普林斯顿王梦迪团队开源扩散语言模型TraDo,并提出TraceRL框架实现SOTA性能!
TraceRL训练显著增强了模型的数学推理能力:在MATH500上,TraDo-4B-Instruct的静态准确率提升了5.4%,动态准确率提升了4.2%,优化后超过Qwen2.5-7B-Instruct;作为首个支持long-CoT的扩散语言模型,TraDo-8B-Thinking在各类基准测试中展现出强大的推理能力,在MATH500上取得了85.8%的准确率,表明扩散语言模型同样能够在复杂推理
普林斯顿王梦迪团队开源扩散语言模型TraDo,并提出TraceRL框架实现SOTA性能!
原创 没方 智猩猩GenAI 2025年09月19日 11:30 北京
智猩猩GenAI整理
编辑:没方
为了将扩散语言模型(Diffusion Language Model,DLMs )应用于语言任务,已有研究探索了多种方法。DLMs 能够通过并行生成实现大规模推理加速,并通过双向注意力机制提升生成一致性。现有的全注意力扩散模型后训练通过随机掩码估计序列得分,因为语言的序列性和逻辑性并非完全随机,这导致训练过程与最优推理过程之间存在不匹配。而块注意力扩散模型采用了一种半自回归的监督微调方法,但其强化学习机制尚未被探索。
普林斯顿大学王梦迪团队提出了一种面向扩散语言模型的轨迹感知强化学习框架TraceRL。该框架将偏好推理轨迹(preferred inference trajectory)融入后训练过程,可同时应用于全注意力和块注意力扩散模型实现快速优化。通过配备基于扩散模型的价值模型以增强训练稳定性,在复杂的数学和编程任务中显著提升推理性能。研究团队利用TraceRL,开发了一系列优越的扩散语言模型TraDo。TraDo-4B-Instruct在数学任务上的表现优于Qwen2.5-7B-Instruct等强大的自回归基线模型。

-
论文标题:
Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
-
论文链接:
https://arxiv.org/pdf/2509.06949
-
项目地址:
https://github.com/Gen-Verse/dLLM-RL
https://huggingface.co/collections/Gen-Verse/trado-series-68beb6cd6a26c27cde9fe3af
01
方法
块注意力扩散模型采用半自回归微调,其目标如下:
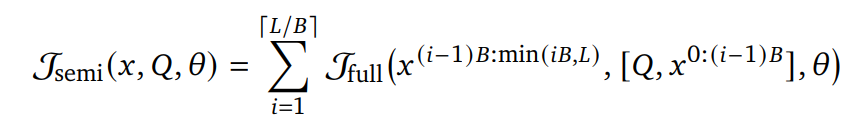
通过块注意力机制能够提升语言模型基于上下文语境生成后续token的能力,同时保持扩散语言模型特有的采样效率优势。
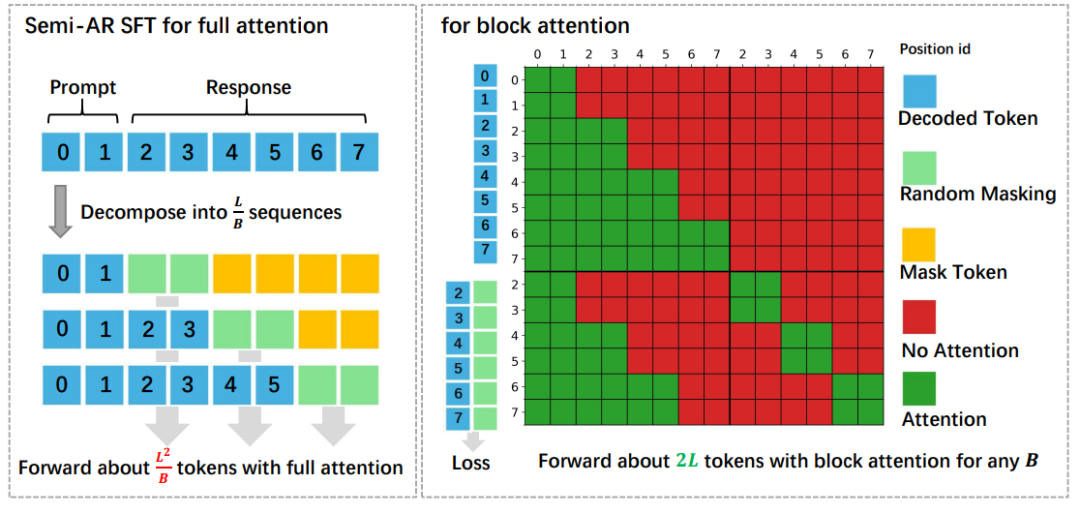
图2 : 全注意力与块注意力模型的半自回归监督微调(Semi-AR SFT)概述图。本示例使用块大小 𝐵 = 2 和序列长度 𝐿 = 6。块注意力扩散模型能够高效地适应半自回归监督微调,而全注意力模型则需要按块大小 𝐵 对数据进行切分。
如图2所示,对于全注意力扩散语言模型,应用半自回归目标函数会不可避免地使前向传播次数增加约⌈𝐿/𝐵⌉倍。然而在计算负载相同的情况下(通过⌈𝐿/𝐵⌉次独立重复实现),
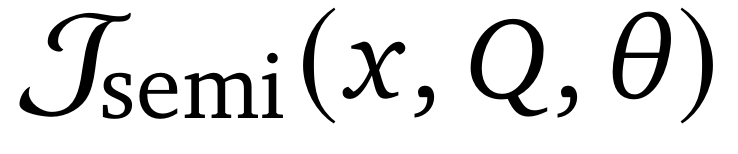
的优化性能显著优于
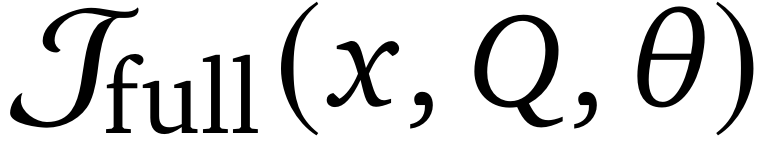
(如表1所示)。表明将后训练目标与通用的从左到右推理模式保持对齐的重要性。
表1:探讨了不同方法在提升模型CoT推理能力方面的有效性,以提升非CoT提示下的推理准确率。2000个数据点由Qwen2.5模型生成,并经过筛选以保留高质量样本。𝑙 表示整个轨迹中每个采集步骤的长度。“×𝑚”表示应用 𝑚 次独立的随机掩码来扩充数据规模以确保公平比较。“Token forward”指模型处理的token总数,代表计算负载或时间。“Token trained”指实际用于优化目标的token数量。此处报告的是在MATH500上的准确率。所使用的块注意力模型为SDAR-4B-Chat(默认块大小为4),全注意力模型为Dream-7B-Instruct。
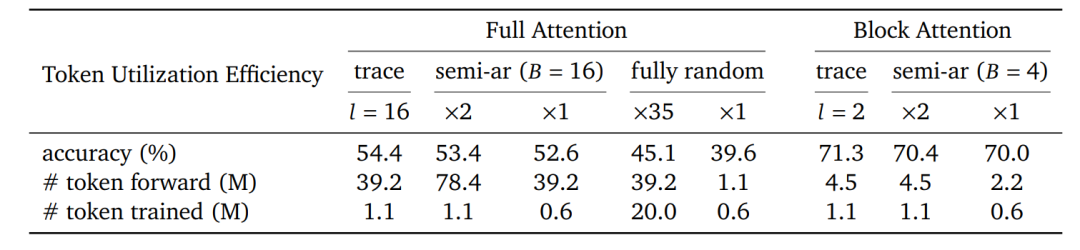
为深入研究,研究团队收集预训练模型从数据集中生成的偏好推理轨迹(preferred inference traces),并将其用于微调。采用静态采样获取每个数据点的最优轨迹,随后将其用于微调过程。表1结果表明:对于块注意力与全注意力结构,使用模型自身的偏好推理轨迹进行微调,能够在低计算负载情况下实现超越基线的性能。
这种微调方法的主要局限是收集推理轨迹需要很大的工作量。相比之下,强化学习在rollout过程中自然生成这些轨迹,使其成为更具实用性的后训练策略。基于此,研究团队提出TraceRL框架,工作流程如图3所示。该框架专注于DLM生成的中间轨迹,可适用于不同架构。研究团队还引入了一种基于扩散模型的价值模型,有助于减少方差并提高训练稳定性。
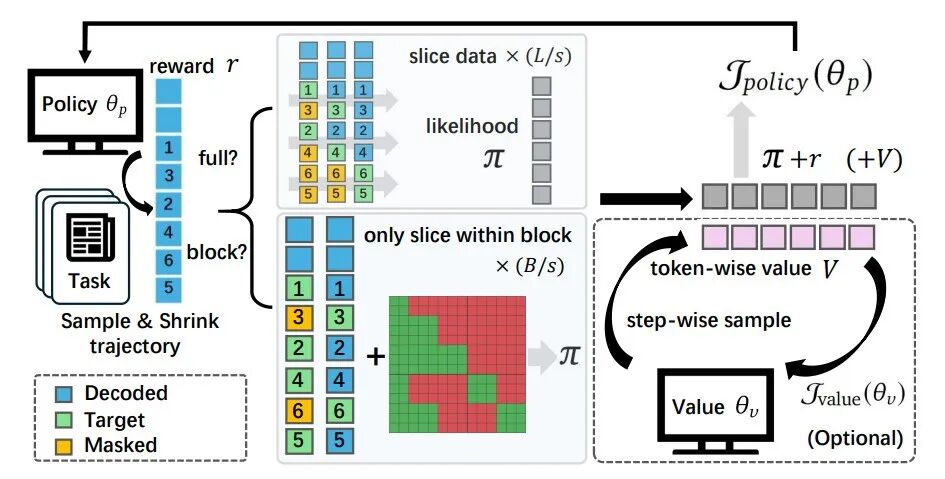
图3:TraceRL 概述图,这是一个 s = 2、L = 6 且 B = 3 的示例。研究团队将每 s 个相邻步骤进行聚合,以执行轨迹感知的强化学习。方块中的数字表示策略推理过程的顺序。
对于给定任务Q生成的每个响应τi,可将其表示为轨迹形式τi≜(τi(1),…,τi(∣τi∣)),其中,∣τi∣为解码总步数,τi(t)为第t步解码的token集合。TraceRL基于响应τi的可验证奖励ri,对策略πθ的生成轨迹进行奖励或惩罚。通过价值模型还可引入过程级奖励。
(1)基于收缩参数的加速训练
对于全注意力模型,基于每次采样步骤分解序列会导致训练过程中大量的前向传递。因此,研究团队引入了一个收缩参数 s,它将每 s 个相邻步骤聚合在一起以提高训练效率。研究团队将轨迹压缩为
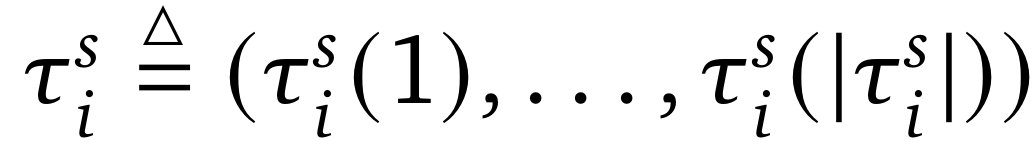
,其中
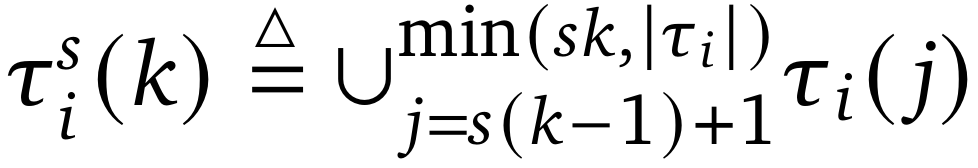
、
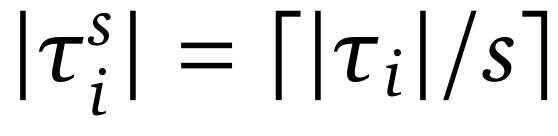
,优化目标如下所示:
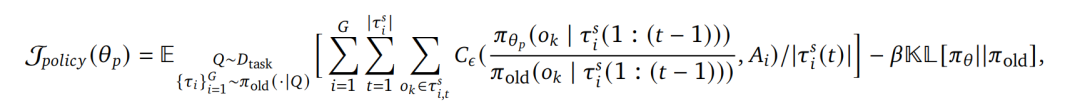
通过引入收缩参数 s,将训练计算复杂度降低了 s 倍。可以直接使用
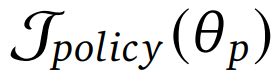
进行高效的RLVR。
(2)基于扩散模型的价值模型
研究团队采用基于扩散模型的价值模型进行逐步价值(step-wise values)估计。对于每条生成的轨迹τ(可能经过收缩因子 s 压缩)。评估冻结的价值网络
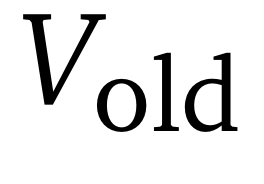
来获取轨迹token级别的价值
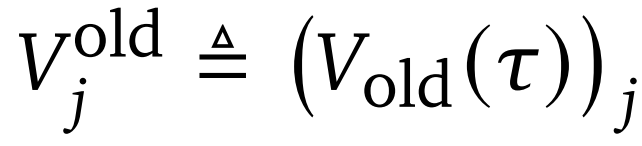
,对于每个轨迹的步骤t,在前缀 τ(1:τ−1)的条件下预测该步骤生成的所有token的价值
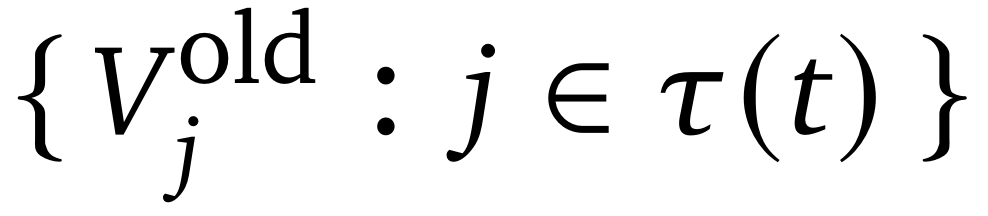
;将第t步的逐步价值定义为
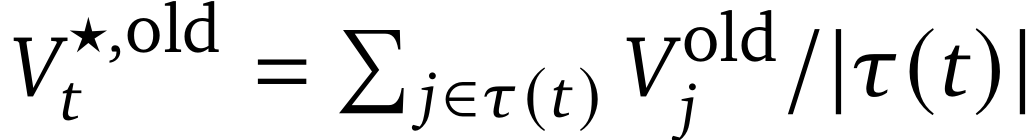
。
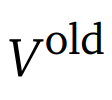
在构建回报(returns)和优势时被视为停止梯度(stop-gradient)的基线;可学习的价值网络
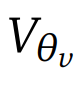
仅通过其自身的回归目标函数进行后续更新。
训练目标推导如下:

价值网络通过剪裁回归损失进行训练:
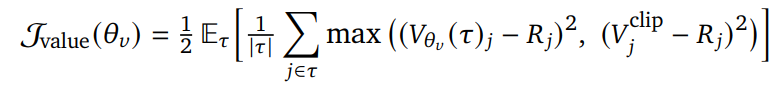
其中,
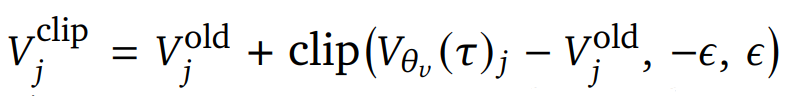
,token优势
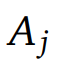
被用于
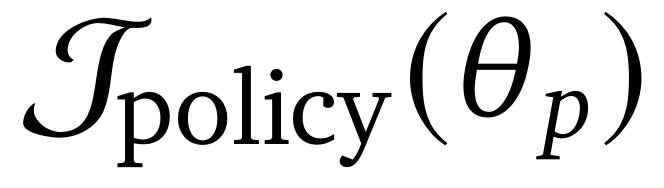
以更新策略。
(3)块注意力扩散模型切片训练
块扩散模型采用块注意力机制进行高效的监督微调,研究团队将这一优势拓展到强化学习。对于每个由块推理生成的处理过的轨迹 τ,将其表示为

。每个块定义为
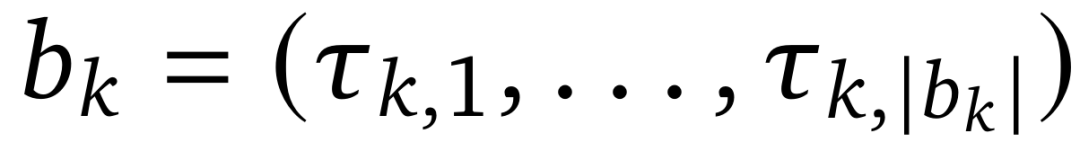
,具有
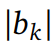
步。将块大小记作B,训练目标可以从
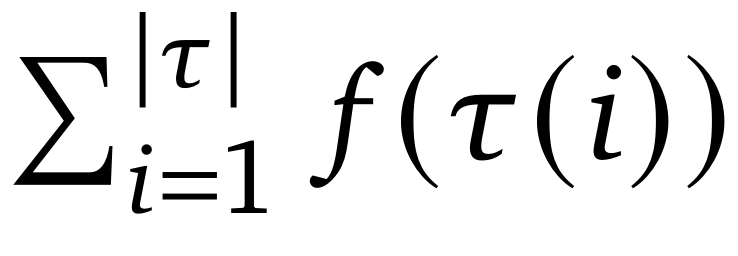
切分为B′个训练切片,即
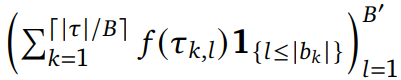
。其中,f 是特定任务的函数,
![]()
。每个切片只需使用块注意力机制进行一次前向传播。这种公式化方法能够最大化块注意力机制,实现高度并行和高效的训练,适用于策略和价值模型的训练,比全注意力训练更高效。
02
评估
研究团队使用不同的数据源进行强化学习。对于数学任务,选择了MATH训练数据集并仅保留第3至第5级别的任务,最终得到8000个难题。在编程强化学习设置中,使用来自PrimeIntellect的6000个经验证的问题,这些问题由DeepCoder进行了验证。
评估同时包含全注意力模型与块注意力模型。全注意力模型采用Dream-7B-Instruct作为基础模型;块注意力模型使用SDAR系列模型,其训练采用的块大小为4。
表2 :数学和编程任务上的主要基准测试结果。“Static”指的是静态采样,“Dynamic”指的是动态采样。这里的 long-CoT 模型 TraDo-8B-Instruct 通过阈值为 0.9 的动态采样进行评估。
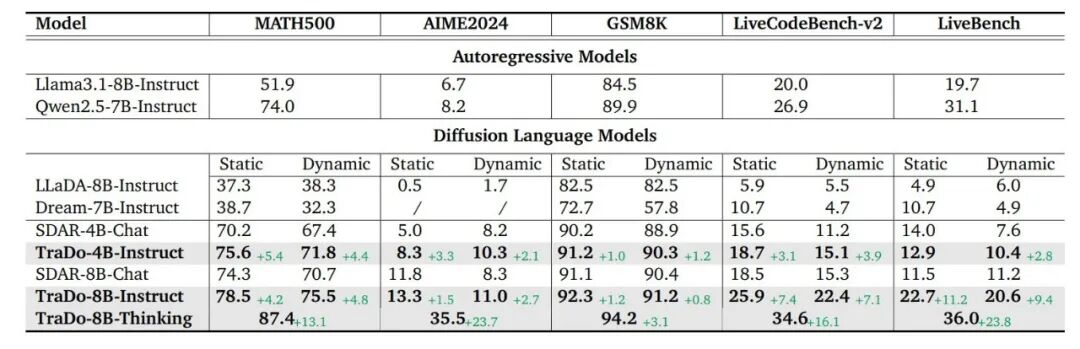
在数学和编程任务应用TraceRL,由SDAR基础模型进行训练得到了TraDo-4B-Instruct和TraDo-8B-Instruct。在数学、编程等推理数据集上对这些模型进行评估。在当前扩散模型中,TraDo指令模型在推理任务上实现了SOTA性能,证明了TraceRL的有效性。无论是动态采样(速度更快)还是静态采样(更准确),其生成能力都得到了显著提升。此外,TraDo-4B-Instruct在所有数学任务上的表现均优于Qwen2.5-7B-Instruct等强大的自回归基线模型。
Long-CoT 扩散语言模型TraDo-8B-Thinking源自TraDo-8B-Instruct,通过long-CoT监督微调与TraceRL相结合的方式进行训练。作为首个支持long-CoT的扩散语言模型,TraDo-8B-Thinking在各类基准测试中展现出强大的推理能力,在MATH500上取得了85.8%的准确率,表明扩散语言模型同样能够在复杂推理任务中表现出色。
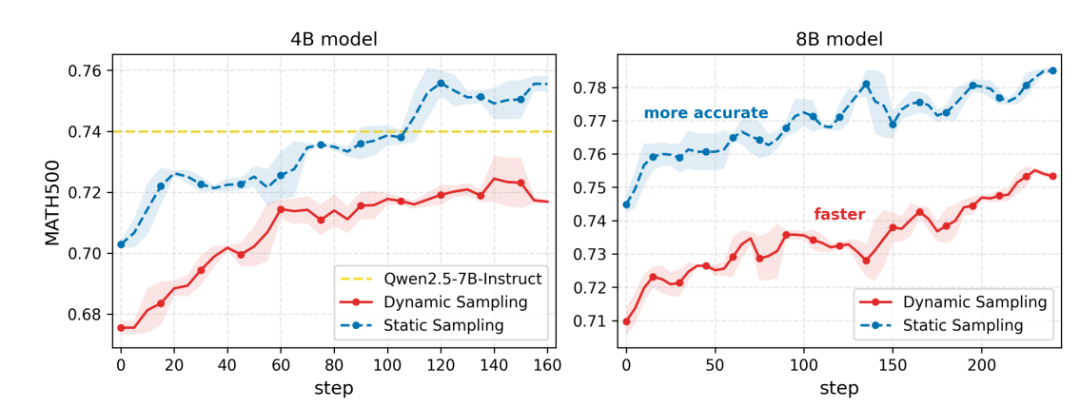
图4 : 4B和8B模型在数学任务上的TraceRL训练曲线。红色曲线代表动态采样准确率,实现了更快的采样速度;蓝色曲线代表静态采样准确率,达到了更高的准确率。4B模型通过价值函数模型进行训练,而8B模型直接使用

进行训练。
4B和8B指令模型在数学任务上的训练动态如图4所示。可以发现,动态和静态采样的准确率都实现了稳步提升,该趋势表明仍有进一步扩展的潜力。TraceRL训练显著增强了模型的数学推理能力:在MATH500上,TraDo-4B-Instruct的静态准确率提升了5.4%,动态准确率提升了4.2%,优化后超过Qwen2.5-7B-Instruct;TraDo-8B-Instruct的静态准确率提升了4.2%,动态准确率提升了4.8%。
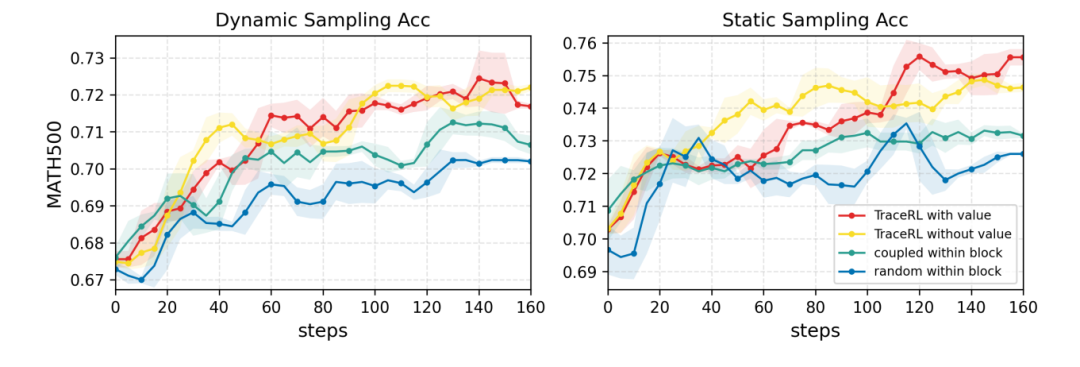
图5 :在块注意力扩散模型和数学强化学习任务上的RL方法消融实验。红色和黄色曲线分别表示使用和不使用价值模型的TraceRL。蓝色曲线对应在块内使用随机掩码目标的训练方法,类似于半自回归训练方法。绿色曲线表示在块内增加一个互补掩码进行训练。
研究团队将TraceRL与现有的强化学习方法进行了比较,首先聚焦于块注意力扩散模型。尽管当前的强化学习方法主要是为全注意力模型设计,研究团队仍将其直接适配到块结构设置中。对于随机掩码(random masking)方法,限制在每个块内进行采样,使其类似于一种半自回归方法。对于coupled RL,在每个块内引入了一个互补的目标从而实现更稳定、更有效的训练。在数学任务上评估了这些方法,结果如图5所示。实验表明,无论是否使用价值模型,TraceRL都实现了最佳的优化效果。所有强化学习方法在rollout阶段均采用动态采样,而TraceRL在动态和静态两种评估设置下均表现出更佳的优化性能。这表明了即使在较小的块内,对偏好轨迹进行优化也至关重要。
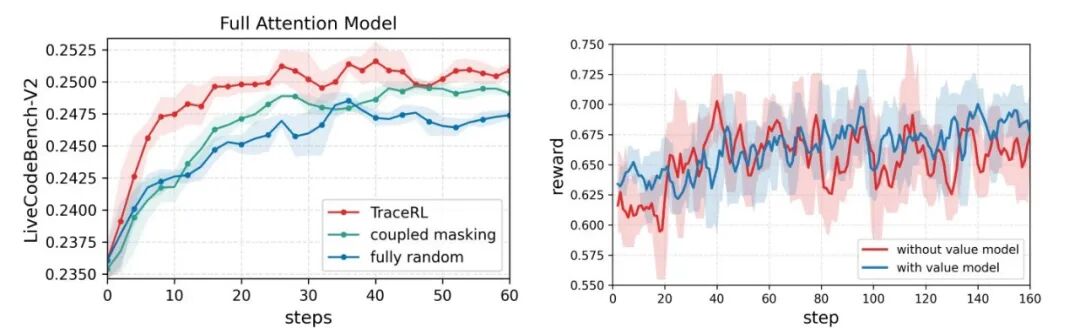
图6:(a) 针对全注意力模型Dream-7B-Coder-Instruct在编程任务上的强化学习训练消融实验。(b) 使用与不使用价值模型的对比表明,引入价值模型能够减少训练过程中的波动。
为验证TraceRL方法的广泛适用性,在编程强化学习任务中对全注意力模型进行了实验。以Dream-7B-Coder-Instruct作为基础模型,在执行强化学习训练前先基于蒸馏数据进行冷启动微调。为加速训练过程,设置收缩参数 𝑠 为 8。参照表1的做法,为两种基线方法扩充了训练数据。实验结果表明,TraceRL相比基线方法收敛更快且达到最佳性能。此外,经过TraceRL训练后的模型在LiveCodeBench-V2上达到25.0%的准确率,实现了开源全注意力扩散语言模型新SOTA。
END
✦
✦
推荐阅读
✦
突破任意比特通信瓶颈!美团英伟达提出FlashCommunication V2,加速LLM分布式训练与部署
LLM后训练新范式!字节提出后完成学习PCL:在后完成空间进行SFT与RL混合训练
图灵奖得主Sutton最新成果!拓展强化学习到控制领域,有望媲美深度强化学习
Hugging Face周榜第一!人大高瓴与快手联合提出ARPO强化学习算法,专为Agent而生
华人团队开源世界首个多智能体记忆系统MIRIX:准确率较Gemini提高410%,存储需求降了9成

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)