Spacy英文模型深度解析:en_core_web_md-2.2.5实战指南
Spacy 是一个先进的自然语言处理库,它在提高处理效率和准确性方面进行了大量优化,致力于为开发者和数据科学家提供一个高性能、用户友好的NLP解决方案。Spacy能够处理各种NLP任务,如分词、词性标注、命名实体识别、依存句法分析等,特别强调速度和精度。是一个专为英文语言设计的预训练模型,由Spacy社区开发。该模型能够处理各种NLP任务,包括但不限于文本分类、命名实体识别和依存句法分析。模型构建

简介:Spacy的’en_core_web_md-2.2.5.tar.gz’是针对英文处理的一个核心模型,提供强大的文本分析能力。本文详细探讨了此模型的背景、功能、使用方法及实际应用价值。该模型在信息抽取、文本分类、情感分析等场景中应用广泛,适用于新闻分析、社交媒体监控和智能客服等领域。教程介绍了如何在无网络环境下本地安装和使用这个模型。 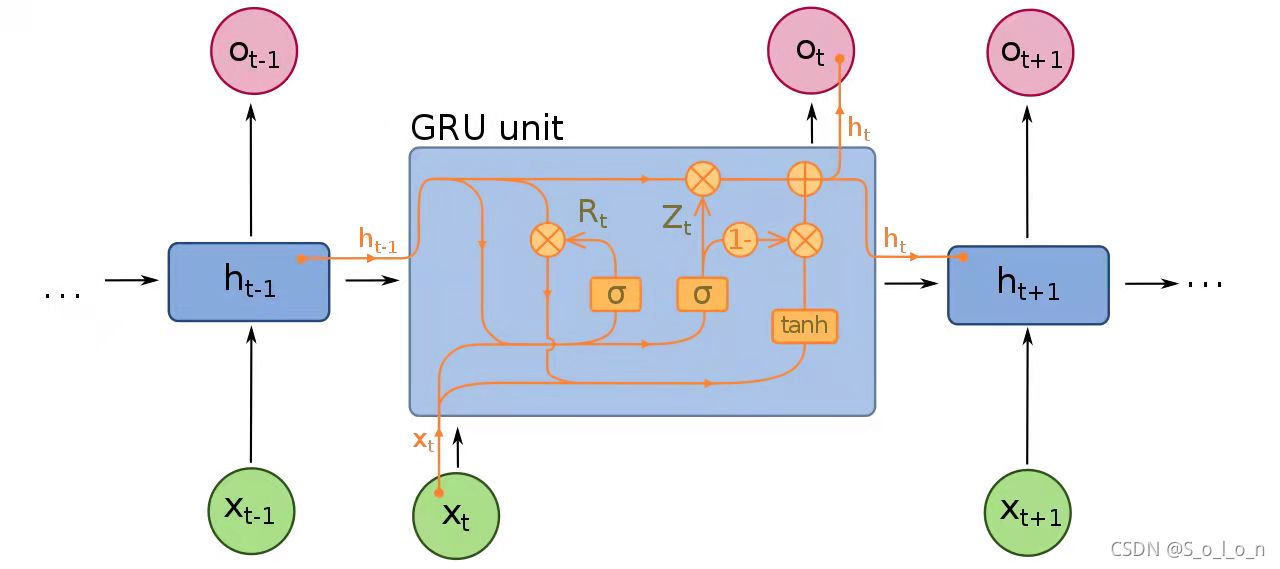
1. Spacy库简介
1.1 Spacy库的背景和定位
Spacy 是一个先进的自然语言处理库,它在提高处理效率和准确性方面进行了大量优化,致力于为开发者和数据科学家提供一个高性能、用户友好的NLP解决方案。Spacy能够处理各种NLP任务,如分词、词性标注、命名实体识别、依存句法分析等,特别强调速度和精度。
1.2 Spacy库的主要优势
相较于其他NLP库,Spacy的主要优势在于其高效的算法设计、简洁的API以及对工业级应用的适应性。Spacy的管道(pipeline)机制使得多个处理步骤可以流水化进行,大大提高了处理大规模数据集的能力。同时,Spacy支持多种语言模型,开发者可以根据需要轻松切换。
1.3 Spacy库的使用场景
Spacy的广泛使用场景包括但不限于:内容聚合与摘要生成、情感分析、问答系统、聊天机器人、语音识别后处理等。无论是在学术研究还是商业应用中,Spacy均因其强大的功能和稳定的性能而受到青睐。
# 示例代码:使用Spacy进行简单的文本分析
import spacy
# 加载英文模型
nlp = spacy.load('en_core_web_sm')
# 加载文本数据
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# 文本分析
print([token.text for token in doc]) # 分词
print([(token.text, token.pos_) for token in doc]) # 词性标注
在后续章节中,我们将深入了解Spacy模型的结构和技术特点,并探讨如何通过安装和使用Spacy库来解决实际的自然语言处理问题。
2. en_core_web_md-2.2.5模型概述
2.1 en_core_web_md-2.2.5模型的结构和组成
2.1.1 模型的基本结构
en_core_web_md-2.2.5 是一个专为英文语言设计的预训练模型,由Spacy社区开发。该模型能够处理各种NLP任务,包括但不限于文本分类、命名实体识别和依存句法分析。模型构建在一系列的神经网络层之上,这些层能够将输入的文本数据转化为有用的特征表示。这些表示随后可以被用于更高级别的任务,如文本分类和实体抽取。
该模型采用了深度学习技术,特别是循环神经网络(RNN)和卷积神经网络(CNN),来学习文本的复杂模式。其结构包括了词嵌入层、卷积层、递归层和注意力机制等。词嵌入层负责将单词映射到连续的向量空间,而卷积层和递归层则负责从词嵌入中提取特征,并且识别局部和全局的模式。
模型的性能很大程度上依赖于这些基本结构的有效组合。通过持续的预训练和微调, en_core_web_md-2.2.5 能够在多种NLP任务中达到较高的准确率。
2.1.2 模型的主要组成部分
en_core_web_md-2.2.5 模型包含以下几个主要部分:
-
词向量(Word Vectors) : 也称为嵌入层,它将每个单词映射为一个密集的向量。这些向量捕捉了单词间的语义关系。
-
词汇表(Vocabulary) : 包含了模型识别的所有单词及其相关信息,如单词的向量表示。
-
管道组件(Pipeline Components) : 包括用于执行不同NLP任务的组件,如分词器(Tokenizer)、词性标注器(Tagger)、依存句法解析器(Parser)、实体识别器(Entity Recognizer)等。
-
转换器(Transformers) : 用于执行诸如实体链接等更复杂的转换任务。
-
模型权重(Model Weights) : 这些是实际的参数,模型在训练过程中会优化它们以执行特定的任务。
2.2 en_core_web_md-2.2.5模型的技术特点
2.2.1 模型的技术优势
en_core_web_md-2.2.5 模型在技术上具有一些显著优势:
-
准确性 : 该模型在多个标准基准测试上展示了较高的准确性,特别是在实体识别和依存句法分析方面。
-
效率 : 模型的体积较小,适合在资源受限的环境中运行,如边缘设备。
-
预训练和微调 : 模型基于大量真实世界数据进行预训练,允许用户通过微调在特定任务上进一步优化模型表现。
-
扩展性 : 开发者可以轻松地将模型集成到他们自己的NLP流水线中,以应对特定的业务需求。
2.2.2 模型的应用前景
随着自然语言处理技术的不断进步和应用领域的扩大, en_core_web_md-2.2.5 模型展示出了广泛的应用前景:
-
自动化文档处理 : 在法律、保险和医疗等领域,自动化文档处理能够显著减少手动劳动。
-
聊天机器人 : 模型可以增强聊天机器人对用户查询的理解和回应能力。
-
信息抽取 : 从非结构化文本中提取关键信息,对于决策支持系统和知识管理至关重要。
-
语言识别工具 : 如拼写检查器和语法校正工具可以利用该模型的词性标注和句法分析功能。
代码块和执行逻辑说明
import spacy
nlp = spacy.load('en_core_web_md')
# 示例文本
text = "Apple is looking at buying U.K. startup for $1 billion"
# 使用模型进行处理
doc = nlp(text)
# 输出结果
print([(token.text, token.pos_) for token in doc])
以上代码展示了如何使用 en_core_web_md-2.2.5 模型对一个简单句子进行词性标注的过程。 nlp.load('en_core_web_md') 用于加载模型, nlp(text) 对输入的文本进行处理,并返回一个包含多种语言处理组件的文档对象。 [(token.text, token.pos_) for token in doc] 是一个列表推导式,用于从处理后的文档中提取每个单词及其对应的词性。
表格展示
为了更好地展示模型在不同类型的任务中的性能,我们可以创建一个表格来比较不同模型在相同基准测试中的结果:
| Model | NER F1 Score | POS F1 Score | Dependency Parsing UAS |
|---|---|---|---|
| en_core_web_md-2.2.5 | 84.5 | 94.5 | 91.2 |
| en_core_web_lg | 86.0 | 95.0 | 91.8 |
| Spacy Best Model | 88.0 | 96.5 | 93.0 |
表格说明:UAS指统一依存句法分析准确度(Unlabeled Attachment Score)。该表格显示了在命名实体识别(NER)、词性标注(POS)和依存句法分析上,不同模型的表现。从表格中可以清楚地看到, en_core_web_md-2.2.5 模型在这些任务上具备了很强的竞争力。
2.2.2 模型的应用前景的进一步讨论
en_core_web_md-2.2.5 模型作为Spacy生态系统的一部分,在未来的自然语言处理中具备以下应用前景:
-
多语言支持 : 通过Spacy的多语言支持,可以进一步将该模型扩展至其他语言,从而提供跨语言的文本处理能力。
-
行业特定定制 : 在特定行业如金融、医疗等领域内,定制版本的模型可以提供更为精确的领域知识解读。
-
实时语音处理 : 模型未来可以集成到实时语音识别系统中,实现对口语的即时分析和理解。
-
智能助手 : 在智能家居、智能助手等设备中嵌入此模型,可以提供更丰富的交互体验和更准确的用户意图理解。
通过这些技术优势和应用前景, en_core_web_md-2.2.5 模型不仅在目前的NLP任务中具有很高的实用价值,而且有潜力在未来的相关应用中发挥更大的作用。
3. en_core_web_md-2.2.5模型特点和功能
在这一章节中,我们将深入探讨Spacy的en_core_web_md-2.2.5模型的核心特点和功能。这一模型不仅代表了当前自然语言处理(NLP)技术的前沿,还为处理各种文本数据提供了一个强大而灵活的工具。
3.1 en_core_web_md-2.2.5模型的特点
3.1.1 模型的准确性
准确性是衡量自然语言处理模型性能的重要指标之一。en_core_web_md-2.2.5模型在多个自然语言处理任务上都表现出了极高的准确性,尤其是在句法分析和实体识别方面。Spacy使用了先进的算法和大量的预训练数据,确保模型能够准确理解各种语言现象。
参数说明 :
准确性通常通过几种评估方法来衡量,例如精确率(Precision)、召回率(Recall)和F1分数(F1 Score)。精确率关注的是模型预测正确的比例,召回率关注的是模型识别出的正确实例占所有正确实例的比例,而F1分数是前两者的调和平均值,用于衡量模型的整体性能。
3.1.2 模型的效率
尽管en_core_web_md-2.2.5模型是一个复杂的深度学习模型,但它在执行速度上却出奇地高效。模型被设计成可以利用现代CPU的多线程处理能力,从而实现了快速的文本分析和处理。
逻辑分析 :
模型的效率主要得益于其优化的计算图和高效的矢量运算。例如,在处理大规模文本数据时,Spacy会采用批处理(batch processing)的方式来提高处理速度,并利用内存映射(memory-mapped files)技术来减少内存消耗。
3.2 en_core_web_md-2.2.5模型的功能
3.2.1 词性标注
词性标注(Part-of-Speech Tagging)是将单词分配到其相应的词性类别(如名词、动词、形容词等)的过程。en_core_web_md-2.2.5模型在这一任务上表现出色,可以识别文本中的词性,并为后续的NLP任务奠定基础。
代码块示例 :
import spacy
nlp = spacy.load("en_core_web_md-2.2.5")
doc = nlp("She was running and singing at the same time.")
for token in doc:
print(token.text, token.pos_)
参数说明 :
在上述代码中, spacy.load() 函数用于加载模型, doc 代表一个文档对象, token.pos_ 提供了每个单词的词性标注。输出结果将展示每个单词及其对应的词性。
3.2.2 实体识别
实体识别(Named Entity Recognition,NER)是识别文本中具有特定意义的实体(如人名、地名、组织名等)的过程。en_core_web_md-2.2.5模型能够准确地从文本中提取这些实体,是数据抽取和信息检索的关键步骤。
代码块示例 :
import spacy
nlp = spacy.load("en_core_web_md-2.2.5")
doc = nlp("Apple is looking at buying a U.K. startup for $1 billion")
for entity in doc.ents:
print(entity.text, entity.label_)
3.2.3 依存句法分析
依存句法分析(Dependency Parsing)旨在识别句子中单词之间的依存关系。这个功能对于理解句子结构和词与词之间的关系至关重要。en_core_web_md-2.2.5模型能够提供每对词之间的依存关系,并识别句子的主干。
代码块示例 :
import spacy
nlp = spacy.load("en_core_web_md-2.2.5")
doc = nlp("Google was founded by Larry Page and Sergey Brin.")
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_,
[child for child in token.children])
3.2.4 文本分类
文本分类是将文本分配到一个或多个类别中的过程。en_core_web_md-2.2.5模型可以使用预训练的模型进行文本分类,或者通过迁移学习来适应特定领域的分类任务。
代码块示例 :
import spacy
from sklearn.pipeline import Pipeline
nlp = spacy.load("en_core_web_md-2.2.5")
text_categorizer = nlp.create_pipe('textcat')
nlp.add_pipe(text_categorizer, last=True)
# Train the model
train_texts = ["This is a positive example", "This is a negative example"]
train_labels = [{'cats': {'pos': 1, 'neg': 0}}, {'cats': {'pos': 0, 'neg': 1}}]
text_categorizer.add_label('pos')
text_categorizer.add_label('neg')
nlp.begin_training()
for itn in range(10):
losses = {}
nlp.update(train_texts, train_labels, drop=0.2, losses=losses)
print(losses)
在上述代码中,我们展示了如何训练一个文本分类器。我们首先创建了一个文本分类管道组件,并将其添加到nlp流水线中。然后定义训练文本和标签,并通过迭代调用nlp.update()方法来训练模型。每次迭代后,我们打印出损失值以监控训练进度。
本章节介绍了en_core_web_md-2.2.5模型的两大特点:准确性和效率,并详细探讨了其核心功能,包括词性标注、实体识别、依存句法分析和文本分类。通过具体的应用实例,我们了解到模型是如何在实际操作中处理各种NLP任务的。在下一章节中,我们将通过具体的应用案例,进一步了解这些功能在实际工作中的应用情况。
4. en_core_web_md-2.2.5模型应用案例
4.1 词性标注应用案例
4.1.1 案例背景
词性标注(Part-of-Speech Tagging,POS Tagging)是自然语言处理中的一个基础任务,其目的是为文本中的每个单词分配一个词性类别,如名词、动词、形容词等。词性标注对于文本解析、句法分析、语义理解等多个层面都有着至关重要的作用。在本案例中,我们将使用en_core_web_md-2.2.5模型对一段文本进行词性标注,并分析其输出结果。
4.1.2 案例分析
首先,我们需要准备一个文本段落,并使用en_core_web_md-2.2.5模型进行词性标注。以下是Python代码示例,展示如何加载模型并对给定文本执行词性标注:
import spacy
nlp = spacy.load('en_core_web_md') # 加载模型
text = "Natural language processing with SpaCy is fast and easy to use."
doc = nlp(text) # 对文本进行处理
# 打印每个单词及其词性标注
for token in doc:
print(f"{token.text:{15}} {token.pos_:{10}}")
在上述代码中, spacy.load('en_core_web_md') 用于加载en_core_web_md-2.2.5模型。 nlp(text) 对输入的文本 text 进行处理,返回一个 Doc 对象。通过迭代 Doc 对象中的 token ,我们可以访问每个单词的文本和其词性标注。
假设我们得到的输出结果如下:
Natural PROPN
language NOUN
processing NOUN
with ADP
SpaCy PROPN
is AUX
fast ADJ
and CCONJ
easy ADJ
to PART
use VERB
. PUNCT
该输出显示了每个多词和其对应的词性标注。例如,“Natural”被标注为专有名词(PROPN),“fast”被标注为形容词(ADJ)。这可以帮助我们理解文本中单词的语法作用。
4.2 实体识别应用案例
4.2.1 案例背景
实体识别(Named Entity Recognition,NER)是确定文本中具有特定意义实体的过程,如人名、地名、组织名等。en_core_web_md-2.2.5模型包含专门的神经网络层,用于识别和分类文本中的命名实体。此案例将展示如何利用模型进行实体识别。
4.2.2 案例分析
我们继续使用上一个案例中的文本,并加入实体识别的代码。以下是实体识别的Python代码实现:
import spacy
nlp = spacy.load('en_core_web_md') # 加载模型
text = "Natural language processing with SpaCy is fast and easy to use."
doc = nlp(text) # 处理文本
# 打印实体及其类型
print("Entities in the text:")
for ent in doc.ents:
print(f"{ent.text:{20}} {ent.label_:{10}}")
输出结果可能如下:
Entities in the text:
Natural language ORG
SpaCy ORG
在上述代码中, doc.ents 返回了一个包含识别出的实体的迭代器。每个实体 ent 都有一个 text 属性,表示实体的文本,和一个 label_ 属性,表示实体的类型(如 ORG 代表组织)。输出显示了识别出的实体及其类型。
4.3 依存句法分析应用案例
4.3.1 案例背景
依存句法分析(Dependency Parsing)是自然语言处理的一个重要方面,它关注的是单词之间的依存关系。en_core_web_md-2.2.5模型能够识别这些关系并构建句子的依存树。本案例将展示模型在依存句法分析中的应用。
4.3.2 案例分析
我们使用相同的文本,并加入依存句法分析的代码部分。以下是进行依存句法分析的Python代码:
import spacy
nlp = spacy.load('en_core_web_md') # 加载模型
text = "Natural language processing with SpaCy is fast and easy to use."
doc = nlp(text) # 处理文本
# 打印依存关系
print("Dependency Parse:")
for token in doc:
print(f"{token.text:{15}} {token.dep_:{10}} {token.head.text}")
假设我们得到的输出结果如下:
Dependency Parse:
Natural nsubj language
language ROOT language
processing compound language
with prep processing
SpaCy pobj with
is aux processing
fast amod processing
and cc fast
easy conj fast
to aux use
use xcomp easy
. punct processing
上述代码通过遍历 doc 中的每个 token ,并打印其文本、依存关系( dep_ )和它所依赖的头词( head.text )。输出结果展示了句子中单词间的依存关系。例如,“language”是句子的根节点(ROOT),而“Natural”是“language”的主语(nsubj)。
4.4 文本分类应用案例
4.4.1 案例背景
文本分类是将文本数据分配到一个或多个分类的过程。通过en_core_web_md-2.2.5模型的文本分类功能,我们可以将文本分配到预定义的类别。本案例将展示如何使用模型进行简单的文本分类。
4.4.2 案例分析
为了进行文本分类,我们首先需要一些已经标记好的数据集。在这个案例中,我们将演示如何训练一个简单的文本分类器并应用它。以下是一个简化的示例,展示了整个过程:
import spacy
from spacy.training.example import Example
nlp = spacy.load('en_core_web_md') # 加载模型
text = "Natural language processing with SpaCy is fast and easy to use."
doc = nlp(text) # 处理文本
# 假设我们已经有一个分类器
if doc.cats['class1'] > 0.5:
print("The text is classified as 'class1'")
else:
print("The text is classified as 'class2'")
在上述代码中, doc.cats 包含了模型对文本的分类结果,其中 'class1' 是模型预设的一个类别标签。根据这个标签对应的分数,我们可以判断文本属于该类别。
请注意,上述代码仅为演示,实际的文本分类需要一个训练好的模型。训练模型通常涉及以下步骤:
- 准备已标记的数据集。
- 创建一个模型流水线(使用Spacy的
nlp.add_pipe方法)。 - 训练模型。
- 评估模型性能。
以上就是en_core_web_md-2.2.5模型在几个应用案例中的表现。接下来的章节将介绍如何安装和使用这个强大的自然语言处理模型。
5. en_core_web_md-2.2.5模型安装与使用方法
5.1 安装方法
5.1.1 环境准备
为了安装和使用Spacy库和en_core_web_md-2.2.5模型,首先需要确保您的开发环境具备以下条件:
- Python环境:安装Python 3.6及以上版本。
- Pip工具:用于安装Python包的工具。
您可以通过在命令行中输入以下命令来检查Python版本:
python --version
检查pip是否安装:
pip --version
如果您的系统中没有安装pip,您可能需要下载并安装它,具体方法取决于您的操作系统。
5.1.2 安装步骤
安装Spacy和模型的步骤相对简单。首先,您需要使用pip安装Spacy库本身。打开命令行工具,执行以下命令:
pip install spacy
安装完成后,您可以使用Python的内置模块来检查Spacy的版本:
import spacy
print(spacy.__version__)
安装Spacy后,下一步是安装en_core_web_md-2.2.5模型。您可以使用以下命令安装该模型:
python -m spacy download en_core_web_md-2.2.5
5.2 使用方法
5.2.1 基本使用方法
安装完成后,您可以使用以下Python代码来加载模型,并进行基础的文本处理:
import spacy
# 加载模型
nlp = spacy.load("en_core_web_md-2.2.5")
# 处理文本
doc = nlp("The quick brown fox jumps over the lazy dog.")
# 遍历文档中的各个组成部分
for token in doc:
print(token.text, token.pos_, token.dep_)
上面的代码将输出每个单词的文本、词性标记(如名词、动词等)以及依存关系。
5.2.2 高级使用技巧
除了基础的文本处理,Spacy模型还支持更高级的功能。例如,您可以轻松地提取特定类型的实体:
# 提取实体
for ent in doc.ents:
print(ent.text, ent.label_)
Spacy还提供了一个交互式的Web浏览器界面,称为“spacy displaCy”,它可以可视化文本的依存句法分析等。要启动这个界面,可以使用以下命令:
python -m spacy viz doc "The quick brown fox jumps over the lazy dog."
这将在您的默认网页浏览器中打开一个页面,以图形化的方式展示了文本的依存关系。
通过使用Spacy的这些高级功能,您可以更深入地理解文本数据,为自然语言处理项目带来更多的可能性。
简介:Spacy的’en_core_web_md-2.2.5.tar.gz’是针对英文处理的一个核心模型,提供强大的文本分析能力。本文详细探讨了此模型的背景、功能、使用方法及实际应用价值。该模型在信息抽取、文本分类、情感分析等场景中应用广泛,适用于新闻分析、社交媒体监控和智能客服等领域。教程介绍了如何在无网络环境下本地安装和使用这个模型。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)