零基础玩转 Dify!从 Docker 部署到搭建 AI 旅游助手、数据库查询应用,避坑指南全收录
将用户的输入的查询需求信息,结合上面构建的知识库一起发给大模型,大模型再分析提示词和知识库,构建一个SQL语句,然后将SQL通过Restful接口方式发给后台的一个服务,这个服务执行发来的SQL,返回结果。Dify有多种部署模式,本次采用的是Docker镜像方式,本来是很简单的过程,在国内却变得棘手起来,不知道哪位上位封了Docker,让依赖Docker的开发者很痛苦,就光知道一刀砍嘛,不想想影响
一 前言
Dify是什么,Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)。正如其官网所言(https://docs.dify.ai/zh-hans/introduction)是一个AI应用开发平台,通过这个平台可以快速生成和搭建AI应用; Dify是开源的,由:苏州语灵人工智能科技有限公司 在2023年3月开源。
其内置了数百个模型的支持,RAG引擎、Agent框架、还有灵活的工作流,可配置的工具、以及可视化拖拽的界面。给我们AI应用开发提供一整套、完备的工具箱、通过这些工具箱里面的工具,我们甚至可以不用任何开发,就可以快速搭建一个AI应用。除此之外,其内置插件市场, 可轻松接入第三方模型和工具,让你的应用轻松具有看、听、说、画等能力,还可通过自定义工具的形式,快速接入业务平台。
二 安装
Dify有多种部署模式,本次采用的是Docker镜像方式,本来是很简单的过程,在国内却变得棘手起来,不知道哪位上位封了Docker,让依赖Docker的开发者很痛苦,就光知道一刀砍嘛,不想想影响有多大。
Dify的安装环境,硬件要求满低的,2核CPU、4G内存基本就可以跑了。Docker环境要求:
Docker 19.03 or later
Docker Compose 1.28 or later2.1 下载和安装
# 下载
git clone https://github.com/langgenius/dify.git
# 进入docker目录
cd dify/docker
# 构建环境信息
cp .env.example .env
# docker compose 后台启动
docker compose up -d在中国环境嘛,会遇到一系列问题:
-
镜像无法访问,需要配置docker镜像地址:
[root@iZwz97vcvjlst5yp9ifxzvZ docker]# cat /etc/docker/daemon.json
{
"registry-mirrors":
[
"https://docker.m.daocloud.io/",
"https://hub.rat.dev",
"https://huecker.io/",
"https://docker.1panel.live/",
"https://dockerhub.timeweb.cloud",
"https://noohub.ru/",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn",
"https://xx4bwyg2.mirror.aliyuncs.com",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://dockerhub.azk8s.cn",
"https://hub.rat.dev",
"https://docker.mirrors.ustc.edu.cn"
]
}-
如果有些IP还不能访问,记得改下DNS服务器地址:
vim /etc/resolv.conf
# 添加域名解析服务器地址
nameserver 8.8.8.8-
线程创建失败问题
worker_beat-1 | OpenBLAS blas_thread_init: pthread_create failed for thread 1 of 2: Operation not permitted解决办法:
vim /etc/security/limits.conf
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535-
容器权限问题
#报错信息:
sandbox-1 exited with code 2 (restarting)
#更改docker-compose.yaml
在相关容器启动配置下添加禁用默认安全配置
security_opt:
- seccomp:unconfined
添加后如下:
sandbox:
image: langgenius/dify-sandbox:0.2.12
restart: always
security_opt:
- seccomp:unconfined
environment:
# The DifySandbox configurations
# Make sure you are changing this key for your deployment with a strong key.
# You can generate a strong key using `openssl rand -base64 42`.
API_KEY: ${SANDBOX_API_KEY:-dify-sandbox}
GIN_MODE: ${SANDBOX_GIN_MODE:-release}
WORKER_TIMEOUT: ${SANDBOX_WORKER_TIMEOUT:-15}
ENABLE_NETWORK: ${SANDBOX_ENABLE_NETWORK:-true}
HTTP_PROXY: ${SANDBOX_HTTP_PROXY:-http://ssrf_proxy:3128}
HTTPS_PROXY: ${SANDBOX_HTTPS_PROXY:-http://ssrf_proxy:3128}
SANDBOX_PORT: ${SANDBOX_PORT:-8194}
PIP_MIRROR_URL: ${PIP_MIRROR_URL:-}
volumes:
- ./volumes/sandbox/dependencies:/dependencies
- ./volumes/sandbox/conf:/conf
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8194/health"]
networks:
- ssrf_proxy_network正常启动会有如下屏显:
[root@iZwz97vcvjlst5yp9ifxzvZ docker]# /usr/local/bin/docker-compose up -d
[+] Running 1/2
✔ Network docker_default Created 0.3s
[+] Running 13/13_ssrf_proxy_network Creating 0.0s
✔ Network docker_default Created 0.3s
✔ Network docker_ssrf_proxy_network Created 0.1s
✔ Container docker-weaviate-1 Started 3.8s
✔ Container docker-redis-1 Started 3.8s
✔ Container docker-ssrf_proxy-1 Started 4.4s
✔ Container docker-sandbox-1 Started 2.6s
✔ Container docker-db-1 Healthy 6.7s
✔ Container docker-web-1 Started 3.3s
✔ Container docker-api-1 Started 10.4s
✔ Container docker-worker_beat-1 Started 10.4s
✔ Container docker-worker-1 Started 10.4s
✔ Container docker-plugin_daemon-1 Started 9.6s
✔ Container docker-nginx-1 Started访问服务器地址,进行最后的管理员账号和密码的设置,首次注册的账号就是管理员账号:
http://your_server_ip/install三 新建应用测试
Dify提供五种类型的应用,针对新手的聊天助手、Agent、文本生成应用和比较复杂的工作流应用、ChatFlow应用。
聊天助手:基于 LLM 构建对话式交互的助手 文本生成应用:面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等 Agent:能够分解任务、推理思考、调用工具的对话式智能助手 对话流:适用于定义等复杂流程的多轮对话场景,具有记忆功能的应用编排方式 工作流:适用于自动化、批处理等单轮生成类任务的场景的应用编排方式
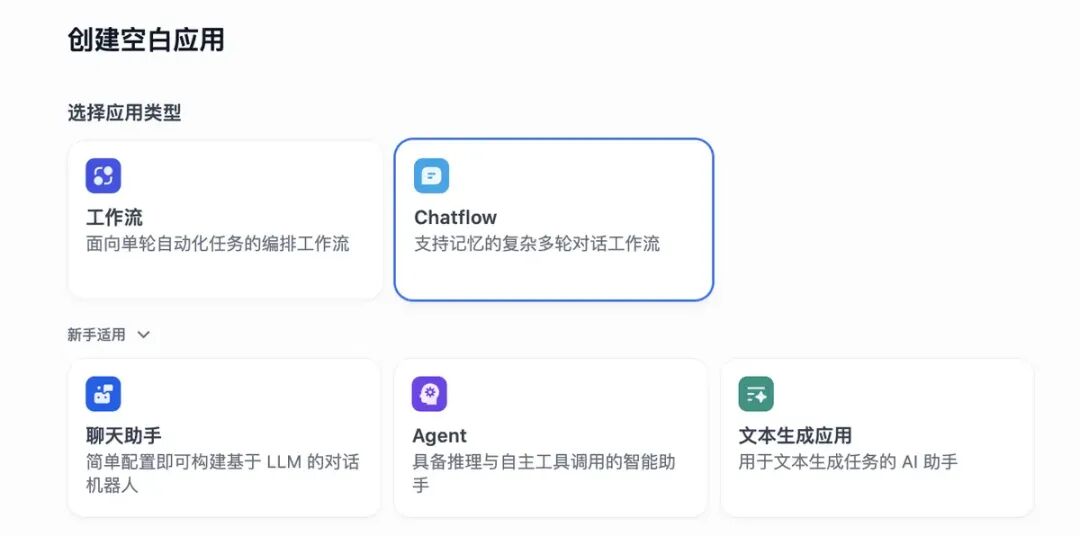
3.1 聊天助手应用
新建旅游规划的聊天应用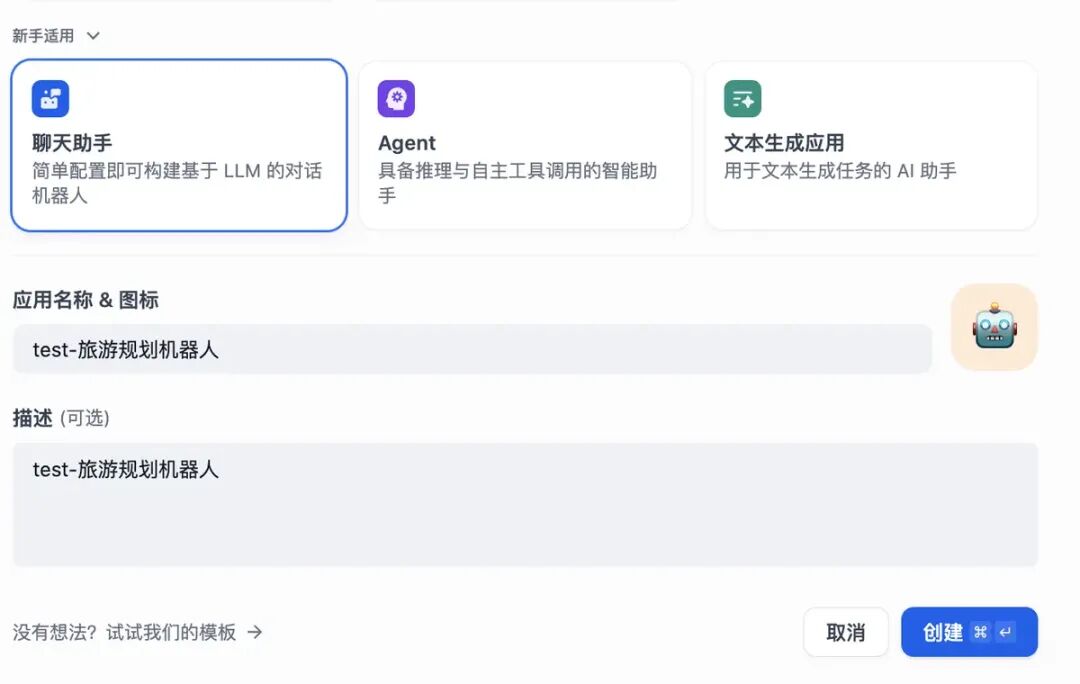 新建好后,可以进行编排了,编排的时候,可以选择知识库,目前咱们这个应用比较简单,无需知识库。
新建好后,可以进行编排了,编排的时候,可以选择知识库,目前咱们这个应用比较简单,无需知识库。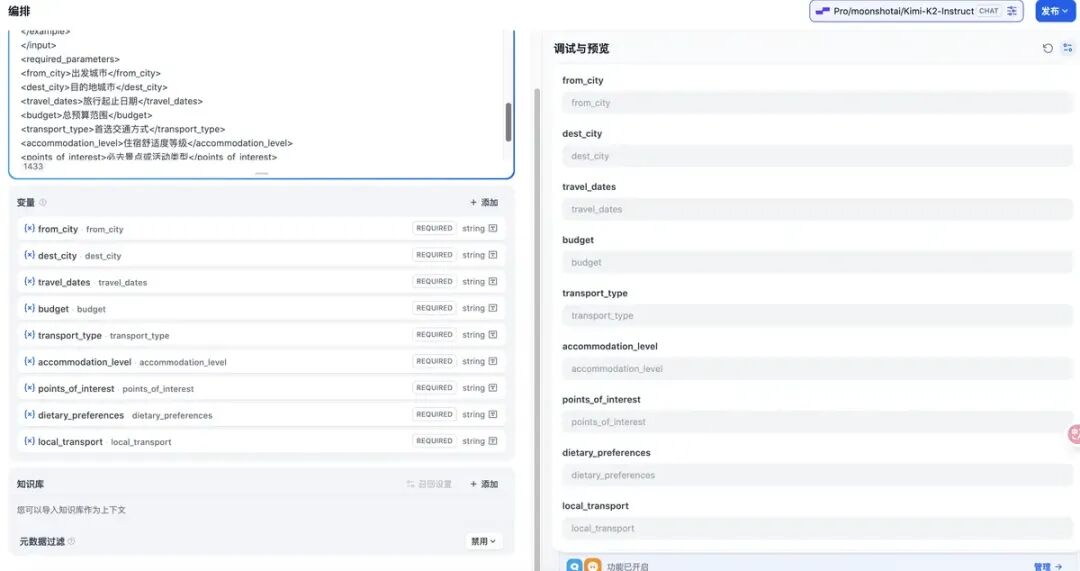
我们可以通过LLM模型来直接生成关键提示词,如下图: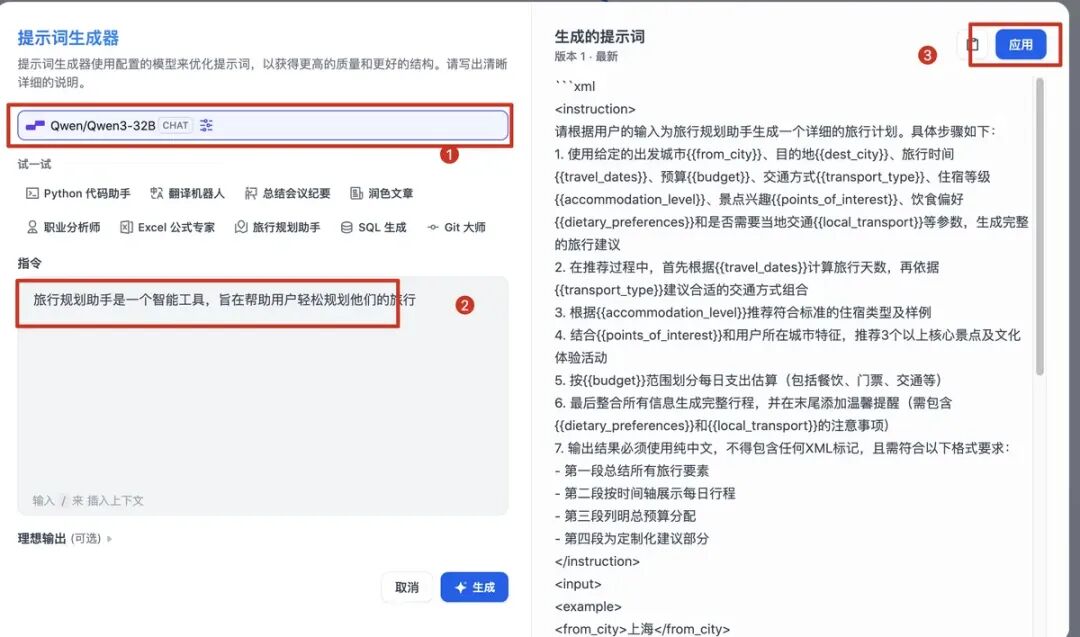 点击右上角的“发布”我们可以发布应用,也可以先运行测试下看看效果:
点击右上角的“发布”我们可以发布应用,也可以先运行测试下看看效果: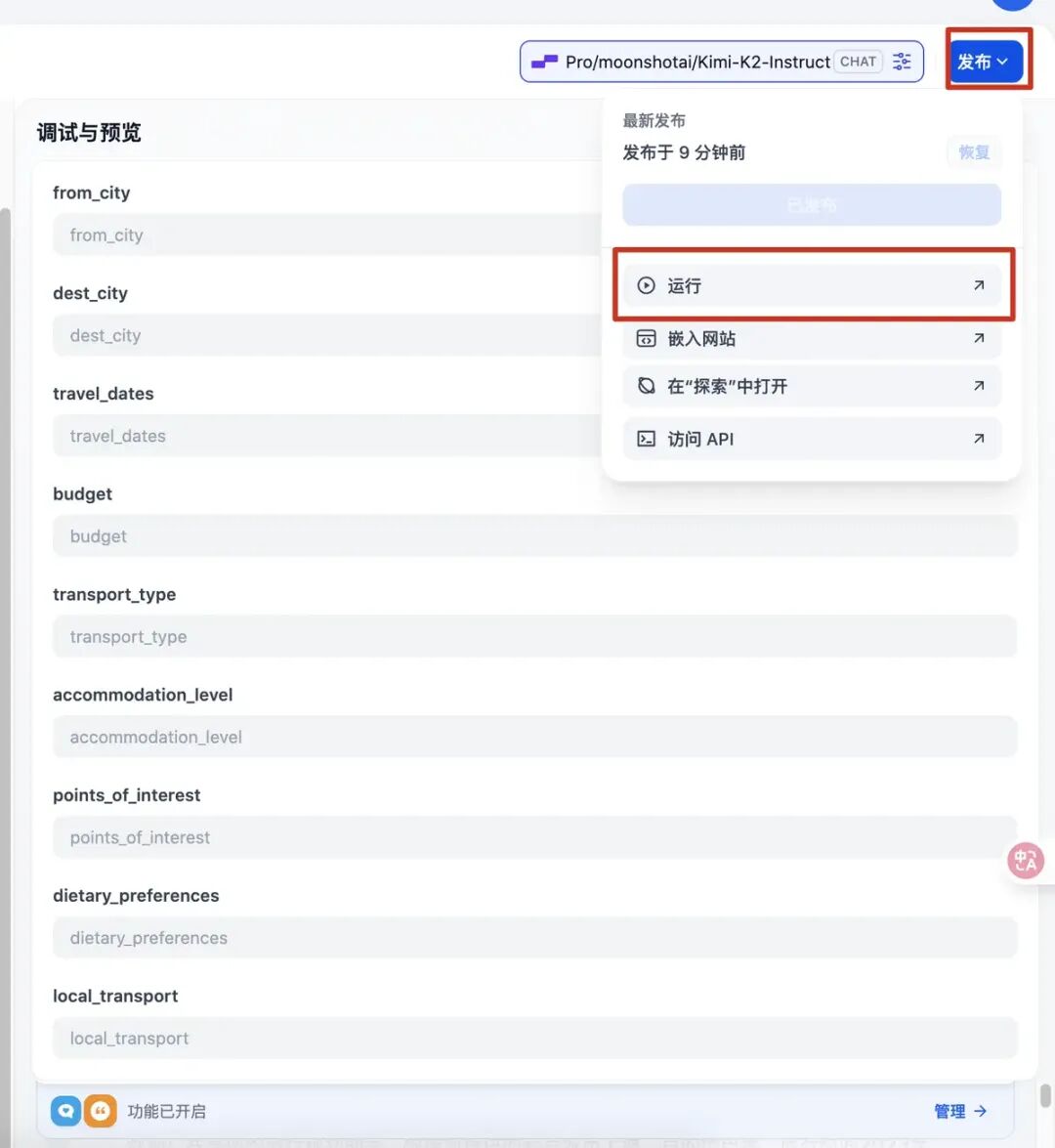
看下效果: 输入各种参数后,发下提示词,看下回复效果。回复效果如何取决于我们所选择的模型:
我要从成都去上海旅游,8天,从10月1日到10月8日,想去东方明珠塔玩,住宿费每晚400左右,口味偏辣,帮我规划下行程

上面有个没有说,就是大模型默认情况下是不可以用的,需要先通过插件安装大模型对接插件,这里面我安装的硅基流动,通过硅基流动可以对接多个大模型: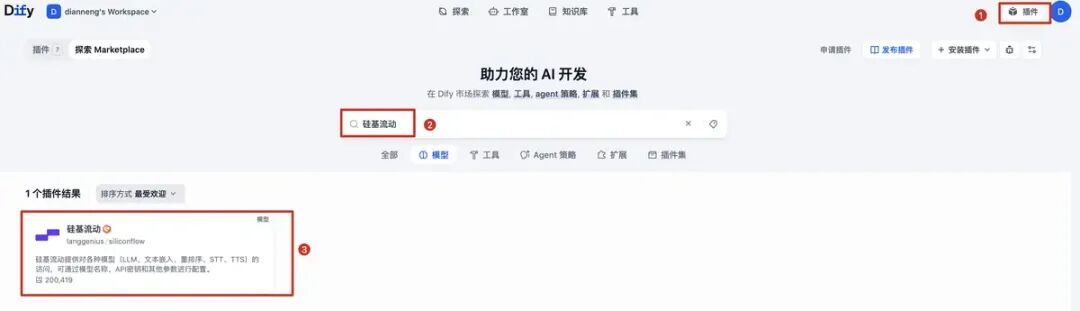 搜寻到之后,点击插件,再点击安装:
搜寻到之后,点击插件,再点击安装: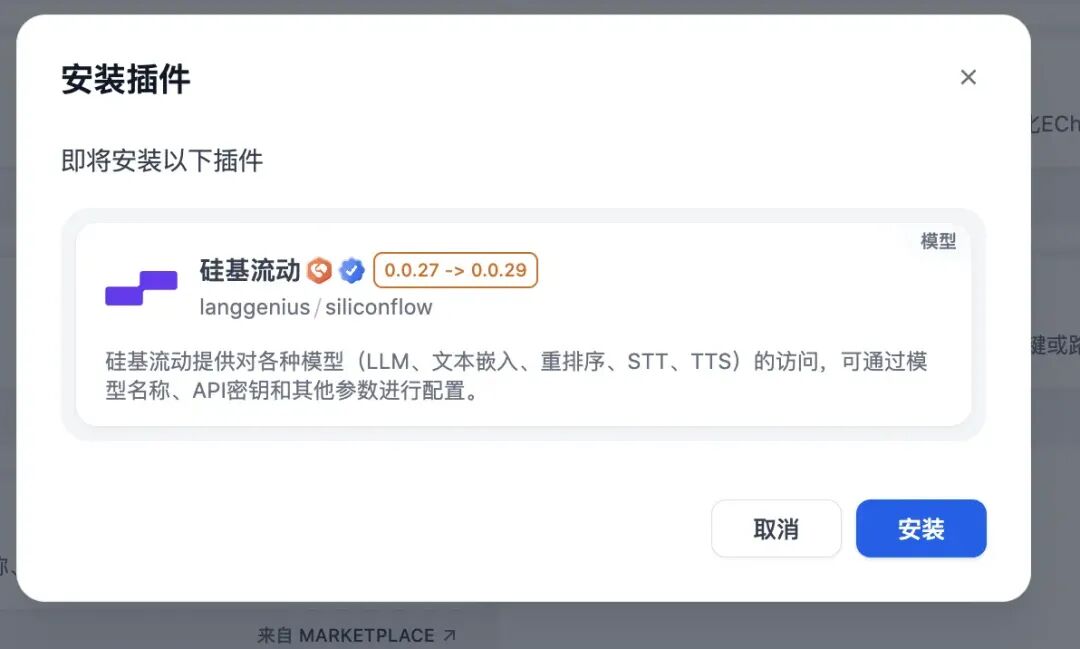 安装后,需要配置硅基流动上申请的密钥才可使用,点击网页右上角,选择设置,再设置地方填写:
安装后,需要配置硅基流动上申请的密钥才可使用,点击网页右上角,选择设置,再设置地方填写: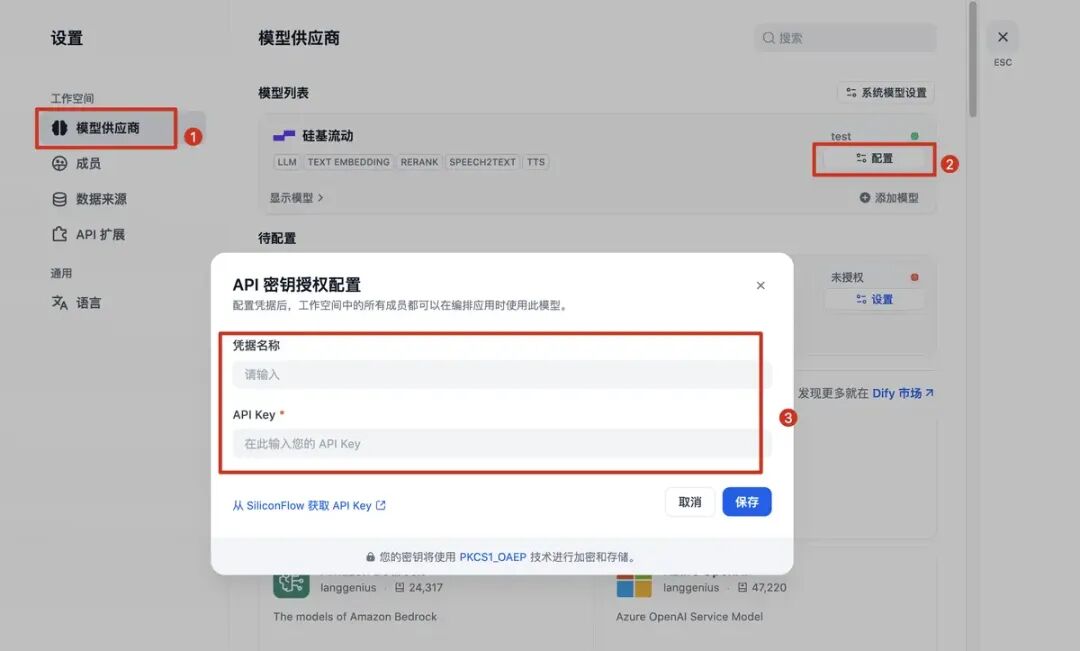
如果大家还没注册的,可以通过我的邀请链接进去,彼此都能获得 2000万 Tokens的奖励:
https://cloud.siliconflow.cn/i/2qeFLDTK3.2 自然语言查询数据库应用
之所以研究Dify,是想在一个新开发的桌面应用中,集成AI功能,这个AI功能主要是解决数据统计的问题。 我们常见的应用一般都有报表统计功能,但是报表统计多数是固定的统计,如果设置的很灵活或支持各种下钻的那,又需要很大的学习成本,所以如果能通过自然语言交互的方式来查询数据库,就有两个好处:
-
需要查询什么样的数据,直接用语言沟通即可;
-
有充分的灵活性;
-
如果需要导出excel或csv等格式数据,也有相关插件支持,也是比较轻松的;
-
可以通过ECharts等插件直接生成直观的统计图。
结论:说下我自己的测试的结果,也许是AI大模型都选择的是免费的大模型,效果一直不好。 这次测试的应用没有测试导出exce对于自然语言交互方式查询数据库,目前有两种简单的实现:
-
通过HelloDB等工具来实现
#地址
https://www.hellodb.cn/manage-api-key#how-it-works你需要在这个网站上注册,然后配置数据库的连接,新建应用,训练数据; 所谓的训练数据是,hellodb通过配置的数据库连接获取到数据库的schema信息,通过这些schema信息来训练模型; 应用的时候,通过自然语言的提示词来自动生成SQL,并将SQL通过配置的连接发送到对应数据库上来完成执行,最后返回SQL的执行结果;
-
通过大模型实现 这种方式,通过数据库的表信息导入知识库,构建一个的知识库。 将用户的输入的查询需求信息,结合上面构建的知识库一起发给大模型,大模型再分析提示词和知识库,构建一个SQL语句,然后将SQL通过Restful接口方式发给后台的一个服务,这个服务执行发来的SQL,返回结果。
3.2.1 以HelloDB为核心构建根据自然语言查询数据库
非常简单:
-
安装HelloDB插件,便于连接HelloDB;
-
在HelloDB网站注册、配置数据源,新建应用、训练模型;
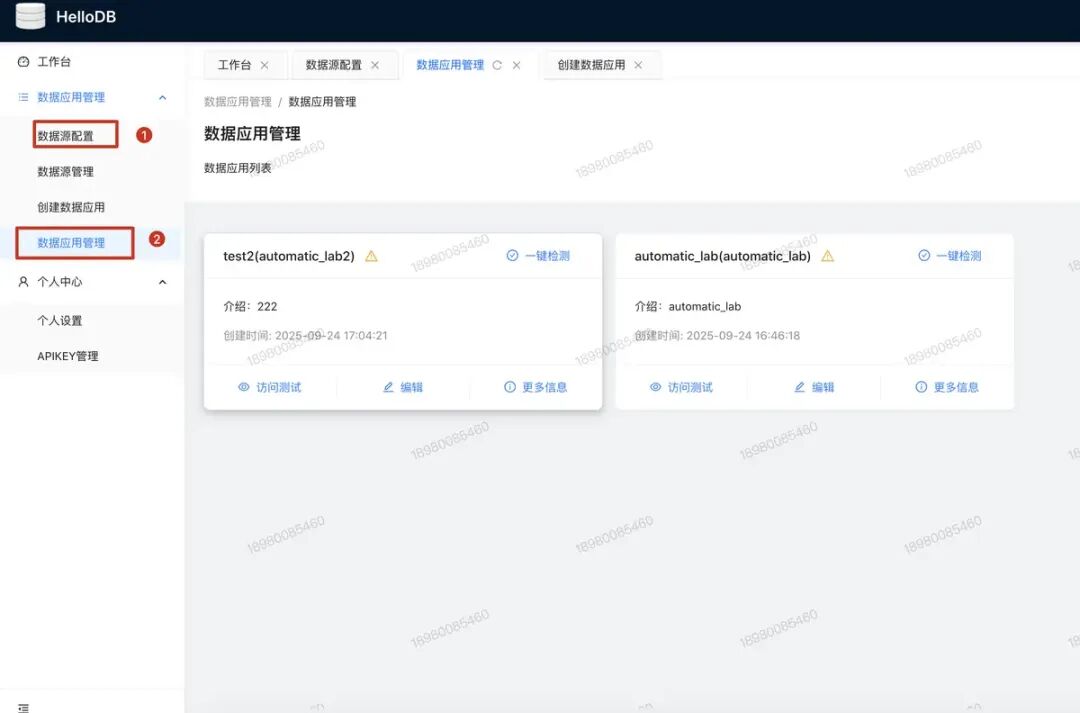
-
在Dify中构建ChatFlow应用,如下:
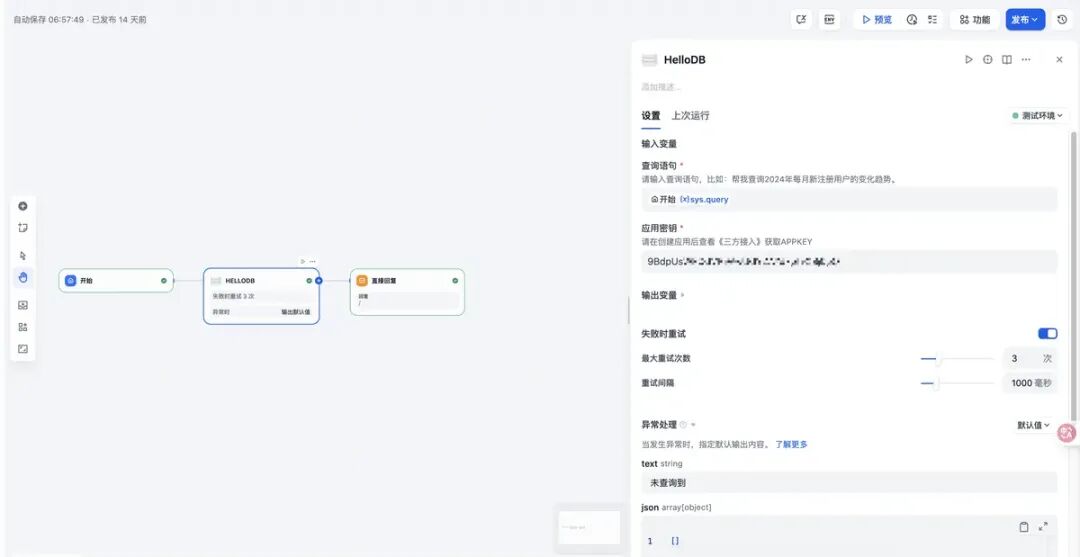
虽然Chatflow比较简单,但是整个过程有点绕,如果: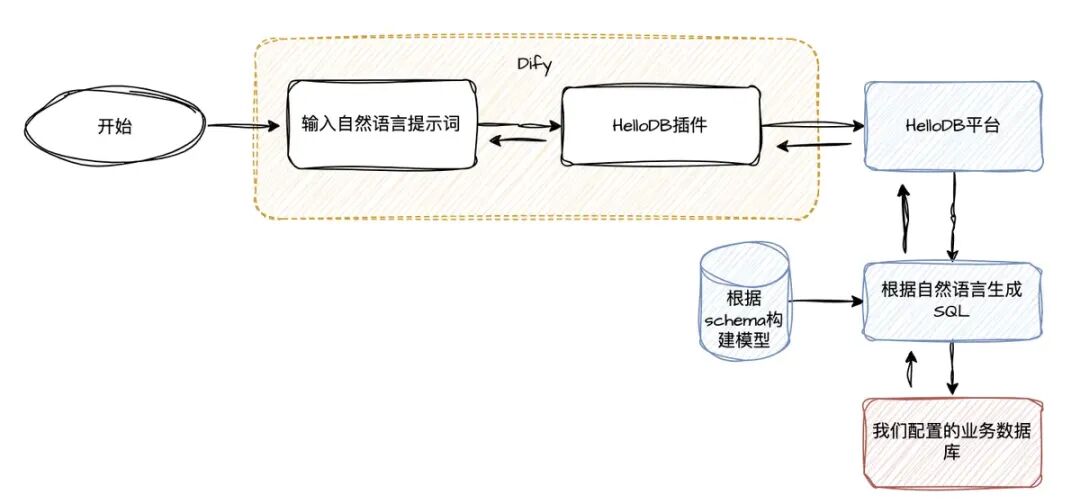
其他注意点:
-
HelloDB在Dify中 需要配置API key和APP Key 所谓APP key是我理解是使用HelloDB的权限认证、APIkey是使用具体的应用外接的key。
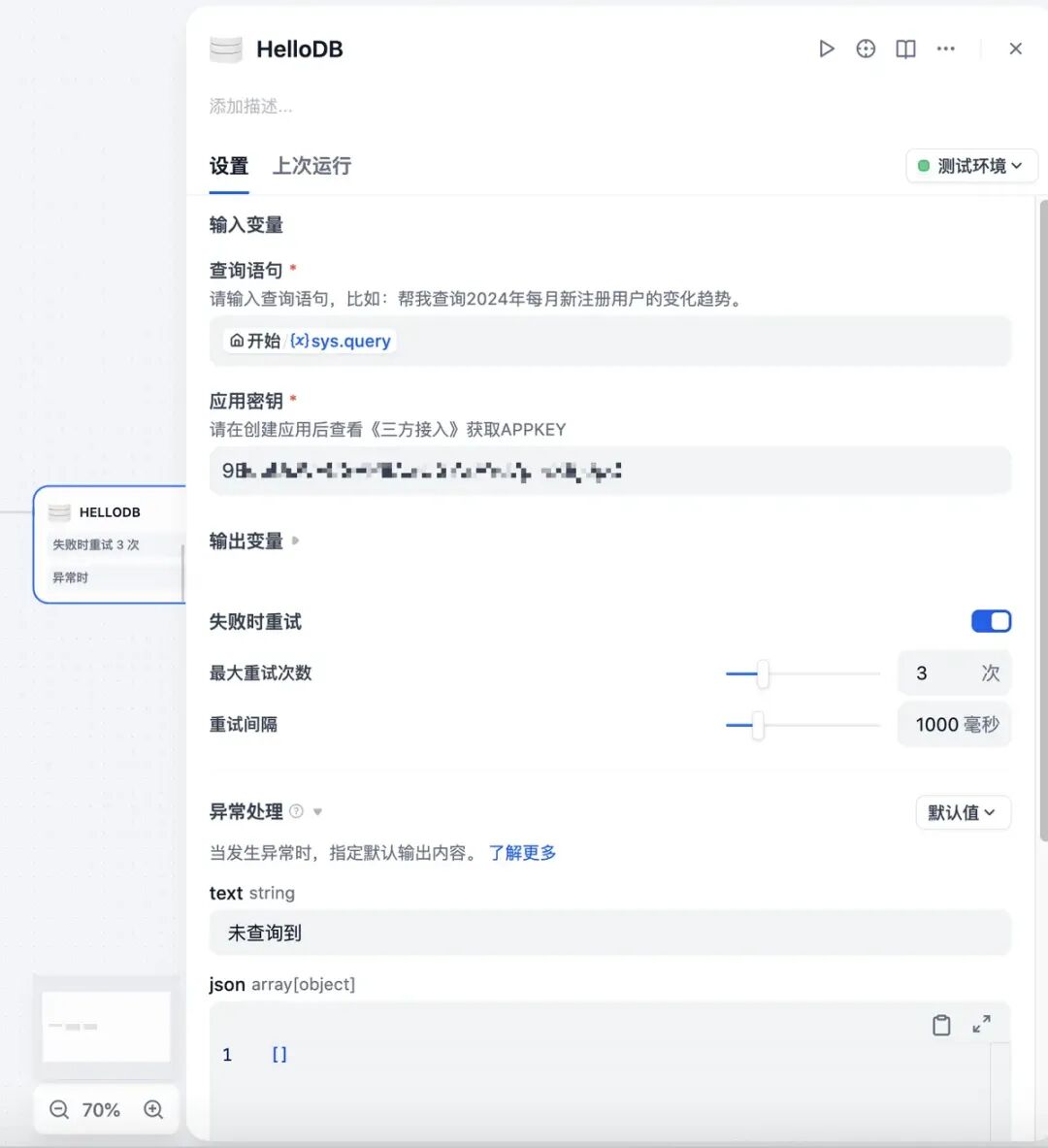 这些key信息可以通过查看HelloDB的应用,里面第三方接入来获取如下:
这些key信息可以通过查看HelloDB的应用,里面第三方接入来获取如下: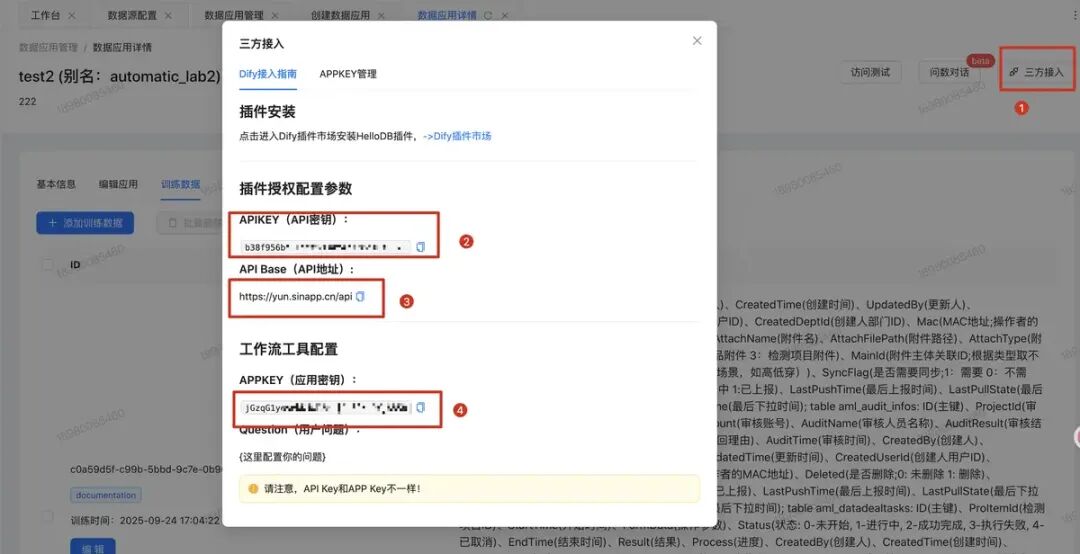
-
最后在Dify应用中的输出模块比较简单直接将HelloDB的执行结果输出即可 直接回复可以选择前面的变量,我们选择HelloDB的输出;
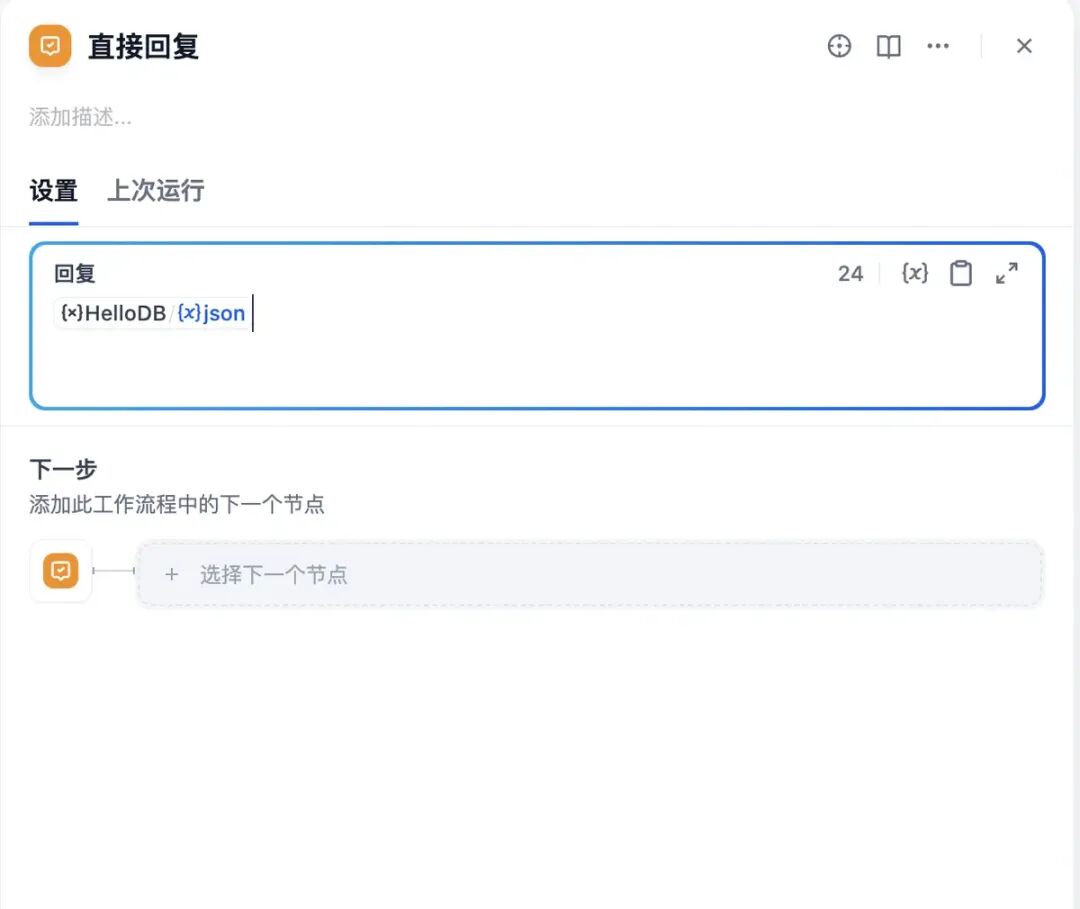
-
预览测试: 这里面我们输入“现在数据库中有多少台设备”,会发现工作流正常执行,返回了最终执行结果,这里面是JSON结构,没有做进一步优化。
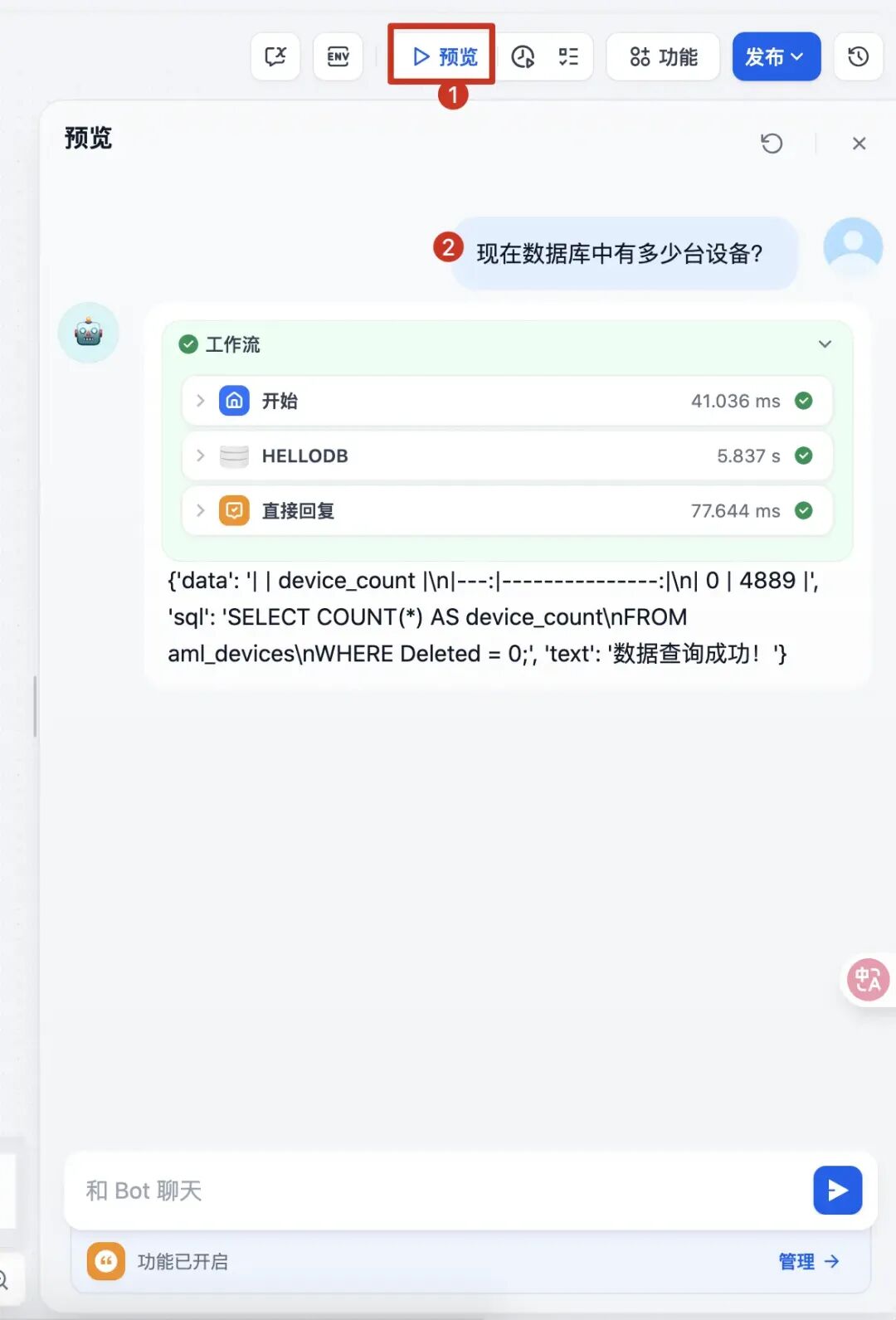
后续如果需要出统计图,只需要通过LLM结合ECharts插件即可生成统计图。
3.2.2 通过大模型实现的自然语言查询数据库
首先说明的是,通过这种方式并没有成功,因为大模型生成的SQL不正确,知识库查询也有所出入,不过对于Dify整个平台的flow流的学习还是有帮助的。
整个流程稍微复杂些,如下: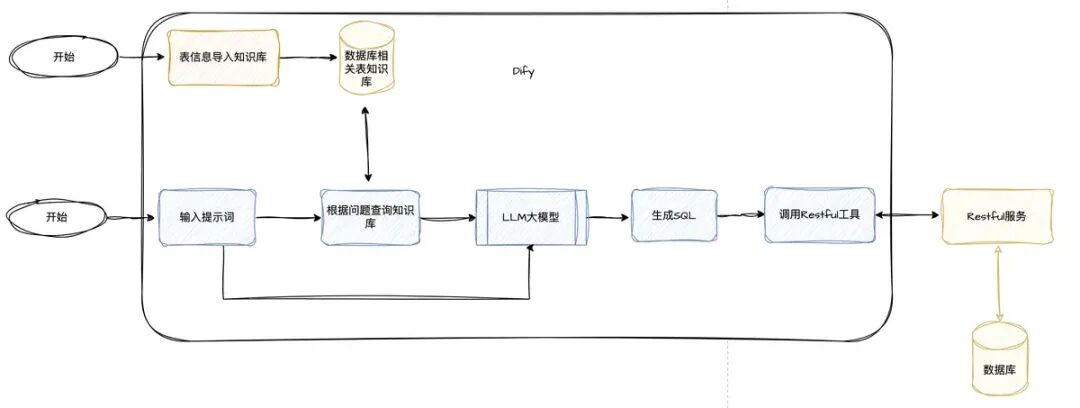
3.2.2.1 构建后台服务
后台构建一个Restful服务,作用就是收到SQL语句后,执行查询,然后返回结果。 这里面用python实现,代码如下:
from flask import Flask, request, jsonify
from sqlalchemy import create_engine, text
app = Flask(__name__)
# 配置数据库连接,替换为你的实际数据库信息
DATABASE_URI = 'mysql+pymysql://test:123456@192.168.0.13:3306/test'
engine = create_engine(DATABASE_URI)
@app.route('/query', methods=['POST'])
def query_database():
# 获取请求中的 SQL 语句
sql_query = request.json.get('sql')
if not sql_query:
return jsonify({"error": "SQL query is required"}), 400
try:
# 执行 SQL 查询
with engine.connect() as connection:
result = connection.execute(text(sql_query))
rows = result.fetchall()
# 将结果转换为字典列表
columns = result.keys()
result_dict = [dict(zip(columns, row)) for row in rows]
return jsonify(result_dict)
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
# 以调试模式启动,默认监听 127.0.0.1:5000
app.run(debug=True)启动后,可以通过curl测试下:
curl -X POST http://localhost:2332/query -H "Content-Type: application/json" -d '{"sql": "SELECT * FROM aml_devices LIMIT 1"}'结果如下: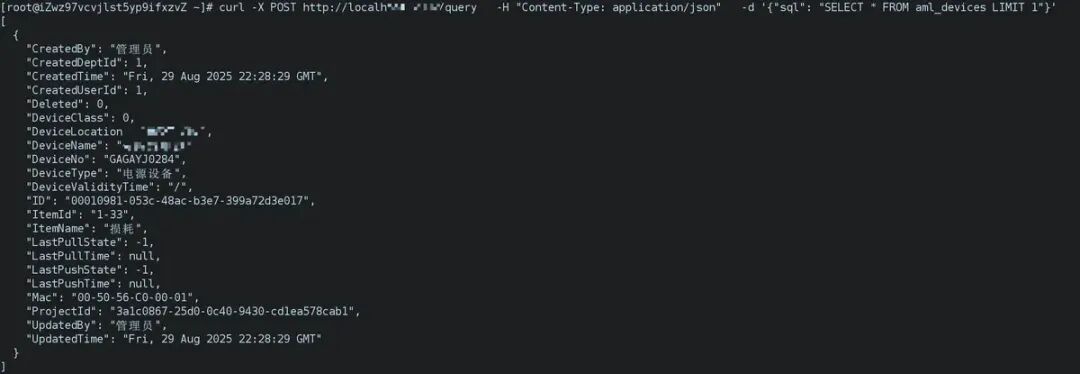
3.2.2.2 新建一个工作流发布为工具
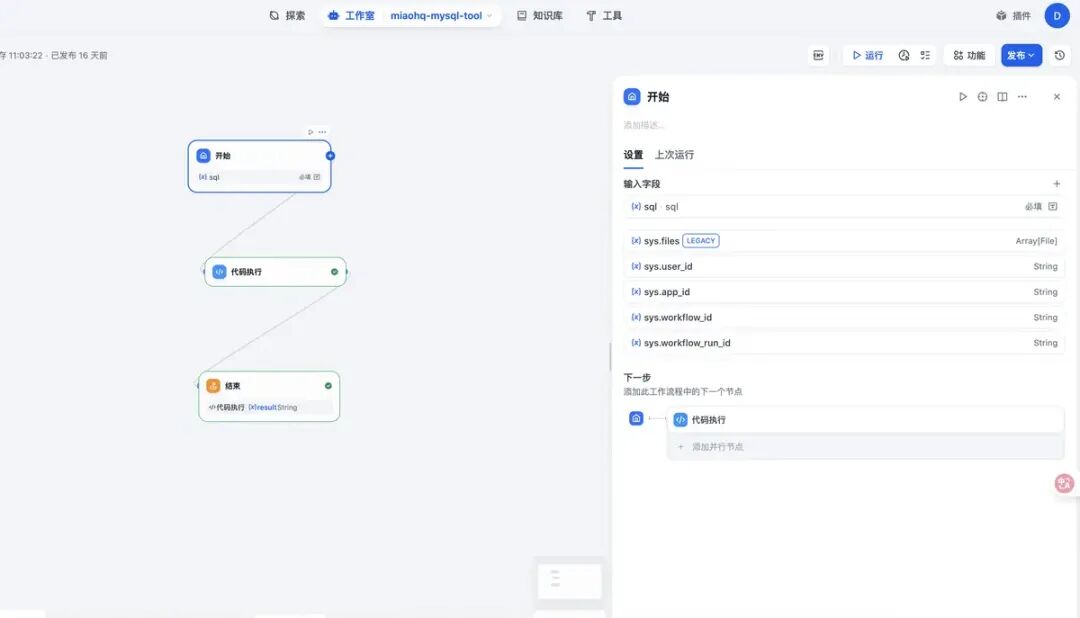
新建这个工作流非常简单,只有一个核心的代码执行节点,这里面即是Restful接口的客户端,通过这个客户端,将sql发送到上面的执行sql的服务上面去:
-
开始节点定义一个sql 字符串类型,表示输入的sql信息;
-
添加代码执行节点,如下图:
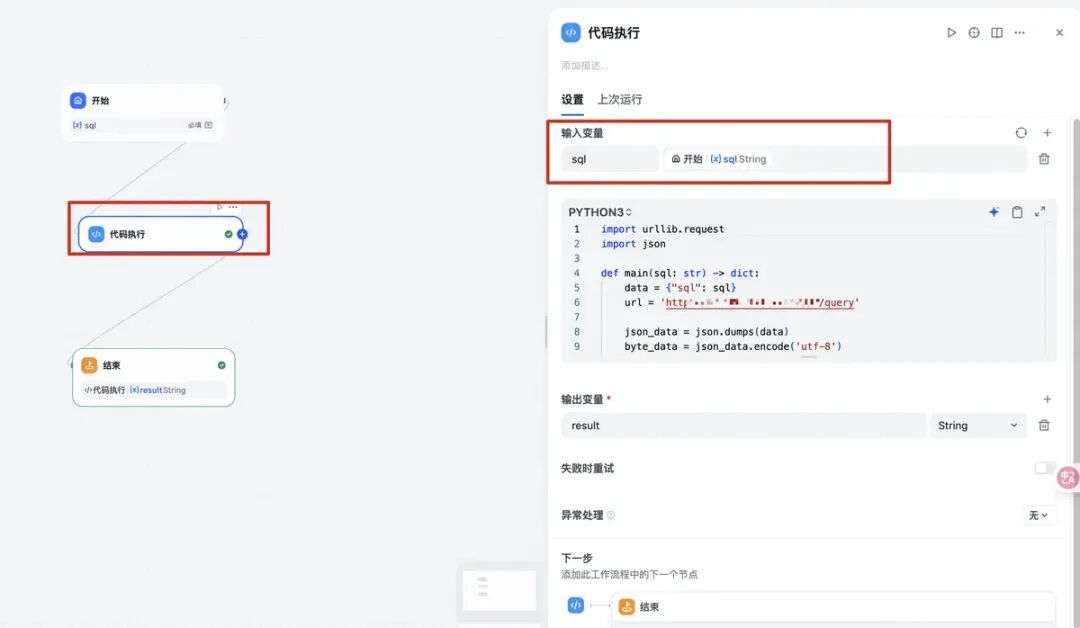 python客户端代码如下:
python客户端代码如下:
import urllib.request
import json
def main(sql: str) -> dict:
data = {"sql": sql}
url = 'http://xx.xx.xx.xx:2332/query'
json_data = json.dumps(data)
byte_data = json_data.encode('utf-8')
req = urllib.request.Request(url, data=byte_data, headers={'Content-Type': 'application/json'})
response = urllib.request.urlopen(req)
response_data = response.read().decode('utf-8')
return {
"result": response_data
}执行下看看效果: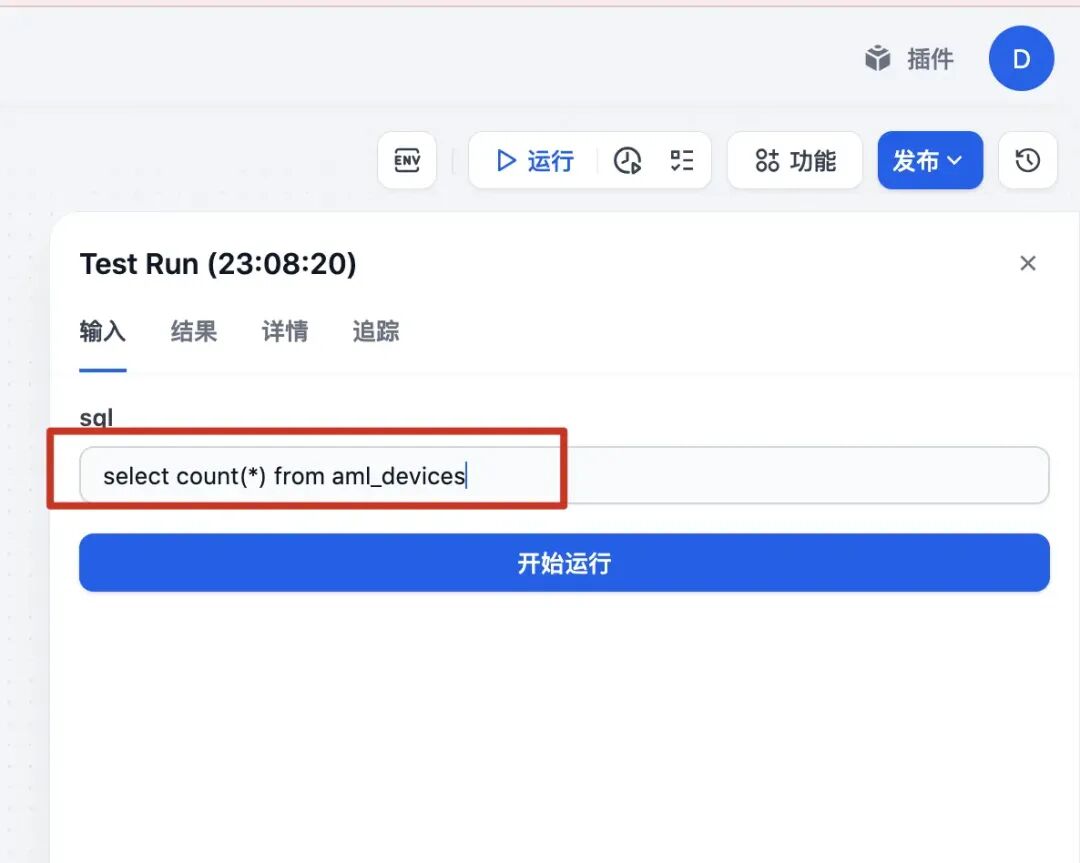 结果:
结果: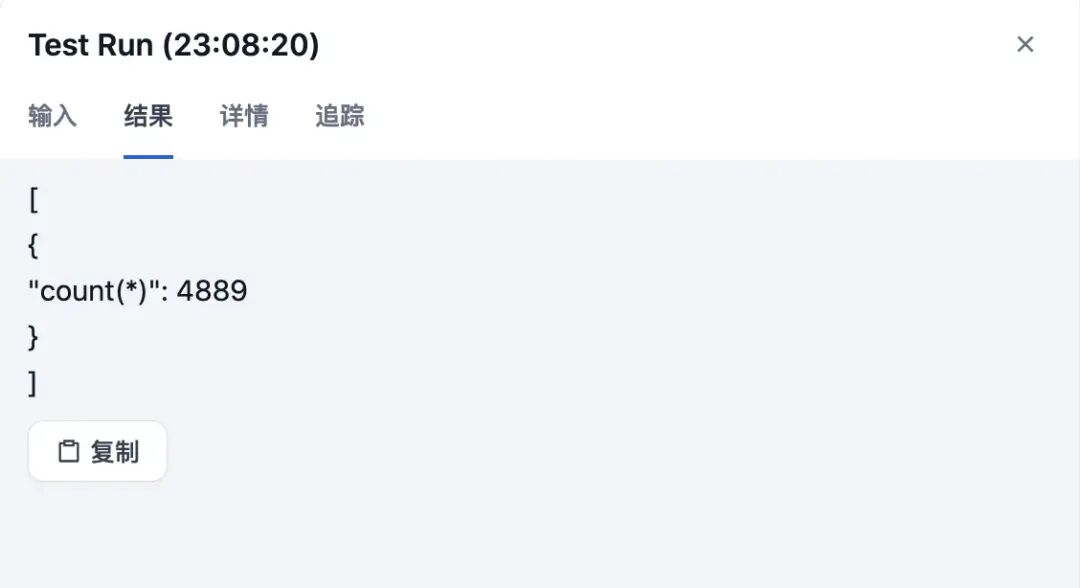
然后点击右上角,发布为工具,如下图: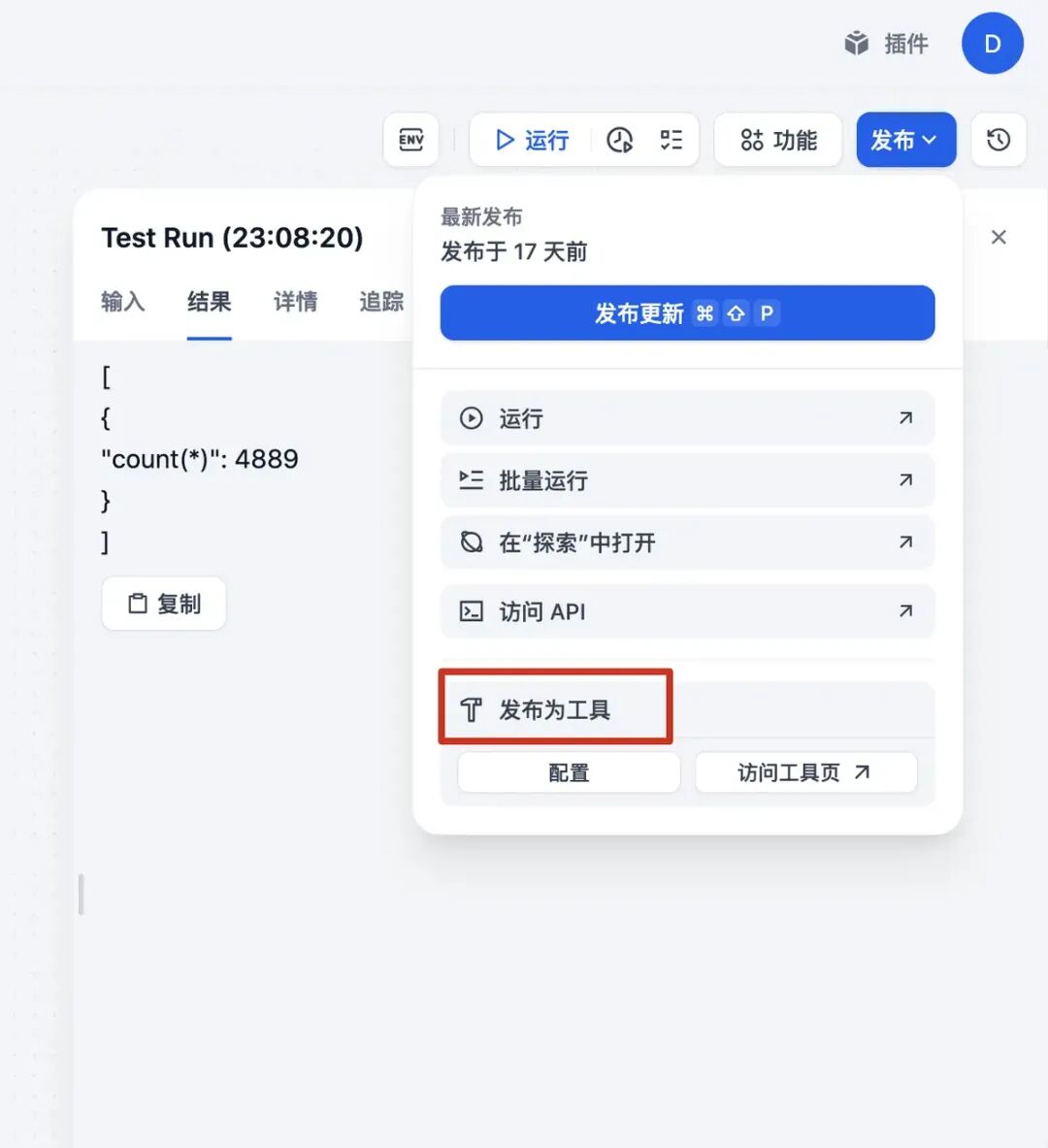
3.2.2.3 新建知识库
知识库是为了让大模型有更多的表信息,从而为生成SQL做准备,新建知识库,上传txt格式文件。 txt文档内容大概如下,用三个井号分隔每个表,对表名和字段信息进行介绍;
### `aml_devices` 表
表结构描述:
表名称:`aml_devices` 设备信息表
字段列表:
`ID`,主键,字符串(长度40)
`CreatedBy`,创建人,字符串(长度90)
`CreatedTime`,创建时间,日期时间类型
`UpdatedBy`,更新人,字符串(长度90)
`UpdatedTime`,更新时间,日期时间类型
`CreatedUserId`,创建人用户ID,整型(默认值-1)
`CreatedDeptId`,创建人部门ID,整型(默认值-1)
`Mac`,MAC地址;操作人的MAC地址,字符串(长度90)
`Deleted`,是否删除;0:未删除1:删除,整型(默认值0)
`DeviceName`,设备名,字符串(长度255)
`DeviceNo`,设备编号,字符串(长度255)
`DeviceType`,设备型号;设备型号,字符串(长度255)
`DeviceClass`,设备类别:0:普通;1:电磁设备,整型
`DeviceValidityTime`,设备有效期;精确到天,字符串(长度32)
`DeviceLocation`,存放位置,字符串(长度128)
`ProjectId`,项目ID;关联到项目ID 为了便于查询冗余,字符串(长度40)
索引:
主键:`ID`
存储引擎:`InnoDB`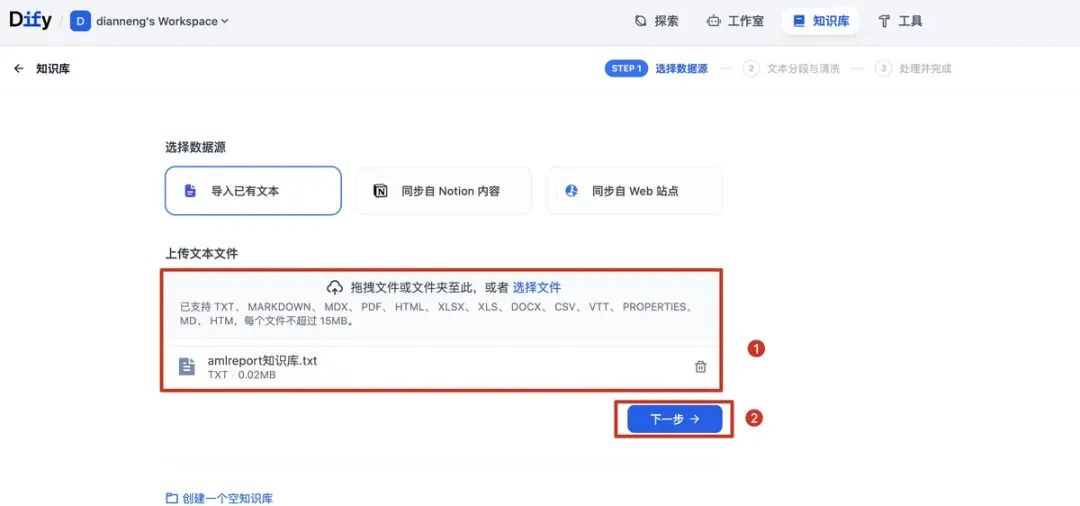
设置好分隔符,然后选择嵌入模型,用于知识库的数据分片处理,生成嵌入向量保存到库中,如下图: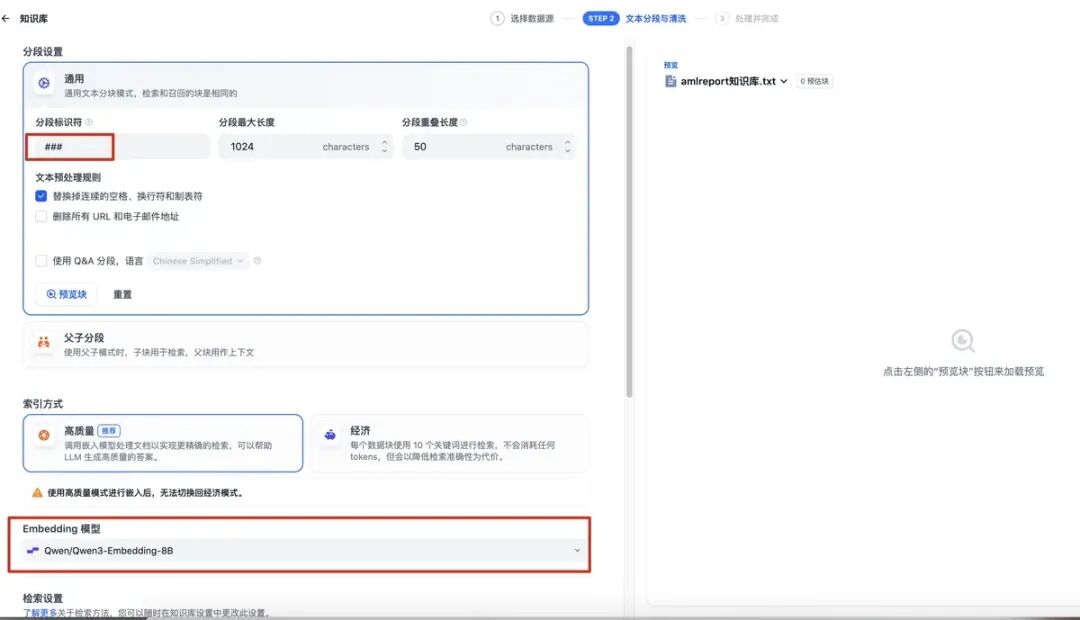 处理完成后,就可以进入下一步了:
处理完成后,就可以进入下一步了: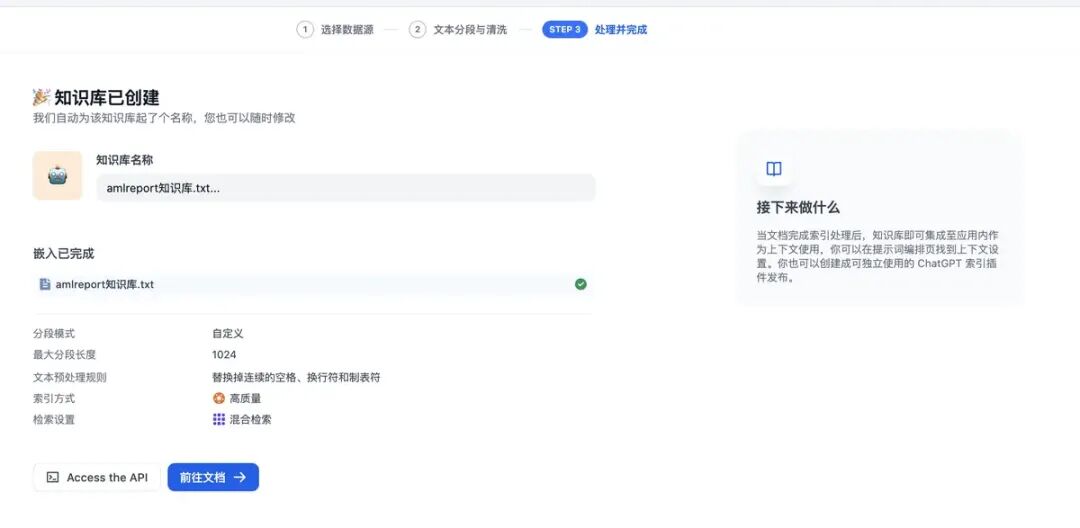
为了验证知识库的效果,我们可以进行召回测试: 知识库可以设置检索的方式是向量检索、还是全文检索还是混合检索,还可以选择召回的chunk数量。效果如下:
知识库可以设置检索的方式是向量检索、还是全文检索还是混合检索,还可以选择召回的chunk数量。效果如下: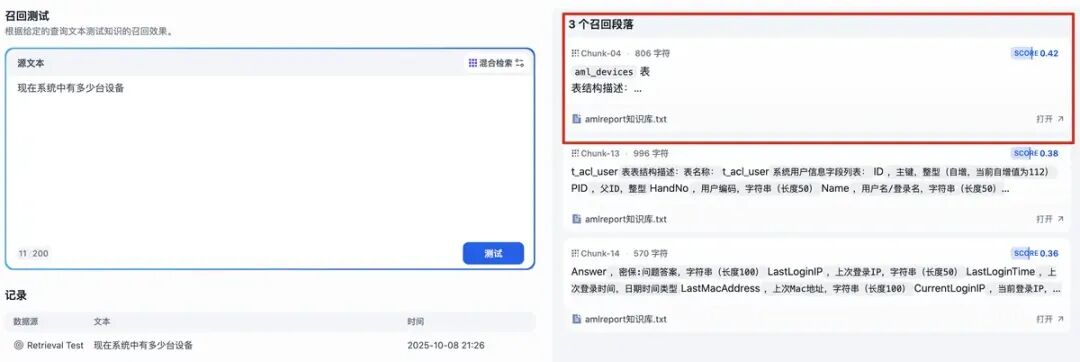
3.2.2.4 新建Agent应用
本来是新建工作流应用的,发现工作流应用里面,将知识库查询放在前面通过问题搜索知识库然后给大模型的方式效果很差,所以采用新建Agent应用方式,如下图:
-
首先是写大模型的提示词,提示词非常关键,如何写那,可以通过AI写,我是将知识库的数据传给豆包,然后说下自己的要求,具体的生成提示词的提示词信息:)如下:
这是我数据库的描述信息,根据这个信息,写提示词,这个提示词给大模型用,用于将用户的问题,转成纯的Mysql语法的SQL,不要其他信息,SQL语句的生成参考我给的附件,文件中三个井号分隔的为每个表,需要根据问题提取表信息,根据表信息和字段信息生成符合Mysql语法的SQL-
知识库的选择 这个就选择我们上面定义的知识库即可;
-
自定义工具选择 选择我们自定义flow流发布的工具,这里面有个注意点就是自定义flow流里面的sql 这个字符串类型一定要设置大一些,默认48太小了,这里设置为256.
-
Agent新建注意事项 这里面有个需要特别注意的,就是Agent新建或更新后,及时点发布更新,不然不会保存的。
新建好的智能体如下: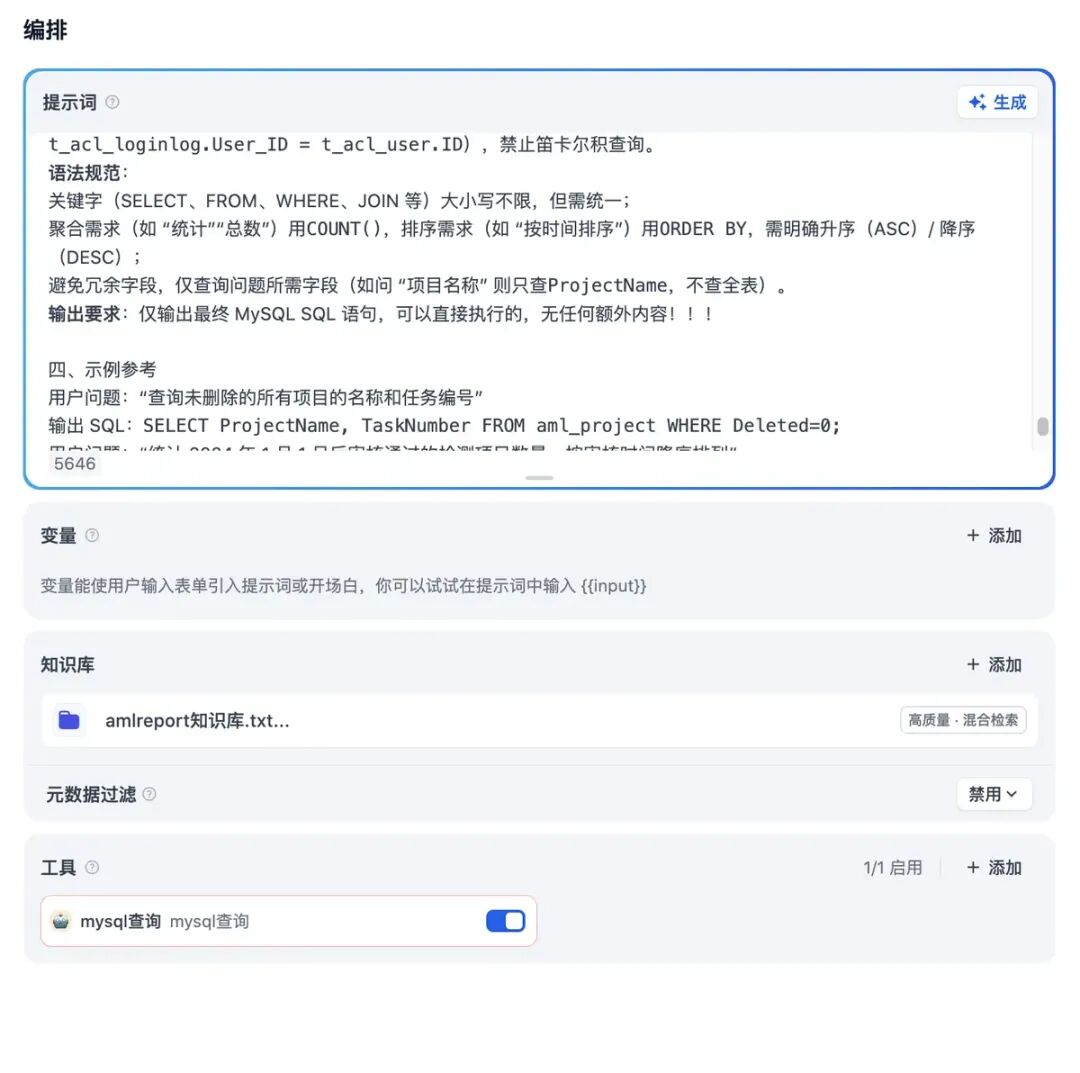
测试了下,倒是生成的SQL但是没有执行: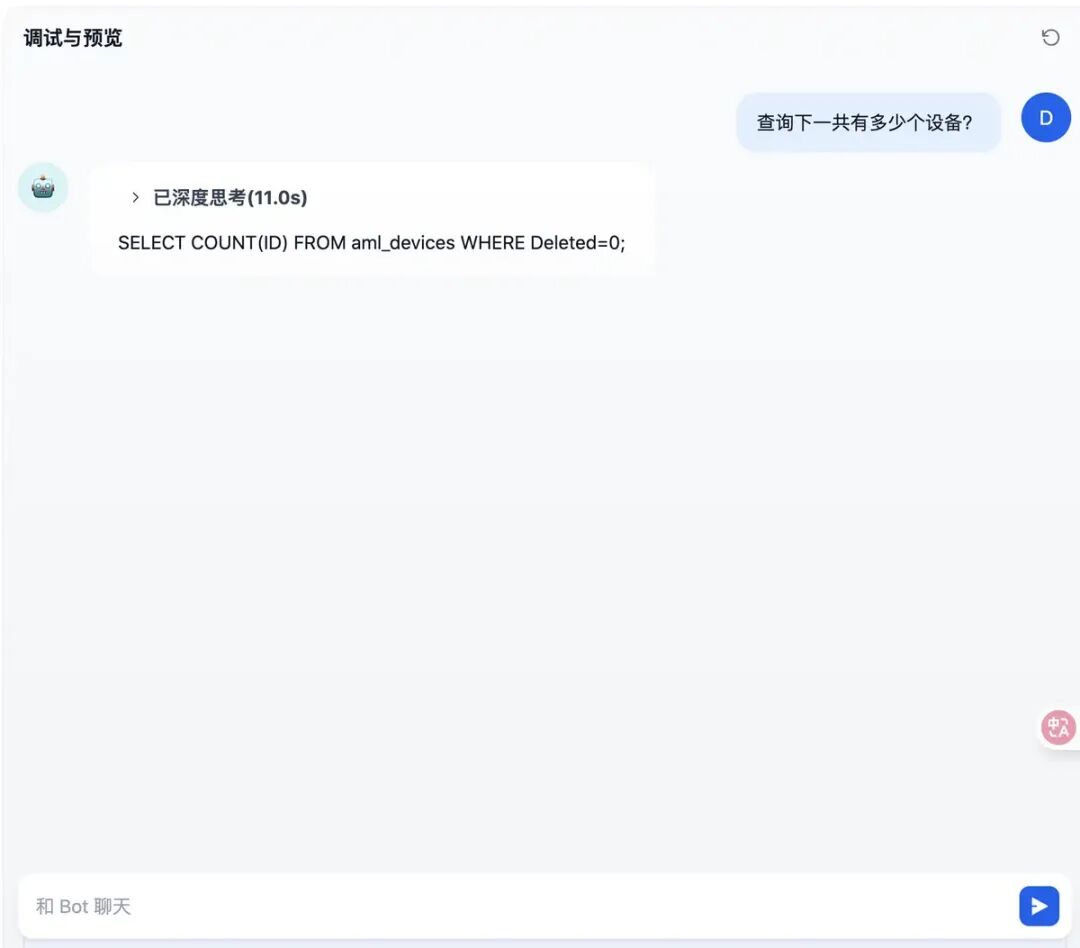
重新换个大模型,测试下效果如下: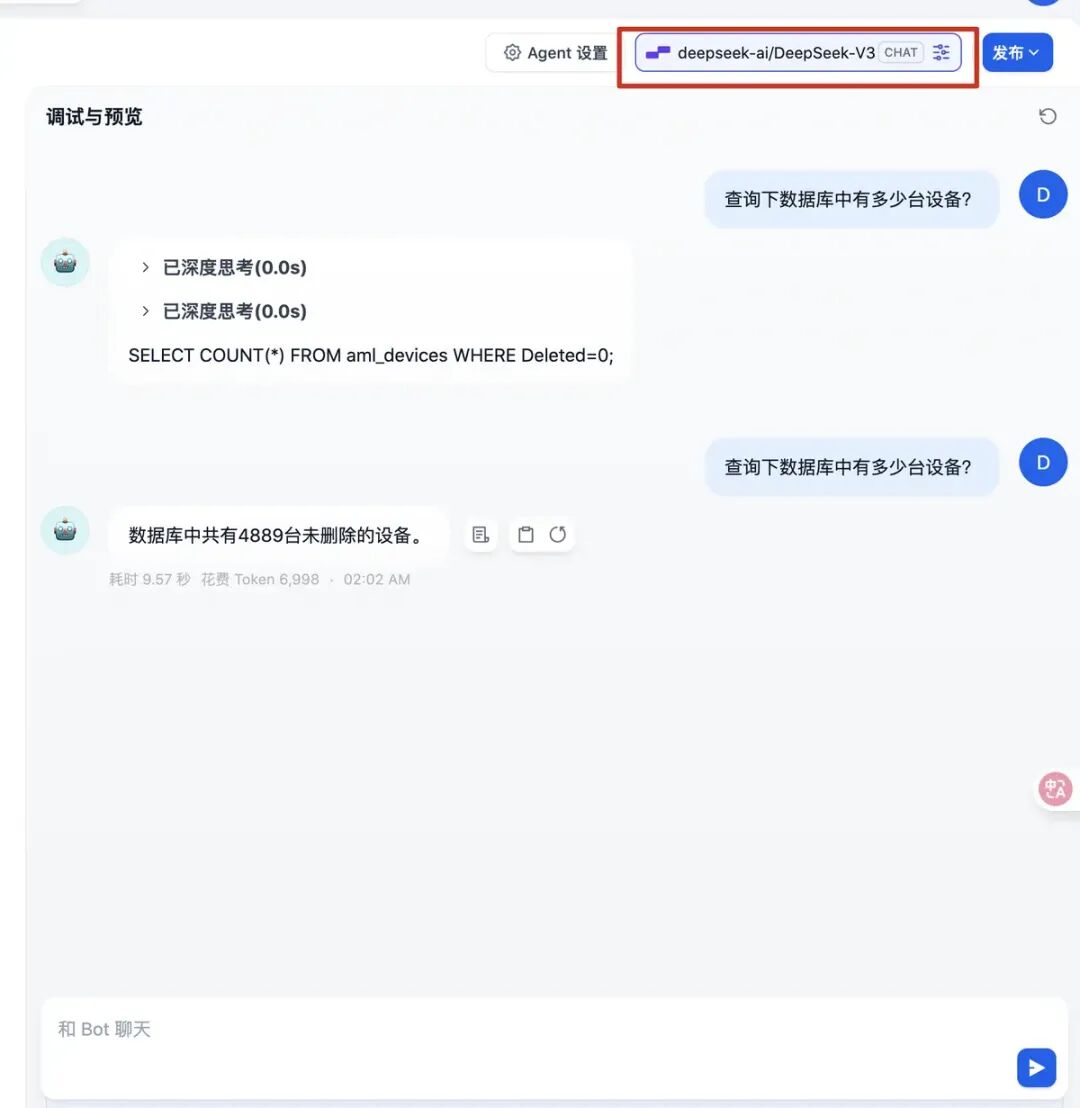
四 其他技巧
-
新建应用的时候,除了几种应用类型外,还可以通过模版创建新应用,简化操作
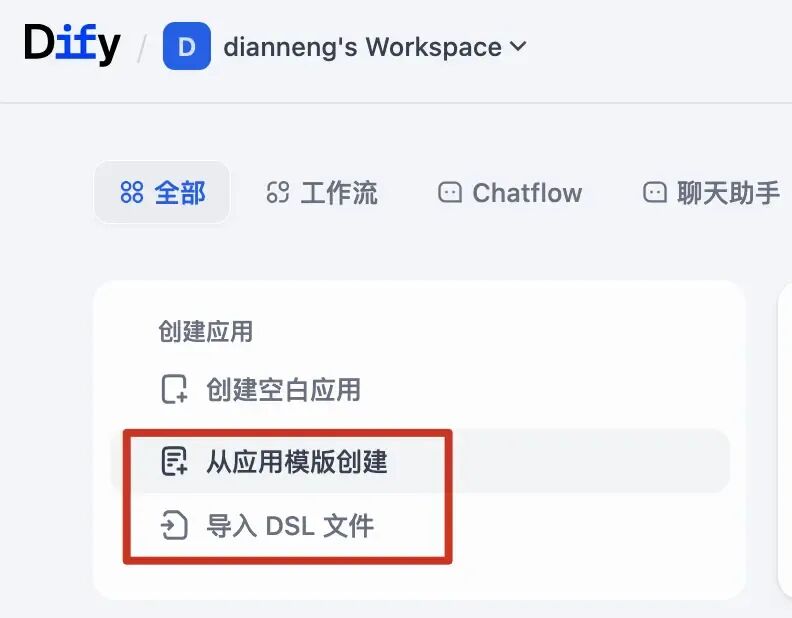
-
应用可以方便导出为DSL文件,也可以将DSL文件导入到Dify中还原成应用; 目前上面的两个应用非常简单,github上有很多开源的Dify搭建的应用,大家可以通过下载DSL文件,然后导入的方式,导入相关应用,跟着学习; 推荐三个地址:
https://github.com/wwwzhouhui/dify-for-dsl
https://github.com/BannyLon/DifyAIA
https://github.com/svcvit/Awesome-Dify-Workflow比如如下图的应用: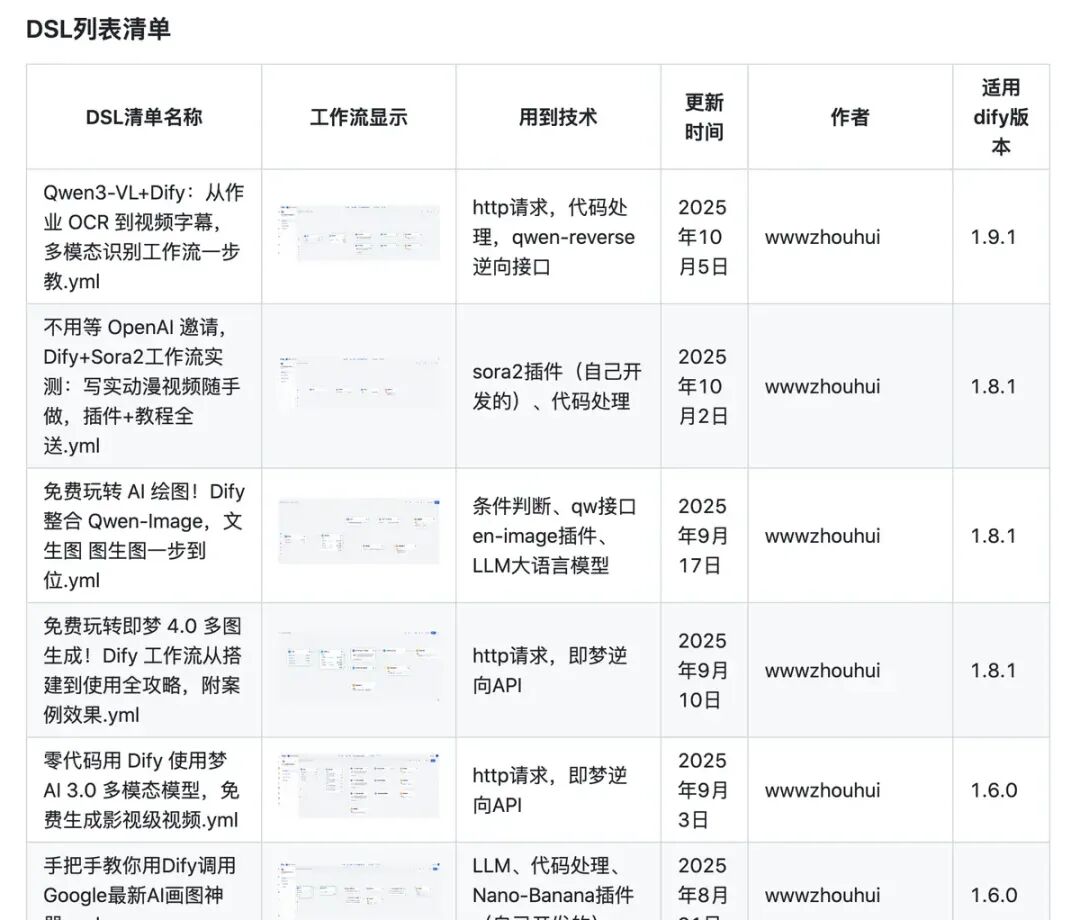
-
初次安装运行Dify后,需要等一会,CPU有一段时间会达到100%。
五 参考
https://www.bilibili.com/video/BV16hhJzQE9b/?spm_id_from=333.1387.favlist.content.click&vd_source=4c7bc398c13eb9f63d6d244194608f0e
https://www.bilibili.com/video/BV1FFh2zZEJ8/?spm_id_from=333.337.search-card.all.click&vd_source=4c7bc398c13eb9f63d6d244194608f0e
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)