Github-LightRAG:简单快速的检索增强生成框架
LightRAG 是一个简单而快速的检索增强生成(RAG)框架,由香港大学数据科学实验室开发。该项目通过创新的知识图谱技术,显著提升了传统RAG系统在处理复杂查询和全局知识理解方面的能力。
Github-LightRAG:简单快速的检索增强生成框架
https://github.com/HKUDS/LightRAG
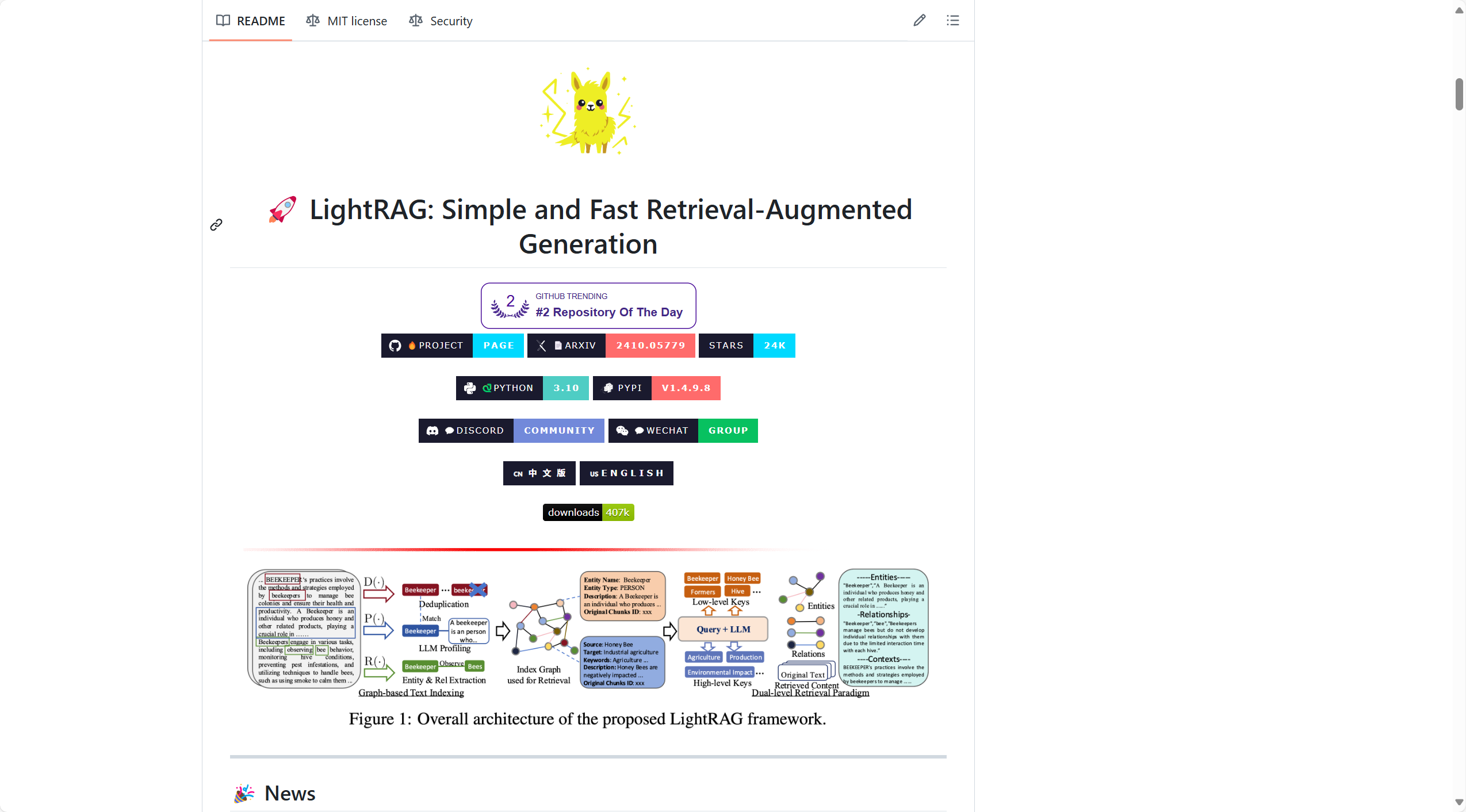
1. 项目概述
LightRAG 是一个简单而快速的检索增强生成(RAG)框架,由香港大学数据科学实验室开发。该项目通过创新的知识图谱技术,显著提升了传统RAG系统在处理复杂查询和全局知识理解方面的能力。
2. 主要功能与目的
核心功能
-
智能文档索引:自动从文档中提取实体和关系,构建知识图谱
-
多模式检索:支持本地、全局、混合和混合检索模式
-
知识图谱管理:完整的实体和关系创建、编辑、合并、删除功能
-
多模态支持:与RAG-Anything集成,支持文本、图像、表格、公式处理
-
可视化界面:提供Web UI进行文档管理和知识图谱可视化
设计目标
解决传统RAG系统在处理需要全局理解的复杂查询时的局限性,提供更智能、更全面的信息检索和生成能力。
3. 技术栈
主要技术
-
编程语言:Python 3.10+
-
核心框架:异步架构设计
-
向量数据库:支持多种后端(NanoVector、PGVector、Milvus、Faiss等)
-
图数据库:NetworkX、Neo4J、Memgraph、PostgreSQL with AGE
-
LLM集成:OpenAI、Hugging Face、Ollama、LlamaIndex
-
部署工具:Docker、uv包管理器
4. 项目结构概览
LightRAG/
├── lightrag/ # 核心代码
│ ├── llm/ # LLM集成模块
│ ├── storage/ # 存储后端
│ └── api/ # API服务
├── lightrag_webui/ # Web界面
├── examples/ # 使用示例
├── reproduce/ # 复现实验代码
├── docs/ # 文档
└── tests/ # 测试代码
5. 核心使用指南
快速开始
import asyncio
from lightrag import LightRAG, QueryParam
from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed
async def main():
# 初始化RAG实例
rag = LightRAG(
working_dir="./rag_storage",
embedding_func=openai_embed,
llm_model_func=gpt_4o_mini_complete,
)
# 必须初始化存储
await rag.initialize_storages()
# 插入文档
await rag.ainsert("您的文档内容")
# 执行查询
result = await rag.aquery(
"查询问题",
param=QueryParam(mode="hybrid")
)
print(result)
asyncio.run(main())
关键配置参数
-
LLM要求:推荐32B+参数,64KB上下文长度
-
嵌入模型:BAAI/bge-m3、text-embedding-3-large等
-
重排模型:BAAI/bge-reranker-v2-m3(显著提升性能)
检索模式
-
local:上下文相关信息
-
global:全局知识利用
-
hybrid:本地+全局混合
-
mix:知识图谱+向量检索
-
naive:基础搜索
6. 创新特点
🎯 核心创新
-
双级检索机制:结合向量检索和知识图谱检索
-
智能实体提取:自动从文档中构建知识图谱
-
动态知识管理:支持实体合并、关系编辑等操作
-
多存储支持:灵活的存储后端选择
🔧 技术亮点
-
高性能:消除处理瓶颈,支持大规模数据集
-
可扩展性:模块化设计,易于扩展新功能
-
生产就绪:支持多种企业级数据库
-
观测性:集成Langfuse进行LLM调用追踪
7. 应用场景
📊 适用领域
-
企业知识管理:构建企业级知识库和智能问答系统
-
学术研究:文献分析和知识发现
-
客户服务:智能客服和知识检索
-
内容创作:基于文档的内容生成和分析
-
教育培训:个性化学习助手
🚀 实际用例
-
文档智能问答系统
-
企业知识图谱构建
-
多模态内容处理
-
长视频内容理解(通过VideoRAG扩展)
8. 生态系统
LightRAG拥有完整的生态系统:
-
RAG-Anything:多模态文档处理
-
VideoRAG:极长上下文视频理解
-
MiniRAG:极简RAG实现
9. 性能表现
根据项目评估,LightRAG在多个领域均显著优于传统RAG方法:
| 领域 | 传统RAG | LightRAG |
|---|---|---|
| 法律文档 | 15.2% | 84.8% |
| 农业领域 | 32.4% | 67.6% |
| 计算机科学 | 38.8% | 61.2% |
总结
LightRAG代表了下一代RAG系统的发展方向,通过巧妙结合知识图谱技术和传统检索方法,在保持简单易用的同时,显著提升了复杂查询的处理能力。其模块化设计、丰富的功能集和强大的性能表现,使其成为构建智能知识管理系统的理想选择。
项目核心价值:让复杂的知识检索变得简单高效,为企业和开发者提供强大的AI驱动知识管理解决方案。
⭐ 如果这个项目对您有帮助,请给项目一个star支持开发者的工作!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)