浅谈 ResNet-18网络预训练模型的使用
·
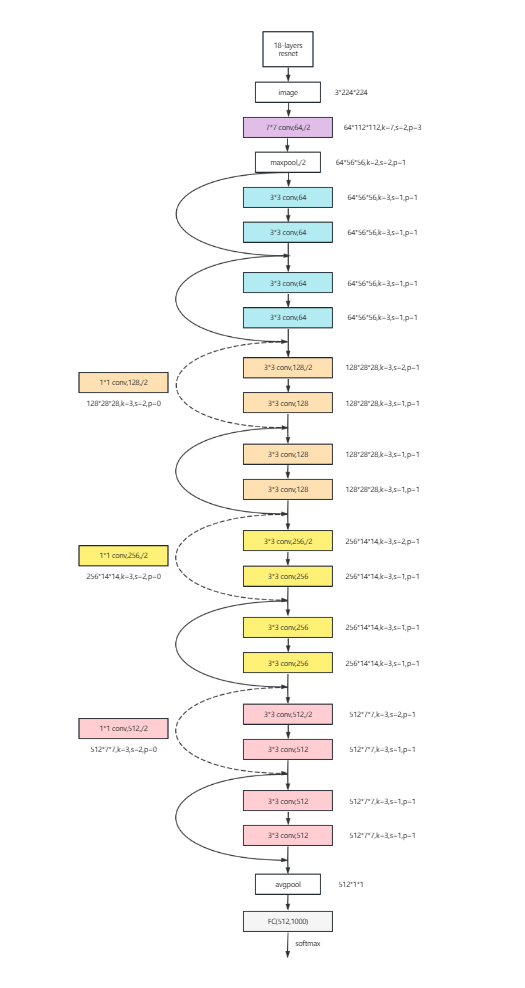
可直接用于各种图像分类,data目录下设置train和val文件夹,文件夹内输入分类样本即可,算法会自动识别是几类样本,样本为jpg,可自行修改
环境配置:
torch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
from torchvision import models
import os
from PIL import Image
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
数据预处理和增强
transform = transforms.Compose([
transforms.Resize((512, 512)), # 调整图像大小
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 颜色调整
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
验证/测试时的预处理
val_transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
自定义数据集类
class ImageDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.images = []
self.labels = []
self.class_to_idx = {}
self.idx_to_class = {}
# 自动检测类别
if os.path.exists(data_dir):
classes = sorted([d for d in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, d))])
self.class_to_idx = {cls_name: idx for idx, cls_name in enumerate(classes)}
self.idx_to_class = {idx: cls_name for idx, cls_name in enumerate(classes)}
# 收集所有图像路径和标签
for class_name in classes:
class_dir = os.path.join(data_dir, class_name)
class_idx = self.class_to_idx[class_name]
for img_file in os.listdir(class_dir):
if img_file.lower().endswith(('.jpg', '.jpeg')):
self.images.append(os.path.join(class_dir, img_file))
self.labels.append(class_idx)
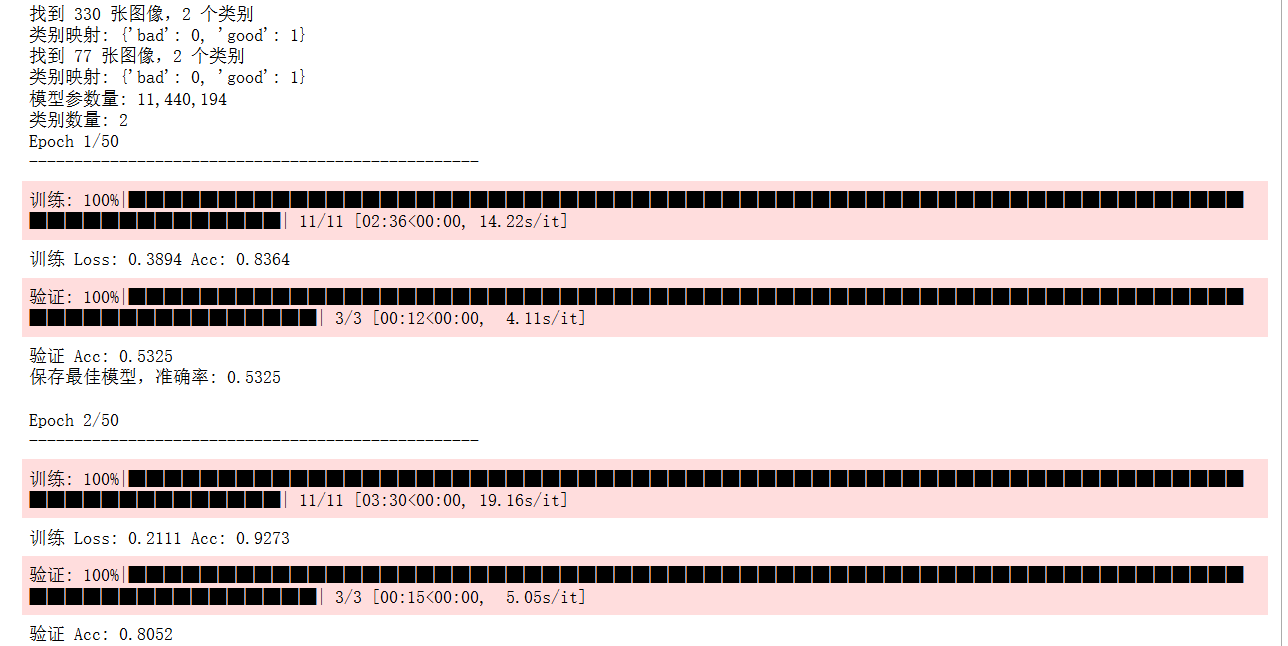
print(f"找到 {len(self.images)} 张图像,{len(self.class_to_idx)} 个类别")
print("类别映射:", self.class_to_idx)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = self.images[idx]
label = self.labels[idx]
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, label
def create_pretrained_model(num_classes=2):
"""使用预训练的ResNet模型"""
model = models.resnet18(pretrained=True)
# 冻结前面的层(可选)
# for param in model.parameters():
# param.requires_grad = False
# 替换最后的全连接层
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, num_classes)
)
return model
训练函数
def train_model(model, train_loader, val_loader, num_epochs=50):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
train_losses = []
val_accuracies = []
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 50)
# 训练阶段
model.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm(train_loader, desc="训练"):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = running_corrects.double() / len(train_loader.dataset)
train_losses.append(epoch_loss)
print(f'训练 Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 验证阶段
model.eval()
val_running_corrects = 0
with torch.no_grad():
for inputs, labels in tqdm(val_loader, desc="验证"):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
val_running_corrects += torch.sum(preds == labels.data)
val_epoch_acc = val_running_corrects.double() / len(val_loader.dataset)
val_accuracies.append(val_epoch_acc.cpu())
print(f'验证 Acc: {val_epoch_acc:.4f}')
# 保存最佳模型
if val_epoch_acc > best_acc:
best_acc = val_epoch_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f'保存最佳模型,准确率: {best_acc:.4f}')
scheduler.step()
print()
# 绘制训练曲线 会导致内核挂掉 注释掉
#plt.figure(figsize=(12, 4))
#plt.subplot(1, 2, 1)
#plt.plot(train_losses)
#plt.title('Training Loss')
#plt.xlabel('Epoch')
#plt.ylabel('Loss')
#plt.subplot(1, 2, 2)
#plt.plot(val_accuracies)
#plt.title('Validation Accuracy')
#plt.xlabel('Epoch')
#plt.ylabel('Accuracy')
#plt.tight_layout()
#plt.savefig('training_curves.png')
#plt.show()
return model
预测函数
def predict_image(model, image_path, transform, class_names):
"""预测单张图像"""
model.eval()
# 加载和预处理图像
image = Image.open(image_path).convert('RGB')
image_tensor = transform(image).unsqueeze(0).to(device)
# 预测
with torch.no_grad():
outputs = model(image_tensor)
_, predicted = torch.max(outputs, 1)
probabilities = torch.softmax(outputs, dim=1)
predicted_class = class_names[predicted.item()]
confidence = probabilities[0][predicted.item()].item()
return predicted_class, confidence
主函数
def main():
# 数据路径设置
train_data_dir = "data/train" # 训练数据路径
val_data_dir = "data/val" # 验证数据路径
# 创建数据集
train_dataset = ImageDataset(train_data_dir, transform=transform)
val_dataset = ImageDataset(val_data_dir, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=0)
# 创建模型
# model = CNNClassifier(num_classes=len(train_dataset.class_to_idx)).to(device)
model = create_pretrained_model(num_classes=len(train_dataset.class_to_idx)).to(device)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
print(f"类别数量: {len(train_dataset.class_to_idx)}")
# 训练模型
trained_model = train_model(model, train_loader, val_loader, num_epochs=50)
# 保存最终模型
torch.save({
'model_state_dict': trained_model.state_dict(),
'class_to_idx': train_dataset.class_to_idx,
'idx_to_class': train_dataset.idx_to_class
}, 'final_model.pth')
print("训练完成!模型已保存为 'final_model.pth'")
使用训练好的模型进行预测
def load_and_predict(model_path, image_path):
"""加载训练好的模型并进行预测"""
# 加载模型
checkpoint = torch.load(model_path, map_location=device)
class_to_idx = checkpoint['class_to_idx']
idx_to_class = {v: k for k, v in class_to_idx.items()}
# 创建模型
model = create_pretrained_model(num_classes=len(class_to_idx))
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
# 预测
predicted_class, confidence = predict_image(model, image_path, transform, idx_to_class)
print(f"预测结果: {predicted_class}")
print(f"置信度: {confidence:.4f}")
# 显示图像
image = Image.open(image_path)
#plt.imshow(image)
#plt.title(f"预测: {predicted_class} (置信度: {confidence:.4f})")
#plt.axis('off')
#plt.show()
return predicted_class, confidence
#模型训练与调用
if __name__ == "__main__":
# 训练模型
main()
# 使用示例:预测单张图像
predicted_class, confidence = load_and_predict('final_model.pth', 'test_image.jpg')

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)