【ICLR26匿名投稿】MMSeg:让“图像提示分割”更聪明——多模态、多视角驱动的无训练分割新范式
最终得到一组多模态融合的提示点(positive/negative prompts),输入 SAM 进行掩码生成。让图像提示分割从“单模态模糊”走向“多模态精准”, 在完全无训练条件下,实现可与训练模型媲美的分割性能。带来了“零样本分割”的浪潮——输入一个提示点或文字,就能切出物体边界。通过“视觉 + 文本”两条独立分支定位目标,再用多视角增强和共识优化生成高质量分割。—— 视觉-only 方法易
文章:MMSeg: Multi-Modal and Multi-View Driven Semantic Enrichment for Training-Free Image Prompt Segmentation
代码:暂无
作者:匿名
一、问题背景:免训练分割,仍有“理解盲区”
在大模型时代,Segment Anything (SAM) 带来了“零样本分割”的浪潮——输入一个提示点或文字,就能切出物体边界。 但实际应用中,免训练(training-free)图像提示分割仍有两大瓶颈:
-
🎯 目标定位不准 —— 仅靠一张参考图像特征匹配,易出现偏移与漏检;
-
🎭 分割质量欠佳 —— 面对复杂背景时,Mask 粗糙、边界模糊;
-
💬 单一模态限制理解 —— 视觉-only 方法易错分,文字-only 方法又受语义歧义困扰。
于是,作者提出:
💡 是否可以同时利用图像和文本的互补性,再引入多视角增强,让模型在无训练的前提下学会更精准地理解目标?
答案,就是 MMSeg。

二、方法创新:多模态 × 多视角,让分割更智能
论文提出 MMSeg(Multi-Modal and Multi-View driven Segmentation), 一个无需训练、基于多模态语义增强的图像提示分割框架。
核心思想:
通过“视觉 + 文本”两条独立分支定位目标,再用多视角增强和共识优化生成高质量分割。
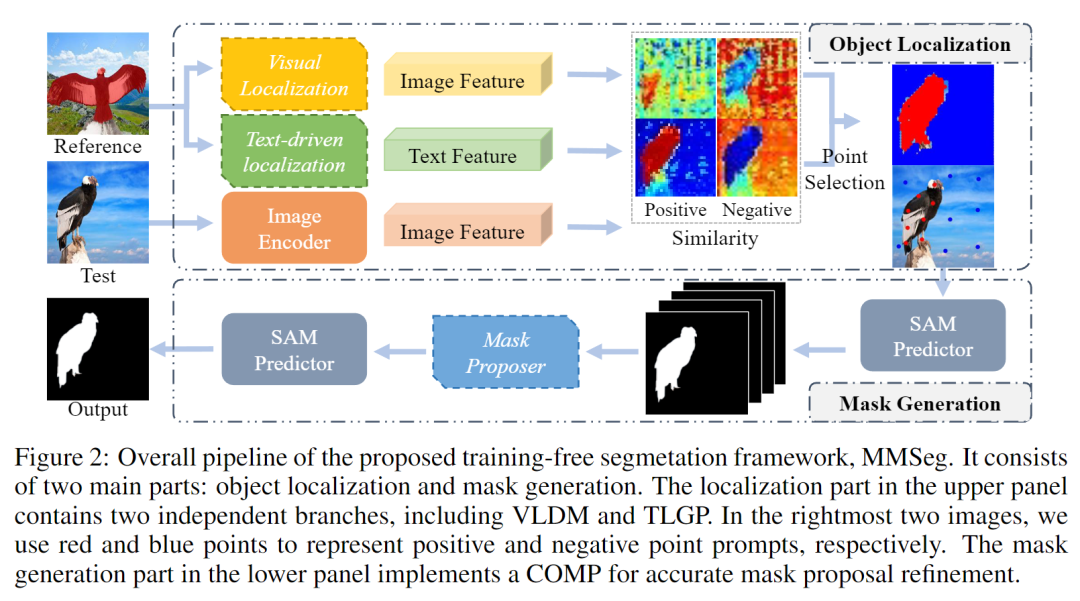
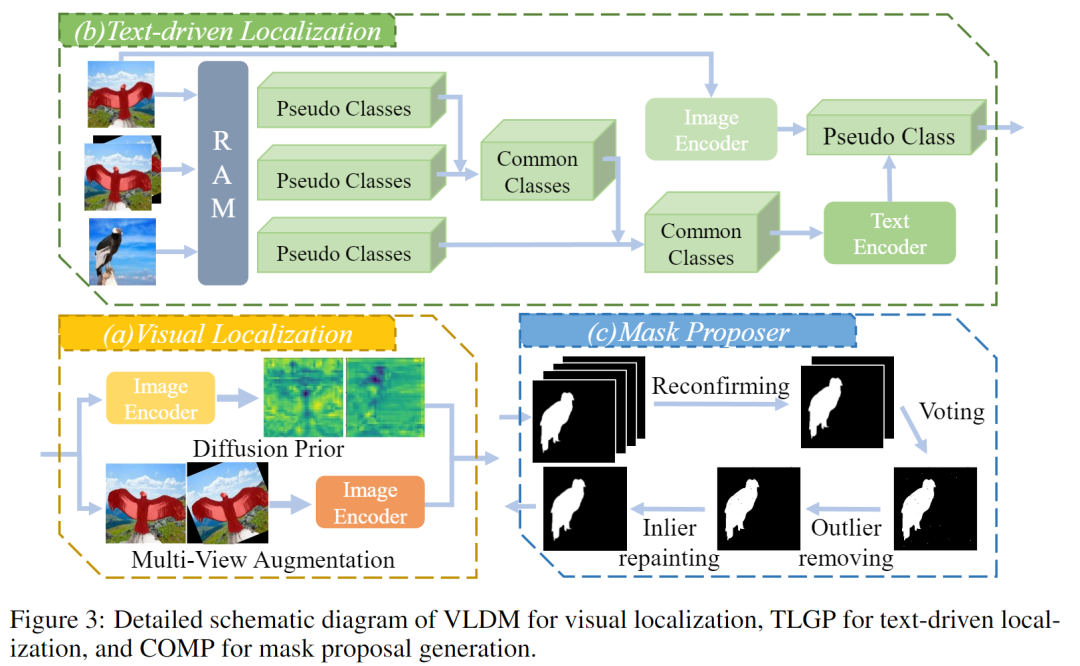
✳️ 1. 视觉定位模块 VLDM(Visual Localization with Diffusion & Multi-view cues)
传统方法仅使用高层特征,容易忽视细节。 VLDM 引入两种增强:
-
Diffusion Prior(扩散先验):借助 CleanDIFT 模型提取低层纹理特征,弥补 DINOv2 等高层特征的细节损失;
-
Multi-View Augmentation(多视角增强):通过旋转、翻转等生成多种视角图像,融合匹配结果提升稳健性。
这样可获得更全面的视觉相似度图,提升局部精度与定位鲁棒性。
✳️ 2. 文本驱动定位 TLGP(Text-driven Localization from Generated Pseudo-labels)
在无文本输入的前提下,MMSeg 自动生成伪类别标签:
-
使用 RAM(Recognize Anything Model) 识别参考图和测试图的伪标签;
-
取多视角交集确定稳定的伪类别;
-
使用 CLIP Surgery 生成干净的文本-图像相似度图;
-
多轮迭代融合视觉与文本相似度,筛选前景/背景点。
最终得到一组多模态融合的提示点(positive/negative prompts),输入 SAM 进行掩码生成。
✳️ 3. 共识导向掩码优化 COMP(Consensus-Oriented Mask Proposer)
SAM 根据提示点生成多个候选掩码。 MMSeg 设计了一个“四步共识”机制,像多个“专家”协同修正掩码:
-
Reconfirming:基于相似度重新筛选高置信度掩码;
-
Voting:多数投票融合重叠区域;
-
Outlier Removal:用形态学腐蚀去除离群噪声;
-
Inlier Repainting:再用膨胀修补被错删的边缘区域。
最终获得边界平滑、语义一致的高质量掩码。
三、实验结果:无训练也能超越训练模型
MMSeg 在多组数据集上表现强劲:
|
数据集 |
方法类型 |
mIoU (%) |
对比提升 |
|---|---|---|---|
| PerSeg |
无训练 |
95.1 |
+0.8% 优于 SegGPT |
| FSS-1000 |
无训练 |
87.4 |
+16.2% 优于 PerSAM |
| COCO-20i |
无训练 |
52.8 |
与 Matcher 持平甚至略高 |
| PASCAL-Part |
无训练 |
44.7 |
+14.6% 优于 PerSAM |
🖼 可视化结果:
-
MMSeg 能精准分割出“背包带、玩具边缘”等细节;
-
在复杂背景下可排除干扰物,如人像、阴影等;
-
掩码边界更平滑连贯,少碎片。
四、优势与局限
✅ 优势
-
🧠 多模态融合:结合视觉与伪文本标签,定位更精准;
-
🌐 多视角一致性:提升泛化与鲁棒性;
-
🎯 完全训练自由:仅用预训练基础模型即可运行;
-
🧩 自校正机制:COMP 提升 Mask 一致性与平滑度。
⚠️ 局限
-
推理速度略慢(多视角匹配与投票步骤复杂);
-
对极端小目标敏感性仍有限;
-
伪标签生成质量依赖 RAM/CLIP 准确率;
-
暂未扩展到视频场景。
📝 一句话总结
MMSeg 让图像提示分割从“单模态模糊”走向“多模态精准”, 在完全无训练条件下,实现可与训练模型媲美的分割性能。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)