RAG评估指标
RAG系统评估主要分为检索和生成两部分。检索评估指标包括精确度、召回率、命中率、MRR和NDCG,用于衡量检索结果的相关性和排序质量。生成评估则关注:1)忠诚度(答案是否基于检索内容)、2)答案相关性(是否符合用户问题)、3)正确性(与参考答案一致性)、4)上下文精确率(利用检索内容程度)、5)上下文召回率(检索内容是否完整支持答案)。通过优化这些指标(如某案例将忠诚度从0.72提升至0.91),
RAG系统的核心流程可以简化为检索组件和答案生成组件,评估RAG即对两部分组件效果进行评估。
1、检索指标
在RAG的检索评估中,我们基本上是在做一个二分类:文档是否与查询相关。
| 实际相关 | 实际不相关 | |
|---|---|---|
| 被系统检索 | 真正例(TP) | 假正例(FP) |
| 未被检索 | 假负例(FN) | 真负例(TN) |
1.1 精确度(Precision)
检索到的文档中有多大比例是真正相关的?
公式:Precision=![]()
1.2 召回率(Recall)
召回率(Recall):成功检索到了多大比例的相关文档?
![]()
1.3 命中率 (Hit Rate)
命中率(Hit Rate):有多大比例的查询在前几个结果中至少检索到了一个相关文档?
![]()
1.4 平均倒数排名(MRR,Mean Reciprocal Rank)
第一个相关文档在搜索结果中平均排在第几位?

举个例子,假设有3个查询:
查询1:第一个相关文档排在第1位,所以倒数排名是1/1=1
查询2:第一个相关文档排在第3位,所以倒数排名是1/3
查询3:第一个相关文档排在第2位,所以倒数排名是1/2
那么MRR = (1 + 1/3 + 1/2) / 3 ≈ 0.61
MRR的值越接近1,表示相关文档在结果列表中的排名越靠前,用户找到所需信息的速度就越快。
这个指标在用户通常只关注前几个结果的系统中特别有价值,比如搜索引擎。用户很少翻到第二页,对吧?
1.5、标准化折扣累积增益(NDCG)
标准化折扣累积增益(NDCG):同时考虑检索文档的相关性和排名顺序。

2、生成指标
对话机器人中 RAG 如何处理后续提问 | Ultrasev Blog - Programming & AI Technical Insights
“评估利用信息回答问题”的能力。
2.1、忠诚度(Faithfulness)
忠实度(Faithfulness):我们经常说的大模型幻觉,就是该指标的描述。具体来说忠诚度是指 生成的答案与检索上下文的一致性。
![]()
更精确地说,忠实度可以通过以下步骤计算:
- 将生成的回答分解为多个事实性声明
- 检查每个声明是否能从检索到的文档中得到支持
- 计算得到支持的声明比例
这个指标帮助确保模型不会"编造"不在检索内容中的信息。如果发现模型经常"幻觉",这个指标会迅速下降。
实际操作中,我们不会人工做上面判断步骤,而是用另一个LLM来自动评估忠实度,我给它检索到的文档和生成的答案,然后让它评估每个声明是否有支持证据。在一个实验中,通过改进检索质量和调整提示词,我们将忠实度从0.72提升到0.91,这大大减少了"幻觉"问题。
2.2 答案相关性(Answer Relevance)
生成的答案与原始查询的相关程度如何?
公式:通常使用语义相似度度量,例如余弦相似度:

这个指标确保模型在使用检索信息的同时,不会偏离用户的原始问题。有时模型会返回检索文档中的信息,但这些信息与用户的问题并不直接相关,这种情况下相关性分数会很低。
在我们的客户服务机器人项目中,通过优化提示词中强调"直接回答用户问题"的部分,我们将相关性从0.65提高到0.83,用户反馈明显改善。
2.3 答案正确性(Answer Correctness)
答案正确性(Answer Correctness):生成的答案与参考答案的一致程度如何。

你有一组基准答案可以比较时,这个指标特别有用。在实践中,我发现基于LLM的评分方法通常比简单的文本匹配效果更好,因为它能捕捉到意义上的等价性,即使表述不同。
在我们的技术支持知识库项目中,通过使用这个指标不断调整检索和生成策略,我们最终将答案正确性从0.69提高到0.88,这让支持团队更加信任系统的输出。
2.4、上下文精确率(Context Precision)
实际使用了多少检索内容
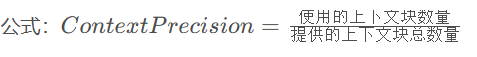
这个指标衡量了模型在多大程度上真正利用了我们提供的上下文信息。如果模型只用了20%的检索内容就给出了完整答案,这可能意味着我们检索了太多无关内容,或者检索结果中有大量冗余。
在优化RAG系统时,我发现提高上下文精确率不仅可以减少token消耗(降低成本),还能提高生成质量。我们通过优化检索方法和减少冗余,将上下文精确率从0.35提升到0.72,同时生成质量也有所提高。
2.5、上下文召回率(Context Recall)
答案需要的信息有多少被包含在检索内容中

这个指标评估我们检索的内容是否足够完整地支持回答问题。如果上下文召回率低,意味着即使模型尽力了,也无法基于给定的检索内容提供完整答案。
在一个产品技术文档项目中,我们发现某些复杂问题的上下文召回率只有0.53,意味着模型无法完整回答问题。通过调整检索数量和改进切块策略,我们将这个指标提高到0.89,大大提升了复杂问题的回答质量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)