x x x + PE)” 表示在进入第 0 层之前是否将 PE 添加到 token 嵌入 ( x x x) 中。
- PE 值对 Last LN 的影响:研究不同 PE 值传递到 Last LN 对模型性能的影响,实验表明无论传递何种 PE 值,MPVG 均优于 PVG,采用 p o s 0 pos_{0} pos0 时 MPVG 性能最佳,说明将 PE 传递到 Last LN 对视觉 Transformer 性能有积极影响。
结论-Conclusion
该部分总结了研究成果、MPVG 方法的优势与局限性,并对未来研究方向提出展望,具体如下:
- 研究成果总结:揭示了在使用 GAP 方法的视觉 Transformer 中,位置嵌入(PE)具有额外作用。在层状结构里,PE 对 token 嵌入值有平衡效果,维持这种由 PE 带来的方向平衡对视觉 Transformer 有益。
- MPVG 方法优势:基于上述发现,提出 MPVG 方法。该方法利用层状结构中 PE 的特性,将 PE 传递到最后一层的层归一化(Last LN),有效最大化了 PE 的作用。通过大量实验表明,MPVG 在多种视觉 Transformer 模型上的图像分类、目标检测和语义分割等任务中,性能均优于以往方法。
- MPVG 方法局限性:MPVG 存在与类 token 方法不兼容的问题。由于在采用 GAP 方法的层状结构研究中发现,GAP 和类 token 方法在处理位置嵌入与层归一化等方面存在差异,导致 MPVG 目前无法与类 token 方法配合使用。
- 未来研究展望:鉴于 MPVG 的局限性,未来研究将围绕进一步探索其更广泛的适用性展开。同时,深入研究 PE 平衡作用的更多潜在影响,挖掘其在不同视觉任务和模型架构中的作用机制,以推动视觉 Transformer 领域的发展 。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)