手把手教你使用langchain4j编写大模型RAG
RAG是通过把本地知识库检索结果和用户的交互信息,一同提交给大模型,由大模型再次加工后,形成最终结果的一个过程。RAG是最简单的使用大模型为我们工作的模式,有着广泛的应用,例如,让大模型成为我们专业领域的客服,让大模型根据我们专业领域知识产生文档等。本文手把手教你用langchain4j编写一个最简单的RAG。STEP4: 编写具体的RAG过程代码RAG过程需要一个大模型调用,以及本地知识库检索内
AI编程之–手把手教你使用langchain4j编写大模型RAG
RAG是通过把本地知识库检索结果和用户的交互信息,一同提交给大模型,由大模型再次加工后,形成最终结果的一个过程。RAG是最简单的使用大模型为我们工作的模式,有着广泛的应用,例如,让大模型成为我们专业领域的客服,让大模型根据我们专业领域知识产生文档等。
本文手把手教你用langchain4j编写一个最简单的RAG。
STEP1: 安装Postgresql+pgvector向量库
AI编程之–手把手教你在CentOS安装Postgresql的Vector向量数据库插件
STEP2: 建设简单的知识库
AI编程之–手把手教你使用postgresql向量数据库建设知识库JAVA版
STEP3: 编写本地知识库检索代码
本地知识库检索能力,包含建设好的向量库和从向量库里检索知识的能力:
LeoPostgresVectorEmbeddingStore embeddingStore = LeoPostgresVectorEmbeddingStore.builder() .host(host) .port(Integer.parseInt(port)) .database(databaseName) .user(dataBaseUserName) .password(dataBasePassword) .dimension(384) .createTable(true) .dropTableFirst(false) .table(tableName) .build(); int maxResults = 1; double minScore = 0.6; EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel(); ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder() .embeddingStore(embeddingStore) .embeddingModel(embeddingModel) .maxResults(maxResults) .minScore(minScore) .build();
STEP4: 编写具体的RAG过程代码
RAG过程需要一个大模型调用,以及本地知识库检索内容。使用langchain4j,这个过程就相对简化很多,而且可以非常方便的通过ChatMemory支持历史记录。
OpenAiChatModel chatModel = OpenAiChatModel.builder().baseUrl("https://xxx.yyy ") .apiKey("sk-1234567890abcdef").modelName("gpt-3.5-turbo").build(); //建立一个可存储10条历史记录的ChatMemory ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10); //通过AiServices实例化一个LLM调用代理 LLMAssistant agent = AiServices.builder(LLMAssistant.class) .chatLanguageModel(chatModel) .contentRetriever(contentRetriever) //在调用LLM之前,会自动从本地知识库检索相关知识 .chatMemory(chatMemory) .build(); String answer = agent.chat("介绍一下五一出游趋势");
STEP5: 看看背后干了啥
我们debug代码,跟踪到发请求前,可以看到,最终调用ChatCompletion接口
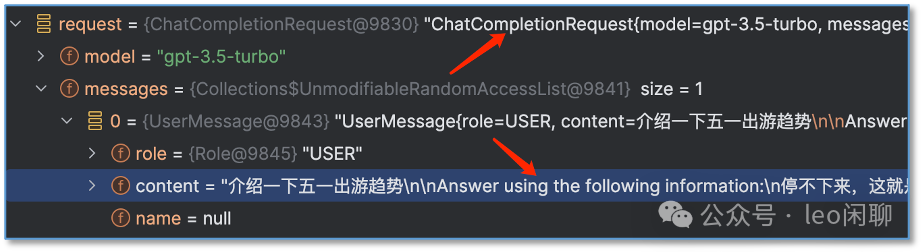
背后调用的chat/completion接口。
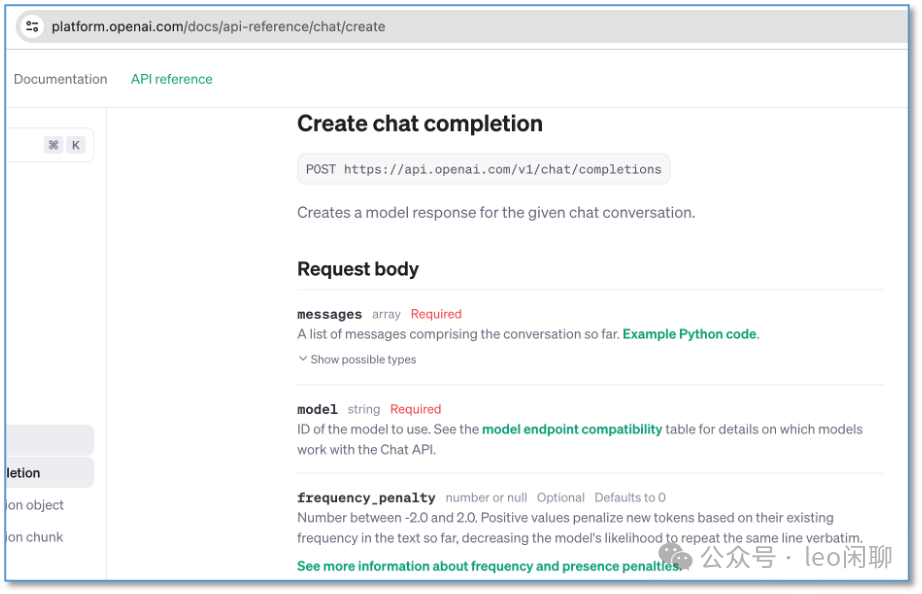
这个接口有较多的参数可用,常用的有如下几个:
- temperature: 为0表示让模型不要自我创造,每次返回的结果都一样,为1表示让模型极大的自我创造
- n:返回的备选文档条数
- message中的
system:设定AI行为的角色和背景,比如“你是一名算法工程师”
user:我们输入的问题,或者请求
assistant:一些期待AI回应的示例
STEP5: 后续
后续将使用Langchain和postgresql实现更多的CASE,敬请关注。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)