Transformer架构详解
Transformer架构由编码器(Encoder)和解码器(Decoder)两部分组成,采用并行化设计替代传统RNN的序列处理模式,显著提升计算效率
·
一、核心架构与组件
Transformer架构由**编码器(Encoder)和解码器(Decoder)**两部分组成,采用并行化设计替代传统RNN的序列处理模式,显著提升计算效率。
-
编码器结构
- 自注意力层(Self-Attention):通过计算词元间的相关性权重(Q/K/V矩阵),动态捕获上下文依赖关系。例如,在句子“他喜欢踢足球”中,模型能识别“他”与“踢足球”的关联性。
- 前馈神经网络(FFN):对注意力输出进行非线性变换,增强模型表达能力。每层FFN由两个线性层和ReLU激活函数组成。
- 残差连接与层归一化:每个子层输出叠加输入并通过LayerNorm,缓解梯度消失问题。
-
解码器结构
- 掩码自注意力层:仅允许关注已生成的词元,确保预测时无未来信息泄露。
- 编码器-解码器注意力:将解码器的Q矩阵与编码器输出的K/V矩阵交互,对齐源语言与目标语言信息(如机器翻译)。
二、关键技术机制
-
自注意力机制
-
计算公式:
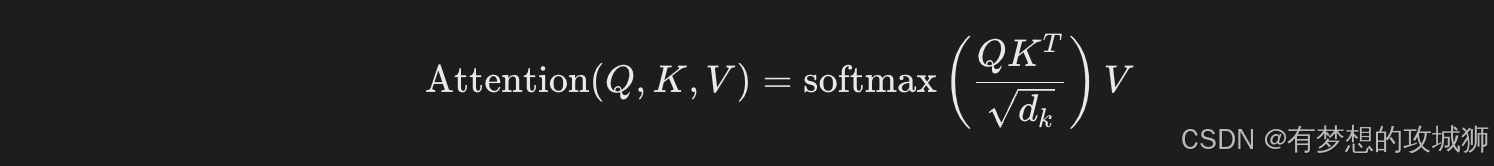
其中 (d_k) 为键向量的维度,用于缩放点积防止梯度爆炸。
-
多头注意力:并行计算多个注意力子空间(如8头),捕获不同粒度的语义关系。
-
-
位置编码(Positional Encoding)
- 绝对位置编码:使用正弦/余弦函数生成位置嵌入,解决并行计算导致的序列顺序缺失问题。
- 相对位置编码(RoPE):在旋转空间中建模词元间相对距离,提升长文本处理能力(如LLaMA模型)。
三、训练与推理流程
-
训练阶段
- 输入处理:源序列与目标序列通过嵌入层转换为向量,目标序列右移并添加起始符(如
<BOS>)。 - 损失计算:交叉熵损失函数衡量预测与真实标签差异,反向传播更新参数。
- 优化策略:
- 使用Adam优化器(β1=0.9,β2=0.98)动态调整学习率。
- 梯度裁剪(如阈值1.0)防止梯度爆炸。
- 输入处理:源序列与目标序列通过嵌入层转换为向量,目标序列右移并添加起始符(如
-
推理阶段
- 自回归生成:逐词预测并更新输出序列,直至生成终止符(如
<EOS>)或达到最大长度。 - 搜索策略:贪婪搜索(快速但局部最优)或束搜索(保留多个候选路径,提升质量)。
- 自回归生成:逐词预测并更新输出序列,直至生成终止符(如
四、技术优势与挑战
-
优势
- 并行计算:全连接结构支持GPU大规模并行加速,训练速度较RNN提升5-10倍。
- 长序列建模:自注意力机制有效捕获长距离依赖(如1000+词元),解决RNN的梯度消失问题。
- 跨领域扩展:适配文本、图像(ViT)、音频(Whisper)等多模态任务。
-
挑战
- 算力需求:训练千亿参数模型需数千GPU/TPU,能耗成本高(如GPT-3训练耗电约1.3GWh)。
- 轻量化需求:通过知识蒸馏(TinyLlama)、稀疏激活(Switch Transformer)压缩模型体积。
五、典型应用场景
- 机器翻译:WMT数据集上BLEU评分超越RNN模型2-3分。
- 文本生成:GPT系列模型实现高质量文章、代码生成。
- 多模态任务:CLIP(图文匹配)、DALL-E(文生图)等扩展应用。
如需代码实现细节或扩展技术(如Flash Attention优化),可参考Transformer实战手册获取完整案例。
拓展


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)