Router-R1:让多个大语言模型协同工作的“智能指挥家”
摘要:伊利诺伊大学团队提出Router-R1框架,通过强化学习实现多轮LLM智能路由与聚合,解决现有单轮路由方案在多跳问答等复杂任务中的局限性。该框架能动态协调不同规模的LLM分步协作,在7个问答数据集上均优于基线方法,同时显著降低调用成本(最高减少35%)。其创新之处在于:1)多轮决策机制支持渐进式问题分解;2)三阶段奖励系统平衡准确性、格式规范和成本效率;3)仅需模型描述即可实现零样本泛化。实

如今,大语言模型(LLM)的发展速度让人惊叹,从日常对话答疑到专业领域的深度问答,各种LLM层出不穷。有的模型擅长流畅的文本表达,有的专精于事实准确性,还有的在多步推理上表现突出。但在实际使用中,我们常会遇到一个尴尬的问题:
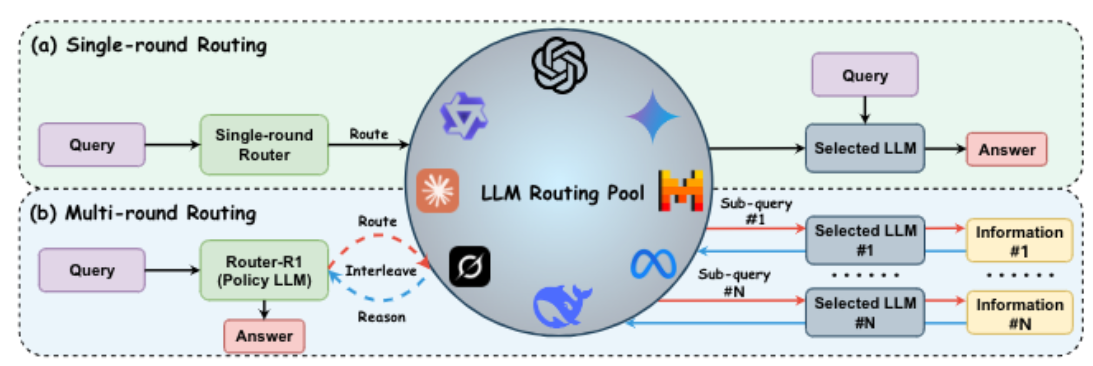
面对复杂任务,比如需要多步验证的多跳问答,单个LLM往往难以兼顾所有需求,这时候如果能让多个LLM协同工作,效果会好很多。可现有的LLM路由工具,大多只能做“一次性选择”,也就是把一个查询分配给一个模型就结束了,没法让多个模型配合着一步步解决问题。为了解决这个痛点,来自伊利诺伊大学厄巴纳-香槟分校的团队提出了Router-R1,一个基于强化学习的多轮LLM路由与聚合框架,它就像“智能指挥家”一样,能协调多个LLM一步步完善答案,还能巧妙平衡回答性能和使用成本。
要理解Router-R1的价值,先得说说现有LLM路由方案的瓶颈:
- 首先,很多路由工具都是“单轮决策”,比如收到一个问题后,直接选一个模型回答,没法根据中间结果调整策略。像“谁是《星际穿越》导演的母校创始人”这类多跳问答,需要先确定导演是诺兰,再查诺兰的母校,最后找母校的创始人,单轮路由根本应付不来,因为它没法分步骤调用不同模型解决每个子问题。
- 其次,这些方案很难处理“非可微决策”,简单说就是选择哪个模型的过程没法通过常规的反向传播训练,要扩展到多轮选择更是难上加难。
- 还有一个关键问题是成本,大模型虽然效果好,但调用费用高,如果不管任务难度都用大模型,会造成不必要的浪费,可现有工具大多没把成本纳入考量,要么只追求性能盲目用大模型,要么只控制成本却牺牲了准确性。
Router-R1的核心思路,就是把多LLM协作变成一个“循序渐进的决策过程”,而不是一次性的模型选择。它本身就用一个能力较强的LLM当“路由器”,这个路由器不只是简单分配任务,还会主动“思考”,收到问题后,先分析“这个问题需要哪些信息”“我现有的知识够不够”,如果判断需要外部帮助,再根据模型的特点选择最合适的LLM调用,拿到结果后又把信息整合到自己的推理过程中,一步步接近最终答案。这种“思考”和“路由”的交替,让它能灵活利用不同LLM的优势,比如用小模型处理简单的事实查询,用大模型攻克复杂的推理步骤,避免了“大材小用”或“小材大用”的尴尬。
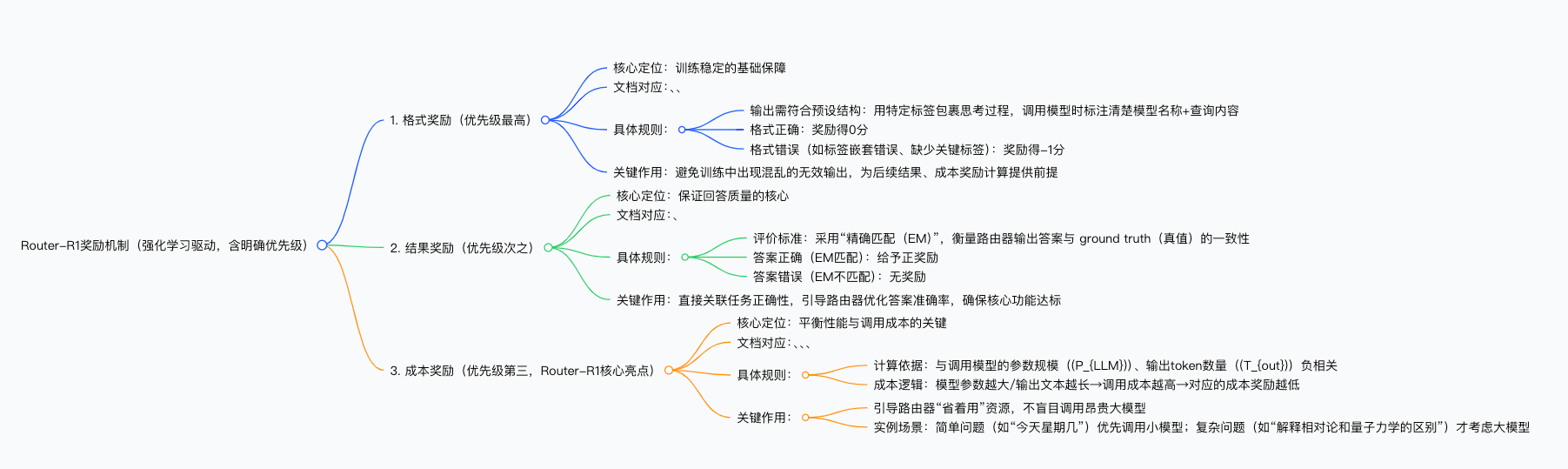
为了让这个“路由器”学会最优策略,团队用了强化学习(RL),还设计了一套实用的奖励机制。这套机制分三部分,而且有明确的优先级,确保训练既稳定又有效:
- 首先是格式奖励,它要求路由器的输出必须符合预设结构,比如用特定标签包裹思考过程、调用模型时标注清楚模型名称和查询内容,要是格式错了就会被扣分,这一步是基础,避免训练中出现混乱的无效输出。
- 然后是结果奖励,用“精确匹配”(EM)来判断答案是否正确,答对了就给正奖励,答错了则没有,这是保证回答质量的核心。
- 最后是成本奖励,这是Router-R1的一大亮点,它会根据调用模型的参数规模和输出token数量计算成本,模型参数越大、输出文本越长,调用成本就越高,对应的成本奖励就越低,这样路由器在训练中会慢慢学会“省着用”,不盲目调用昂贵的大模型。比如面对简单的“今天星期几”这类问题,它会优先调用小模型,只有遇到“解释相对论和量子力学的区别”这种复杂问题时,才会考虑大模型。
还有一个细节特别实用,Router-R1不用提前“认识”所有LLM。它做决策时,只依赖模型的简单描述,比如价格、响应速度、过去在类似任务中的表现,这些信息不需要复杂的训练数据,只要新模型的描述清晰,Router-R1不用重新训练就能直接调用。比如后来团队加入了Palmyra-Creative-122B(擅长创意写作)和LLaMA3-ChatQA-1.5-8B(专精对话问答)这两个之前没接触过的模型,Router-R1只需要获取它们的参数规模、调用成本等基本信息,就能把它们纳入协作体系,而且性能还略有提升,这种泛化能力对快速更新的LLM生态来说太重要了。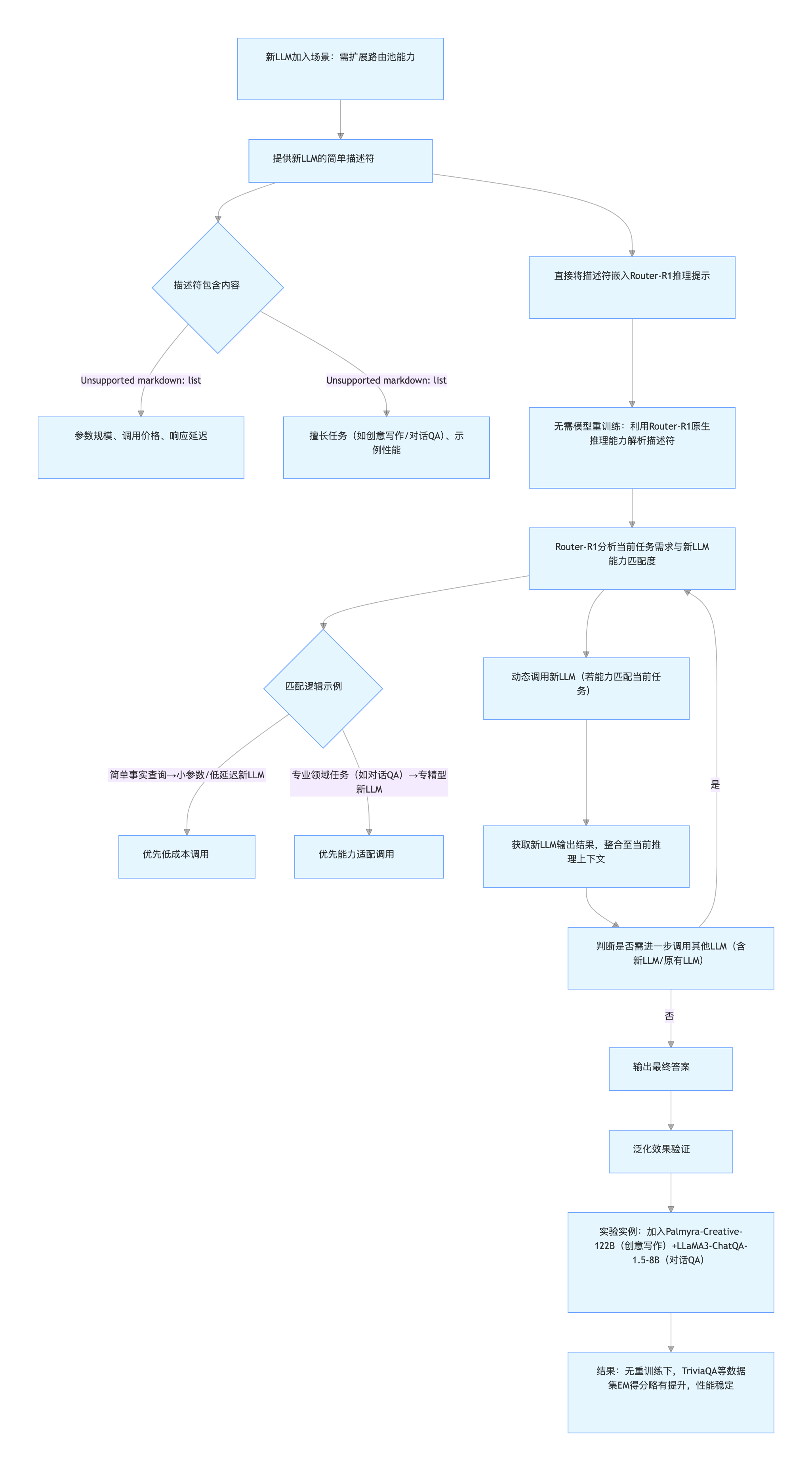
为了验证Router-R1的效果,团队在七个问答数据集上做了全面测试,这些数据集既有普通的单步问答(比如NQ、TriviaQA),也有需要多步推理的多跳问答(比如HotpotQA、2WikiMultiHopQA),基本覆盖了日常和专业场景的问答需求。对比的基线也很全面,包括直接用单个LLM推理、基于思维链(CoT)的提示方法、检索增强生成(RAG),还有其他主流的LLM路由工具比如GraphRouter、RouterDC等,确保结果的说服力。
实验结果很直观,Router-R1在所有数据集上都超过了这些基线。比如在通用问答数据集NQ上,它的精确匹配(EM)得分比直接用基础LLM推理高了近30个百分点,比同样支持多轮交互的Search-R1也高了8个百分点左右;在多跳问答数据集HotpotQA上,它的优势更明显,EM得分比单轮路由的GraphRouter高了12个百分点,因为这类任务需要多模型协作,正好发挥了Router-R1多轮路由的特长。有意思的是,即使面对没见过的LLM,Router-R1也能保持稳定表现,比如加入Palmyra-Creative-122B后,它在TriviaQA上的EM得分还提升了2个百分点,证明它不是靠“死记硬背”模型特点,而是真的能通过描述判断模型能力。
更值得关注的是成本控制能力。当调整成本系数时,Router-R1能灵活切换策略:系数低的时候,它更看重性能,会适当调用大模型;系数高的时候,它会优先用小模型,只有小模型搞不定才升级。比如当成本系数设为0.6时,它的EM得分和不考虑成本时(系数0.0)相比只下降了2个百分点,但调用大模型的次数少了近40%,平均每次查询的成本降低了35%。这种“精打细算”的能力在实际应用中很有价值,比如企业用它处理客服问答,既能保证回答准确,又能控制API调用成本,不用为简单问题浪费大模型资源。
Router-R1的出现,不只是技术上的突破,还有实际应用中的深层意义。
- 首先,它降低了多LLM协作的门槛,过去要让多个LLM配合工作,需要人工设计复杂的调用规则,比如“什么问题用A模型,什么问题用B模型”,而Router-R1能自动学习最优策略,企业不用再投入大量人力调试,开发效率大大提升。
- 其次,它能减少不必要的大模型调用,这不仅能降低财务开销,还能减少计算资源的浪费,要知道,大模型的训练和推理都需要大量电力,减少调用相当于间接降低了碳排放,符合绿色AI的发展趋势。
- 还有,它的泛化性让新LLM能快速融入现有系统,不用每次有新模型发布都重新训练路由工具,这在LLM更新频繁的当下,能帮企业节省大量时间和成本。
当然,Router-R1也不是完美的,还有一些需要改进的地方。目前它主要在问答任务上做了测试,能不能顺利用到对话生成、文本摘要、代码生成这些领域,还需要进一步验证,毕竟不同任务的需求差异很大,比如对话需要连贯性,摘要需要简洁性,路由策略可能得调整。而且多轮交互虽然效果好,但会增加推理延迟,每多一轮调用,就需要等模型返回结果,对于语音助手、实时客服这类对响应速度要求高的场景,可能还需要优化延迟问题。另外,它依赖的模型描述符如果不够详细,可能会影响对新模型的判断,比如只看参数规模和价格,没法完全捕捉模型的细微能力差异,比如有的小模型虽然参数小,但在特定领域(如医疗问答)比大模型还准,这时候Router-R1可能会错过更优选择。
不过这些局限也指明了未来的改进方向,比如可以优化奖励机制,加入更细致的评价指标,比如事实一致性、文本连贯性,让Router-R1不只追求“答对”,还能保证“答得好”;或者通过技术手段减少推理延迟,比如提前预判哪些问题需要多轮调用,哪些一步就能解决,避免不必要的等待。
总的来说,Router-R1为多LLM协同工作提供了一种全新的思路,不是让单个模型“独当一面”,而是让多个模型“分工协作”。它既解决了现有路由工具的单轮局限,又平衡了性能和成本,还具备良好的泛化性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)