一文说清楚什么是Base LLM,Instruction-Tuned LLM
在实际应用中,建议优先尝试指令微调模型,它们就像已经具备基本能力的 "通用助手",能快速解决大多数实际问题。对于特殊需求,再考虑在基础模型上进行深度定制。其本质就是相当于可以把预训练是大语言模型的 "婴儿期",目标是让模型掌握语言规律,就像人类婴儿通过听大量对话学习语言规则。它们的关系就像毛坯房与精装房,前者需要后续装修才能入住,后者已经配备了各种智能设备。
·
一、AI 世界的 "原始人" 与 "现代人"
在 AI 的世界里,有两个神奇的存在:
- 基础模型 (Base LLM):如同刚学会说话的孩子,掌握了语言规则但缺乏任务意识。
- 指令微调模型 (Instruction-Tuned LLM):如同经过岗前培训的专业助手,能精准完成各种任务。
它们的关系就像毛坯房与精装房,前者需要后续装修才能入住,后者已经配备了各种智能设备。
二、基础模型:语言世界的 "原始人"
1. 预训练:学会语言的魔法
基础模型通过自监督学习,在海量文本中学习语言规律:
其本质就是相当于可以把预训练是大语言模型的 "婴儿期",目标是让模型掌握语言规律,就像人类婴儿通过听大量对话学习语言规则。
# 预训练核心逻辑(伪代码)
def pre_train(model, corpus):
for text in corpus:
# 生成带掩码的输入
masked_text = mask_random_words(text)
# 模型预测被掩码的词
predictions = model(masked_text)
# 计算损失并更新参数
loss = compute_loss(predictions, original_text)
model.backward(loss)
model.update_params()2. 训练流程分解
1. 数据准备
corpus = [
"人工智能正在改变世界",
"机器学习是AI的核心技术",
"大语言模型具有强大的生成能力"
]2. 掩码处理
def mask_random_words(text, mask_ratio=0.15):
words = text.split()
num_mask = int(len(words) * mask_ratio)
for i in np.random.choice(len(words), num_mask, replace=False):
words[i] = "[MASK]"
return " ".join(words)3. 模型预测
def model_forward(input_text):
# 模拟Transformer模型处理过程
embeddings = tokenize(input_text) # 分词并转向量
attention = compute_attention(embeddings) # 计算注意力权重
output = apply_transformer_layers(attention) # 通过多层Transformer
return predict_words(output) # 预测掩码词4. 损失计算
def compute_loss(predictions, original_text):
# 使用交叉熵损失
return cross_entropy(predictions, original_text)3. 通俗类比:儿童语言学习
| 儿童学习阶段 | 预训练过程 | 技术细节 |
|---|---|---|
| 听父母说话 | 处理海量文本 | 互联网、书籍、代码 |
| 模仿发音 | 预测下一个词 | 掩码语言模型 |
| 掌握语法 | 学习语言结构 | Transformer 架构 |
| 积累常识 | 理解世界知识 | 多领域数据训练 |
4. 关键技术点
1. 掩码语言模型(MLM)
# BERT-style预训练
input = "巴黎是[MASK]的首都"
output = model(input) # 预测为"法国"2. 自回归模型(AR)
# GPT-style预训练
input = "法国的首都是"
output = model.generate(input) # 生成"巴黎"3. 多任务学习
# T5-style预训练
input = "translate English to French: Paris is the capital of France"
output = model(input) # 输出"Paris est la capitale de la France"
三、指令微调模型:AI 世界的 "专业助手"
1. 指令微调:岗前培训
# 监督微调示例
dataset = [
{"instruction": "解释相对论", "response": "爱因斯坦提出..."},
{"instruction": "总结文章", "context": "AI改变世界", "response": "AI影响多行业"}
]
def fine_tune(model, dataset):
for example in dataset:
model.learn_instruction(example) # 学习指令-响应模式通俗类比其实跟岗前培训流程差不多!!都包括了:
- 基础培训 (SFT):学习 10 万条指令 - 回应对
- 实战演练 (RLHF):根据人类反馈优化回答
- 安全考试:通过价值观对齐测试
然后再安全对齐,给模型装上 "方向盘"
# 安全模块示意图
def filter_input(input_text):
if "非法" in input_text:
return "无法协助"
return input_text
def constrain_output(output):
if "暴力" in output:
return "此回答不符合规范"
return output四、核心差异对比表
| 对比项 | 基础模型 (Base LLM) | 指令微调模型 (Instruction-Tuned LLM) |
|---|---|---|
| 训练方式 | 自监督学习,无任务优化 | 指令微调 + RLHF,任务导向 |
| 数据类型 | 原始文本数据 | 包含指令 - 响应数据 |
| 响应质量 | 可能偏离指令 | 精准符合用户意图 |
| 典型应用场景 | 需进一步微调才能使用 | 直接用于智能助手、客服等场景 |
| 代表模型 | GPT-3、LLaMA 2 | ChatGPT、DeepSeek Chat |
五、如何选择合适的模型?
1. 开发流程建议
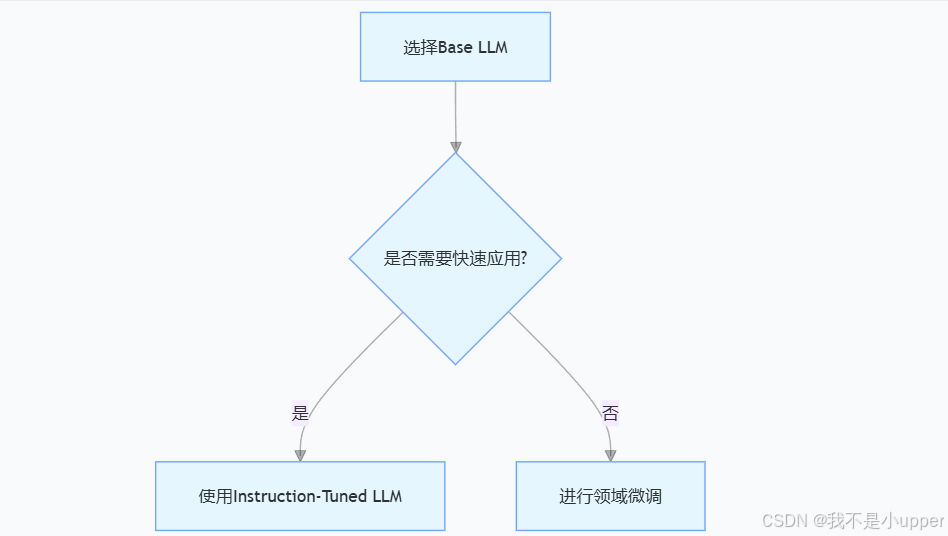
2. 适用场景指南
-
基础模型:
- 学术研究
- 特定领域的深度定制
- 需要高度灵活的文本生成
-
指令微调模型:
- 聊天机器人
- 客服系统
- 任务型应用开发
六、未来发展趋势
- 混合架构:Base LLM + 领域适配器
- 持续进化:动态指令学习
- 伦理安全:AI 价值观对齐
- 多模态融合:文本 + 图像 + 语音联合微调
在实际应用中,建议优先尝试指令微调模型,它们就像已经具备基本能力的 "通用助手",能快速解决大多数实际问题。对于特殊需求,再考虑在基础模型上进行深度定制。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)