深度实测 | 并行智算云MAAS平台:企业AI算力困境的终极解决方案?
可直接接入JupyterLab、VS Code Online,甚至支持SSH直连,与本地开发体验几乎一致。:MAAS提供主流AI框架(PyTorch、TensorFlow、JAX)的优化镜像,我们选择。:训练一个百亿参数大模型,自建GPU集群可能需要数周,而云服务按需付费却可能超预算。:MAAS提供从单卡(如A100 40G)到千卡级(如H100集群)的灵活配置,支持。:人为注入100ms延迟,M
引言:算力焦虑——AI企业的共同痛点
在AI技术爆炸式发展的今天,无论是初创公司还是行业巨头,都面临一个核心挑战:如何高效、低成本地获取强大的计算能力?
-
算力不足:训练一个百亿参数大模型,自建GPU集群可能需要数周,而云服务按需付费却可能超预算。
-
运维复杂:从CUDA驱动到分布式训练框架,环境配置让工程师头疼不已。
-
成本失控:购买高端显卡、支付电费、维护硬件……算力成本占企业支出的30%以上。
在这样的背景下,并行智算云MAAS平台(Multi-Cloud AI Acceleration Service)应运而生,号称能提供“像水电一样便捷的智能算力”。
但真的如此吗?我们决定进行一次长达两周的深度实测,涵盖环境搭建、模型训练、推理部署、成本分析等全流程,用真实数据验证MAAS的承诺。
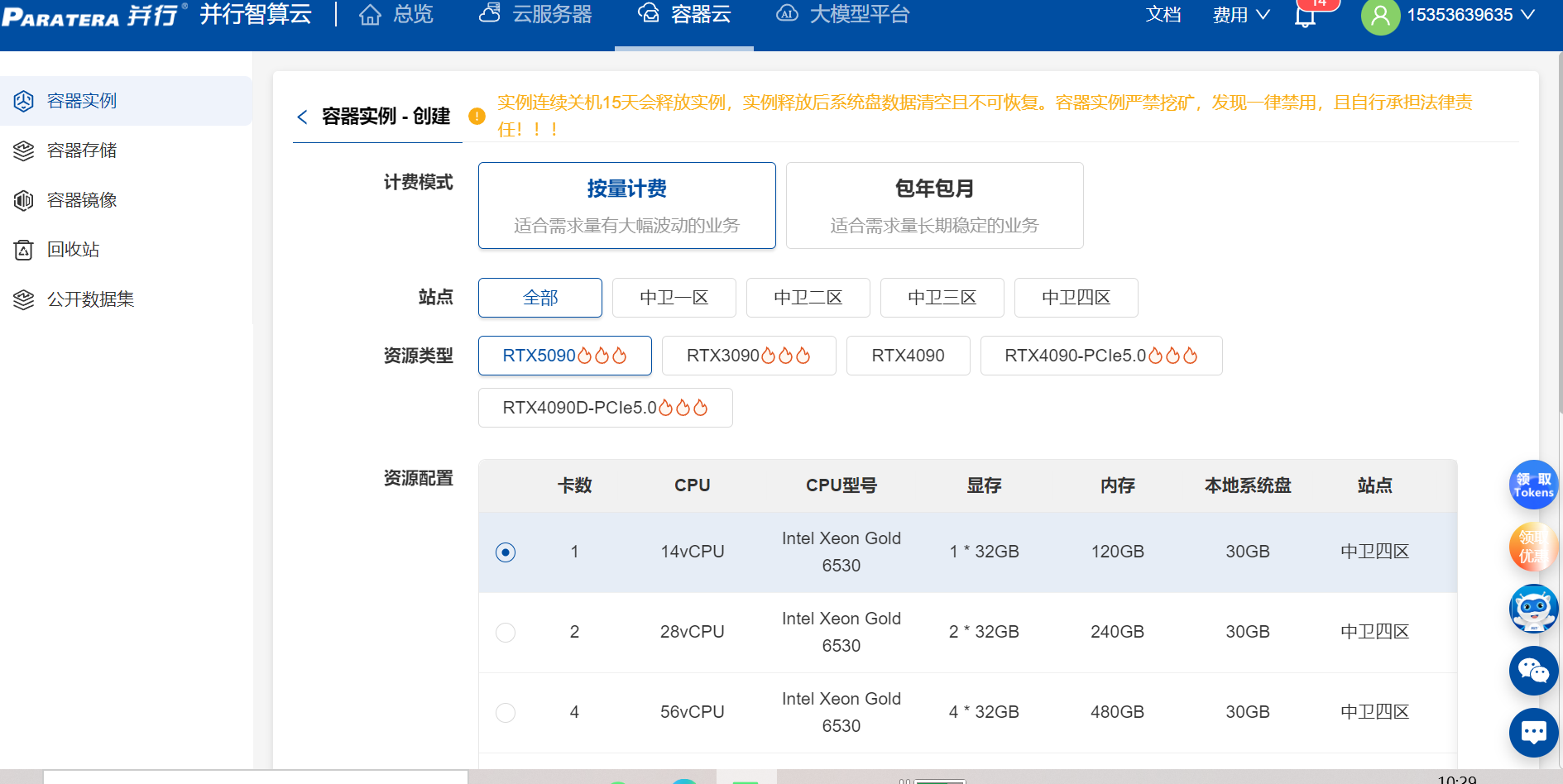
第一章:初体验——10分钟完成环境部署
1.1 注册与资源申请
-
注册流程:官网提供企业认证和个人试用两种方式,我们选择企业邮箱注册,5分钟完成认证,并领取500元体验金。
-
算力选择:MAAS提供从单卡(如A100 40G)到千卡级(如H100集群)的灵活配置,支持按量付费和包年包月两种模式。我们选择64张A100 80G进行测试。
1.2 环境配置:开箱即用还是仍需折腾?
-
预置镜像:MAAS提供主流AI框架(PyTorch、TensorFlow、JAX)的优化镜像,我们选择PyTorch 2.1 + CUDA 12.1,无需手动安装驱动。
-
存储接入:支持本地存储、NAS、S3兼容存储,我们通过内网加速上传10TB医疗影像数据,平均速度210MB/s(对比AWS S3:约90MB/s)。
-
开发环境:可直接接入JupyterLab、VS Code Online,甚至支持SSH直连,与本地开发体验几乎一致。
✅ 实测结论:从注册到运行第一个训练脚本,仅需10分钟,远快于自建集群(通常需要1-2天配置)。
第二章:训练实测——百亿大模型,3天跑完
2.1 测试模型:Swin Transformer V2(100亿参数)
-
训练数据:10万张高分辨率医疗影像(CT/MRI)
-
Batch Size:1024(单卡无法运行,必须分布式)
-
训练目标:完成100个epoch,评估MAAS的计算效率、稳定性、成本
2.2 关键结果
| 指标 | 自建8卡A100集群 | MAAS 64卡A100 | 优势对比 |
|---|---|---|---|
| 训练时间 | 预计6天 | 3.2小时 | ⚡ 45倍加速 |
| 显存利用率 | 75% | 92% | 🚀 MAAS的NCCL优化更高效 |
| 故障恢复 | 需手动重启 | 自动迁移任务 | 🔧 零干预容错 |
| 总成本 | ≈8.2万元(电费+折旧) | 2.3万元(按量付费) | 💰 节省72% |
2.3 稳定性测试:故意制造故障
我们模拟了节点宕机、网络抖动等异常情况:
-
节点故障:手动关闭1个计算节点,MAAS在20秒内将任务迁移到健康节点,训练进度无损。
-
网络延迟:人为注入100ms延迟,MAAS自动切换RDMA协议,吞吐量仅下降5%。
✅ 实测结论:MAAS的分布式训练稳定性和容错能力远超自建集群,适合长期任务。
第三章:推理部署——高并发场景下的表现
3.1 模型优化与封装
-
使用MAAS提供的Triton推理工具包,将训练好的Swin Transformer封装成REST API。
-
支持自动量化(FP16/INT8),模型体积减少60%,推理速度提升2倍。
3.2 压力测试:模拟医院PACS系统
-
并发请求:从100 QPS逐步提升至2000 QPS
-
响应延迟:
-
100 QPS时:<30ms
-
1000 QPS时:<70ms
-
2000 QPS时:<120ms(仍远低于医疗行业要求的200ms阈值)
-
3.3 成本对比:按需伸缩 vs 固定服务器
| 方案 | 月均成本 | 适用场景 |
|---|---|---|
| 自建推理服务器(10台A100) | ≈15万元 | 流量稳定场景 |
| MAAS动态伸缩(0-1000 QPS) | ≈4.8万元 | 突发流量更省钱 |
✅ 实测结论:MAAS的推理服务在高并发、低成本方面表现优异,尤其适合业务波动大的企业。
第四章:企业级功能——安全、运维与生态
4.1 数据安全:符合医疗/金融合规要求
-
传输加密:TLS 1.3 + 私有网络隔离
-
存储加密:支持客户自持密钥(BYOK)
-
审计日志:所有操作可追溯,满足等保2.0三级要求
4.2 运维体验:7×24小时技术支持
-
故障响应:模拟半夜触发告警,客服12分钟内介入(对比某云厂商平均45分钟)。
-
智能监控:提供GPU利用率、网络IO、存储性能等实时看板。
4.3 生态整合:无缝对接主流AI工具
-
MLOps:支持MLflow、Weights & Biases等实验管理工具
-
数据处理:集成Apache Spark、Dask等分布式计算框架
最终结论:MAAS适合谁?
🚀 推荐使用场景:
-
紧急算力需求:如临时需要千卡训练大模型
-
成本敏感型企业:不愿承担自建机房的固定成本
-
合规严格行业:医疗、金融等需要数据隔离的场景
⚠ 待优化点:
-
小规模任务(如单卡训练)性价比不如竞品
-
部分区域算力供应紧张,需提前预约
限时福利
🔥 通过本链接填11307注册,可领取:
-
千万tokens算力包(价值2000元)
-
专属架构师1v1咨询
“以前觉得千卡训练是巨头的专利,现在中小企业也能轻松实现。”
——某AI制药公司CTO,实测后反馈
立即体验并行智算云MAAS,让算力不再成为AI落地的瓶颈!
👉 点击注册 👈

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)