一个“苍穹外卖”项目,究竟能覆盖多少Java后端知识点?
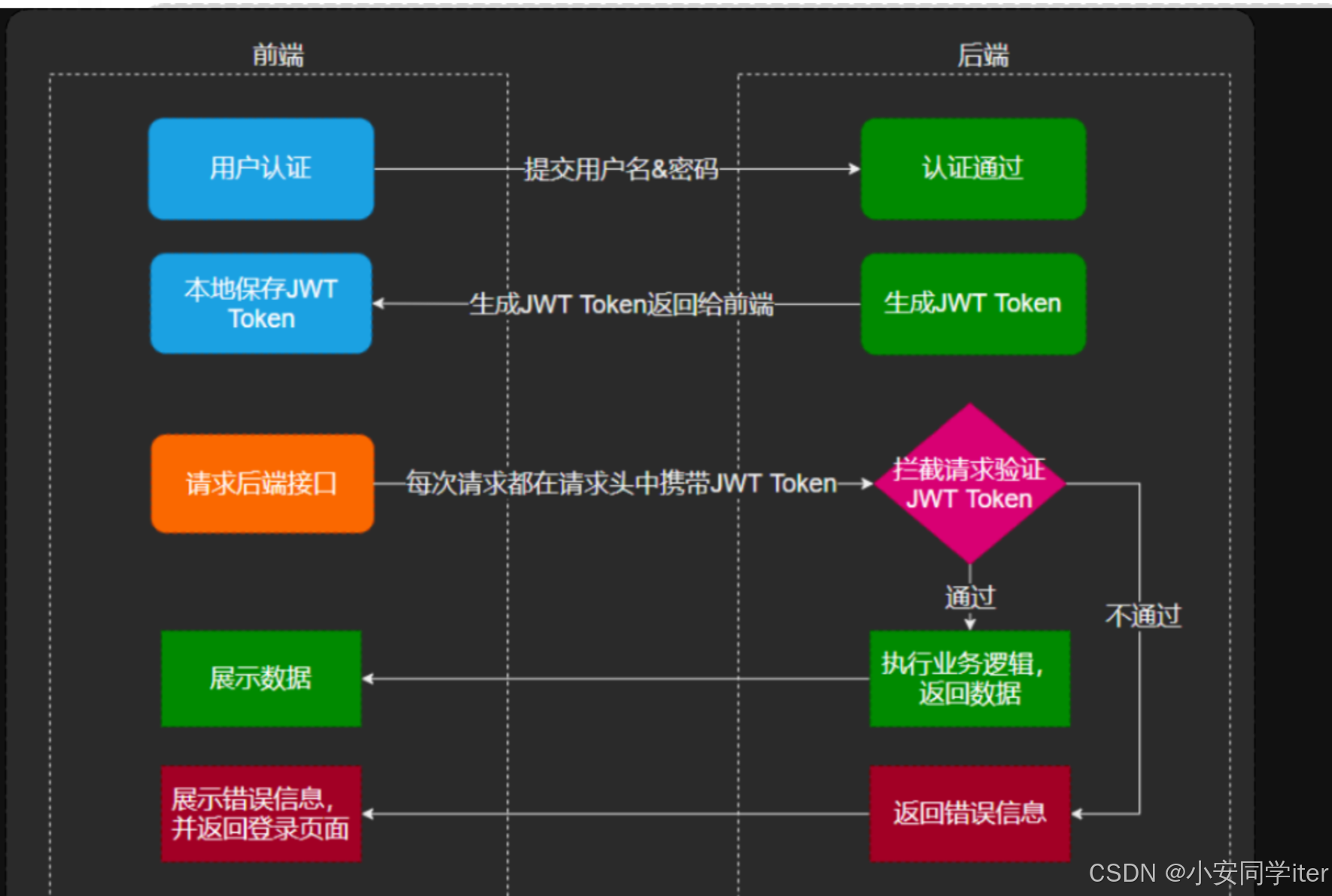
再说一下Token的实际运作过程,我们在实际的业务当中会出现登录的操作,在后端服务器我们接收客户端请求,将传递的登录信息反序列化,服务器会验证登录信息是否正确,如果正确就会生成Token令牌,返回给前端,后端无需存储Token,只需存储密钥即可,在后续操作当中服务器会编写拦截器在请求之前拦截,同时对Token令牌进行解析验证,如果验证成功便可执行业务代码。ThreadLocal是Java中的一个线
目录
1 登录认证
技术点:JWT令牌技术(JSON Web Token)
JWT(JSON Web Token)是一种令牌技术,主要由三部分组成:Header头部、Payload载荷和Signature签名。Header头部存储令牌的类型(如JWT)和使用的加密算法(如HS256)。Payload载荷包含具体信息,如用户身份、权限、过期时间等声明(Claims)。Signature签名通过加密算法对Header和Payload进行签名,用于验证数据完整性和发行者身份。
在实际业务中,用户登录时,后端服务器接收客户端请求并解析传递的登录信息,验证用户名和密码是否正确。若验证成功,服务器生成JWT令牌返回给前端。后端无需存储Token,只需保存密钥(Secret Key)。后续请求时,服务器通过拦截器在请求前拦截,提取JWT并进行解析与验证:首先检查签名是否有效(防止篡改),再校验Payload中的声明(如是否过期、权限是否有效)。验证通过后,放行请求并执行业务逻辑。
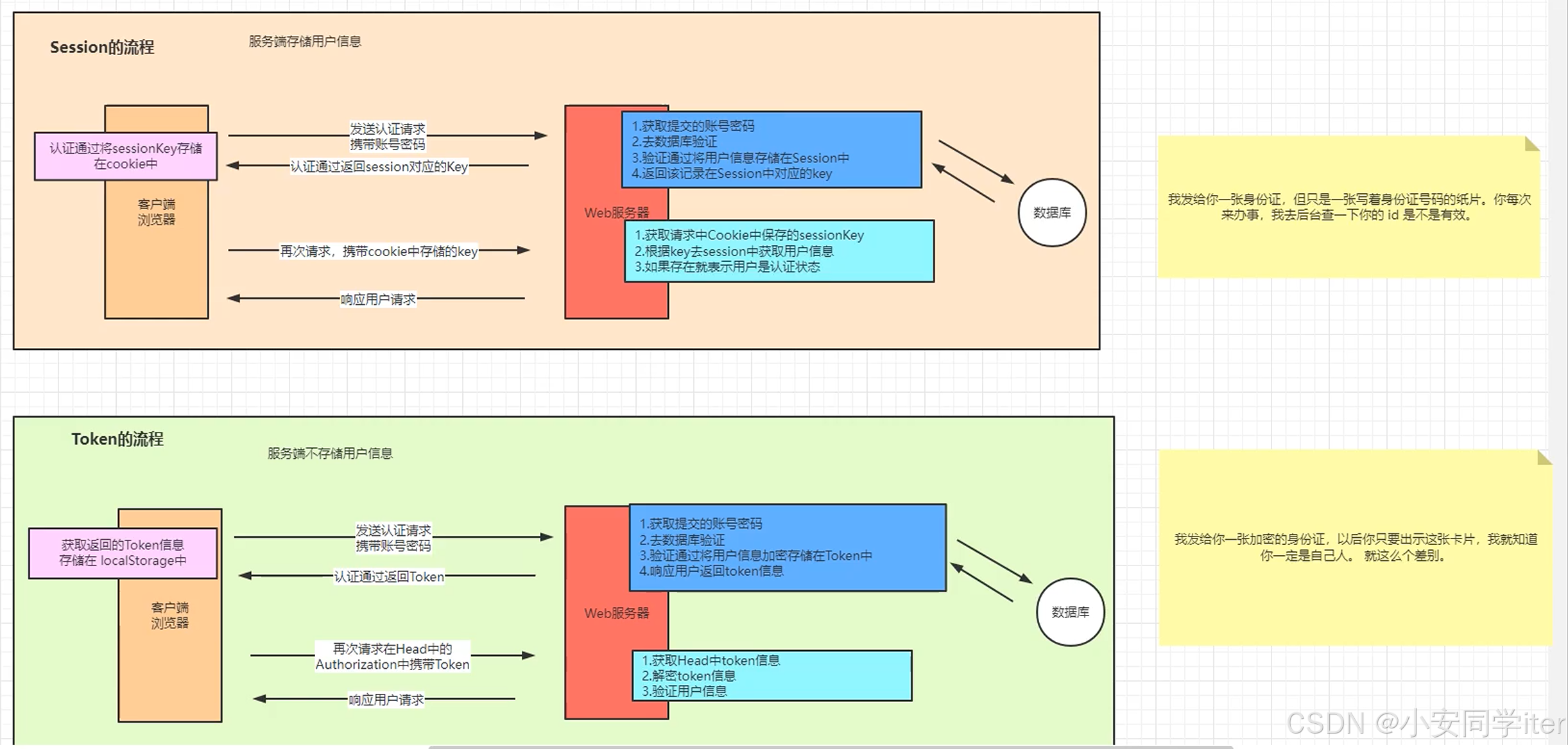
Session与Token的对比
2 分页查询
PageHelper是一个基于MyBatis的分页插件,通过拦截MyBatis的执行器实现分页功能。
当调用 PageHelper.startPage() 设置分页参数后,MyBatis 会通过其拦截器机制自动触发分页逻辑,动态修改后续的 SQL 语句以实现分页。
分页参数通过 ThreadLocal 存储到当前线程的上下文中(PageContext),确保同一线程内的后续操作可获取这些参数。PageHelper 在处理完当前 SQL 后,自动清除 ThreadLocal 中的分页参数,因此同一线程后续的查询不会被分页,除非再次调用 startPage()。
/**
* 分页查询套餐
*
* @param setmealPageQueryDTO
* @return
*/
@Override
public PageResult pageQuery(SetmealPageQueryDTO setmealPageQueryDTO) {
int pageNum = setmealPageQueryDTO.getPage();
int pageSize = setmealPageQueryDTO.getPageSize();
PageHelper.startPage(pageNum, pageSize);
Page<SetmealVO> page = setmealMapper.pageQuery(setmealPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}-- 原始SQL
SELECT * FROM table;
-- 重写后(MySQL示例)
SELECT * FROM table LIMIT offset, pageSize;3 MVC当中的参数注解
1 @RequestBoby:绑定HTTP请求体,反序列化为java对象。-(JSON,XML)
2 @RequestParam:绑定查询参数。(URL后-问号传参,参数用 ? 分隔,参数间用 & 连接。)
3 @PathVariable:绑定URL路径变量。(URL中-路径传参,参数用用 {} 包裹,/连接。)
4 @RequestHeader :绑定HTTP请求头。
5 @CookieValue:绑定Cookie
4 ThreadLocal
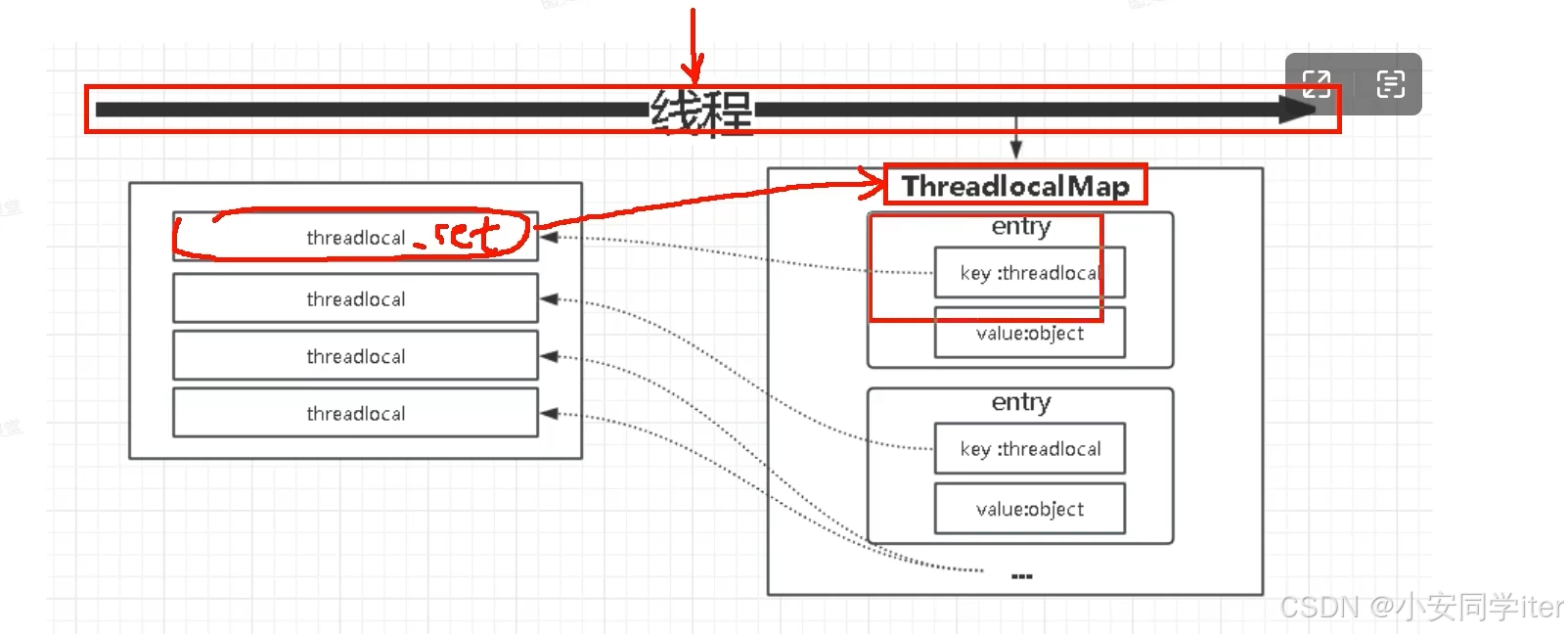
ThreadLocal是Java中的一个线程变量,它可以为每个线程提供一个独立的变量副本。ThreadLocal实例是共享的,但每个线程通过它访问的是自己的ThreadLocalMap中的值。
ThreadLocal的主要作用是在多线程的环境下提供线程安全的变量访问。它常用于解决线程间数据共享的问题,特别是在并发编程中,当多个线程需要使用同一个变量时,可以使用ThreadLocal确保每个线程访问的都是自己的变量副本,从而避免了线程安全问题。
ThreadLocal底层是通过ThreadLocalMap来实现的,每一个Thread(线程)对象中都存在一个ThreadLocalMap,Map的key为ThreadLocal对象,Map的value为需要缓存的值。
static修饰的ThreadLocal对象属于类级别,在JVM的整个生命周期中仅初始化一次,后续所有的线程通过BaseContext.threadLocal访问同一个ThreadLocal实例,但每个线程的变量副本独立存储,避免重复创建对象。
内存泄漏问题:当ThreadLocal对象使用完之后,应该将Entry对象(即key和value)回收。而线程对象是通过强引用指向ThreadLocalMap,ThreadLocalMap也是通过强引用指向Entry对象。在Entry中,key是弱引用,会触发自动回收机制,但value是强引用不会自动回收,最终导致Entry整体无法被回收机制回收。最终导致线程池中的线程因ThreadLocalMap未清理而出现内存泄漏。解决方法是手动调用ThreadLocal的remove()方法,清除Entry对象。
package com.sky.context;
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {threadLocal.set(id);}
public static Long getCurrentId() {return threadLocal.get();}
public static void removeCurrentId() {threadLocal.remove();}
}
示例:
public class ThreadLocalExample {
// 定义一个ThreadLocal变量
private static final ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
// 线程A设置值
Thread threadA = new Thread(() -> {
threadLocal.set(100); // 线程A的值为100
System.out.println("线程A的值:" + threadLocal.get()); // 输出100
});
// 线程B尝试获取值
Thread threadB = new Thread(() -> {
System.out.println("线程B的值:" + threadLocal.get()); // 输出null(未设置时默认值)
threadLocal.set(200); // 线程B的值为200
System.out.println("线程B的值:" + threadLocal.get()); // 输出200
});
threadA.start();
threadB.start();
}
}项目当中便可使用这个来存储用户的id值其可全局获取,并且不需要多次实例化对象,在jwt校验结束便可设置。
5 @JSONFormat
在业务需求当中可能会出现前端给我们传递过来的时间参数,其格式不一定符合我们变量的格式。
因此我们需要对前端的时间参数进行格式化,将前端传递的参数指定为pattern当中的参数格式。
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;6 基于注解和AOP的公共字段填充
在业务开发中,由于存在大量数据表且字段重叠较多,我们可以使用AOP技术结合注解技术对公共字段进行填充,从而减少代码的冗杂性。
首先,我们需要创建一个自定义注解,用于标记需要自动填充公共字段的方法。
注解:AutoFill
注解的目的作用在Mapper业务层,对那些需要对数据库操作的进行字段填充。
package com.sky.annotation;
import com.sky.enumeration.OperationType;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 自定义注解,用于标识需要自动填充的字段
*/
// 标识在方法上
@Target(ElementType.METHOD)
// 标识在运行时
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoFill {
//数据库操作类型 UPDATE INSERT
OperationType value();
}
然后,AOP切面拦截这些注解的方法
切面:AutoFillAspect
使用的是前置通知,目标方法执行前自动调用,拦截带有@AutoFill的方法,业务当中通过反射的思想进行字段赋值。
package com.sky.aspect;
import com.sky.annotation.AutoFill;
import com.sky.constant.AutoFillConstant;
import com.sky.context.BaseContext;
import com.sky.enumeration.OperationType;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
/**
* 自定义切面,用于自动填充公共字段处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点表达式 com.sky.mapper 包下的所有类中的所有方法并且有 @AutoFill 注解的方法
*/
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut() {
}
/**
* 前置通知,在目标方法执行前执行
*/
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) {
log.info("开始进行公共字段自动填充...");
// 通过方法签名获取方法上的注解
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class); // 关键修改
if (autoFill == null) {
log.info("当前方法没有 @AutoFill 注解,不需要自动填充");
return;
}
OperationType operationType = autoFill.value();//数据库操作类型
//获取当前杯拦截的方法的参数--实体对象
Object[] args = joinPoint.getArgs();
if (args == null || args.length == 0) {
log.info("当前方法没有参数,不需要自动填充");
return;
}
Object entity = args[0];
log.info("当前自动填充的实体对象:{}", entity.toString());
//准备赋值的数据
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
log.info("当前操作的用户id:{}", currentId);
//根据当前不同的操作类型,为对应的实体对象通过反射来赋值
if (operationType == OperationType.INSERT) {
//四个公共字段:createTime、createUser、updateTime、updateUser赋值
try {
//获取当前实体类中的对应方法(使用本地的常量方法名)
Method createTimeMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method createUserMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method updateTimeMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method updateUserMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为实体对象赋值
createTimeMethod.invoke(entity, now);
createUserMethod.invoke(entity, currentId);
updateTimeMethod.invoke(entity, now);
updateUserMethod.invoke(entity, currentId);
log.info("为实体类 {} 赋值成功", entity);
} catch (Exception e) {
e.printStackTrace();
}
} else if (operationType == OperationType.UPDATE) {
try {
//两个公共字段:updateTime、updateUser赋值
Method updateTimeMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method updateUserMethod = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
updateTimeMethod.invoke(entity, now);
updateUserMethod.invoke(entity, currentId);
log.info("为实体类 {} 赋值成功", entity);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
示例:(这段代码就实现了对公共字段的填充)
/**
* 新增套餐
*
* @param setmeal
*/
@AutoFill(OperationType.INSERT)
void insert(Setmeal setmeal);7 分页操作的实现思路
1 首先存在一个PageEntity的类
@Data
@EqualsAndHashCode(callSuper = false)// 不包含父类字段的比较
@Accessors(chain = true)// 支持链式调用
public class PageEntity<T> extends Page implements Serializable {
private static final long serialVersionUID = 6911873155210956319L;
/**
* 查询实体
*/
@Valid
private T entity;
/**
* 当前页
*/
private long current = 1;
/**
* 分页条数
*/
private long size = 20;
}这样定义的好处在于将当前也与分页条数都进行封装,统一声明了,否则的话可能会出现:
public R page(
@RequestParam(defaultValue = "1") int current,
@RequestParam(defaultValue = "20") int size,
@RequestBody QueryDTO query)
导致代码会十分的繁琐。
2 controller层请求
@SysLog(value = "machine_capacity_search")
@PreAuthorize("@pms.hasPermission('machine_capacity_search')")
@PostMapping("/page")
@Operation(summary = "分页查询机台产能信息", tags = "传入equipmentYield")
public R getEquipmentYieldPage(@RequestBody PageEntity<EquipmentYieldDTO> pageEntity){
return R.ok(equipmentYieldService.EquipmentYieldPage(pageEntity));
}在我自身定义好了PageEntity之后,在前端进行传递时,核心就是传递这个,当然这里的current与size是存在默认值的,如果不去进行声明只传递需要去进行分页查询的实体参数也可以。
{
"current": 1,
"size": 20,
"entity": {
// 具体的查询条件,对应 EquipmentYieldDTO
"comBoBokSite": "SITE001",
"comBoBokPLine": "LINE_A",
"equipmentCode": "EQ001",
"startTime": "2024-01-01 00:00:00",
"endTime": "2024-01-31 23:59:59"
}
}3 接下来就到了实现类这一层
这里去声明Page(借助当前页数以及分页的数量)
获取对应的实体,传递给Mapper层去进行查询。
@Override
public IPage<EquipmentYieldDTO> EquipmentYieldPage(PageEntity<EquipmentYieldDTO> pageEntity) {
Page<EquipmentYieldDTO> page = new Page<>(pageEntity.getCurrent(), pageEntity.getSize());
EquipmentYieldDTO equipmentYield = pageEntity.getEntity();
return baseMapper.selectEquipmentYieldPage(page, equipmentYield);
}4 到达数据库的Mapper层
IPage<EquipmentYieldDTO> selectEquipmentYieldPage(Page page, @Param("equipmentYield") EquipmentYieldDTO equipmentYield);这里需要注意的就是Page这个参数必须放在第一个位置,这样Mybatis-plus当中的自动分页就会在后续的sql当中自动去进行limit进行分页操作。
// 假设:current = 2, size = 10
// 你写的 SQL:
SELECT * FROM equipment_yield WHERE site_code = 'SITE001' ORDER BY production_date DESC
// MyBatis-Plus 自动转换后的 SQL:
SELECT COUNT(*) FROM equipment_yield WHERE site_code = 'SITE001' -- 先查总数
SELECT * FROM equipment_yield WHERE site_code = 'SITE001' ORDER BY production_date DESC LIMIT 10 OFFSET 10 -- 再查分页数据8 返回R的统一定义
import java.io.Serializable;
public class R<T> implements Serializable {
private static final long serialVersionUID = 1L;
private int code;
private String msg;
private T data;
// 成功响应
public static <T> R<T> ok() {
return new R<>(CommonConstants.SUCCESS, null, null);
}
public static <T> R<T> ok(T data) {
return new R<>(CommonConstants.SUCCESS, null, data);
}
public static <T> R<T> ok(T data, String msg) {
return new R<>(CommonConstants.SUCCESS, msg, data);
}
public static <T> R<T> okMsg(String msg) {
return new R<>(CommonConstants.SUCCESS, msg, null);
}
// 失败响应
public static <T> R<T> failed() {
return new R<>(CommonConstants.FAIL, null, null);
}
public static <T> R<T> failed(String msg) {
return new R<>(CommonConstants.FAIL, msg, null);
}
public static <T> R<T> failed(T data) {
return new R<>(CommonConstants.FAIL, null, data);
}
public static <T> R<T> failed(T data, String msg) {
return new R<>(CommonConstants.FAIL, msg, data);
}
public boolean isOk() {
return this.code == CommonConstants.SUCCESS;
}
public R() {
}
public R(int code, String msg, T data) {
this.code = code;
this.msg = msg;
this.data = data;
}
// Getters and Setters
public int getCode() {
return code;
}
public R<T> setCode(int code) {
this.code = code;
return this;
}
public String getMsg() {
return msg;
}
public R<T> setMsg(String msg) {
this.msg = msg;
return this;
}
public T getData() {
return data;
}
public R<T> setData(T data) {
this.data = data;
return this;
}
@Override
public String toString() {
return "R(code=" + code + ", msg=" + msg + ", data=" + data + ")";
}
}返回格式
{
"code": 0,
"msg": null,
"data": "导入完成,总共处理 32899 条数据,其中 400 条数据导入失败,已自动导出失败数据",
"ok": true
}
介绍一下这个
public boolean isOk() {
return this.code == CommonConstants.SUCCESS;
}我们写的
R<T>是 Java 对象,最终返回给前端的是 JSON 字符串(比如你给出的{"code":0, "msg":null, "data":"...", "ok":true})。这个转换过程叫 “JSON 序列化”(比如用 Jackson、Fastjson 等工具)。JSON 序列化工具会把 Java 对象的 字段 和 getter 方法 转换为 JSON 的键值对:
- 对于字段(如
code、msg、data):直接把字段名作为 JSON 的键,字段值作为 JSON 的值。- 对于
isXXX()形式的方法(比如isOk()):序列化工具会把它当作一个 “属性” 处理,去掉前面的is,剩下的部分作为 JSON 的键(即ok),方法的返回值(true/false)作为 JSON 的值。
// 前端拿到后端返回的 R 对象(序列化后传输过来的)
const result = 后端接口返回的数据;
// 调用 isOk() 判断,逻辑清晰,不用记后端的 code 是200还是1
if (result.isOk()) {
// 成功:渲染数据
renderData(result.data);
} else {
// 失败:弹窗提示
alert(result.msg);
}9 全局异常处理器
对于全局异常处理器,其在使用过程当中主要是对于那些异常需要较多进行返回的场景,通过自定义的异常信息枚举类,从而将代码的可读性增强。同时呢,还存在一个全局兜底的一个处理,避免出现报错异常信息,影响实际的用户体验。在实际开发过程当中,对于一些比较特殊的异常返回信息,更推荐去使用局部的处理,代码也更加灵活,当然是需要根据具体的情况进行判断。
1 首先呢定义一个业务异常信息的枚举类
后续如果需要传参直接使用BizExceptionEnum.CESHI这种形式进行调用即可
package com.ax.demo001.enumeration;
import lombok.Getter;
/**
* @author ABC
*/
@Getter
public enum BizExceptionEnum {
ORDER_NOT_EXIST(10001, "订单不存在"),
ORDER_STATUS_ERROR(10002, "订单状态错误"),
ORDER_PAID(10003, "订单已支付"),
ORDER_CANCEL_FAIL(10004, "订单取消失败"),
ORDER_PAY_FAIL(10005, "订单支付失败"),
OTHER_ERROR(40001, "其他错误"),
CESHI(40002, "算数运算错误测试"),
;
private final int code;
private final String msg;
BizExceptionEnum(int code, String msg) {
this.code = code;
this.msg = msg;
}
}然后定义一个自定义的异常类(继承自RuntimeException)
构造方法需要定义为BizException(BizExceptionEnum bizExceptionEnum)这种形式,便于后续的调用,同时还需要重写父类的构造方法。
package com.ax.demo001.exception;
import com.ax.demo001.enumeration.BizExceptionEnum;
import lombok.Getter;
/**
* 自定义业务异常类
* @author ax
*/
@Getter
public class BizException extends RuntimeException{
//业务异常码,业务异常原因
private final Integer code;
private final String msg;
public BizException(Integer code, String msg) {
super(msg);
this.code = code;
this.msg = msg;
}
public BizException(BizExceptionEnum bizExceptionEnum) {
super(bizExceptionEnum.getMsg());
this.code = bizExceptionEnum.getCode();
this.msg = bizExceptionEnum.getMsg();
}
}全局异常类的定义
全局异常类当中需要包含 @ExceptionHandler(Throwable.class)从而首先统一处理,同时呢还可以再代码当中去加入自定义的异常(BizException),以及需要在全局异常处理器当中进行声明的异常类。
import com.ax.demo001.exception.BizException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
/**
* @author ax
*/
@RestControllerAdvice//合成注解
public class GlobalExceptionHandler {
/**
* 统一处理算术异常
*
* @param e
* @return
*/
@ExceptionHandler(ArithmeticException.class)
public R handleArithmeticException(ArithmeticException e) {
return R.failed(500, "算数运算符异常" + e.getMessage());
}
/**
* 统一处理业务异常
*
* @param e
* @return
*/
@ExceptionHandler(BizException.class)
public R handleBizException(BizException e) {
return R.failed(e.getCode(), e.getMessage());
}
/**
* 统一处理其他异常
*
* @param e
* @return
*/
@ExceptionHandler(Throwable.class)
public R handleThrowable(Throwable e) {
return R.failed(500, "全局异常捕获" + e.getMessage());
}
}举个例子说明一下
这里仅做测试使用
controller层:
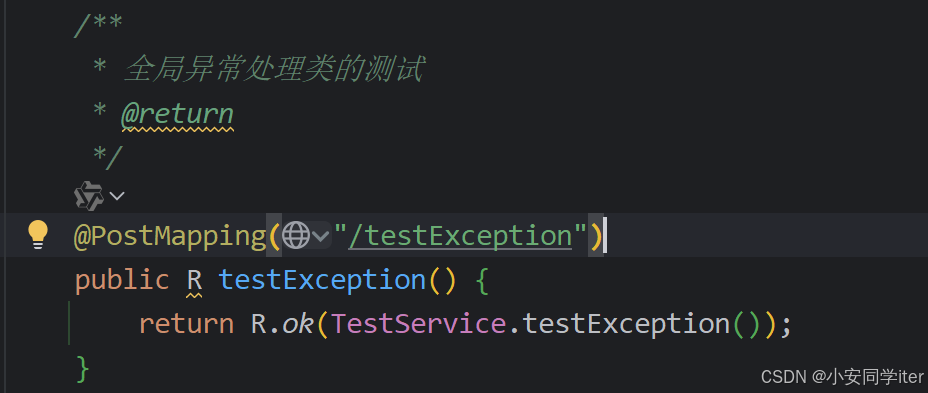
实现类:

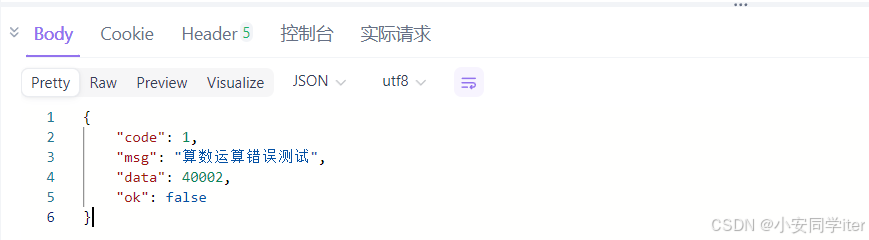
最后的调用返回结果:
个人感悟
在初次接触项目时第一感觉就是觉得太复杂了,当时看见那么多的类文件,觉得自己肯定学不好也学不会,但是不断的接触才发现,是有其自己的一套方法,也是可以接受的,也能跟着照葫芦画瓢,其三层架构十分具有条理性的将代码进行分割将业务代码进行拆分,在这个项目当中解除了后端方面对基础业务CRUD的实现,同时也有一些常见开发规范的学习,以及小程序端的开发,实现前后端的联调实现业务的完整性,但是学习的过程也是有不足的很多实现的过程都是跟着老师进行开发的很多都没有由自己开发实现,自己单独分析接口文档进行接口编写的能力还是有所欠缺。在学习过程中也发现自己之前的遗漏点,也是一种学习的方法,遇到不会的再向前学习,再进行运用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 41
41 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)