VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model 论文解读
该论文介绍了一种新的高质量多视图一致的图像生成方法VideoMV,从现有的视频生成模型中进行微调,来用于多视图的合成。提到预训练的数据和模型决定了学习的特征类型,底层的三维模型决定了是否多视图一致。提出了一种新颖的3D-aware的去噪策略(基于视频的多视图生成的前馈模型),进一步提高生成图像的多视图一致性。实验结果表明,VideoMV在效率和质量上显著优于现有多视图合成方法(MVDream)。
目录
一、概述
该论文介绍了一种新的高质量多视图一致的图像生成方法VideoMV,从现有的视频生成模型中进行微调,来用于多视图的合成。提到预训练的数据和模型决定了学习的特征类型,底层的三维模型决定了是否多视图一致。
提出了一种新颖的3D-aware的去噪策略(基于视频的多视图生成的前馈模型),进一步提高生成图像的多视图一致性。
实验结果表明,VideoMV在效率和质量上显著优于现有多视图合成方法(MVDream)。
二、相关工作
1、基于蒸馏的生成
基于蒸馏的生成最早由DreamFusion(用了SDS)提出,通过从预训练的2D图像生成模型中蒸馏来生成3D模型,无需使用任何3D数据。
Fantasia3D进一步将优化过程分为几何和外观两个阶段。Magic3D采用粗到细的策略进行高分辨率3D生成。ProlificDreamer提出了变分得分蒸馏(VSD),将3D参数建模为随机变量而不是常量。
CSD将多个样本视为粒子进行更新,同步蒸馏生成先验。NFSD提出了一种可以在标称CFG尺度下蒸馏形状的解释,使生成的数据更加真实。SteinDreamer降低了得分蒸馏过程中的方差。LucidDreamer提出了区间得分匹配来抑制过度平滑。
HiFA和DreamTime优化了蒸馏公式。RichDreamer使用多视图法线-深度扩散模型对几何进行建模,使优化更加稳定。RealFusion、Make-it3D、HiFi-123和Magic123使用多模态信息来提高生成保真度。
DreamGaussian和GaussianDreamer使用高效的高斯溅射表示来加速优化过程。
总的来说,基于蒸馏的生成方法需要2D生成器进行数万次迭代,需要数小时才能生成单个资产,效率较低。
2、基于前馈的生成
基于前馈的生成方法尝试直接使用神经网络学习3D分布,通过拟合3D数据来实现3D生成。其中:
OccNet将形状编码到函数空间,从各种输入中推断3D结构。MeshVAE也学习了一个合理的概率潜在空间表示,用于各种应用。
3D-GAN设计了一个体积生成对抗网络,从潜在空间生成形状。随着可微渲染的发展,HoloGAN和BlockGAN以无监督的方式从自然图像中学习3D表示。
为了保持多视图一致性,一些先前的工作在生成对抗网络中引入隐式3D表示进行3D感知生成。GET3D、DG3D和TextField3D利用DMTet进行精确的纹理化形状建模。
随着2D扩散模型的发展,3D扩散模型使用扩散模型变体进行生成式形状建模。Point-E和Shap-E[25]扩展了训练数据集的范围,用于通用物体生成。
LRM、PF-LRM和LGM选择使用确定性方法进行少视图重建。LEAP和FORGE专注于使用少量图像和噪声相机姿态或未知相机姿态生成3D模型。
总的来说,这些基于前馈的方法比基于蒸馏的方法快很多,但生成质量有所限制
3、新视角生成
一些工作将新视角生成与传统的重建过程或快速神经重建网络相结合,用于3D生成。
ViewFormer使用Transformer进行新视角合成。
3DiM是首次使用扩散模型进行姿态可控的视角生成。
Zero123采用了大型预训练的图像生成器(StableDiffusion),在Objaverse上微调后大大提高了可推广性。
SyncDreamer设计了一种新的深度注意力模块,用于生成具有固定姿态的16个一致的视图。
Consistent123结合了2D和3D扩散先验进行3D一致的生成。
Zero123++克服了常见的问题,如纹理退化和几何不一致。
Wonder3D引入了跨域扩散模型。
ImageDream提出了全局控制和局部控制,分别塑造整体物体布局和细化图像细节。
iNVS通过精确的深度扭曲增强了新视角合成管道。
MVDream提出了联合生成4个视图的方法,并在所有视图上使用密集的自注意力。
SPAD进一步通过提出的极线注意力增强了多视图一致性。
总的来说,这些工作在新视角生成方面取得了显著进步,可以为下游任务如密集视图重建和基于蒸馏的3D生成提供一致且细粒度的先验。
三、VideoMV
给定一个文本或单张图像作为提示,VideoMV可以在用户指定的相机姿态下生成一致的多视图图像。
下图为VideoMV的主要框架。
Stage1:微调一个预训练的视频生成模型,用于多视图图像的生成,获得多视图生成模型G。
Stage2:使用一个前馈重建模块,基于G生成的多视图得到显式的全局三维模型,显式模型使用了一个3DGS的变体。
Stage3:介绍了一个3D-Aware去噪采样策略,有效的将全局三维模型渲染的图像插入到去噪循环中,提高多视图一致性。
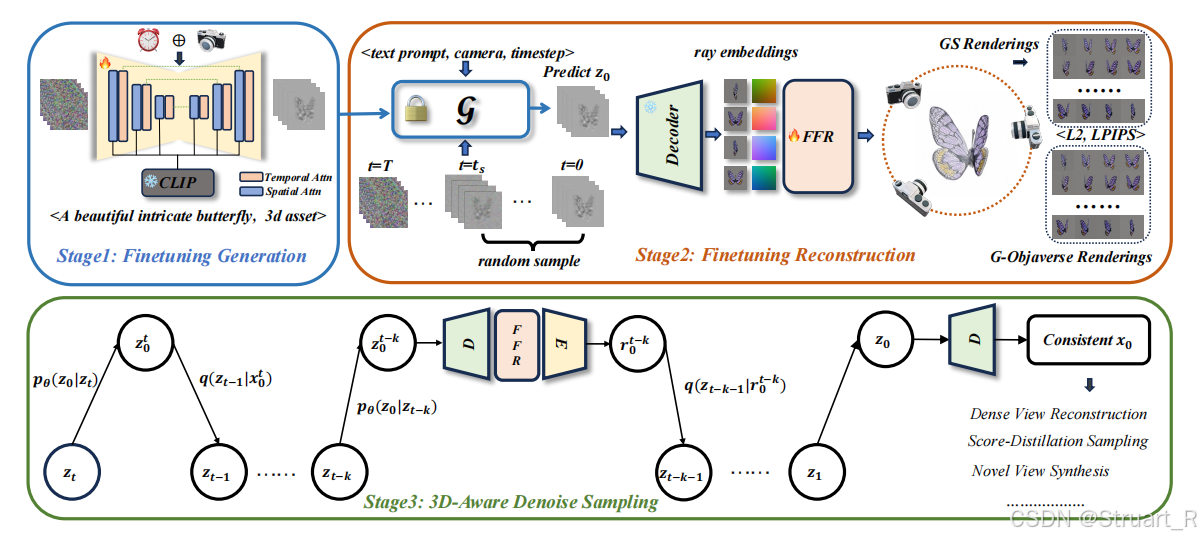
1、微调视频生成模型
首先利用两个开源的预训练模型ModelScope-T2V和I2VGen-XL,文生多视图和单视图生多视图模型,其中编码器和解码器部分使用VQGAN,应该就是这两个预训练模型带的,其中y代表条件(文本或者单视图)。
损失函数定义为:
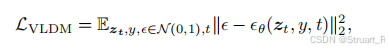
用于微调的视频生成模型,利用3D G-Objaverse数据集,以每个物体为中心,生成24个视图,其中仰角固定(5-30度随机一个),方位角均匀分布一圈。
在Stage1图中可以看到,使用了有效的时间卷积和时间注意力,在帧之间稀疏位置,而MVDream是轨迹中所有位置,导致密集视图内存爆炸。
另外将相机嵌入+两层MLP提取特征,结合到Temporal Attn层,来输入相机的姿态。
图像和文本通过CLIP输入到Spatial Attn层。
2、前馈重建
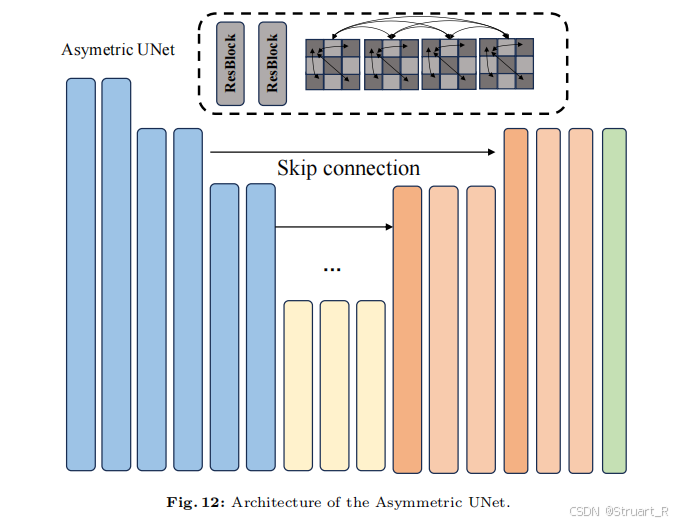
前馈重建的目的是,恢复全局三维模型,由于视频模型输出的图像帧存在损坏或者不一致,所以利用一个重建模型进行稀疏图像多视角重建。所以看Stage2中提到的FFR就是Feed-Forward Reconstruction的缩写,也就是经过视频生成模型G后,解码得到视频帧,再引入Plucker射线concat到RGB的视频帧上,作为多视图重建模型LGM的输入,最终输出一个3dgs表示。
采用了与LGM相同的非对称U-Net结构减少了高分辨率输出,也就是高斯溅射点的减少,这样在内存效率方面有优势。U-Net中包含了密集的自注意力,类似于MVDream,但考虑到计算资源,没有扩展到容纳24视图。
对于LGM的输入不可能输入所有的视频帧,所以我们选择了4个视图作为输入,并使用plucker射线嵌入对相机姿态进行密集编码,并与RGB值concat,作为重建模块输入。
注意:文生多视图中使用[128,128,128]作为背景色,就是那个全灰图,然后图生多视图将背景建模纯白。另外输入FFR的四个视图为正交视图,可以稳定重建性能。

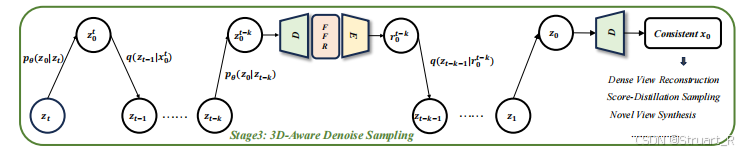
3、3D-Aware 去噪采样
3D-Aware 去噪采样是一种策略,进一步提高图像的多视图一致性,应用于多视图生成过程。
首先是视频生成模型在时间步t的潜在特征,
就是时间步t-k的潜在特征,
就是预测出的潜在特征(去噪后的) ,
是将
丢入FFR重建得到的渲染图像,之后将
引入去噪循环,我的理解是用这个渲染图像来计算t-k步的噪音差。其中k设置成10。
利用这种方法可以重建出拥有3D-Aware的图像,保证多视图一致性。
四、相关细节
1、ModelScopeT2V
基于文本的视频生成模型ModelScopeT2V,主要结构由VQGAN和Denoise U-Net构成VQGAN就是负责压缩和还原的功能,现在的模型都是VQVAE自编码器,VQGAN先单独训练,类似VQVAE的训练方式,然后计算重建损失和对抗性损失。
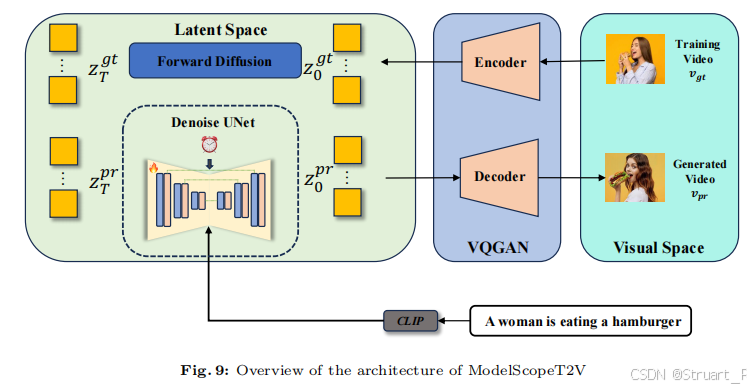
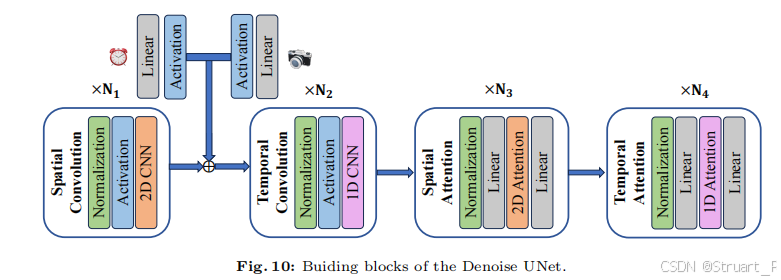
Denoise U-Net中文本经过CLIP encoder得到图像维度的特征,并通过Spatial Attention的cross attention中引入特征。另外扩散步t和相机姿态通过线性层和激活函数concat后引入spatial convolution得到的特征后。一个在卷积层concat,一个在Spatial Attn处cross-attention。
将ModelScopeT2V的原始输入接受32帧改为24帧,对齐VideoMV的要求,最终输出也是24帧。
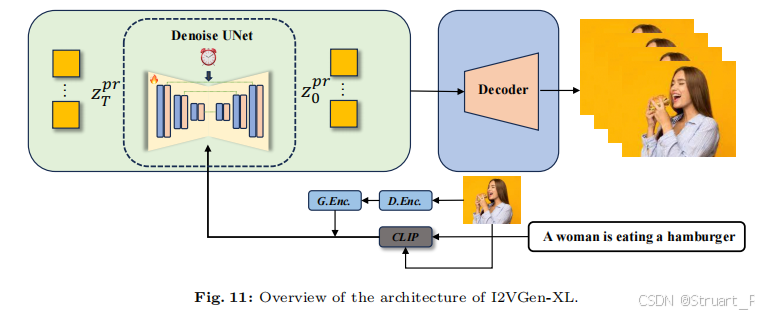
2、I2VGen-XL
基于图像的视频生成模型I2VGen-XL,我们根据下面这个单阶段的模型,这个模型与Modelscope有这相似的结构,但是为了不输入文字,就将输入的文本设为一个空字符串。另外G.Enc和D.Enc是一个VQGAN结构。
另外训练细节上,将帧数同样改为24,分辨率为256*256。
五、实验
文生视频量化比较。

文生视频上为MVDream,下为VideoMV。

图生视频的量化比较。
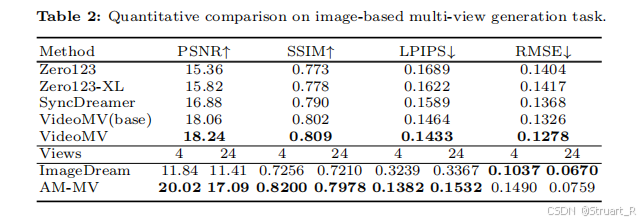
GSO数据集上的图生视频比较。


VideoMV:https://arxiv.org/abs/2403.12010
ModelScopeT2V:https://arxiv.org/abs/2308.06571
I2VGen-XL:https://arxiv.org/abs/2311.04145

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)