基因集预后模型泛滥了?关我Transformer什么事!!!
第四步,将多头连接后的矩阵依次通过全连接层、ReLU 层、随机 dropout 层、另一全连接层与另一随机 dropout 层,最后再进行层归一化。a.维恩图基于以 cGAS-STING 为中心的通路中按 AUC 选取的特征,展示用于预测抗 PD-1/PD-L1 应答结局的特征筛选结果。作者先在 TCGA-LIHC 中计算了 cGAS–STING 通路的 ssGSEA 分数,随后与 50 个 ha
生信碱移
transformer预后模型
基因集的预后模型是泛滥了,好吧得加个前缀 Transformer 了。
大众基因集/通路层面的肿瘤研究在2025年可以说是寸步难行,主要还是大部分文章分析都比较常见,期刊编辑也是见多不怪。
这两天小编看到一篇年初发表在Briefings in Bioinformatics [IF:7.7] 的肿瘤纯生信研究,同样聚焦在一个通路,是与先天免疫与肿瘤微环境的 cGAS–STING。不过在常规分析的基础上,作者引入了概念性的①大语言模型框架 Transformer 对肝细胞癌构建了预后模型。除此之外,还用② XGBoost 构建了一个 PD-1/PD-L1 免疫治疗应答二分类模型。

DOI: 10.1093/bib/bbae686。
文章的主要分析都比较常见,小编主要带大家看看这两个模型。
首先是基于 transformer 的预后模型。作者先在 TCGA-LIHC 中计算了 cGAS–STING 通路的 ssGSEA 分数,随后与 50 个 hallmark 通路做 Spearman 相关,鉴定了与 cGAS–STING 相关的多个通路。
在此基础上,将样本的 TPM 矩阵经标准化、层归一化与缺失值填补作为模型输入。模型架构其实就是两层 Transformer 编码器,说是用来提取通路间的全局依赖与非线性交互,最后输出 0–1 的样本风险分数。最后,基于 DeepSurv 框架的 Cox 部分似然负对数损失函数,配合 L2 正则进行训练。对 DeepSurv 感兴趣的同学,可以阅读小编两年前的分享DeepSurv深度学习预后模型。
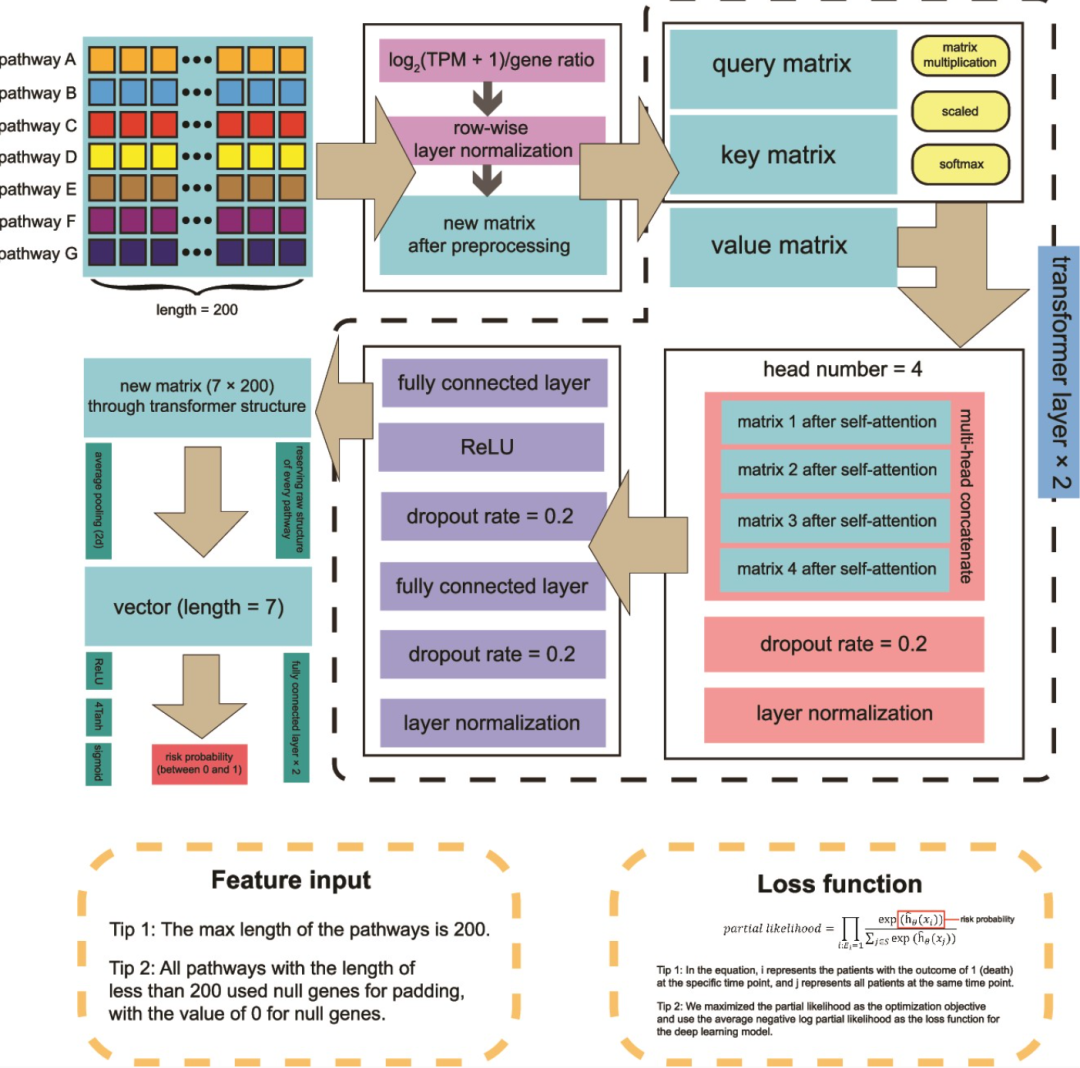
图:文章预后模型的结构。以 cGAS–STING 为中心的通路作为特征输入,对基因数少于 200 的通路用取值为 0 的“空基因”进行填充。在第一步,对输入基因进行预处理,包括对数变换、样本表达校正以及按行的层归一化。第二步,在预处理后的矩阵上执行自注意力操作,得到查询(Q)、键(K)和值(V)矩阵;经由矩阵乘法、归一化与 softmax 后,将三者转换为新的 7×200 矩阵。第三步,对自注意力后的矩阵进行多头连接,随后以 0.2 的概率进行随机 dropout,并做层归一化。第四步,将多头连接后的矩阵依次通过全连接层、ReLU 层、随机 dropout 层、另一全连接层与另一随机 dropout 层,最后再进行层归一化。第五步,对得到的 7×200 矩阵做平均池化,得到长度为 7 的一维向量;再依次通过全连接层、ReLU 层与另一全连接层,将其长度变为 1。第六步,为确保预测的 HCC 风险概率位于 0–1 区间,依次对最终输出施加 ReLU、4Tanh 与 sigmoid 变换。
第二个模型就比较简单了,主要是基于 XGBoost 构建一个免疫检查点治疗反应二分类模型,用于预测抗 PD-1/PD-L1 疗效。输入特征也是使用 cGAS–STING 为中心的通路/基因表达表征,在 R 使用 xgboost 就可以完成训练了。作者后续还使用 SHAP 分析每个特征的重要性,也做了 TIDE 免疫逃逸得分这样的常见分析。
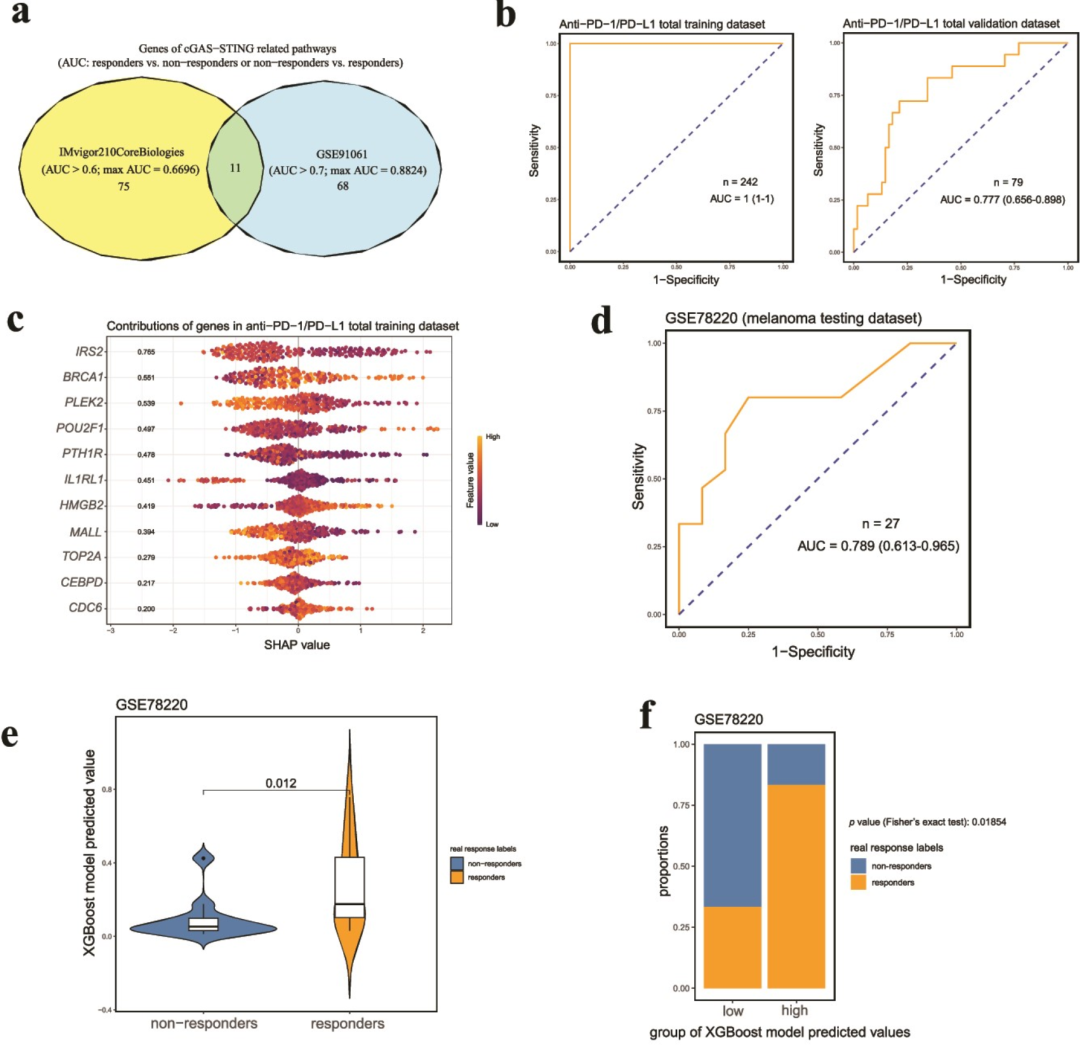
图:用于预测抗 PD-1/PD-L1 应答结局的可解释 XGBoost 模型的训练、验证与测试。a.维恩图基于以 cGAS-STING 为中心的通路中按 AUC 选取的特征,展示用于预测抗 PD-1/PD-L1 应答结局的特征筛选结果。b.两条 ROC 曲线分别显示模型在训练集与验证集上的预测能力。c.散点呈现总训练集中各样本的各变量 SHAP 值,左侧数值为各变量的重要性。d.ROC 曲线展示 XGBoost 模型在 GSE78220 数据集中的预测性能。e.小提琴图比较 GSE78220 数据集中非应答者与应答者的模型预测概率。f.条形图展示 GSE78220 数据集中 XGBoost 模型预测概率高低分组内非应答者与应答者的构成比例。
换个基因集复现一下?
从学习和发表两个层面都有意义
各位佬哥佬姐关注起来啊

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)