LangSmith—AI应用性能评估快速上手
本文介绍了使用LangSmith工具评估AI应用性能的方法。主要内容包括:1)评估三要素:数据集(含输入和预期输出)、目标函数(被评估的AI组件)和评估器(对输出进行语义评分);2)实践步骤:设置环境变量,构建RAG智能体(含PDF加载、文本分割、向量存储和检索工具),创建5个测试用例的数据集,使用Deepseek模型实现语义评估器,定义目标函数调用智能体;3)执行评估并查看结果。该方法通过结构化
1.概述
性能评估用户定量衡量智能应用的性能。因为大模型的行为是不可预测的,对于提示词的微小修改,对于不同的大模型及同一个大模型的不同配置,对于输入微小不同输出的结果很可能大相径庭。LangSmith支持对智能应用进行结构化的评估,从而识别问题并指导优化,从而构建更可靠的AI应用。
使用LangSmith对AI应用进行评估时需要三个组件:
1)评估数据集。包括输入及预期输出。对应于单元测试中的用例。
2)目标函数:AI应用中被评估的部分,可以是大模型调用,也可以是工作流,也可以是智能体,还可以是深度智能体。对应与单元测试中的测试函数
3)评估器:对于目标函数的输出进行评价打分。对应于单元测试中的assert*。
2.性能评估
2.1设置环境变量
import os
os.environ['LANGSMITH_API_KEY'] = 'lsv2_sk_*'
os.environ['LANGSMITH_WORKSPACE_ID'] = '6a784490-13b5-4bf6-ab4e-d6796476dbea'
2.2被评估应用
以下对一个简单的RAG智能体进行评估,直接把应用代码贴到这里:
from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain.tools import tool
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
loader = PyPDFLoader ("../data/beijing_annual_report_2024.pdf")
docs = loader.load()character_splitter = RecursiveCharacterTextSplitter(
#separators=["\n\n", "\n", ". ", " ", ""],英文文档的分割符示例
separators=["\n\n", "\n", "。", ",", "、", ";", ""],
chunk_size=1000,
chunk_overlap=0)
splits = character_splitter.split_documents(docs)embedding = HuggingFaceEmbeddings(
model_name='../models/text2vec-base-chinese' # 高效的语义模型
)
persist_directory = "../data/chroma2"
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
@tool
def retrieve(query: str):
"""Retrieve information to help answer a query."""
retrieved_docs = vectordb.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docsllm = ChatOpenAI(
model = 'qwen-plus',
api_key = "sk-*",
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1")from langchain.agents import create_agent
agent = create_agent(
model=llm,
tools=[retrieve,]
)
2.3评估数据集
创建评估数据集思路与单元测试完全相同,以下代码创建了一个包括5个用例的测试数据集:
from langsmith import Client
client = Client()
#创建数据集
dataset = client.create_dataset(#指定数据集的名字,后面评估时要使用
dataset_name="20th-dataset", description="A sample dataset in LangSmith."
)
examples = [#测试数据
{
"inputs": {"question": "简单总结一下北京市政府工作报告中关于城市发展有哪些规划?"},
"outputs": {"answer": "北京市……成第三届“一带一路”国际合作高峰论坛服务保障。"},
},
{
"inputs": {"question": "北京市政府工作报告中关于保障就业有哪些举措?"},
"outputs": {"answer": "北京市政府工作……万人."},
},
{
"inputs": {"question": "简述一下将如何推动京津冀协同发展,不要超过200字"},
"outputs": {"answer": "推动京津冀协……和协同配套"}
},
{
"inputs": {"question": "如何提升公共服务水平?,不要超过200字"},
"outputs": {"answer": "提升公共服务水……度"}
},
{
"inputs": {"question": "如何节能减排,不要超过200字"},
"outputs": {"answer": "提升公共服务……意度"}
},
]#在数据集中加载测试数据
client.create_examples(dataset_id=dataset.id, examples=examples)
2.4评估器
联想一下传统应用的单元测试,总是把实际结果与预期结果进行比对,相同则用例通过,否则用例失败。 因为大模型输出的不确定性,所以AI应用中进行评估时并非把预期结果和实际结果进行相等比较,而是进行语义比较,如果二者语义一致则测试通过,否则测试不通过。一般执行评估时使用与执行实际任务的不同的大模型(我们这里采用了deepseek作为评估模型)。
如下代码实现了一个评估器:
deepseek = ChatOpenAI(
model='deepseek-chat',
base_url='https://api.deepseek.com',
api_key='sk-*')#reference_outputs对应预期结果,outputs对应实际执行结果
def valid_answer(reference_outputs: dict, outputs: dict) -> bool:
"""Use an LLM to judge if the answer for the question is correct."""
instructions = """
Given the following answer and reference_outputs, determine if the answer
for the question and the reference_output is consistant.
return correct if consistant, else return incorrect
"""
msg = f"Answer: {outputs['answer']}\nReference_output: {reference_outputs['answer']}"response = deepseek.invoke(
[
{"role": "system", "content": instructions,},
{"role": "user", "content": msg}
],
)
return response.content == 'correct'
2.5目标函数
目标函数目的是驱动被测对象,这里就是调用RAG智能体,并返回执行结果,具体实现如下:
def target(inputs: dict) -> dict:
result = agent.invoke(
{
"messages":[
{"role": "system", "content": "Answer the following question accurately"},
{"role": "user", "content": inputs["question"]},
]
}
)
return {"answer": result["messages"][-1].content}
2.6执行评估
万事俱别,下面直接运行评估:
experiment_results = client.evaluate(
target,#目标函数
data="20th-dataset", #数据集
evaluators=[valid_answer], #评估器
experiment_prefix="my-experiment", #评估前缀
)
2.7查看结果
用你的LangSmith登录,定位到测试结果集:
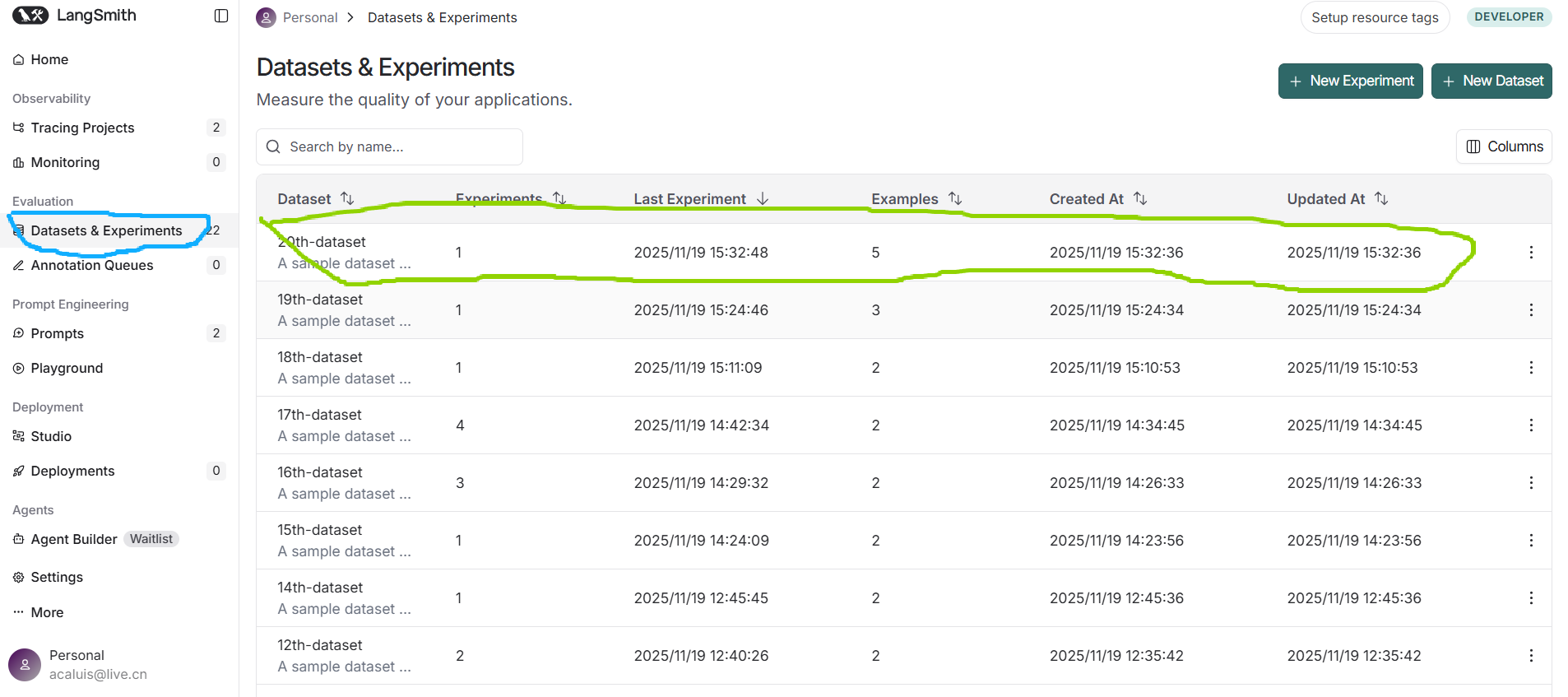
查看测试结果:
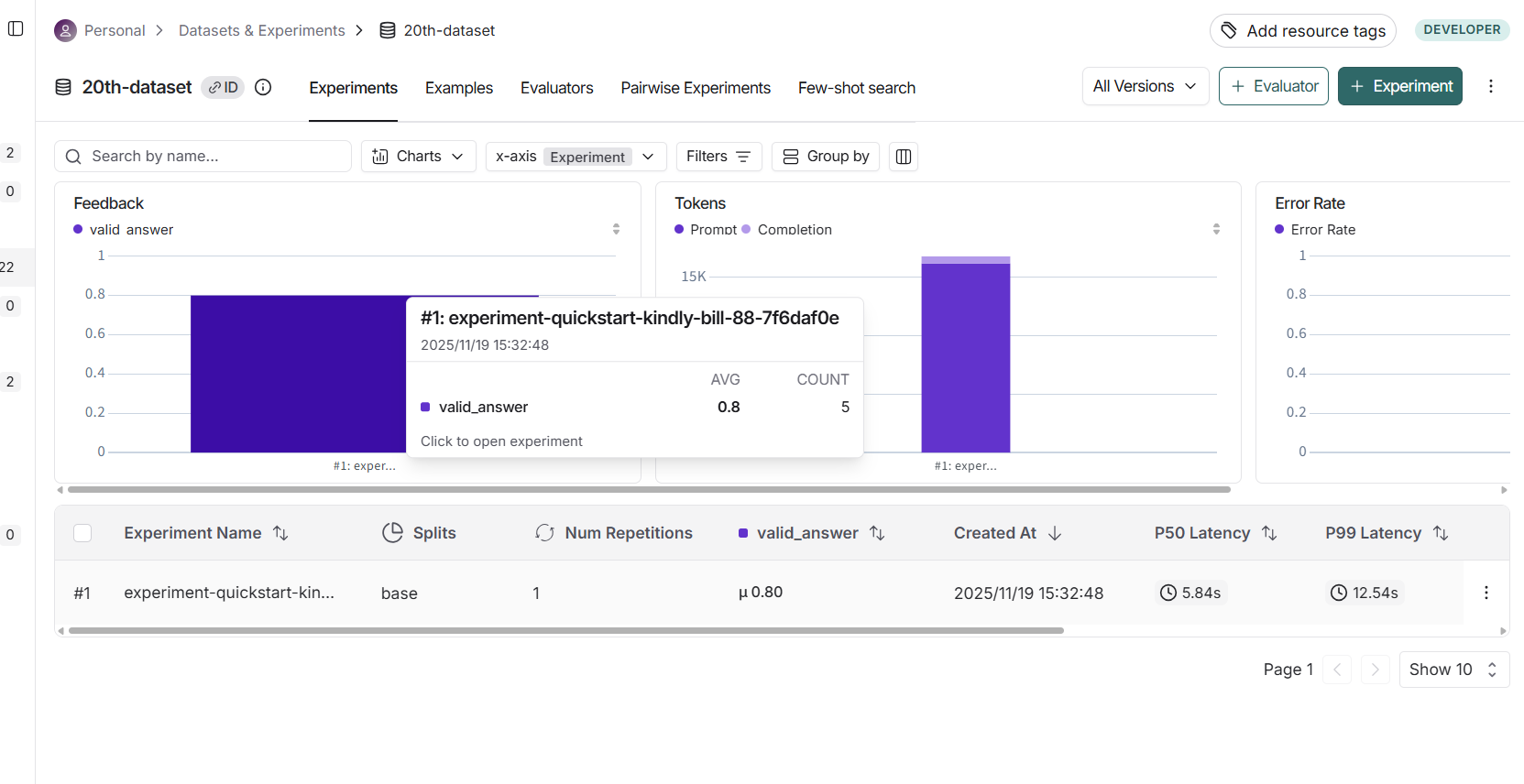
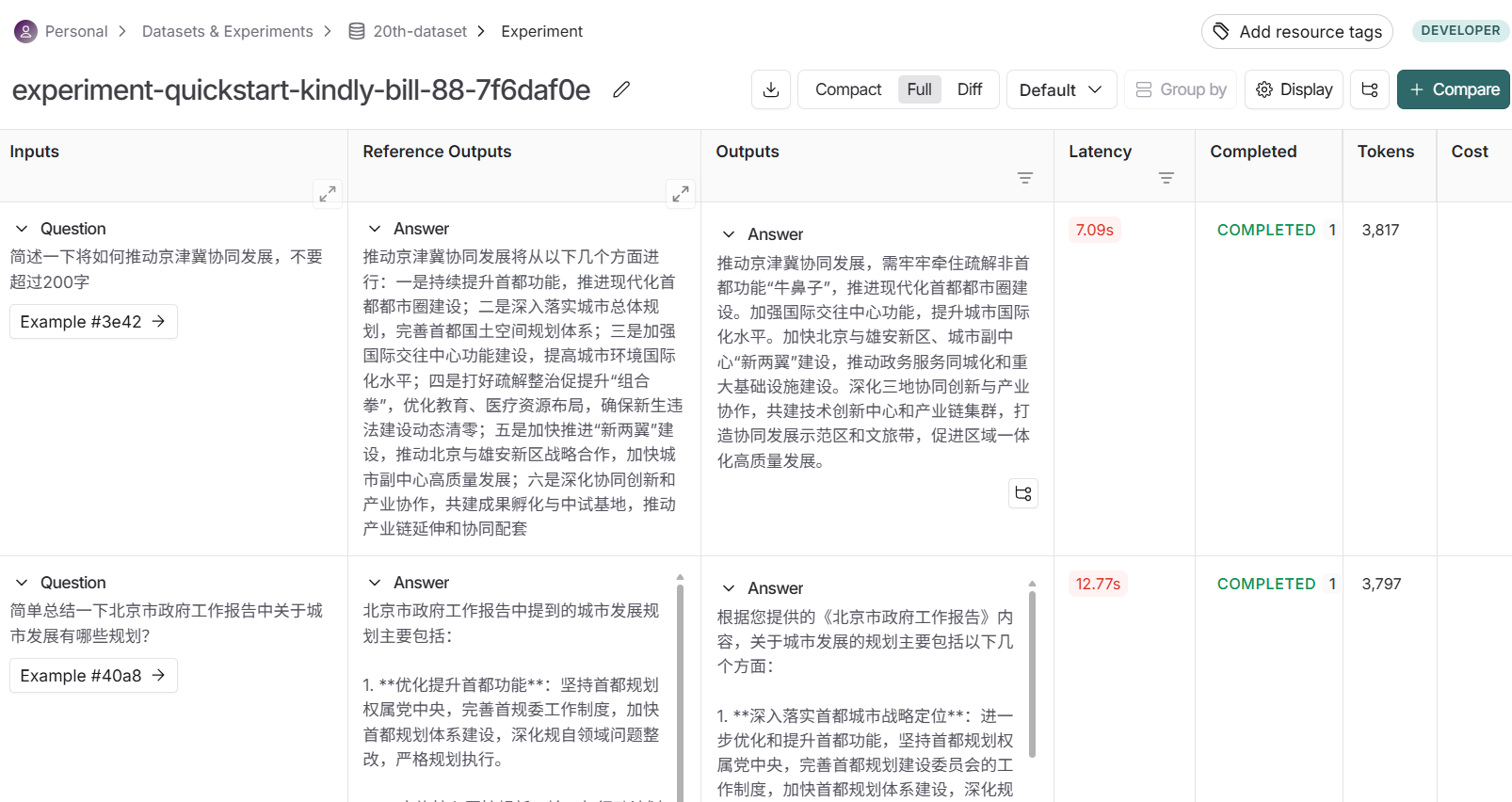
查看测试结果详细信息:
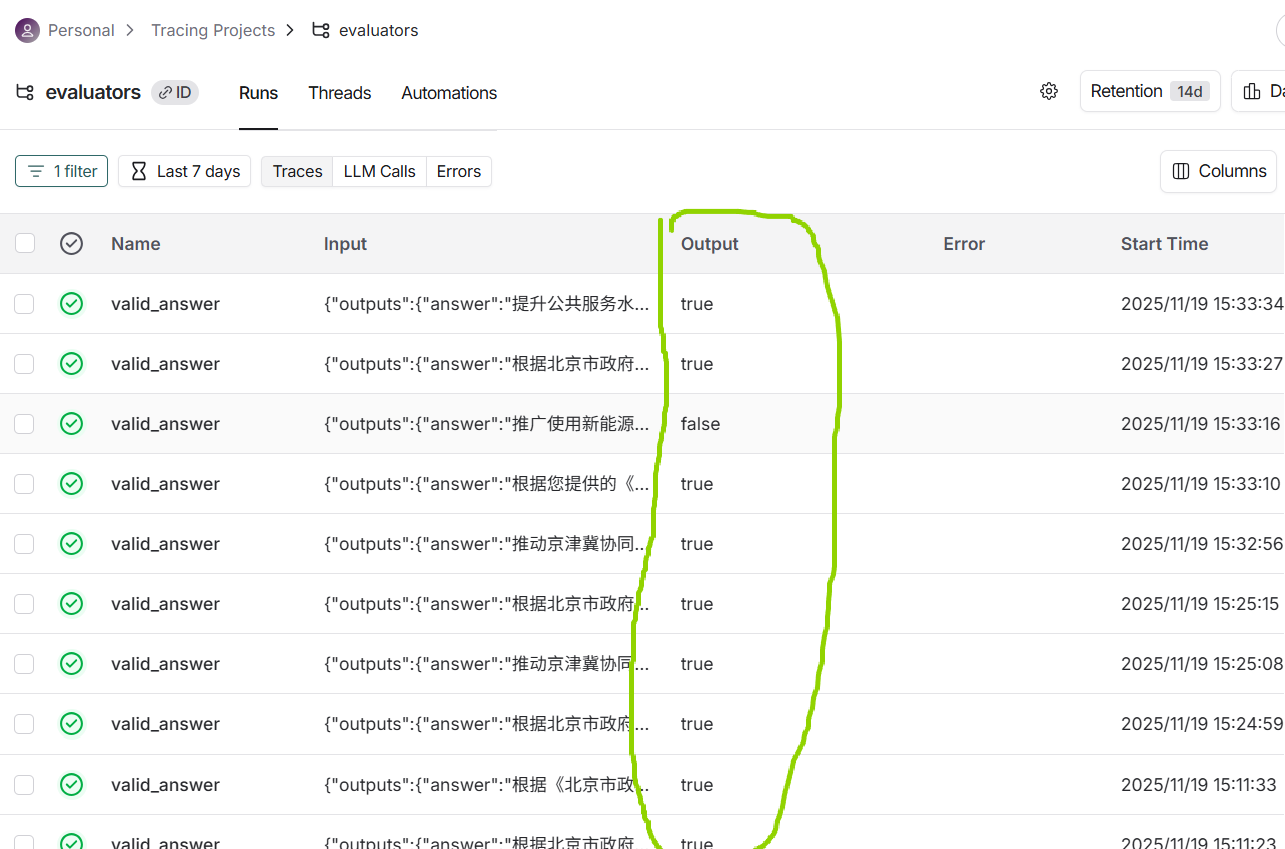
查看针对每条测试数据的运行结果:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)