【Elasticsearch面试必知】Elasticsearch分片(Shard)详解:为什么需要分片?如何优化分片策略?
Elasticsearch(ES)是一个基于Lucene的分布式搜索和分析引擎,广泛应用于日志分析、全文检索、实时数据分析等场景。在Elasticsearch中,一个索引(Index)的数据会被拆分成多个分片,并分布在不同的节点上,以实现。是一个核心概念,直接影响集群的性能、扩展性和高可用性。分片(Shard)是Elasticsearch中。副本分片(Replica Shard)主分片(Prima
·
目录
1 引言
Elasticsearch(ES)是一个基于Lucene的分布式搜索和分析引擎,广泛应用于日志分析、全文检索、实时数据分析等场景。在Elasticsearch中, 分片(Shard) 是一个核心概念,直接影响集群的性能、扩展性和高可用性。本文将探讨:
- 什么是分片?
- 为什么Elasticsearch需要分片?
- 分片的类型(主分片 vs. 副本分片)
- 如何优化分片策略?
2 什么是分片(Shard)?
分片(Shard)是Elasticsearch中 数据存储和计算的基本单位。一个索引(Index)的数据会被拆分成多个分片,并分布在不同的节点上,以实现 水平扩展和 并行处理。
2.1 分片的基本概念
- 主分片(Primary Shard):存储索引的原始数据,负责写入和查询
- 副本分片(Replica Shard):主分片的备份,提供高可用性和读取负载均衡
2.2 分片的数据分布
Elasticsearch使用 哈希路由(Hash Routing) 将文档分配到不同的分片:
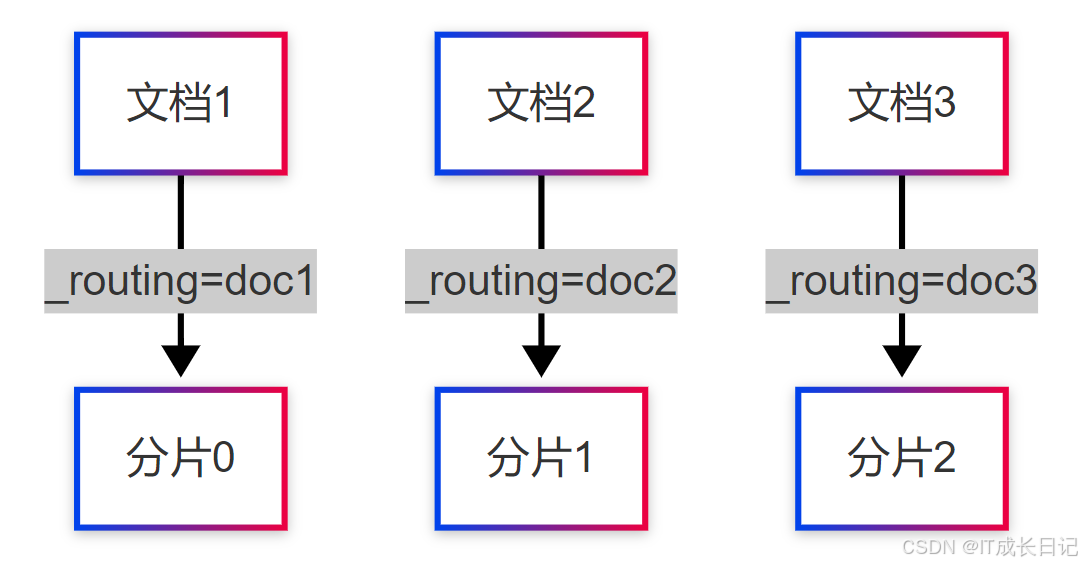
说明:
- 文档写入时,Elasticsearch计算 _routing(默认使用 _id)的哈希值
- 根据哈希值决定文档存储在哪个分片(shard = hash(_routing) % number_of_shards)
- 数据均匀分布在所有主分片上
3 为什么Elasticsearch需要分片?
3.1 提高并发处理能力
- 单节点存储和计算能力有限,分片允许数据分布在多个节点上,提高并行处理能力
- 查询可以并行执行,减少响应时间
3.2 支持水平扩展
- 当数据量增长时,可以动态增加节点,Elasticsearch会自动调整分片分布
- 避免单机存储瓶颈,支持PB级数据存储
3.3 提高高可用性
- 副本分片(Replica Shard) 可以在主分片故障时接管服务,避免数据丢失
- 副本分片可以分担读请求,提高查询性能
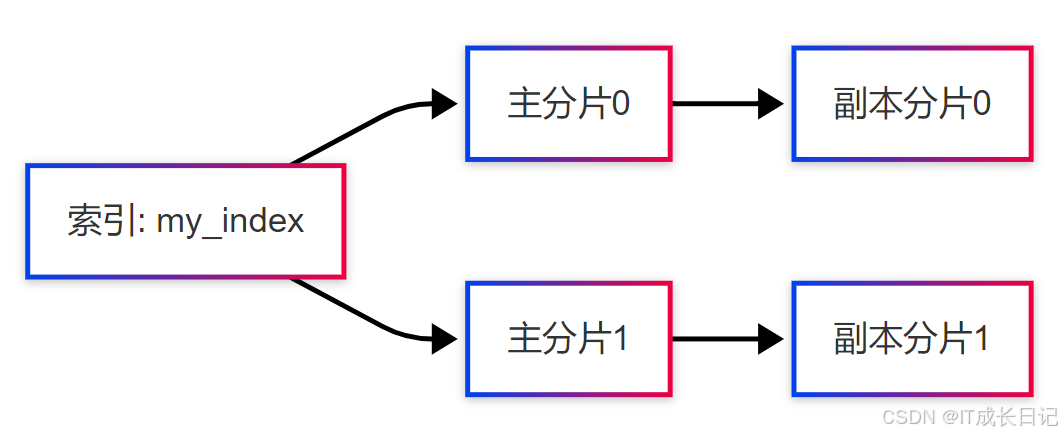
说明:
- 每个主分片可以有多个副本分片(默认1个)
- 副本分片可以分布在不同的节点上,提高容错能力
4 主分片 vs 副本分片
|
特性 |
主分片(Primary Shard) |
副本分片(Replica Shard) |
|
数据来源 |
存储原始数据 |
复制自主分片 |
|
写入方式 |
接受写入请求 |
不直接写入,仅同步主分片数据 |
|
查询方式 |
可处理查询请求 |
可处理查询请求(负载均衡) |
|
高可用性 |
单点故障可能导致数据不可用 |
主分片故障时可接管 |
|
扩展性 |
数量固定(创建索引时指定) |
可动态调整 |
5 如何优化分片策略?
5.1 合理设置主分片数量
- 主分片数量在索引创建时确定,后续无法修改(除非使用Reindex)
- 建议:
- 单个分片大小控制在 10GB~50GB(日志类数据可更大)
- 分片过多会导致 元数据管理开销增加,影响性能
5.2 调整副本分片数量
- 副本分片数量可以动态调整:
PUT /my_index/_settings
{
"number_of_replicas": 2
}建议:
- 生产环境至少 1个副本分片,提高容错能力
- 查询密集型场景可增加副本分片,提高读取吞吐量
5.3 避免热点分片
- 如果某些分片数据量远大于其他分片,会导致负载不均
- 解决方案:
- 使用 自定义_routing均匀分布数据
- 监控分片大小,必要时进行Reindex重新分配
6 总结
- 分片(Shard) 是Elasticsearch实现分布式存储和计算的核心机制
- 主分片 负责数据写入,副本分片提供高可用性和读取负载均衡
- 优化分片策略 可以提高集群性能、扩展性和稳定性

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)