OpenVLA: An Open-Source Vision-Language-Action Model论文学习
VLA训练的时候要多几个epoch,不能像LLM一样1,2个就完事了。VLA意为:vision language action 模型,其中的v可以使用常规多模态模型的vision部分。使用的现成的数据集,但是做了修改。只要人为手动的数据集,使用的机器什么的都要统一,各种任务类型也要平均。Motion(移动):同样的东西和背景看起来差不多,不过东西的位置不太一样。优点基本上就是:模型小,开源,直接用
·
VLA意为:vision language action 模型,其中的v可以使用常规多模态模型的vision部分
优点基本上就是:模型小,开源,直接用的vlm微调还做了量化
使用的现成的数据集,但是做了修改。只要人为手动的数据集,使用的机器什么的都要统一,各种任务类型也要平均
论文发现使用高分辨率训练没啥用。训练的时候把vision encoder冻住更好。VLA训练的时候要多几个epoch,不能像LLM一样1,2个就完事了。
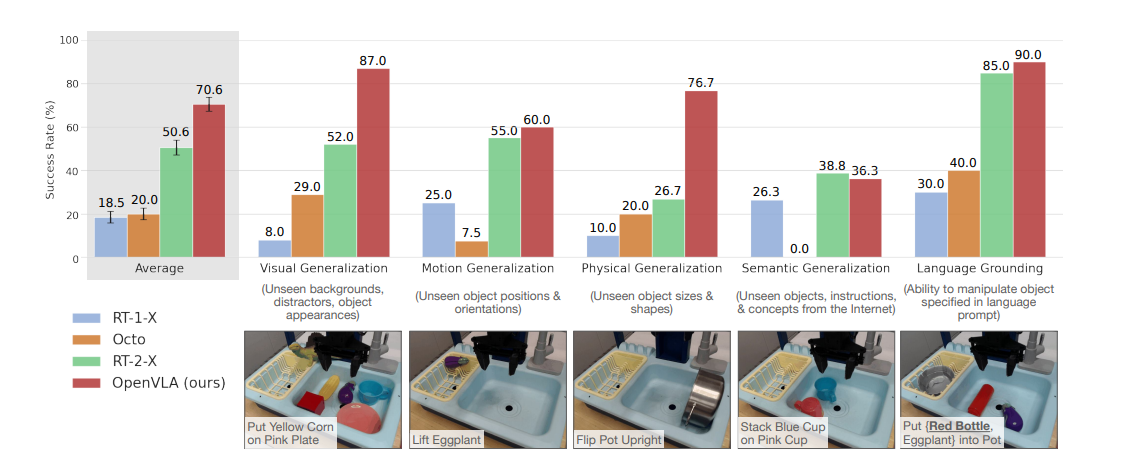
这个任务分类值得讲一下:
视觉类任务就是:要干的事情是一样的,就是画面看起来不一样
Motion(移动):同样的东西和背景看起来差不多,不过东西的位置不太一样
Physical:要干的事情一样,但是东西不一样
Semantic(语义):东西和任务都不一样
Language(语言定位):没太搞懂。论文中说测试的时候一次测第一种物品,一次测第二种。有什么区别吗?

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)