在向量库里进行相似检索:Hybrid Search 的常见算法
Hybrid Search 的核心目标是结合关键词检索的精确性与向量检索的语义能力:最常用、可调节精度与召回的平衡;RRF:更健壮的无参排序融合;Cross-Encoder 重排:牺牲性能换取极致精度;Sparse + Dense 一体化:系统级方案,适合长期工程化部署。根据业务场景和性能需求,可以灵活选择或组合使用这些方法,构建高效稳定的混合检索系统。
在 RAG 系统中,单纯依赖关键词检索(BM25 等)或纯粹的向量检索(Embedding + ANN)往往存在局限:
-
关键词检索:覆盖度高,但语义理解有限;
-
向量检索:能捕捉语义,但容易误召回或漏召关键字。
因此,业界普遍采用 Hybrid Search(混合检索) —— 同时结合关键词检索与向量检索,以提升准确度和鲁棒性。常见的混合策略主要有以下四类。
一、线性/加权分数融合(Weighted Score Fusion)
思路:
分别运行 BM25(或 BM25F)和向量检索,得到两个分数,再做归一化并加权融合:
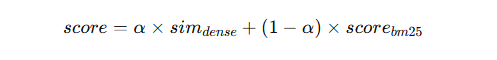
代表实现:
-
Weaviate 的
hybrid查询接口自带alpha参数(0 = 纯关键词,1 = 纯向量,0.5 = 各占一半),内部并行检索后融合输出。
适用场景:
-
最常用、最快落地的方案;
-
权重 α 可通过小规模实验调优(常见范围 0.3–0.7)。
二、RRF(Reciprocal Rank Fusion,倒数名次融合)
思路:
不直接融合分数,而是融合排序名次:

代表实现:
-
Azure AI Search 提供了 RRF 排序功能;
-
OpenSearch 内置了 RRF 混排;
-
社区在 Elasticsearch 中也常用 RRF 合并 BM25 与向量检索结果。
适用场景:
-
当 BM25 与向量检索分数量纲不同、难以直接归一时;
-
希望避免复杂调参,追求鲁棒性。
三、学习排序 / 重排(Cross-Encoder Re-rank)
思路:
先用 BM25 与向量检索分别取 Top-N 候选,合并后交给 重排模型(Cross-Encoder 或 bge-reranker) 逐条重新打分,再得到最终排序。
代表实践:
-
Qdrant 的官方教程推荐“两阶段”方案:BM25 + 向量召回 → Cross-Encoder 重排;
-
Elastic、Vespa 等也常用此模式。
适用场景:
-
对准确率要求极高的场景,如客服问答、法规/合规检索。
-
缺点:增加一次模型调用,延迟和计算成本更高。
四、稀疏+稠密一体化(Sparse-Dense Hybrid)
思路:
将关键词检索也表示为“稀疏向量”(如 SPLADE、uniCOIL),与稠密向量在同一引擎里融合,形成统一的检索框架。
代表实现:
-
Weaviate 与 Vespa:原生支持 sparse + dense 同时检索并融合打分;
-
Elasticsearch:提供多种 Hybrid 检索策略,支持将稀疏/稠密得分放在同一排序表达式中。
适用场景:
-
需要把 Hybrid 逻辑内置到底层引擎,追求更稳定一致的行为。
五、如何选择?
-
快速上线 / 默认首选:线性加权分数融合(Weighted Fusion),简单高效。
-
追求鲁棒、少调参:RRF(Reciprocal Rank Fusion),跨模态分数难对齐时尤其适合。
-
追求极致准确率:候选合并后加 Cross-Encoder 重排,适合客服、金融、法律等对答案精度要求高的业务。
-
长期工程优化:采用 Sparse + Dense 一体化方案,让系统层面天然支持 Hybrid。
总结
Hybrid Search 的核心目标是结合 关键词检索的精确性 与 向量检索的语义能力,实现更强的检索效果:
-
Weighted Fusion:最常用、可调节精度与召回的平衡;
-
RRF:更健壮的无参排序融合;
-
Cross-Encoder 重排:牺牲性能换取极致精度;
-
Sparse + Dense 一体化:系统级方案,适合长期工程化部署。
根据业务场景和性能需求,可以灵活选择或组合使用这些方法,构建高效稳定的混合检索系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)