LLM应用开发学习路线:快速入门路线与教程汇总
本文分享LLM应用开发的学习路线与资源汇总,包含Python基础、LLM核心技术(RAG/Agent)的进阶路径。作者在GitHub开源了系统化学习资料库(https://github.com/tataCrayon/LLM-DEV-COOKBOOK),提供从入门到实践的完整教程与代码Demo。内容涵盖核心知识图谱、学习框架图及分阶段教程索引,适合开发者快速掌握大语言模型应用开发的关键技能。欢迎交流
欢迎来到啾啾的博客🐱。
记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。
有很多很多不足的地方,欢迎评论交流,感谢您的阅读和评论😄。
引言
本篇分享一下LLM应用开发的快速入门学习路线+教程汇总+代码demo。
详细内容在个人仓库:
https://github.com/tataCrayon/LLM-DEV-COOKBOOK
1 先快速入门
快速了解RAG与Agent。了解LangChain4j。做一个简单的Demo。
这里放上自己的学习路线与联系代码以供参考,个人仓库:
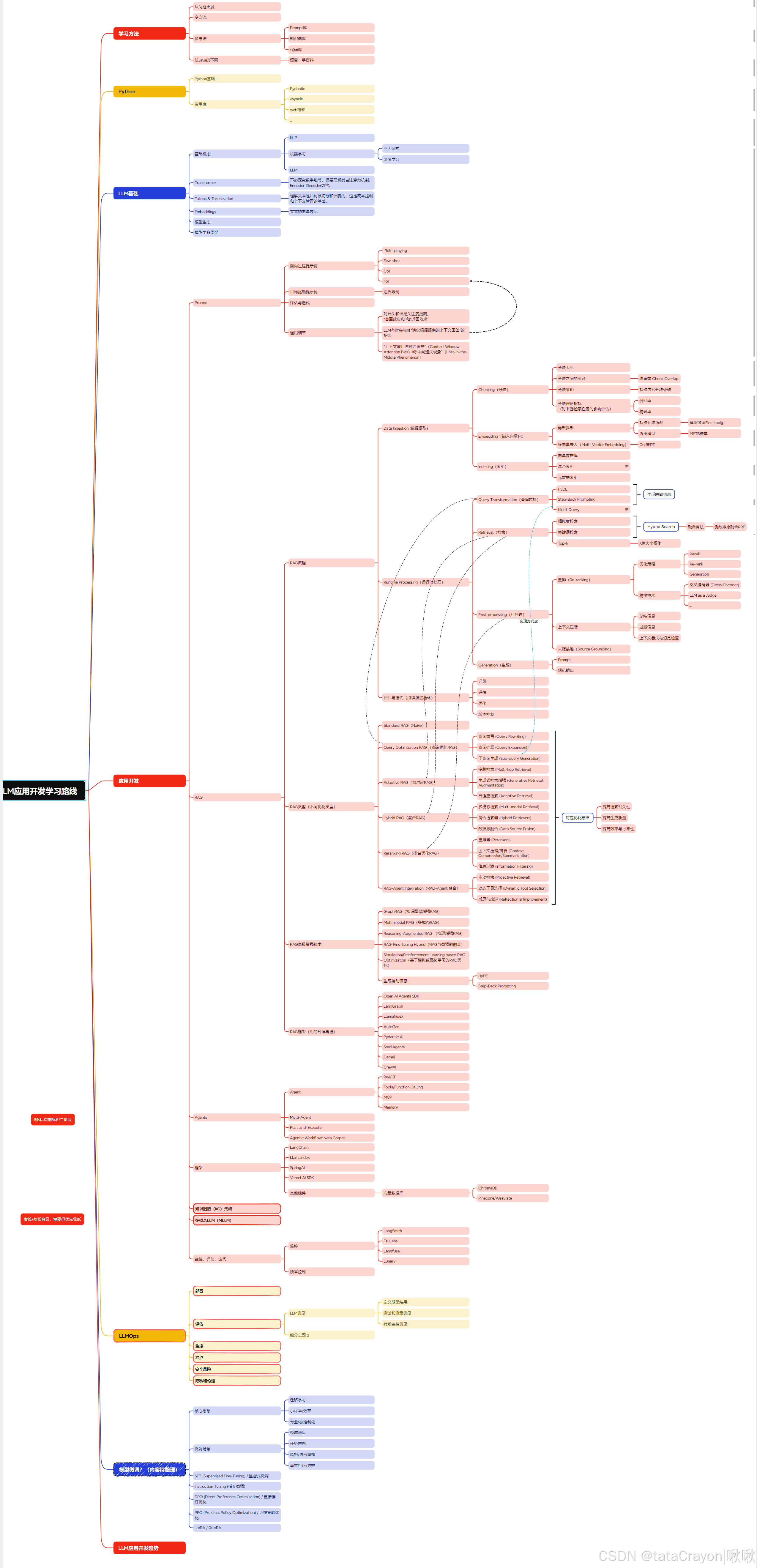
2 对学习能力的要求
LLM的知识更新的很快,今天掌握的技能可能明天就需要被完善或增强。
因此,一个学习计划不能是一个静态的文档,而必须融入持续评估、调整和持续学习的机制。
学习者必须培养一种终身学习的心态,并随着新范式的出现而不断拥抱它们。
一些学习方法:
- 借鉴别人的学习路线与笔记,结合书籍,多看优秀的Github项目。
- 将自己学习、整理的思路形成Prompt,以让大模型辅助回答整理格式。
- 问题主导。学完后找一些常见QA回答,学的时候也带着问题去学。
- 知识面有广度后,阅读源码,尝试手搓代码。
- 简化主干,尝试一句话总结复杂描述。
- 定期计划梳理,之前多个事项长期并行有点累了。
- 学习完一阶段的知识后,可以去看一下面试题做补充。
- 得看论文,研究第一手资料。(论文和书籍不一样,有另外的阅读方法)
- 持续评估迭代自己,适应性学习。
2.1 按照评估制定计划
首先,我们需要一个目标,以及评估自身的能力情况。
基于目标我们需要拆解、制定一个学习计划。
以下表格提供了一个结构化的框架,供学习者进行自我评估,将“技能差距识别”这一抽象概念具体化、可操作化:
AI生成,目标不同还需自行调整。
表1:LLM技能差距评估关键领域
| 技能类别 | 具体技能/概念 | 当前熟练度 (1-5) | 期望熟练度 (1-5) | 识别差距 | 优先级 (高/中/低) | 备注/理由 |
|---|---|---|---|---|---|---|
| 数学基础 | 线性代数、微积分、概率论、统计学 | |||||
| NLP核心与LLM协同 | 分词、语义分析、Transformer模型、Hugging Face | |||||
| 模型优化 | 微调(LoRA, QLoRA)、量化、模型蒸馏 | |||||
| 高级应用设计模式 | 提示工程(CoT, ToT)、RAG、自主AI代理 | |||||
| 数据策略 | 数据清洗、去重、合成数据生成 | |||||
| LLMOps | 部署(Docker, Kubernetes, vLLM)、评估、监控、负责任AI | |||||
| 多模态与知识图谱 | 多模态LLM架构、知识图谱集成、GraphRAG | |||||
| 异步编程 | asyncio、并发操作、错误处理 |
熟练度评分:1=新手,2=初级,3=中级,4=高级,5=专家
2.2 寻求反馈
可以通过八股测试、社区沟通、请教大佬等方式,总结或寻求建设性意见。
争取360°的全面视角。
3. 教程汇总(系统学习)


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 36
36 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)