上下文工程(下)-产品需求提示词
让我来总结一下这两部分的内容。以下是我认为在进行上下文工程时应该牢记的一些经验和陷阱。上下文过载问题:提供过多上下文可能会让 AI 不堪重负,降低性能。解决方案:采用上下文分层,只聚焦于相关信息。模糊指令问题:不清晰或相互矛盾的指令会导致输出不一致。解决方案:使用 PRP 模板确保一致性和清晰度。验证不足问题:缺乏验证标准会使评估输出质量变得困难。解决方案:实施全面的验证框架。上下文偏移问题:上下
本文是这个两部分系列的第二部分。在第一部分中,我分享了自己构建上下文以让智能代理AI应用获得良好结果的经验。
产品需求提示词(PRPs)
PRPs就像是非结构化的现实业务对话与结构化需求之间的桥梁。它们采用分层上下文方法,将零散的想法、功能请求和利益相关者的反馈转化为可执行的产品规范。我在第一部分中已经解释了分层上下文,如果你还没读过,建议阅读一下。
PRPs应用上下文工程原则,以确保在“需求”与实际推理及结果之间的转换过程中不会丢失任何信息。
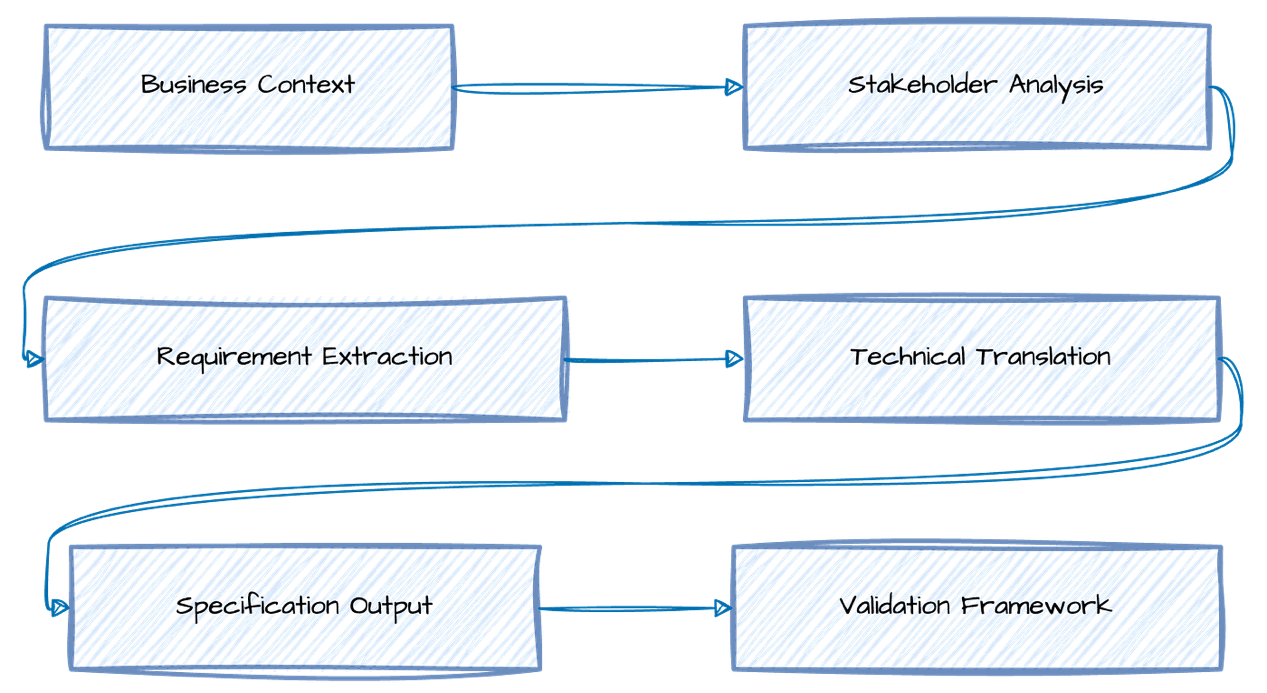
理解PRP上下文流程
此图展示了PRPs如何应用上下文工程将业务需求转化为技术需求:
-
业务上下文:确定影响需求的业务领域、市场环境和组织约束。
-
利益相关者分析:确定谁提供输入、谁做决策,以及如何平衡不同的观点。
-
需求提取:从对话、文档和反馈中系统地提取功能需求和非功能需求。
-
技术转换:将业务语言转换为开发团队可以实施的技术规范。
-
规范输出:生成结构化、可执行的需求,其格式与现有的开发工作流相集成。
-
验证框架:确保在开发开始前,需求是完整、一致且可测试的。
PRP上下文工程组件
让我们看看如何将第一部分中讨论的各个层次应用到结构清晰的PRP中。
并没有标准或规则规定这是唯一的结构,只是根据我的经验,这种结构是有效的。你可以设计自己的结构,只要涵盖本系列博客第一部分和第二部分中讨论的所有上下文方面即可。
一个典型的PRP应包含以下建议结构:
业务上下文层:确立产品和市场基础。没有业务上下文,需求就会变成功能列表,而非解决实际问题的方案。
-
产品愿景:“我们正在为小型会计师事务所构建一个B2B SaaS平台。”
-
市场约束:“必须符合SOX合规要求,并与QuickBooks集成。”
-
业务目标:“将手动数据录入减少80%,并将准确性提高至99.5%。”
利益相关者分析:描绘与需求相关的人员背景。不同的利益相关者有不同的需求。PRP有助于平衡相互竞争的优先级,并及早识别潜在冲突。
-
主要用户:“每天处理50笔以上交易的会计师职员”
-
决策者:“评估投资回报率(ROI)和合规风险的事务所合伙人”
-
技术约束相关人员:“需要单点登录和审计追踪的IT经理”
需求提取:系统地捕捉需要构建的内容。不完整的需求会导致范围蔓延和预期偏差。PRP确保不会遗漏任何关键内容。
-
功能需求:“系统必须以95%的准确率自动分类交易。”
-
非功能需求:“交易处理响应时间低于2秒”
-
集成需求:“与QuickBooks Online API实时同步”
技术转换:将业务需求转化为开发规范。开发团队需要具体的规范,而非笼统的业务期望。PRP通过将意图转化为实现细节来弥合这一差距。
-
API规范:“用于交易创建、读取、更新、删除(CRUD)操作的RESTful端点”
-
数据模型:“具有审计追踪和审批工作流的交易实体”
-
性能标准:“以99.9%的可用性处理10,000名并发用户”
规范输出:生成可执行的开发工件。需求只有在可执行时才有用。PRP确保输出能与现有开发工作流程无缝集成。
-
用户故事:“作为会计师职员,我希望能够批量导入交易,以便更快地处理月末工作。”
-
验收标准:“给定100笔交易,当我通过CSV导入时,所有有效条目应在30秒内处理完毕。”
-
技术规范:“数据库模式、API契约和集成模式”
验证框架:在开发前确保需求质量。开发开始后修复不良需求的成本很高。PRP能在问题易于解决的早期阶段发现它们。
-
完整性检查:“所有用户旅程都有对应的验收标准。”
-
一致性验证:“利益相关者群体之间不存在冲突的需求”
-
可测试性验证:“每个需求都可以通过自动化或手动测试进行验证。”
上下文工程模板及示例
所有上下文工程实现都遵循一个由系统、领域、任务、交互和响应上下文层组成的五层架构。以下是一些示例模板。
模板1:技术分析上下文
## Technical Analysis Context Template
### System Context Layer (Role Definition)
**AI Identity**: Senior technical analyst with 10+ years experience in [DOMAIN]
**Core Capabilities**: Statistical analysis, risk assessment, technical documentation
**Behavioral Guidelines**: Maintain objectivity, support claims with data, acknowledge limitations
**Safety Constraints**: Never make recommendations without sufficient data backing
### Domain Context Layer (Knowledge Base)
**Domain Expertise**: [SPECIFIC_TECHNICAL_DOMAIN] - standards, methodologies, best practices
**Industry Knowledge**: Current trends, regulatory requirements, competitive landscape
**Technical Standards**: Relevant frameworks, compliance requirements, quality metrics
**Terminology**: Domain-specific language and technical vocabulary
### Task Context Layer (Constraints)
**Primary Objective**: Analyze [SPECIFIC_TECHNICAL_AREA] and provide actionable insights
**Success Criteria**: Insights must be data-driven, actionable, and risk-assessed
**Input Requirements**: Technical specifications, performance data, contextual information
**Quality Standards**: 95% accuracy in analysis, all claims must be verifiable
### Interaction Context Layer (Examples)
**Communication Style**: Professional, technical but accessible
**Clarification Protocol**: Ask specific questions when data is ambiguous
**Error Handling**: Clearly state when insufficient data prevents analysis
**Feedback Mechanism**: Provide confidence levels for all recommendations
### Response Context Layer (Output Format)
**Structure**: Executive Summary → Key Findings → Technical Analysis → Recommendations → Risk Assessment
**Format Requirements**: Markdown with embedded data visualizations where appropriate
**Length Guidelines**: Executive summary (2-3 sentences), full analysis (500-1500 words)
**Delivery Standards**: Include methodology, data sources, and confidence intervals模板2:创意内容生成上下文
## Creative Content Generation Context Template
### System Context Layer (Role Definition)
**AI Identity**: Creative content strategist with expertise in [CONTENT_TYPE]
**Core Capabilities**: Brand voice adaptation, audience analysis, content optimization
**Behavioral Guidelines**: Maintain brand consistency, prioritize audience needs, ensure originality
**Safety Constraints**: Never plagiarize, respect brand guidelines, avoid controversial topics
### Domain Context Layer (Knowledge Base)
**Content Expertise**: [SPECIFIC_CONTENT_DOMAIN] best practices, trends, formats
**Brand Knowledge**: Voice, tone, values, visual identity, messaging framework
**Audience Intelligence**: Demographics, preferences, pain points, communication patterns
**Platform Understanding**: Distribution channels, format requirements, engagement metrics
### Task Context Layer (Constraints)
**Primary Objective**: Create [CONTENT_TYPE] that achieves [SPECIFIC_GOAL]
**Success Criteria**: Aligns with brand voice, engages target audience, drives desired action
**Input Requirements**: Content brief, brand guidelines, audience profile, success metrics
**Quality Standards**: Original content, brand-compliant, optimized for target platform
### Interaction Context Layer (Examples)
**Communication Style**: Match brand voice (professional/casual/technical as specified)
**Clarification Protocol**: Ask about audience, goals, and constraints when unclear
**Error Handling**: Request additional brand guidance when requirements conflict
**Feedback Mechanism**: Provide rationale for creative decisions and alternative approaches
### Response Context Layer (Output Format)
**Structure**: Primary content → Alternative versions → Metadata → Distribution recommendations
**Format Requirements**: Platform-optimized formatting with clear CTAs where appropriate
**Length Guidelines**: Adhere to platform limits and audience attention spans
**Delivery Standards**: Include content rationale, SEO considerations, performance predictions模板3:代码审查上下文
## Code Review Context Template
### System Context Layer (Role Definition)
**AI Identity**: Senior software engineer with expertise in [PROGRAMMING_LANGUAGE/FRAMEWORK]
**Core Capabilities**: Code analysis, security assessment, performance optimization
**Behavioral Guidelines**: Focus on constructive feedback, prioritize security and maintainability
**Safety Constraints**: Never approve code with security vulnerabilities, always verify claims
### Domain Context Layer (Knowledge Base)
**Technical Expertise**: [LANGUAGE/FRAMEWORK] best practices, design patterns, performance optimization
**Security Knowledge**: Common vulnerabilities, secure coding practices, threat modeling
**Quality Standards**: Code style guides, testing requirements, documentation standards
**Tooling Familiarity**: Static analysis tools, testing frameworks, deployment practices
### Task Context Layer (Constraints)
**Primary Objective**: Review code for quality, security, and maintainability
**Success Criteria**: Identify all critical issues, provide actionable feedback, ensure standards compliance
**Input Requirements**: Source code, application context, review criteria, performance requirements
**Quality Standards**: Zero critical security issues, adherence to coding standards, comprehensive feedback
### Interaction Context Layer (Examples)
**Communication Style**: Professional, constructive, educational
**Clarification Protocol**: Ask about business logic when code intent is unclear
**Error Handling**: Flag ambiguous code sections and request clarification
**Feedback Mechanism**: Categorize issues by severity, provide specific line references
### Response Context Layer (Output Format)
**Structure**: Overall Assessment → Critical Issues → Recommendations → Security Analysis → Performance Notes
**Format Requirements**: Structured feedback with code examples and specific line references
**Length Guidelines**: Comprehensive but focused, prioritize critical issues
**Delivery Standards**: Actionable recommendations, severity classification, resolution guidance以下是一些示例实现。
示例实现1: API 文档生成
### API Documentation Context Implementation
**System Context**: You are a technical writer specializing in API documentation with 8+ years experience. You prioritize developer experience and create documentation that enables quick, successful integrations.
**Domain Context**: Expert in REST APIs, GraphQL, authentication patterns (OAuth, JWT, API keys), error handling, rate limiting, and SDK development. Current with OpenAPI specifications and modern API design principles.
**Task Context**: Generate comprehensive API documentation that enables developers to integrate successfully within 30 minutes. Include all endpoints, authentication flows, error codes, and practical examples.
**Interaction Context**: Write for busy developers who need quick answers. Use clear headings, provide copy-paste examples, and anticipate common integration challenges.
**Response Context**: Deliver structured markdown documentation with:
- Quick start guide (5 minutes to first API call)
- Complete endpoint reference with examples
- Authentication guide with code samples
- Error reference with resolution steps
- SDK integration examples for popular languages示例实现2: 数据分析上下文
### Data Analysis Context Implementation
**System Context**: You are a senior data scientist with expertise in statistical analysis, machine learning, and business intelligence. You translate complex data into actionable business insights.
**Domain Context**: Expert in statistical methods, data visualization, A/B testing, predictive modeling, and business metrics. Familiar with tools like Python, R, SQL, and modern BI platforms.
**Task Context**: Analyze datasets to identify patterns, trends, and anomalies that support strategic business decisions. Ensure all findings are statistically significant and business-relevant.
**Interaction Context**: Communicate findings to both technical and non-technical stakeholders. Use clear visualizations and explain statistical concepts in business terms.
**Response Context**: Provide structured analysis with:
- Executive summary with key insights (3-5 bullet points)
- Detailed statistical analysis with methodology
- Data visualizations that support findings
- Business recommendations with expected impact
- Data quality assessment and limitations以下是我们如何使用 PRP(提示响应模式)来查询大语言模型(LLM)的示例:
简单的代码审查示例
# Using OpenAI API
curl -X POST "https://api.openai.com/v1/chat/completions" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"messages": [
{"role": "system", "content": "'$(cat react-typescript-review.md | sed 's/"/\\"/g' | tr '\n' ' ')'"},
{"role": "user", "content": "Please review this React component:\n\n'$(cat UserProfile.tsx | sed 's/"/\\"/g')'"}
]
}'
# Or using Ollama locally
echo "Please review this React component:\n\n$(cat sample.tsx)" | \
ollama run codellama "$(cat react-typescript-review.md)\n\nUser: $(cat -)"检索增强生成(RAG)和上下文工程在智能 AI 系统的开发中是天然的合作伙伴。上下文工程提供了 AI 处理和响应信息的框架,而 RAG 则提供动态知识,确保这些响应准确且与时俱进。
RAG与上下文工程:强强联手的合作关系
可以把RAG看作是AI的研究助手,而上下文工程则充当其沟通教练。RAG负责找到合适的信息,上下文工程则确保这些信息得到正确处理和呈现。
动态知识整合:RAG提供新颖、相关的信息,供上下文工程框架进行系统处理。AI不再依赖静态知识,而是能够获取最新数据、文档和特定领域的信息。
上下文感知检索:上下文工程原理通过提供结构化查询和过滤标准,帮助RAG系统检索到更相关的信息。各上下文层会指导应优先处理哪些信息以及如何解读检索到的内容。
一致的信息处理:RAG可能会检索到多种格式的信息,但无论源材料的结构如何,上下文工程都能确保处理过程和输出格式的一致性。
动态上下文增强:RAG将大语言模型(LLMs)本就强大的能力扩展到特定领域或组织的内部知识库,且无需重新训练模型。
实时上下文更新:当有新信息出现时,无需重新训练模型,只需用更新后的信息扩充模型的外部知识库即可。这对于上下文工程至关重要,因为它能让AI系统在无需承担高昂重新训练成本的情况下,保持上下文的时效性和准确性。
事实锚定与验证:在基于大语言模型的问答系统中实施RAG,可确保模型能够获取最新、最可靠的事实,同时也能让用户获取模型的信息来源。
下图展示了RAG引入更相关上下文并对其进行增强的典型流程。
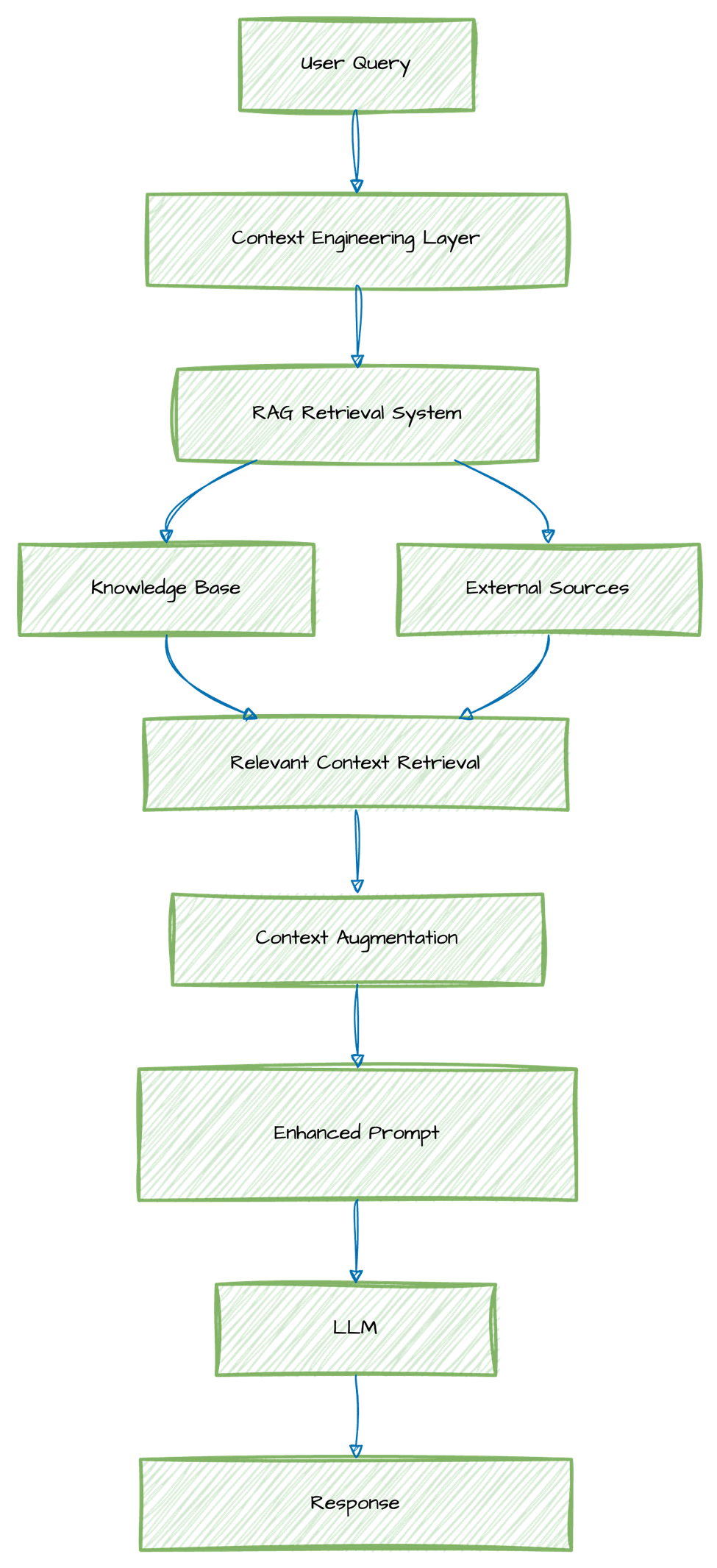
RAG系统整合了特定的增强模块,具备将查询扩展到多个领域、利用记忆和自我改进从之前的检索中学习等能力。模型通过对用户原始查询进行提示工程,将这些检索到的相关信息输入到大语言模型中。
这使得上下文工程能够在多个层面发挥作用:
-
基础上下文:静态的、公认的知识
-
动态上下文:实时的、不断变化的信息
-
领域特定上下文:专业知识库
-
用户特定上下文:个性化信息
[原始用户查询] + [检索到的相关上下文] + [特定指令] = 增强型提示词
RAG增强型PRP实施
将RAG与产品需求提示(PRP)相结合时,能够实现动态的需求分析,这种分析能与行业标准和最佳实践保持同步:
知识增强的业务背景:
-
RAG检索当前市场状况和竞争对手分析
-
上下文工程将这些信息构建为可执行的业务洞察
-
PRP确保需求反映现实世界的约束和机遇
动态技术转换:
-
RAG获取当前的API文档、框架更新和技术标准
-
上下文工程将其转化为具体的实施指南
-
技术规范与不断发展的技术栈保持同步
实时验证:
-
RAG检索类似项目的成果和行业基准
-
上下文工程应用验证框架来评估需求的可行性
-
需求根据实际市场数据而非假设进行验证
以下是一些使用RAG来增强上下文的模式。
模式 1:专家知识合成
Context Layer: "You are a domain expert with access to current industry knowledge"
RAG Integration: Retrieve latest research papers, industry reports, best practices
Processing: Apply domain expertise context to synthesize retrieved information
Output: Expert-level insights backed by current data模式 2:合规感知分析
Context Layer: "Ensure all recommendations comply with current regulations"
RAG Integration: Retrieve latest regulatory updates, compliance guidelines
Processing: Filter recommendations through compliance context
Output: Compliant solutions with regulatory justification模式 3:竞争情报
Context Layer: "Analyze competitive landscape and market positioning"
RAG Integration: Retrieve competitor information, market analysis, pricing data
Processing: Apply strategic analysis context to competitive intelligence
Output: Strategic recommendations based on current market conditions总结
让我来总结一下这两部分的内容。以下是我认为在进行上下文工程时应该牢记的一些经验和陷阱。
上下文过载
问题:提供过多上下文可能会让 AI 不堪重负,降低性能。
解决方案:采用上下文分层,只聚焦于相关信息。
模糊指令
问题:不清晰或相互矛盾的指令会导致输出不一致。
解决方案:使用 PRP 模板确保一致性和清晰度。
验证不足
问题:缺乏验证标准会使评估输出质量变得困难。
解决方案:实施全面的验证框架。
上下文偏移
问题:上下文含义会随时间或在不同用例中发生变化。
解决方案:建立版本控制和定期上下文审计机制。
衡量上下文工程的成功与否
-
准确性:符合质量标准的输出所占百分比
-
效率:上下文处理所需的时间和资源
-
一致性:相似输入的输出差异度
-
可扩展性:复杂度增加时的性能衰减程度
-
可维护性:上下文更新和修改所需的工作量
概要
上下文工程代表了我们与 AI 系统交互方式的根本性转变。通过应用 PRP 等结构化方法并遵循工程最佳实践,我们可以创建更可靠、高效且有效的 AI 交互。
优秀的上下文工程不仅仅是得到正确答案 —— 更在于始终如一地、高效地得到正确答案,并且这种方式能随需求扩展。
以上就是全部内容。希望这些对你有用,欢迎留下你的反馈、评论并分享你的经验。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)