【读点论文】TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document专用OCR大模型,优化token采样策略
通过同时参与多个面向文本的任务,TextMonkey增强了其对空间关系的感知和理解,从而提高了可解释性并支持点击屏幕截图。通过将我们的模型与各种lmm进行比较,我们的模型在多个基准上取得了优异的结果。值得一提的是,我们还发现直接提高输入分辨率并不总能带来改善,尤其是对于小得多的图像。这强调了创建一种有效的方法来缩放尺寸变化剧烈的文档中的分辨率的必要性。采用零初始化的移位窗口注意力来帮助建立关系,同
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Abstract
- 我们提出了TextMonkey,一个为以文本为中心的任务定制的大型多模态模型(LMM)。我们的方法在几个维度上引入了增强:通过采用零初始化的移位窗口注意,我们在更高的输入分辨率下实现了跨窗口连接,并稳定了早期训练;我们假设图像可能包含冗余标记,通过使用相似性来过滤掉重要的标记,我们不仅可以简化标记长度,还可以增强模型的性能。
- 此外,通过扩展我们的模型的能力,以包含文本定位和背景,并将位置信息纳入回应,我们增强了可解释性。它还通过微调学习执行截图任务。在12个基准测试上的评估显示了显著的改进:以场景文本为中心的任务(包括STVQA、TextVQA和OCRVQA)提高了5.2%,面向文档的任务(如DocVQA、InfoVQA、ChartVQA、DeepForm、Kleister Charity和WikiTableQuestions)提高了6.9%,关键信息提取任务(包括FUNSD、SROIE和POIE)提高了2.8%。
- 它在场景文本识别方面表现出色,提高了10.9%,并在OCRBench上设立了新的标准,OCR bench是一个由29项OCR相关评估组成的综合基准,得分为561,超过了之前用于文档理解的开源大型多模态模型。代码将在以下位置发布:GitHub - Yuliang-Liu/Monkey: Monkey (LMM): Image Resolution and Text Label Are Important Things for Large Multi-modal Models (CVPR 2024 Highlight)。
- TextMonkey,一个针对文本中心任务的大型多模态模型(LMM),提到了其采用的 Shifted Window Attention、Token Resampler,以及在多个基准测试中的提升,比如 Scene Text-Centric 任务 5.2%,Document-Oriented 任务 6.9%,OCRBench 得分 561 等。TextMonkey是一款专为文本中心任务设计的大型多模态模型(LMM),通过采用Shifted Window Attention with zero-initialization实现高分辨率输入下的跨窗口连接并稳定训练,利用相似性过滤冗余令牌的 Token Resampler 精简令牌长度并提升性能,同时集成文本定位、 grounding 及位置信息增强可解释性,还通过微调掌握截图任务。
- 核心创新方法:Shifted Window Attention,零初始化稳定训练,实现跨窗口连接,处理高分辨率图像;Token Resampler,基于相似性过滤冗余令牌,压缩令牌长度,提升性能;位置相关任务,集成文本定位与grounding,响应中包含位置信息,增强可解释性。
- Shifted Window Attention with zero-initialization:采用滑动窗口分割高分辨率图像,通过 Shifted Window Attention 建立跨窗口连接,结合零初始化稳定早期训练,平衡高分辨率处理与计算效率。
- Token Resampler:针对高分辨率导致的令牌冗余,基于相似性筛选关键令牌,压缩令牌长度的同时保留重要特征,性能优于随机筛选。
- 位置信息融合:通过文本定位、grounding 任务及修改数据集引入位置线索,要求模型输出答案时附带视觉证据,减少幻觉问题,增强可靠性。
- 总参数 9.7B:包括 7.7B 参数的 LLM、1.9B 参数的视觉编码器、90M 参数的 Image Resampler、13M 参数的 Token Resampler、45M 参数的 Shifted Window Attention;AdamW 优化器(学习率 1e-5→5e-6,余弦调度),batch size=128,权重衰减 0.1,训练周期 12 A800 天。
INTRODUCTION
-
从各种来源提取关键信息,包括表格、表单和发票等文档,以及野外的文本,对于行业和学术研究至关重要,旨在自动化和优化基于文档和场景文本的工作流。该领域需要文档图像和真实世界场景中的文本检测和识别、语言理解以及视觉和语言的整合。
-
许多早期的方法试图使用两阶段的方法来处理该任务:1)使用外部系统检测和识别文本;2)基于文本结果和图像融合的文档理解。然而,处理管道中文本读取的单个步骤可能导致错误的累积。此外,依赖现成的OCR模型/API(OCR模型)会引入额外的工程复杂性,限制文本与其周围环境之间的联系,并可能增加计算成本。为了在理解之前减轻外部系统的缺点,无OCR解决方案 ,最近吸引了越来越多的关注。
-
大型多模态模型(lmm) 领域发展迅速,因为它具有处理不同类型数据的强大能力。然而,在处理与文本相关的任务时,它们仍然有局限性。如图1 (a)所示,包括LLaVAR 、UniDoc 、TGDoc 和mPLUG-DocOwl 在内的几种方法严重依赖预训练剪辑进行视觉编码。然而,这些编码器的输入分辨率为224或336,不足以满足包含大量小文本的文档的需求。所以他们只能识别大文字,在图像中与小文字斗争。为了解决微小文本的局限性,UReaer 和Monkey 采用了裁剪策略来扩展输入分辨率,如图1 (b)所示。但是,这种裁剪策略可能会在不经意间将相关词拆分,导致语义不连贯。
-

-
图1:与现有文档理解管道的比较。与(a)基于调整大小的方法、(b)基于裁剪的方法和©基于频率的方法相比,我们的模型可以有效地处理具有各种任务的高分辨率文本相关图像。
-
-
例如,单词“Backup”可能被分为“Back”和“up”,使得即使在执行了融合之后也不可能恢复其原始含义。此外,这种分割导致的空间分离也使得处理文本位置相关的任务,如文本背景,变得具有挑战性。如图1 ©所示,DocPedia 直接在频域而不是像素空间中处理视觉输入。由于频域的特性,它可以在不丢失信息的情况下快速扩展分辨率。然而,由于特征空间的转换,很难利用现有的预训练模型,增加了对训练资源的需求。
-
我们希望继承Monkey 的高效图像分辨率缩放特性,但解决上述文档缺少跨窗口上下文的问题。为此,我们引入了 TextMonkey,如图1 (d)所示。TextMonkey使用一个分割模块,该模块使用滑动窗口方法将高分辨率图像分成窗口补丁。受[Swin transformer]的启发,我们将剪辑中的每一个自我关注层都视为非重叠窗口中的自我关注。为了在保持高效计算的同时引入跨窗口关系,我们使用零初始化的转移窗口注意力来建立跨窗口连接。
-
这种方法允许我们维护编码器的训练数据分布并处理高分辨率文档图像,同时从头开始减少训练的计算成本。另一方面,分割模块的使用仍然提出了重大挑战,因为它导致令牌长度的显著增加。我们已经观察到,有许多重复的图像特征与语言空间一致,类似于语言本身中的某些重复元素。因此,我们提出了一个令牌重采样器来压缩这些特征,同时尽可能多地保留最重要的特征。我们使用重要的标记作为查询,使用原始的特征作为键值对,这有助于特征的重新聚集。在减少令牌数量的基础上,我们的模块相比随机查询也能显著提高性能。
-
另一方面,由于文本的自解释性质,在大多数情况下,人类能够定位答案本身的位置。为了进一步缓解大型语言模型中的幻觉问题,我们要求模型不仅提供准确的答案,而且定位支持其响应的特定视觉证据。我们还介绍了各种文本相关的任务,以加深文本信息和视觉信息之间的联系,如文本定位和文本基础。此外,在答案中加入位置线索可以进一步提高模型的可靠性和可解释性。我们将我们方法的优点总结如下:
-
加强跨窗口关系。在扩展输入分辨率的同时,我们采用了改进的窗口注意来成功地整合跨窗口连接。此外,我们在移位窗口注意机制中引入零初始化,使得模型能够避免对早期训练的剧烈修改。
-
令牌压缩。我们显示,扩大分辨率导致一些冗余的令牌。通过使用相似性作为标准,我们能够找到重要的记号,作为记号重采样器的查询。该模块不仅减少了令牌长度,而且提高了模型的性能。此外,与使用随机查询相比,它显著提高了性能。
-
支持 text grounding。我们将我们的范围扩展到基于文本的问题回答之外的任务,包括阅读文本、文本定位和文本基础。此外,我们发现将位置信息整合到答案中可以提高模型的可解释性。TextMonkey也可以被微调以理解屏幕截图点击的命令。
-
我们在12个公认的基准上评估了TextMonkey的性能,观察到了几个方面的显著改进。首先,在STVQA、TextVQA、OCRVQA等以场景文本为中心的任务中,TextMonkey实现了5.2%的性能提升。对于面向文档的任务,包括DocVQA、InfoVQA、ChartVQA、DeepForm、Kleister Charity和WikiTableQuestions,它显示了6.9%的改进。在关键信息提取任务领域,如FUNSD、SROIE和POIE,我们注意到有2.8%的提升。
-
特别值得注意的是它在场景文本定位任务(Total-Text、CTW1500和ICDAR 2015)中的性能,该任务侧重于转录准确性,提高了10.9%。此外,TextMonkey在OCRBench上创下了561分的新高,这是一个包含29项OCR相关评估的综合基准,大大超过了以前为文档理解而设计的开源、大规模多模态模型的性能。这一成就强调了TextMonkey在文档分析和理解领域的有效性和进步。
-
-
采用Shifted Window Attention with zero-initialization实现高分辨率输入下的跨窗口连接并稳定训练;提出Token Resampler基于相似性过滤冗余令牌,精简长度并提升性能;扩展至文本定位与 grounding 任务,在响应中融入位置信息增强可解释性。
RELATED WORKS
- 设计用来理解带有文本信息的图像的模型可以大致分为两种类型:OCR模型驱动的方法和非OCR方法。
OCR-Model-Driven Methods
-
OCR模型驱动的方法使用OCR工具来获取文本和边界框信息。随后,他们依靠模型来集成文本、布局和视觉数据。同时,不同的预训练任务被设计来增强视觉和文本输入之间的跨模态对齐。StrucTexT 在预训练任务的设计中,注重图像内部的细粒度语义信息和全局布局信息。ERNIE-Layout 基于版面知识增强技术,创新性地提出了两个自我监督的预训练任务:阅读顺序预测和细粒度图文匹配。LayoutLM 系列通过集成预先训练的文本、布局和视觉特征并引入统一的模型架构和预先训练目标来不断改进。这增强了模型在各种文档理解任务中的性能,并简化了整体设计。UDOP 通过VTL Transformer 和统一的生成式预训练任务统一了视觉、文本和布局。
-
Wukong reader 提出了文本行-区域对比学习和特制的预训练任务来提取细粒度的文本行信息。DocFormerv2 为可视化文档理解设计了非对称预训练方法和简化的视觉分支。DocLLM 专门关注位置信息以结合空间布局结构,使用分解的注意力机制来建立文本和空间模态之间的交叉对齐。
-
虽然已经取得了进步,但OCR模型驱动的方法依赖于从外部系统提取文本,这需要增加计算资源并延长处理持续时间。此外,这些模型可能会继承OCR的不准确性,给文档理解和分析任务带来挑战。
OCR-Free Methods
-
OCR-Free 方法不需要现成的OCR引擎/API。Donut 首先提出了一种基于无OCR的Transformer的端到端训练方法。Dessurt 基于一个类似于Donut的架构,结合了双向交叉注意,并采用了不同的预训练方法。Pix2Struct 通过学习将网页的屏蔽截图解析为简化的HTML来进行预训练,引入了可变分辨率的输入表示和更灵活的方式来集成语言和视觉输入。StrucTexTv2 引入了一种新的自我监督预训练框架,采用文本区域级文档图像掩蔽来学习端到端的视觉文本表示。
-
虽然这些方法不需要OCR工具的限制,但它们仍然需要针对特定任务进行微调。在多模态大型语言模型(MLLMs)快速发展的时代,一些模型在视觉文本理解数据集上进行显式训练,并使用指令进行微调。LLaVAR 、mPLUG-DocOwl 和UniDoc 创建了新颖的指令跟踪数据集,以增强调优过程并提高对文本丰富的图像的理解。已经进行了额外的努力来捕捉更复杂的文本细节。UReader 设计了一个形状自适应裁剪模块,它利用一个冻结的低分辨率视觉编码器来处理高分辨率图像。DocPedia 在频域而不是像素空间中处理视觉输入,以处理具有有限视觉表征的更高分辨率图像。通过在大量数据上训练视觉词汇,Vary 扩展了其分辨率并取得了令人印象深刻的结果。最近,TGDoc 使用文本背景来增强文档理解,提出文本背景可以提高模型解释文本内容的能力,从而增强其对富含文本信息的图像的理解。
METHODOLOGY
-
图2中呈现的方法开始于使用滑动窗口模块将输入图像分成不重叠的小块,每个小块的大小为448×448像素。这些小块被进一步细分成更小的14×14像素的小块,每个小块被视为一个令牌。利用从预训练剪辑模型继承的变换器块,我们在每个窗口小块上分别处理这些令牌。为了在各种窗口小块之间建立连接,在 Transformer 块内的特定间隔处集成了转移的窗口注意力。为了生成分层表示,将输入图像的大小调整为448x448,并馈入CLIP以提取全局特征,如[Monkey: Image resolution and text label are important things for large multi-modal models]所建议的。然后,这个全局特征连同来自子图像的特征由共享图像重采样器处理,以与语言域对齐。然后,使用记号重采样器,通过压缩记号的长度来进一步最小化语言空间中的冗余。最终,这些经过处理的特征,结合输入的问题,由大型语言模型(LLM)进行分析,以产生所需的答案。
-

-
图2 ,TextMonkey的概述。它能够利用有限的训练资源增强分辨率,同时保留跨窗口信息并减少由分辨率增强引入的冗余令牌。此外,通过各种数据和代理提示,TextMonkey已经具备了处理多项任务的能力。
-
Shifted Window Attention:解决滑动窗口分割高分辨率图像时的跨窗口连接问题,避免文本被分割导致语义不连贯。解决滑动窗口分割高分辨率图像时的跨窗口连接问题,避免文本被分割导致语义不连贯。借鉴 Swin Transformer 的 Shifted Window Attention 机制,通过 cyclic-shifting 窗口和掩码机制限制自注意力计算在新窗口内,结合零初始化稳定训练。窗口大小 Hv 和 Wv 设为 448(与 Qwen-VL 的编码器匹配),零初始化修改 MLP 的权重(B 为零初始化,A 为随机高斯初始化)。增强跨窗口上下文理解,提升小文本和密集文本的处理能力,对场景文字定位和识别至关重要,因为避免了文字被分割导致的识别错误。
-
Image Resampler:减少图像特征的冗余,将视觉特征压缩到固定长度,便于与语言模型结合。使用可学习的查询向量对视觉特征进行交叉注意力操作,压缩到 256 长度,保留 2D 绝对位置编码。继承自 Qwen-VL 的图像重采样器,利用交叉注意力进行特征压缩,保留位置信息有助于细粒度理解。256 个可学习查询向量,整合 2D 绝对位置编码到交叉注意力的查询 - 键对中。减少特征维度,加快后续处理,位置编码帮助模型定位文字位置,对定位任务有直接影响。
-
Token Resampler:高分辨率导致令牌数量激增,通过相似性筛选关键令牌,减少冗余,同时保留重要信息。基于余弦相似度识别冗余令牌,用关键令牌作为查询进行交叉注意力聚合特征,压缩令牌长度。减少令牌数量,降低计算成本,同时保留关键特征,提升模型对重要文字的识别和理解能力,对问答交互中的准确响应很重要。
-
Position-Related Task:通过任务微调让模型学习文本定位和 grounding,将位置信息整合到响应中,减少幻觉。处理文本 spotting、阅读文本等任务,修改数据集加入答案位置,保持文本与位置的对齐。位置信息归一化到 (0,1000) 范围,添加额外训练任务。直接提升文字定位能力,使模型在问答时能指出答案位置,增强交互的可信度,对场景文字识别和问答交互的准确性至关重要。
-
-
加载预训练的模型和对应的分词器,并进行必要的配置,确保模型能够正常运行。
-
from monkey_model.modeling_textmonkey import TextMonkeyLMHeadModel from monkey_model.tokenization_qwen import QWenTokenizer from monkey_model.configuration_monkey import MonkeyConfig from argparse import ArgumentParser def _get_args(): parser = ArgumentParser() parser.add_argument("-c", "--checkpoint-path", type=str, default=None, help="Checkpoint name or path, default to %(default)r") parser.add_argument("--share", action="store_true", default=True, help="Create a publicly shareable link for the interface.") parser.add_argument("--server-port", type=int, default=7680, help="Demo server port.") parser.add_argument("--server-name", type=str, default="127.0.0.1", help="Demo server name.") args = parser.parse_args() return args args = _get_args() checkpoint_path = args.checkpoint_path device_map = "cuda" # 从预训练的配置文件中加载模型配置 config = MonkeyConfig.from_pretrained( checkpoint_path, trust_remote_code=True, ) # 从预训练的检查点加载TextMonkey模型,并根据配置进行初始化 model = TextMonkeyLMHeadModel.from_pretrained(checkpoint_path, config=config, device_map=device_map, trust_remote_code=True).eval() # 从预训练的检查点加载Qwen分词器 tokenizer = QWenTokenizer.from_pretrained(checkpoint_path, trust_remote_code=True) # 设置分词器的填充方向为左填充 tokenizer.padding_side = 'left' # 设置分词器的填充标记ID为结束标记ID tokenizer.pad_token_id = tokenizer.eod_id # 设置分词器的图像标记跨度为配置中的视觉查询数量 tokenizer.IMG_TOKEN_SPAN = config.visual["n_queries"] -
接收用户输入的文本和图像,将其处理为模型可接受的输入格式,然后使用模型进行推理,得到输出结果。
-
def inference(input_str, input_image): # 将输入的图像路径和文本组合成模型输入格式 input_str = f"<img>{input_image}</img> {input_str}" # 使用分词器将输入字符串转换为模型所需的输入ID input_ids = tokenizer(input_str, return_tensors='pt', padding='longest') # 获取输入的注意力掩码 attention_mask = input_ids.attention_mask input_ids = input_ids.input_ids # 使用模型进行生成 pred = model.generate( input_ids=input_ids.cuda(), attention_mask=attention_mask.cuda(), do_sample=False, num_beams=1, max_new_tokens=2048, min_new_tokens=1, length_penalty=1, num_return_sequences=1, output_hidden_states=True, use_cache=True, pad_token_id=tokenizer.eod_id, eos_token_id=tokenizer.eod_id, ) # 解码模型生成的结果,去除特殊标记 response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=False).strip() # 打开输入的图像并进行必要的处理 image = Image.open(input_image).convert("RGB").resize((1000,1000)) font = ImageFont.truetype('NimbusRoman-Regular.otf', 22) # 提取响应中的边界框信息 bboxes = re.findall(r'<box>(.*?)</box>', response, re.DOTALL) # 提取响应中的引用信息 refs = re.findall(r'<ref>(.*?)</ref>', response, re.DOTALL) if len(refs)!=0: num = min(len(bboxes), len(refs)) else: num = len(bboxes) for box_id in range(num): bbox = bboxes[box_id] matches = re.findall( r"\((\d+),(\d+)\)", bbox) draw = ImageDraw.Draw(image) point_x = (int(matches[0][0])+int(matches[1][0]))/2 point_y = (int(matches[0][1])+int(matches[1][1]))/2 point_size = 8 point_bbox = (point_x - point_size, point_y - point_size, point_x + point_size, point_y + point_size) draw.ellipse(point_bbox, fill=(255, 0, 0)) if len(refs)!=0: text = refs[box_id] text_width, text_height = font.getsize(text) draw.text((point_x-text_width//2, point_y+8), text, font=font, fill=(255, 0, 0)) # 再次解码模型生成的结果,去除特殊标记 response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip() output_str = response output_image = image print(f"{input_str} {response}") return output_image, output_str -
使用 Gradio 库搭建一个交互式界面,方便用户输入文本和图像,并显示模型的输出结果。
-
demo = gr.Interface( inference, inputs=[ gr.Textbox(lines=1, placeholder=None, label="Question"), gr.Image(type="filepath", label="Input Image"), ], outputs=[ gr.Image(type="pil", label="Output Image"), gr.Textbox(lines=1, placeholder=None, label="TextMonkey's response"), ], title=title, description=description, allow_flagging="auto", ) demo.queue() demo.launch( server_name=args.server_name, server_port=args.server_port, share=args.share ) -
在
data_generation目录下,包含了数据生成的相关代码,如blip2.py用于生成全局描述,grit_generate.py用于生成密集字幕,amg.py用于生成分割图等。这些代码的关键思想是利用不同的模型和方法,为图像生成各种类型的注释信息。在finetune目录下,包含了模型训练的相关脚本,如finetune_ds_debug.sh和finetune_textmonkey.sh。这些脚本的关键思想是利用预训练的模型和生成的数据,对模型进行微调,以提高模型在特定任务上的性能。
-
Shifted Window Attention
-
先前的研究强调了输入分辨率对于精确理解文档的重要性。为了提高训练效率,最近的方法 采用了滑动窗口技术来提高图像分辨率。虽然由于其局部的内容而在分析自然场景中是有效的,但是这种策略可能导致文档分析中的连接文本的碎片,破坏语义连续性。此外,空间分离对依赖文本定位的任务提出了挑战,例如文本背景。
-
为了缓解上述问题,我们采用转移窗口注意力来增强剪辑模型的视觉处理能力。具体来说,对于输入图像 I ∈ R H × W × 3 I ∈ \R^{H×W×3} I∈RH×W×3,我们的方法将图像分割成不重叠的窗口。该切片是使用滑动窗口 W ∈ R H v × W v W ∈ \R^{H_v×W_v} W∈RHv×Wv 实现的,其中 Hv 和 Wv 表示窗口的大小。在每个窗口中,我们独立地应用来自CLIP架构的变换器块,它最初不考虑跨窗口关系。为了整合不同窗口之间的交互并增强模型对图像的上下文理解,我们采用了移位窗口注意(SWA)机制。滑动窗口向左上方向循环移位,产生新窗口。通过屏蔽机制进行自我注意计算,将自我注意计算限制在新窗口内。
-
为了实现更平滑的训练初始化,我们对转移窗口注意力进行了修改,允许它们从零初始化开始学习,避免在初始阶段过度转换早期特征。特别地,受[Lora: Low-rank adaptation of large language models]的启发,我们将MLP中的常规初始化修改为零初始化,以实现更平滑的训练:
-
x = BA x ^ , ( 1 ) x = \textbf {BA}\hat {x}, (1) x=BAx^,(1)
-
其中B和A是指两个线性层的重量。我们对 A 使用随机高斯初始化,对 B 使用零初始化。这种方法确保图像编码器的参数在初始阶段保持稳定,有助于更平滑的训练体验。
-
Image Resampler
- 为了最初减少图像特征中的冗余,我们从Qwen-VL 继承了图像重采样器,其在每个窗口上使用。该模块采用一组可训练参数作为查询向量,并利用来自视觉编码器的图像特征作为交叉注意操作的关键字和值。这个过程有助于将视觉特征序列压缩到256的固定长度。此外,为了保留对细粒度图像理解至关重要的位置信息,2D绝对位置编码被集成到交叉注意机制的查询键对中。
Token Resampler
-
随着分辨率的提高,使用滑动窗口机制,令牌的数量也显著增加。然而,由于一些语言模型的输入长度的限制和训练时间的约束,减少标记的数量变得必要。在常见的视觉场景中,前面的方法已经证明了合并标记方法的可行性。
-
对于自然语言,冗余信息可以是重复的语言元素。假设通过扩大图像的分辨率,会存在冗余的视觉信息。在确定两个语言元素之间的相似性时,我们经常测量它们嵌入的相似性。为了评估图像特征的冗余,我们测量已经映射到语言空间的图像表征的相似性。我们在图像重采样器后随机选择20个有序特征,并使用余弦相似性来比较成对相似性,如图3所示。
-

-
图3:图像令牌相似性比较。我们从图像标记中随机选择20个有序标记,并使用余弦相似性作为度量相似性的度量。
-
-
通过比较图像表征的相似性,我们可以观察到许多图像表征表现出多个相似表征的模式。此外,我们定量地比较了不同分辨率下的标记冗余,如图4所示。根据经验,我们选择阈值0.8作为相似性阈值,在分辨率为448、896和1334时,我们分别观察到68/256 (26.6%)、571/1024 (55.8%)和1373/2304 (59.5%)的冗余令牌。如图4所示,随着分辨率的增加,重复记号的出现率更高。这验证了我们的假设,即虽然扩大分辨率可以实现更清晰的可见性,但它也引入了一些冗余特征。
-

-
图4:对特定冗余令牌的定量分析。使用每个记号和其他记号之间的最大余弦相似性作为识别冗余记号的标准,我们在x轴上绘制阈值,在y轴上绘制不同分辨率下的冗余记号的数量。
-
-
然而,我们如何识别重要的令牌并消除多余的令牌呢?我们已经观察到,某些记号是非常独特的,并且缺少非常相似的对应物,例如图3中的第五个记号。这表明这个令牌是独特的。我们假设这些记号携带了关键的和独特的信息,这在随后的实验中得到了进一步的验证。因此,我们利用相似性作为度量来识别重要的标记。因此,我们提出了一种令牌重采样器来压缩冗余令牌,如图2的左部所示。如Algor1所示。我们利用令牌过滤算法来选择最有价值的令牌。
-
为了避免直接丢弃其他特征造成的信息丢失,我们利用重要的特征作为查询,并利用交叉注意来进一步聚合所有的特征。基于令牌数的减少,与随机查询相比,我们的模块还可以显著提高性能。

Position-Related Task
-
为了缓解大型语言模型(LLM)中的幻觉问题,在大型语言模型中,他们可能产生与所提供的图像无关的错误响应,我们的目标是增强他们分析和将视觉信息纳入其响应的能力。考虑到基于文本的任务的答案通常在图像本身中找到,我们预计大模型不仅会产生精确的反应,还会识别支持其答案的特定视觉证据。
-
此外,我们对现有的问答数据集进行了修改。具体来说,我们已经找到了图像中大多数答案的位置。这些位置线索已经被提取出来,并无缝集成到答案本身中。为了保留原有的直接对话能力,我们还保留了原有的问答任务。
-
为了更好地感知文本的空间位置,需要模型具有很强的空间理解能力。在前面提到的模型设计的基础上,我们增加了额外的训练任务来提高模型对文本位置的感知,例如文本定位和阅读文本。具体任务和提示显示在表1中。为了保证文本和位置数据之间的紧密联系,我们严格保持它们的对齐,确保文本信息总是出现在任何相关的位置细节之前。
-

-
表1:各种任务的提示。
-
-
为了标准化不同比例的图像,我们使用(0,1000)的比例来表示位置信息。因此,在分辨率为( H r × W r H_r × W_r Hr×Wr )的图像中,文本坐标(x,y)将被归一化为 [ ( x / H r ∫ 1000 ) ] [(x/H_r∫1000)] [(x/Hr∫1000)],这同样适用于y。恢复过程涉及逆运算。
Dataset Construction
-
在我们的训练过程中,我们只利用开源数据,并对不同的数据集应用各种特定任务的增强。通过整合不同的数据集和对不同的任务使用不同的指令,我们增强了模型的学习能力和训练效率。对于场景文本场景,我们选择COCOText 、TextOCR 、HierText 、TextVQA 和MLT 进行训练。对于文档图像,我们选择IIT-CDIP ,DocVQA ,ChartQA ,InfoVQA ,DeepForm ,Kleister Charity (KLC) 和WikiTableQuestions (WTQ) 。为了加快训练速度,我们已经将单图像问题回答转换为多轮基于图像的问题回答,显著提高了图像特征的利用率,遵循了LLaVA 中介绍的成功方法。我们的训练数据的细节显示在表2中。我们的数据集中总共有409.1k对对话数据和210万对问答数据来训练我们的模型。
-

-
表2:训练数据的细节,完全来自公开可用的数据集。
-
-
为了进一步加强模型处理结构化文本的能力,我们使用结构化数据对TextMonkey上的一个epoch进行了微调,以增强其结构化功能,从而产生了TextMonkey。微调数据主要包括前一阶段的5%的数据,以及一部分结构化数据,包括文档、表格和图表。结构化数据图像也来源于公开可用的数据集,并使用其结构信息生成。因此,我们在结构化数据中共有55.7k的数据。
Loss
-
由于TextMonkey被训练为像其他LLM一样预测下一个令牌,所以它只需要在训练时最大化丢失的可能性。
-
KaTeX parse error: Undefined control sequence: \label at position 2: \̲l̲a̲b̲e̲l̲ ̲{eq_objective} …
-
其中 I 是输入图像,Q是问题序列,s是输出序列,s是输入序列,L是输出序列的长度。
-
EXPERIMENTS
-
推理阶段主要在
Monkey/demo_textmonkey.py文件中实现,在inference函数中,首先将输入的文本和图像路径进行组合:-
input_str = f"<img>{input_image}</img> {input_str}" -
这里通过特定的格式
<img>... </img>将图像路径嵌入到文本输入中,以此实现图像和文本模态信息的初步融合。使用QWenTokenizer对组合后的输入字符串进行分词处理,转换为模型所需的输入 ID 和注意力掩码: -
input_ids = tokenizer(input_str, return_tensors='pt', padding='longest') attention_mask = input_ids.attention_mask input_ids = input_ids.input_ids -
将处理后的输入 ID 和注意力掩码输入到模型中进行推理:
-
pred = model.generate( input_ids=input_ids.cuda(), attention_mask=attention_mask.cuda(), do_sample=False, num_beams=1, max_new_tokens=2048, min_new_tokens=1, length_penalty=1, num_return_sequences=1, output_hidden_states=True, use_cache=True, pad_token_id=tokenizer.eod_id, eos_token_id=tokenizer.eod_id, ) -
对模型的输出进行解码,并解析其中的边界框信息
<box>和引用信息<ref>,将其可视化到图像上: -
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=False).strip() image = Image.open(input_image).convert("RGB").resize((1000,1000)) font = ImageFont.truetype('NimbusRoman-Regular.otf', 22) bboxes = re.findall(r'<box>(.*?)</box>', response, re.DOTALL) refs = re.findall(r'<ref>(.*?)</ref>', response, re.DOTALL) if len(refs)!=0: num = min(len(bboxes), len(refs)) else: num = len(bboxes) for box_id in range(num): bbox = bboxes[box_id] matches = re.findall( r"\((\d+),(\d+)\)", bbox) draw = ImageDraw.Draw(image) point_x = (int(matches[0][0])+int(matches[1][0]))/2 point_y = (int(matches[0][1])+int(matches[1][1]))/2 point_size = 8 point_bbox = (point_x - point_size, point_y - point_size, point_x + point_size, point_y + point_size) draw.ellipse(point_bbox, fill=(255, 0, 0)) if len(refs)!=0: text = refs[box_id] text_width, text_height = font.getsize(text) draw.text((point_x-text_width//2, point_y+8), text, font=font, fill=(255, 0, 0))
-
-
训练阶段的代码主要涉及
Monkey/project/mini_monkey/internvl/train/internvl_chat_pretrain.py和Monkey/project/mini_monkey/internvl/train/dataset.py文件,在multi_modal_get_item函数中,首先对图像进行加载和预处理:-
# Build transformation function transform = self.get_transform() # Merge the image path image_path = self.get_image_path(data_item['image']) # Load the image using tcs_loader if available, otherwise use PIL image = self.load_image(image_path) if self.dynamic_image_size: # If dynamic image size is enabled, preprocess the image dynamically images = dynamic_preprocess(image, min_num=self.min_dynamic_patch, max_num=self.max_dynamic_patch, image_size=self.image_size, use_thumbnail=self.use_thumbnail) else: # Otherwise, use the original image as a single patch images = [image] # Apply the transformation to each image and stack the results into a tensor pixel_values = [transform(image) for image in images] pixel_values = torch.stack(pixel_values) -
在
preprocess_mpt函数中,对对话数据进行处理,包括应用提示模板、替换图像占位符和分词: -
# Apply prompt templates conversations = [] for i, source in enumerate(sources): if roles[source[0]['from']] != conv.roles[0]: # Skip the first one if it is not from human source = source[1:] conv.messages = [] for j, sentence in enumerate(source): role = roles[sentence['from']] assert role == conv.roles[j % 2], f'{i}' conv.append_message(role, sentence['value']) conversations.append(conv.get_prompt()) if not text_only: new_conversations = [] for conversation in conversations: for i in range(num_image): image_tokens = f'{IMG_START_TOKEN}{IMG_CONTEXT_TOKEN * num_image_token_list[i]}{IMG_END_TOKEN}' conversation = conversation.replace('<image>', image_tokens, 1) new_conversations.append(conversation) conversations = new_conversations # Tokenize conversations input_ids = tokenizer( conversations, return_tensors='pt', padding=False if group_by_length or use_packed_ds else 'max_length', max_length=tokenizer.model_max_length, truncation=True, ).input_ids targets = input_ids.clone() -
将处理后的图像特征
pixel_values和文本特征input_ids等组合成一个字典,作为模型的输入: -
ret = dict( input_ids=ret['input_ids'][0], labels=ret['labels'][0], attention_mask=ret['attention_mask'][0], pixel_values=pixel_values, image_flags=torch.tensor([1] * num_patches, dtype=torch.long) ) -
在推理和训练阶段,图像和文本模态信息的融合与解析主要通过以下方式实现:将图像路径嵌入到文本输入中,使用分词器处理文本,将处理后的输入输入到模型中进行推理,最后对输出进行解析和可视化。训练阶段:分别对图像和文本进行预处理,将图像转换为像素值张量,将文本转换为输入 ID 和标签,然后将它们组合成一个字典作为模型的输入。
-
Implementation Details
-
型号配置。在我们的实验中,我们使用了来自Qwen-VL 的训练有素的 Vit-BigG 和LLM,这是一个预训练的大型多模态模型。我们将图像输入的高度和宽度(Hv,Wv)配置为448,以符合Qwen-VL的编码器规格。我们的图像重采样器配备了256个可学习的查询,对于分辨率为896的图像,令牌重采样器的比率®设置为512,对于分辨率为1344的图像,比率增加到1024。为了最大化训练效率,我们的主要实验重点是使用 TextMonkey并在896分辨率设置下评估结果。
-
TextMonkey由7.7B参数的大语言模型,90M参数的图像重采样器模块,13M参数的令牌重采样器模块,1.9B参数的编码器,45M参数的移位窗口注意组成。总的来说,TextMonkey共有9.7B个参数。
-
训练。在训练阶段,我们利用AdamW 优化器,在初始阶段将学习率设置为1e-5,在后续阶段将其降低到5e-6,同时采用余弦学习率计划。参数 β1 和 β2 分别配置为0.9和0.95。包含150个步骤的预热阶段被合并,我们以128个为一批处理数据。为了降低过度拟合的风险,我们应用了0.1的权重衰减因子。全面的训练程序跨越了12个800天,以完成一个 epoch。
-
评价。为了便于与其他方法进行更公平的比较,我们采用了准确性度量,其中如果我们的模型产生的响应包含了基本事实,则被认为是正确的。测试数据集的选择和评估标准的制定按照中描述的方法进行。为了确保与其他方法进行更公平的比较,我们还利用原始指标对某些数据集进行了补充评估,如F1得分和ANLS(平均标准化Levenshtein相似性)。
Results
-
OCRBench结果。我们用最近的大型多模态模型对我们的方法进行了比较分析。在我们的评估中,我们利用了三个以文本为中心的场景VQA数据集:STVQA 、TextVQA 和OCRVQA;三个面向文档的VQA数据集:DocVQA 、InfoVQA 和chart QA;以及三个关键信息提取(KIE)数据集:FUNSD 、SROIE 和POIE 。为了对性能进行全面评估,我们的评估包括OCRBench ,这是最近专门为评估大型多模态模型的光学字符识别(OCR)能力而开发的基准。OCRBench涵盖了广泛的文本相关的视觉任务,包含29个数据集,旨在生成一个总分数。
-
如表3中所示。与现有的大型多模态模型相比,我们的模型表现出优越的性能,尤其是在文本密集且较小的场景中。我们的方法本质上增强了许多当前的评估数据集,对于以场景文本为中心的VQA、以文档为导向的VQA和KIE,使用许多基线方法的平均性能分别提高了5.2%、6.9%和2.8%。TextMonkey在DocVQA上可以做到64.3%,在ChartQA上可以做到58.2%。具体来说,我们的模型在OCRBench上获得了561分。在两个具有挑战性的下游任务和OCRBench上的性能证明了它在文本相关任务中的有效性。我们发现我们的模型倾向于提供没有单位的数字答案,这导致了POIE的性能下降。
-

-
表3:我们的模型与现有的大型多模态模型(lmm)在几个基准上的定量准确度(%)比较。我们用Sec 3.5中显示的结构化数据对TextMonkey进行了微调。产生TextMonkey。
-
-
记录基准结果。为了进一步比较和评估我们方法的能力,我们利用他们论文中提供的特定评估指标对其他数据集进行了测试:Deepform和KLC的F1评分,WTQ的准确性,ChartQA 的宽松准确性测量,DocVQA的ANLS和TextVQA的VQA评分。
-
结果显示在 表4 中。表明我们的模型在这些数据集上的性能领先,优于其他模型。在不同的领域中,TextMonkey在DocVQA中获得了71.5分,在WTQ中获得了30.6分,在ChartQA中获得了65.5分,在TextVQA中获得了68.0分。它显示了我们的模型处理文档、表格、图表和场景文本的能力。
-

-
表4:其他文档基准的量化结果。“DF”是DeepForm的缩写。
-
-
文本定位结果。为了展示我们的模型的广泛能力,我们在没有微调的情况下评估了它在文本定位数据集上的性能,详见表5。鉴于我们的模型侧重于识别完整的文本段落,我们将预测的内容分割成单个单词进行分析。我们采用了两种评估方法来评估我们的模型的性能。在“Trans”模式下,如果答案包含该单词,则文本被视为正确。相反,“Pos”模式要求根据之前的方法考虑位置信息。对于这两种度量,由于输出的粒度问题(TextMonkey经常产生一个完整的段落,而其他人只产生所需的单词),度量不能严格遵循评估设置;然而,两者应该非常相似,因为在计算中错误和正确的情况都是匹配的。
-

-
表5:文本定位的定量准确性。“TotalText”和“CTW1500”数据集不使用特定的词汇进行评估,而“ICDAR 2015”数据集使用通用词汇来评估其他模型。注意TTS仅使用合成位置数据。没有任何词汇的下游文本定位数据集不会对TextMonkey进行微调。
-
-
为了保持TextMonkey的一致性能,我们避免使用下游文本定位数据对其进行微调,这与针对“Trans”或“Pos”指标进行优化的其他方法不同。我们的结果显示,对于“Trans”指标,TextMonkey的表现比SPTS v2高出10.9%。关于“位置”度量,它展示了胜任的文本定位能力,显示了它在理解文本内容和空间定位方面的能力。
Visualization
- 我们在各种场景中对TextMonkey进行了定性评估,包括自然场景和文档图像。如图5的左部所示,TextMonkey精确地定位和识别场景和文档图像中的文本。此外,图5 (a)中的自然图像、图5 (b)中的文档、图5 ©中的图表和图5 (d)中的表格例证了TextMonkey在广泛的场景中辨别和解释视觉和文本信息的熟练程度。总的来说,TextMonkey在各种场景中的表现证明了它在各种视觉环境中感知和理解文本信息的有效性。
-

-
图 5 ,TextMonkey的可视化结果。模型生成的边界框以红色显示。地面实况的位置用绿色方框突出显示。
-
Ablation Study
-
零初始化的消融研究。由于CLIP已经过预训练,建议在早期训练阶段避免功能的剧烈变化。如表6中所示。合并这种零初始化方法可以在ChartQA上产生0.6%的性能增益。
-

-
表6:零初始化的消融研究。
-
-
不同部件的消融研究。如表7中所示。通过引入跨窗口连接,我们在SROIE上实现了0.1%的提升,在DocVQA上实现了1.5%的提升,在TextVQA上实现了2.4%的提升。可以观察到,跨窗口连接部分地补偿了由分块引起的不连续性,并且有助于更好地理解图像。基于令牌重采样器,我们的方法表现出更好的性能,在SROIE、DocVQA和TextVQA上分别实现了1.0%、0.2%和1.1%的性能增益。这表明,我们的方法有效地保留了基本信息,同时消除了冗余标记,从而简化了模型的学习过程。
-

-
表7:不同部件的消融研究。“W-Attn”表示转移窗口注意力,“T-Resampler”表示令牌重采样器。
-
-
缩减令牌长度策略的消融研究。如表8所示。用随机令牌替换重要令牌(没有令牌过滤器)会导致性能平均下降大约12.7%。这种下降归因于优化随机查询的复杂性增加,与使用重要标记相比,这需要更多的数据集来实现通用表示。只关注pivotal特性(没有重采样)并直接消除特性会导致一些信息的丢失,表现为性能下降,例如SROIE下降了2.1%。此外,由于语言模型固有的组织无序标记的能力,忽略标记的顺序(使用无序标记过滤器)不会显著降低性能。尽管如此,缺少令牌顺序仍然会导致性能下降,在DocVQA的结果中尤为明显,性能下降了2.2%。
-

-
表8:令牌重采样器策略的有效性。
-
-
输入分辨率和剩余标记数之间的交互作用。如表9中所示。直接提高分辨率而不压缩令牌实际上会导致一致的更差的性能,尤其是在DocVQA中性能下降了9.2%。我们推测,分辨率的增加导致冗余标记的显著增加,使得在我们的设置中找到关键信息更加困难。因此,合理压缩令牌可以获得更高的性能。考虑到大尺寸图像中信息的稀疏性,还需要考虑为不同的输入分辨率选择合适的“r”值。此外,提高输入分辨率有利于包含许多大尺寸图像的数据集,DocVQA和InfoVQA的性能分别提高0.2%和3.2%。然而,对于像TextVQA和SROIE这样包含小得多的图像的数据集,直接提高输入分辨率不会产生任何收益。
-

-
表9:分辨率和保持“r”的令牌数之间的相互作用。“r”中的“-”表示不使用令牌重采样器,保留所有剩余令牌。
-
Structuralization
- 图表的结构化具有重要的实用价值。结构化图表和表格以清晰的格式呈现数据,通过从图像中提取结构化信息,计算机可以准确地解析和提取数据。这使得数据分析、统计和建模更加高效和精确。它还有助于降低信息的复杂性,提高信息的可理解性。如图6所示,我们的模型能够将图表和表格组织成JSON格式,展示了它在下游应用中的潜力。根据表4,TextMonkey在表格和图表上的性能分别提高了1.3%和1.4%。这强调了高质量的数据不仅支持模型的结构化能力,而且放大了相关基准的有效性。然而,值得注意的是,这种类型的数据将主要有利于其自身域内的数据,从而导致跨域TextVQA的性能下降。
-

-
图6:使用TextMonket结构化图表的例子。
-
App Agent
- 最近,使用lmm作为智能手机应用程序代理的任务受到了很多关注。与Siri等通过系统后端访问和函数调用进行操作的现有智能手机助手不同,该代理以类似人类的方式与智能手机应用程序进行交互,使用图形用户界面(GUI)上的点击和滑动等低级操作。它消除了对系统后端访问的需求,增强了安全性和隐私性,因为代理不需要深入的系统集成。GUI主要由图标和文本组成,我们探索了TextMonkey在这方面的可行性。我们转换了来自Rico 数据集的15k用户点击数据,并使用TextMonkey执行了下游微调。如图7定性所示,我们的模型能够理解用户意图并点击相应的图标,这表明该模型通过使用下游数据充当应用程序代理的潜力。
-

-
图7:微调后的TextMonkey for Apps的可视化结果。模型生成的点击结果以红点显示。为了更好地模拟人类行为,我们将这些点放大成圆圈。
-
DISCUSSION
Interpretability
- 通过检查基础信息,我们可以确定模型错误背后的原因,从而增强对模型行为的更好理解。如图8 (a)所示,我们接地到白色区域,表明该模型可能在产生幻觉。我们正确地识别了位置,但是在图8 (b)中识别错误。图8 ©突出了一个场景,其中模型以不正确的文本为基础,但是仍然提供正确的答案。这可能意味着模型的响应在这一点上存在一定程度的随机性或不确定性。在图8 (d)中,位置和文本之间的对齐表明模型对其预测更有信心。因此,基于这些分析,我们可以更好地理解模型的行为,并更好地意识到模型的幻觉,从而减少模型的幻觉。
-
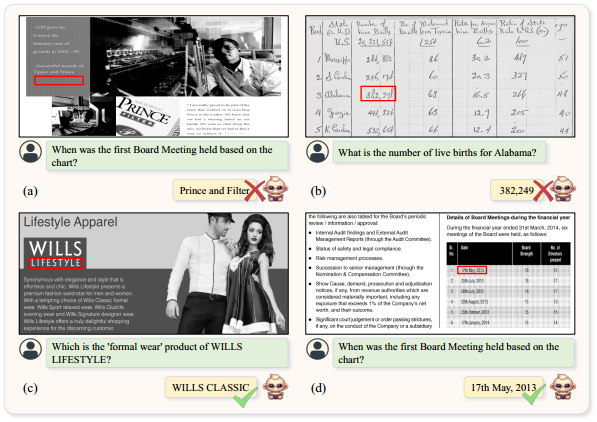
-
图8:把答案的位置定位的例子。
-
Chain-of-Thought
- 我们还在几个数据集上进行实验,如果我们需要一个模型来提供答案的位置,我们会观察到不一致的改进,如表10所示。在大多数答案基于图像中的信息的数据集(如DocVQA和SROIE)中,要求模型提供答案的位置有明显的好处。然而,对于涉及推理任务的数据集,如ChartQA和InfoVQA,其中问题需要比较或定量分析(例如,“A比B多多少?”),要求位置答案实际上会导致有害的效果。在进一步检查错误答案后,我们认为 定位 的要求可能部分影响了某些推理需求。因此,在决定是否强制要求位置答案时,必须考虑数据集的性质和所提问题的类型。
-

-
表10:纳入答案位置的影响
-
- 此外,我们认为,在后续步骤中自动构建思维链的过程可能是未来研究的一个有希望的方向。通过开发自动生成连贯推理链的机制,我们可以潜在地增强模型的整体性能和推理能力。
Comparison Between Different Representations of Position
-
最近,一些方法已经使用点来表示位置,而不是矩形和多边形。首先,直觉上,与生成矩形和多边形相比,推理期间生成点的成本会更低,因为其他形式的边界框需要生成Nx个点。我们的目标是进一步调查和实验验证哪种形式更适合LMMs学习。为了在我们的实验中保持严格的一致性,我们只对数据应用变换,同时保持其他训练超参数不变。对于这些点,我们选择了最有意义的边界框的中心点。
-
如表11所示,采用点作为视觉线索比矩形显著提高了性能。在Docvqa的情况下,有0.7%的改进,而对于SROIE,增强达到0.9%。此外,矩形在性能上经常超过多边形。这可能归因于之前讨论的问题,即冗余图像标记会增加模型学习过程的复杂性。类似地,广泛的立场陈述可能会面临类似的障碍。考虑到这些因素以及相关的推理成本,利用点作为表示对于适当的任务可能是一种可行的策略。
-

-
表11:不同形状边框的比较。
-
CONCLUSION
-
本文引入了TextMonkey来解决与大量文本任务相关的挑战,例如文档问答和细粒度的文本分析。我们采用零初始化的移位窗口注意力来帮助建立关系,同时使用滑动窗口来增加输入分辨率。提高分辨率的同时也增加了令牌的数量。通过分析令牌的冗余性,我们提出的令牌重采样器有效地减少了令牌的数量。
-
此外,通过同时参与多个面向文本的任务,TextMonkey增强了其对空间关系的感知和理解,从而提高了可解释性并支持点击屏幕截图。通过将我们的模型与各种 lmm 进行比较,我们的模型在多个基准上取得了优异的结果。值得一提的是,我们还发现直接提高输入分辨率并不总能带来改善,尤其是对于小得多的图像。这强调了创建一种有效的方法来缩放尺寸变化剧烈的文档中的分辨率的必要性。
-
提升场景文字定位与识别能力,优化窗口尺寸与注意力机制:文档中窗口尺寸固定为 448x448,可测试更小窗口(如 224x224)对小文本(如街景小字招牌)的定位效果,或更大窗口(如 896x896)对长文本(如横幅)的连贯性保留能力。增强 Token Resampler 的场景适应性:当前相似性阈值 0.8 是通用设置,可针对不同场景(如模糊文本、倾斜文本)动态调整阈值(如模糊场景降低阈值至 0.7,减少有效令牌丢失),并测试不同筛选策略(如基于文本显著性的加权筛选)对识别精度的影响。可使用 Total-Text、CTW1500 等数据集进行微调,优化 “Trans”(转录准确率)和 “Pos”(位置准确率)指标,尤其提升弯曲文本、低光照场景的识别鲁棒性。
-
提升问答交互能力,动态调整位置信息融入策略:提到加入位置信息对推理类问答(如 “A 比 B 多多少?”)有负面影响(Tab.10),可设计自适应机制:对事实性问答(如 “招牌名称是什么?”)强制输出位置,对推理问答弱化位置约束,同时保留 “文本 + 位置” 的对齐关系,提升交互灵活性。引入 Chain-of-Thought(CoT)推理:文档提出自动生成推理链是未来方向,可在问答中加入 CoT,让模型逐步解释 “如何定位→如何识别→如何得出答案”,例如:“1. 定位到图像 (200,300) 处的文字;2. 识别为‘XX 超市’;3. 因此答案是 XX 超市”,提升交互的可解释性。增强多轮问答的上下文记忆:当前以单轮问答为主,可构建多轮对话数据集(如 “问:招牌上的电话号码?答:xxx;问:该号码的归属地?答:xxx”),让模型在多轮交互中保持对文字位置和内容的记忆,提升交互连贯性。
-
模型定义模块(modeling_textmonkey.py)
-
import importlib import math from typing import TYPE_CHECKING, Optional, Tuple, Union, Callable, List, Any, Generator import torch import torch.nn.functional as F import torch.utils.checkpoint from torch.cuda.amp import autocast from torch.nn import CrossEntropyLoss from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList from transformers.generation.logits_process import LogitsProcessorList if TYPE_CHECKING: from transformers.generation.streamers import BaseStreamer from transformers.generation.utils import GenerateOutput from transformers.modeling_outputs import ( BaseModelOutputWithPast, CausalLMOutputWithPast, ) from transformers.modeling_utils import PreTrainedModel from transformers.utils import logging from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training try: from einops import rearrange except ImportError: rearrange = None from torch import nn from monkey_model.modeling_qwen import QWenModel,QWenPreTrainedModel,QWenLMHeadModel from monkey_model.text_monkey.visual_text import VisionTransformer SUPPORT_CUDA = torch.cuda.is_available() SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported() SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7 logger = logging.get_logger(__name__) -
这部分代码主要导入了必要的库和模块,包括 PyTorch、Transformers 库以及自定义的模型组件。同时,检查了 CUDA 支持和不同精度计算的支持情况。
-
class TextMonkeyModel(QWenModel): def __init__(self, config): super().__init__(config) self.visual = VisionTransformer(**config.visual) def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ): if past_key_values is None and torch.any(input_ids == self.config.visual['image_start_id']): # 找到图像开始和结束标记的位置 bos_pos = torch.where(input_ids == self.config.visual['image_start_id']) eos_pos = torch.where(input_ids == self.config.visual['image_start_id'] + 1) assert (bos_pos[0] == eos_pos[0]).all() img_pos = torch.stack((bos_pos[0], bos_pos[1], eos_pos[1]), dim=1) images = [] for i, a, b in img_pos: # 提取图像编码 image = input_ids[i][a + 1 : b - 1].tolist() image = image[ : image.index(self.config.visual['image_start_id'] + 2)] images.append(bytes(image).decode('utf-8')) if self.visual.lora_repeat_num>0: # 使用 LoRA 进行图像编码 images = self.visual.encode(images,lora_idx=self.visual.lora_repeat_num) else: # 普通图像编码 images = self.visual.encode(images) assert images.shape[0] == len(images) else: images = None # 调用父类的 forward 方法 return super().forward(input_ids, past_key_values, attention_mask, token_type_ids, position_ids, head_mask,inputs_embeds, encoder_hidden_states, encoder_attention_mask, use_cache, output_attentions, output_hidden_states, return_dict, images) -
TextMonkeyModel继承自QWenModel,并添加了一个VisionTransformer模块用于处理图像信息。在forward方法中,首先检查输入中是否包含图像标记。如果包含,则提取图像编码,并根据lora_repeat_num的值决定是否使用 LoRA 进行图像编码。最后,调用父类的forward方法,将图像信息传递给模型进行处理。
-
-
class TextMonkeyLMHeadModel(QWenLMHeadModel): _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.rotary_emb\.inv_freq"] _keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.masked_bias"] def __init__(self, config): super().__init__(config) assert ( config.bf16 + config.fp16 + config.fp32 <= 1 ), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true" autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0 if autoset_precision: if SUPPORT_BF16: logger.warn( "The model is automatically converting to bf16 for faster inference. " "If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"." ) config.bf16 = True elif SUPPORT_FP16: logger.warn( "The model is automatically converting to fp16 for faster inference. " "If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"." ) config.fp16 = True else: config.fp32 = True if config.bf16 and SUPPORT_CUDA and not SUPPORT_BF16: logger.warn("Your device does NOT seem to support bf16, you can switch to fp16 or fp32 by by passing fp16/fp32=True in \"AutoModelForCausalLM.from_pretrained\".") if config.fp16 and SUPPORT_CUDA and not SUPPORT_FP16: logger.warn("Your device does NOT support faster inference with fp16, please switch to fp32 which is likely to be faster") if config.fp32: if SUPPORT_BF16: logger.warn("Your device support faster inference by passing bf16=True in \"AutoModelForCausalLM.from_pretrained\".") elif SUPPORT_FP16: logger.warn("Your device support faster inference by passing fp16=True in \"AutoModelForCausalLM.from_pretrained\".") self.transformer = TextMonkeyModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) if config.bf16: self.transformer.bfloat16() self.lm_head.bfloat16() if config.fp16: self.transformer.half() self.lm_head.half() self.post_init() -
TextMonkeyLMHeadModel继承自QWenLMHeadModel,用于生成文本输出。在__init__方法中,首先检查配置中的精度设置,确保只使用一种精度(bf16、fp16 或 fp32)。如果没有手动设置精度,则根据设备支持情况自动选择。然后,创建TextMonkeyModel作为transformer模块,并添加一个线性层lm_head用于将隐藏状态映射到词汇表大小。最后,根据配置的精度将模型转换为相应的精度。 -
视觉文本处理模块(monkey_model/text_monkey/visual_text.py)
-
def forward(self, query, key, value, attn_mask = None,lora_idx = None): # query/key/value: [sq, b, h] sq, b, _ = query.size() assert query is key, 'Only Support Self-Attention Currently' sk = sq mixed_x_layer = self.in_proj(query) if lora_idx == None: pass else: # 使用 LoRA 进行投影 lora_res = self.in_proj_lora[lora_idx](query) mixed_x_layer += lora_res # [sq, b, (np * 3 * hn)] --> [sq, b, np, 3 * hn] new_tensor_shape = mixed_x_layer.size()[:-1] + \ (self.num_attention_heads_per_partition, 3 * self.hidden_size_per_attention_head) mixed_x_layer = mixed_x_layer.view(*new_tensor_shape) # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn] query_layer, key_layer, value_layer = mixed_x_layer.split( self.hidden_size_per_attention_head, dim=-1) # [sq, b, np, hn] -> [sq, b * np, hn] query_layer = query_layer.view(sq, b * self.num_attention_heads_per_partition, self.hidden_size_per_attention_head).transpose(0, 1) # [sk, b, np, hn] -> [sk, b * np, hn] key_layer = key_layer.view(sk, b * self.num_attention_heads_per_partition, self.hidden_size_per_attention_head).transpose(0, 1) q_scaled = query_layer / self.norm_factor if attn_mask is not None: attention_probs = torch.baddbmm(attn_mask, q_scaled, key_layer.transpose(-2, -1)) else: attention_probs = torch.bmm(q_scaled, key_layer.transpose(-2, -1)) attention_probs = attention_probs.softmax(dim=-1) value_layer = value_layer.view(sk, b * self.num_attention_heads_per_partition, self.hidden_size_per_attention_head).transpose(0, 1) # matmul: [b * np, sq, hn] context_layer = torch.bmm(attention_probs, value_layer) # change view [b, np, sq, hn] context_layer = context_layer.view(b, self.num_attention_heads_per_partition, sq, self.hidden_size_per_attention_head) # [b, np, sq, hn] --> [sq, b, np, hn] context_layer = context_layer.permute(2, 0, 1, 3).contiguous() # [sq, b, np, hn] --> [sq, b, hp] new_context_layer_shape = context_layer.size()[:-2] + \ (self.hidden_size_per_partition,) context_layer = context_layer.view(*new_context_layer_shape) output = self.out_proj(context_layer) if lora_idx == None: pass else: # 使用 LoRA 进行投影 lora_res = self.out_proj_lora[lora_idx](context_layer) output += lora_res return output -
该方法实现了自注意力机制,用于处理视觉文本信息。对输入的
query进行线性投影,并根据lora_idx的值决定是否使用 LoRA 进行投影。然后,将投影后的结果分割为query_layer、key_layer和value_layer,并进行缩放和注意力计算。最后,将注意力结果与value_layer相乘,得到上下文表示,并进行线性投影和 LoRA 调整,返回最终输出。
-
-
演示脚本模块(demo_textmonkey.py)
-
import re import gradio as gr from PIL import Image, ImageDraw, ImageFont from monkey_model.modeling_textmonkey import TextMonkeyLMHeadModel from monkey_model.tokenization_qwen import QWenTokenizer from monkey_model.configuration_monkey import MonkeyConfig from argparse import ArgumentParser def _get_args(): parser = ArgumentParser() parser.add_argument("-c", "--checkpoint-path", type=str, default=None, help="Checkpoint name or path, default to %(default)r") parser.add_argument("--share", action="store_true", default=True, help="Create a publicly shareable link for the interface.") parser.add_argument("--server-port", type=int, default=7680, help="Demo server port.") parser.add_argument("--server-name", type=str, default="127.0.0.1", help="Demo server name.") args = parser.parse_args() return args args = _get_args() checkpoint_path = args.checkpoint_path device_map = "cuda" # 创建模型 config = MonkeyConfig.from_pretrained( checkpoint_path, trust_remote_code=True, ) model = TextMonkeyLMHeadModel.from_pretrained(checkpoint_path, config=config, device_map=device_map, trust_remote_code=True).eval() tokenizer = QWenTokenizer.from_pretrained(checkpoint_path, trust_remote_code=True) tokenizer.padding_side = 'left' tokenizer.pad_token_id = tokenizer.eod_id tokenizer.IMG_TOKEN_SPAN = config.visual["n_queries"] title = "TextMonkey : An OCR-Free Large Multimodal Model for Understanding Document" description = """ <font size=4> Welcome to TextMonkey Hello! I'm TextMonkey, a Large Language and Vision Assistant developed by HUST VLRLab and KingSoft. You can click on the examples below the demo to display them. ## Example prompts for different tasks You need to replace "Question" with your question. 1.**Read All Text:** Read all the text in the image. 2.**Text Spotting:** OCR with grounding: 3.**Position of Text:** <ref>"Question"</ref> 4.**VQA:** "Question" Answer: 5.**VQA with Grounding:** "Question" Provide the location coordinates of the answer when answering the question. 6.**Output Json**: Convert the chart in this image to json format. Answer:(Convert the document in this image to json format. Answer:)(Convert the table in this image to json format. Answer:) </font> """ def inference(input_str, input_image): input_str = f"<img>{input_image}</img> {input_str}" input_ids = tokenizer(input_str, return_tensors='pt', padding='longest') attention_mask = input_ids.attention_mask input_ids = input_ids.input_ids pred = model.generate( input_ids=input_ids.cuda(), attention_mask=attention_mask.cuda(), do_sample=False, num_beams=1, max_new_tokens=2048, min_new_tokens=1, length_penalty=1, num_return_sequences=1, output_hidden_states=True, use_cache=True, pad_token_id=tokenizer.eod_id, eos_token_id=tokenizer.eod_id, ) response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=False).strip() image = Image.open(input_image).convert("RGB").resize((1000,1000)) font = ImageFont.truetype('NimbusRoman-Regular.otf', 22) bboxes = re.findall(r'<box>(.*?)</box>', response, re.DOTALL) refs = re.findall(r'<ref>(.*?)</ref>', response, re.DOTALL) if len(refs)!=0: num = min(len(bboxes), len(refs)) else: num = len(bboxes) for box_id in range(num): bbox = bboxes[box_id] matches = re.findall( r"\((\d+),(\d+)\)", bbox) draw = ImageDraw.Draw(image) point_x = (int(matches[0][0])+int(matches[1][0]))/2 point_y = (int(matches[0][1])+int(matches[1][1]))/2 point_size = 8 point_bbox = (point_x - point_size, point_y - point_size, point_x + point_size, point_y + point_size) draw.ellipse(point_bbox, fill=(255, 0, 0)) if len(refs)!=0: text = refs[box_id] text_width, text_height = font.getsize(text) draw.text((point_x-text_width//2, point_y+8), text, font=font, fill=(255, 0, 0)) response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip() output_str = response output_image = image print(f"{input_str} {response}") return output_image, output_str demo = gr.Interface( inference, inputs=[ gr.Textbox(lines=1, placeholder=None, label="Question"), gr.Image(type="filepath", label="Input Image"), ], outputs=[ gr.Image(type="pil", label="Output Image"), gr.Textbox(lines=1, placeholder=None, label="TextMonkey's response"), ], title=title, description=description, allow_flagging="auto", ) demo.queue() demo.launch( server_name=args.server_name, server_port=args.server_port, share=args.share ) -
该脚本使用 Gradio 库创建了一个交互式演示界面,用于展示 TextMonkey 模型的功能。解析命令行参数,加载模型和分词器。然后,定义
inference函数,该函数接受输入文本和图像,将它们组合成输入序列,并使用模型生成响应。最后,使用正则表达式提取响应中的边界框和引用信息,并在图像上绘制标记。最终,返回处理后的图像和文本响应。
-
-
TextMonkey 的代码实现主要围绕多模态信息融合和文档理解任务展开。通过在
TextMonkeyModel中添加VisionTransformer模块,实现了图像信息的处理和融合。在forward方法中,通过检查输入中的图像标记,提取图像编码并进行处理。在视觉文本处理模块中,实现了自注意力机制和 LoRA 调整,用于处理视觉文本信息。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)