LangChain核心解析:掌握AI开发的“链“式思维
探索LangChain的核心概念"Chain",这把AI开发瑞士军刀让复杂应用构建变得简单!从四大基础链到高级文档处理,从记忆功能到自定义扩展,全方位剖析伴有实用代码示例。无论你是AI初学者还是经验开发者,这篇指南都能帮你快速掌握链式开发,构建智能应用的必读教程!
0. 思维导图

1. 引言 🌟
在人工智能快速发展的今天,如何有效地利用大语言模型(LLM)构建强大的应用成为众多开发者关注的焦点。前面的课程中,我们学习了正则表达式以及向量数据库的相关知识,了解了如何处理文档并将其附加给大模型。本章我们将深入探讨LangChain中的核心概念——“Chain”(链)。
LangChain作为一个强大的框架,让我们能够将LLM与其他计算资源或知识源结合起来,创建更加智能的应用。而Chain则是这个框架的重要组成部分,它就像是将各种功能模块串联起来的纽带,使得复杂的AI工作流成为可能。
2. 什么是Chain(链)💡
2.1 链的基本概念
在LangChain中,Chain(链)是一个核心概念,它代表一系列组件的连接,这些组件按照特定的顺序执行,以完成复杂的任务。简单来说,Chain就是将多个步骤组合成一个可调用的单元,让信息能够从一个组件流向另一个组件。
链的基本工作流程是:接收输入 → 处理数据 → 产生输出。而这个处理过程可能涉及到与LLM的交互、文档的检索、信息的提取等多个步骤。
2.2 链的重要性
链的设计理念使得我们可以:
- 🔄 模块化地组合不同功能
- 📦 封装复杂的逻辑流程
- 🛠️ 重用常见的处理模式
- 🧩 灵活地扩展应用功能
正是这种灵活性和模块化的特性,使得LangChain能够适应各种各样的AI应用场景,从简单的问答系统到复杂的智能助手。
3. 四种基本的内置链 🔗
LangChain提供了多种内置的链类型,其中最基础的四种分别是LLM链、顺序链、路由链和检索链。这些内置链为我们提供了处理不同任务的基本工具。
3.1 LLM Chain
LLM Chain(LLM链)是最基础也是最常用的链类型,它将提示模板(PromptTemplate)和语言模型(LLM)结合在一起,形成一个简单但强大的处理单元。
工作原理:
- 接收用户输入
- 根据提示模板格式化输入
- 将格式化后的提示发送给LLM
- 返回LLM的响应
代码示例:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# 创建提示模板
template = "请告诉我{topic}的三个重要知识点"
prompt = PromptTemplate(input_variables=["topic"], template=template)
# 初始化LLM
llm = OpenAI(temperature=0.7)
# 创建LLM链
chain = LLMChain(llm=llm, prompt=prompt)
# 使用链
response = chain.run("人工智能")
print(response)
3.2 Sequential Chain(顺序链)
顺序链允许我们将多个链按照特定顺序连接起来,前一个链的输出可以作为后一个链的输入,从而实现更复杂的处理流程。
顺序链主要有两种类型:
- SimpleSequentialChain:每个链只有一个输入和一个输出,链之间一对一串联
- SequentialChain:支持多输入多输出,更加灵活
代码示例(SimpleSequentialChain):
from langchain.chains import SimpleSequentialChain
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7)
# 第一个链:生成一个故事概要
first_prompt = PromptTemplate(
input_variables=["subject"],
template="请为{subject}写一个简短的故事概要"
)
chain_one = LLMChain(llm=llm, prompt=first_prompt)
# 第二个链:基于故事概要写一个完整故事
second_prompt = PromptTemplate(
input_variables=["概要"],
template="基于以下概要,写一个完整的故事:\n\n{概要}"
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 创建顺序链
overall_chain = SimpleSequentialChain(chains=[chain_one, chain_two])
# 运行链
response = overall_chain.run("一只迷路的猫")
print(response)
代码示例(SequentialChain):
from langchain.chains import SequentialChain
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7)
# 第一个链:为电影生成标题
first_prompt = PromptTemplate(
input_variables=["genre"],
template="为{genre}类型的电影想一个标题"
)
title_chain = LLMChain(llm=llm, prompt=first_prompt, output_key="title")
# 第二个链:为电影生成简介
second_prompt = PromptTemplate(
input_variables=["title"],
template="为电影《{title}》写一个简短的简介"
)
synopsis_chain = LLMChain(llm=llm, prompt=second_prompt, output_key="synopsis")
# 创建顺序链
overall_chain = SequentialChain(
chains=[title_chain, synopsis_chain],
input_variables=["genre"],
output_variables=["title", "synopsis"]
)
# 运行链
response = overall_chain.run("科幻")
print(f"标题: {response['title']}\n简介: {response['synopsis']}")
3.3 Router Chain(路由链)
路由链是一种能够根据输入动态决定调用哪个子链的高级链。它根据输入的内容或特征,选择最适合处理该输入的链,类似于一个智能分发器。
Router Chain由三个主要部分组成:
- 路由器(决定使用哪个链)
- 目标链(可选择的链集合)
- 默认链(当无法确定路由时使用)
代码示例:
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7)
# 定义各专业领域的提示模板
physics_template = PromptTemplate(
template="你是一位物理学专家。回答以下物理学问题:{question}",
input_variables=["question"]
)
math_template = PromptTemplate(
template="你是一位数学专家。解答以下数学问题:{question}",
input_variables=["question"]
)
history_template = PromptTemplate(
template="你是一位历史学家。解答以下历史问题:{question}",
input_variables=["question"]
)
default_template = PromptTemplate(
template="回答以下问题:{question}",
input_variables=["question"]
)
# 创建各领域的链
physics_chain = LLMChain(llm=llm, prompt=physics_template)
math_chain = LLMChain(llm=llm, prompt=math_template)
history_chain = LLMChain(llm=llm, prompt=history_template)
default_chain = LLMChain(llm=llm, prompt=default_template)
# 创建路由链
router_chain = MultiPromptChain(
router_chain=LLMRouterChain.from_llm(llm),
destination_chains={
"物理": physics_chain,
"数学": math_chain,
"历史": history_chain
},
default_chain=default_chain
)
# 使用路由链
physics_q = "光速为什么是宇宙速度的上限?"
response = router_chain.run(physics_q)
print(response)
3.4 Retrieval Chain(检索链)
检索链专门用于处理那些需要从外部知识库检索信息来回答问题的场景。它结合了向量数据库和LLM的能力,能够实现基于知识的智能问答。
工作流程:
- 接收用户查询
- 从文档存储中检索相关文档
- 将查询和检索到的文档组合成提示
- 发送给LLM生成最终回答
代码示例:
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# 加载文档
loader = TextLoader('data.txt')
documents = loader.load()
# 文档切分
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
# 创建检索链
llm = OpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever()
)
# 使用检索链
query = "什么是LangChain?"
response = qa_chain.run(query)
print(response)
4. 链的不同调用方法和自定义 ⚙️
4.1 链的调用方法
LangChain中的链提供了多种调用方式,根据不同的需求选择合适的方法:
-
run方法:最简单的调用方式,直接传入字符串,适用于单输入单输出的情况
response = chain.run("请介绍一下人工智能") -
__call__方法:更灵活的调用方式,可以传入字典形式的多个输入变量
response = chain({"topic": "人工智能", "length": "简短"}) -
invoke方法:提供显式API调用,可以传入多个参数
response = chain.invoke({"topic": "人工智能"}) -
predict方法:接受关键字参数,使代码更易读
response = chain.predict(topic="人工智能", length="详细") -
batch方法:批量处理多个输入
responses = chain.batch([{"topic": "AI"}, {"topic": "机器学习"}])
4.2 自定义链
除了使用内置链,LangChain还允许我们创建自定义链来满足特定需求。自定义链需要继承Chain类并实现必要的方法。
自定义链的基本步骤:
- 继承
Chain类 - 定义输入输出键
- 实现
_call方法处理核心逻辑
示例代码:
from langchain.chains.base import Chain
from langchain.llms import OpenAI
from typing import Dict, List, Any
class CustomChain(Chain):
llm: OpenAI
@property
def input_keys(self) -> List[str]:
return ["question"]
@property
def output_keys(self) -> List[str]:
return ["answer"]
def _call(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
question = inputs["question"]
# 自定义处理逻辑
enhanced_question = f"请仔细思考并详细回答:{question}"
answer = self.llm(enhanced_question)
return {"answer": answer}
# 使用自定义链
custom_chain = CustomChain(llm=OpenAI(temperature=0.7))
response = custom_chain.run("什么是深度学习?")
print(response)
5. 处理文档的预制链 📑
LangChain提供了多种专门用于处理文档的预制链,使我们能够更容易地实现文档问答、摘要生成等功能。
5.1 Load-Retrieve-Generate链
这是一个基础的文档处理链,包含三个主要步骤:加载文档、检索相关内容、生成回答。
工作流程:
- 加载文档
- 将文档转换为向量嵌入并存储
- 根据查询检索相关文档片段
- 将检索到的文档片段和查询一起发送给LLM
- 生成基于文档的回答
代码示例:
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# 加载PDF文档
loader = PyPDFLoader("document.pdf")
documents = loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(split_docs, embeddings)
# 创建检索问答链
llm = OpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever()
)
# 使用链进行问答
query = "文档中提到的主要观点是什么?"
response = qa_chain.run(query)
print(response)
5.2 Map-Reduce链
Map-Reduce链适用于处理大量文档的场景,它将任务分解为"映射"和"归约"两个阶段:
工作流程:
- 映射阶段:对每个文档片段单独处理(例如,为每个片段生成摘要)
- 归约阶段:将所有处理结果合并为一个最终结果(例如,合并所有摘要)
这种方法可以有效处理大型文档,因为它分散处理文档片段,减少了每次处理的复杂度。
代码示例:
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import PyPDFLoader
from langchain.llms import OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载文档
loader = PyPDFLoader("large_document.pdf")
documents = loader.load()
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=100
)
split_docs = text_splitter.split_documents(documents)
# 创建Map-Reduce摘要链
llm = OpenAI(temperature=0)
map_reduce_chain = load_summarize_chain(
llm,
chain_type="map_reduce",
verbose=True
)
# 生成文档摘要
summary = map_reduce_chain.run(split_docs)
print(summary)
5.3 Refine链
Refine链是一种迭代改进答案的方法,特别适合需要高质量、精确回答的场景。
工作流程:
- 使用第一个文档片段生成初始回答
- 依次处理后续文档片段,每次都对前一个回答进行改进
- 最终得到一个基于所有文档信息的精细回答
代码示例:
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import PyPDFLoader
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
# 加载文档
loader = PyPDFLoader("research_paper.pdf")
documents = loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents)
# 创建Refine摘要链
llm = OpenAI(temperature=0)
refine_chain = load_summarize_chain(
llm,
chain_type="refine",
verbose=True
)
# 生成文档摘要
refined_summary = refine_chain.run(split_docs)
print(refined_summary)
5.4 Stuff链
Stuff链是最简单的文档处理链,它将所有文档内容"塞入"(stuff)一个提示中,适用于处理少量或短小文档。
工作流程:
- 将所有文档内容合并为一个文本
- 将合并后的文本与查询一起发送给LLM
- 由LLM直接生成回答
代码示例:
from langchain.chains.question_answering import load_qa_chain
from langchain.document_loaders import TextLoader
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
# 加载文档
loader = TextLoader("short_document.txt")
documents = loader.load()
# 分割文档(这里分割只是为了演示,Stuff链通常用于较小文档)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents)
# 创建Stuff问答链
llm = OpenAI(temperature=0)
stuff_chain = load_qa_chain(
llm,
chain_type="stuff"
)
# 使用链进行问答
query = "文档的主要内容是什么?"
response = stuff_chain.run(input_documents=split_docs, question=query)
print(response)
6. Memory功能:让LLM拥有记忆力 🧠
在长时间交互或多轮对话中,记忆上下文信息至关重要。LangChain的Memory组件使链能够记住之前的交互,从而实现更自然、更连贯的对话体验。
6.1 Memory的基本概念
Memory在LangChain中的作用是存储和管理先前交互的信息,它可以:
- 📝 记录对话历史
- 🔄 在新的交互中引用过去的信息
- 🗃️ 以不同的格式组织和存储信息
6.2 常见的Memory类型
LangChain提供了多种Memory类型,每种都有特定的用途和特点:
6.2.1 ConversationBufferMemory
最基本的记忆类型,简单地存储所有先前的消息。
特点:
- 存储完整的对话历史
- 随着对话进行可能占用大量内存
- 适合短期对话
代码示例:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
# 初始化内存和模型
memory = ConversationBufferMemory()
llm = OpenAI(temperature=0.7)
# 创建带记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 第一轮对话
response1 = conversation.predict(input="你好!我叫小明。")
print(response1)
# 第二轮对话(会记得用户的名字)
response2 = conversation.predict(input="你还记得我的名字吗?")
print(response2)
6.2.2 ConversationBufferWindowMemory
与BufferMemory类似,但只保留最近的K个交互,节省内存空间。
特点:
- 只保留最近的几轮对话
- 适合需要有限上下文的场景
- 内存使用更加高效
代码示例:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferWindowMemory
# 初始化窗口内存(只保留最近2轮对话)
memory = ConversationBufferWindowMemory(k=2)
llm = OpenAI(temperature=0.7)
# 创建带窗口记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 多轮对话测试
responses = []
responses.append(conversation.predict(input="我的名字是小红"))
responses.append(conversation.predict(input="我喜欢吃苹果"))
responses.append(conversation.predict(input="我今年25岁"))
# 只会记住最近两轮对话,关于年龄和苹果的信息
responses.append(conversation.predict(input="你记得我的名字吗?"))
for i, response in enumerate(responses):
print(f"回答 {i+1}: {response}")
6.2.3 ConversationSummaryMemory
不存储完整的对话历史,而是存储对话的摘要,随着对话进行不断更新摘要。
特点:
- 内存使用效率高
- 适合长时间对话
- 可能会丢失一些细节信息
代码示例:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationSummaryMemory
# 初始化摘要内存
llm = OpenAI(temperature=0.7)
memory = ConversationSummaryMemory(llm=llm)
# 创建带摘要记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 多轮对话
conversation.predict(input="我是一名数据科学家,正在学习如何使用LangChain构建AI应用。")
conversation.predict(input="我最近在研究如何处理大规模文档数据。")
conversation.predict(input="我想了解向量数据库和嵌入技术。")
# 查看摘要
print("对话摘要:")
print(memory.buffer)
# 测试记忆效果
response = conversation.predict(input="你能总结一下我们之前讨论的内容吗?")
print(response)
6.2.4 ConversationTokenBufferMemory
基于令牌数量而非消息数量限制内存,特别适合处理LLM上下文窗口限制的场景。
特点:
- 根据令牌数量限制内存
- 适合固定上下文窗口的LLM
- 可以更精确地控制内存使用
代码示例:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationTokenBufferMemory
# 初始化基于令牌的内存(最大2000个令牌)
llm = OpenAI(temperature=0.7)
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=2000)
# 创建带令牌限制记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 测试对话
response1 = conversation.predict(input="请详细介绍一下什么是大语言模型?")
print(response1)
response2 = conversation.predict(input="这些模型面临哪些挑战?")
print(response2)
# 查看当前使用的令牌数
print(f"当前使用的令牌数: {memory.llm_token_count}")
6.2.5 ConversationEntityMemory
专门记住对话中提到的特定实体(如人物、地点、概念等)。
特点:
- 提取并存储关键实体信息
- 可以针对特定实体进行回忆
- 适合需要跟踪多个主题的对话
代码示例:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationEntityMemory
# 初始化实体内存
llm = OpenAI(temperature=0.7)
memory = ConversationEntityMemory(llm=llm)
# 创建带实体记忆的对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 测试对话
conversation.predict(input="我的猫叫小花,它今年3岁了。")
conversation.predict(input="我的狗叫大黄,它喜欢吃骨头。")
# 查看存储的实体
print("存储的实体:")
print(memory.entity_store.store)
# 测试实体记忆
response = conversation.predict(input="我的猫叫什么名字?")
print(response)
6.3 为链添加Memory功能
任何LangChain链都可以添加Memory组件,使其能够记住之前的交互。添加Memory通常有两种方式:
- 在创建链时添加:
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=OpenAI(temperature=0.7),
memory=memory
)
- 自定义链中添加:
from langchain.chains.base import Chain
from langchain.memory import ConversationBufferMemory
from typing import Dict, List, Any
class CustomMemoryChain(Chain):
memory: ConversationBufferMemory
# 其他自定义逻辑...
@property
def input_keys(self) -> List[str]:
return ["input"]
@property
def output_keys(self) -> List[str]:
return ["output"]
def _call(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
# 从内存中获取对话历史
chat_history = self.memory.chat_memory.messages
# 处理输入和历史
# ...处理逻辑...
# 更新内存
self.memory.chat_memory.add_user_message(inputs["input"])
self.memory.chat_memory.add_ai_message(response)
return {"output": response}
7. 主要的预制链和Memory工具总结 🧰
7.1 预制链的选择指南
根据不同的应用场景,我们可以选择不同类型的预制链:
| 场景 | 推荐链类型 |
|---|---|
| 简单问答 | LLMChain |
| 多步骤处理 | SequentialChain |
| 不同任务分流 | RouterChain |
| 基于文档问答 | RetrievalQA |
| 处理大型文档 | MapReduceChain |
| 需要高质量回答 | RefineChain |
| 处理小文档 | StuffChain |
7.2 Memory选择指南
| 场景 | 推荐Memory类型 |
|---|---|
| 短期对话 | ConversationBufferMemory |
| 有限上下文 | ConversationBufferWindowMemory |
| 长时间对话 | ConversationSummaryMemory |
| 固定上下文窗口 | ConversationTokenBufferMemory |
| 多实体追踪 | ConversationEntityMemory |
7.3 工作流程图示
以下是一个典型的带有Memory功能的问答链的工作流程:
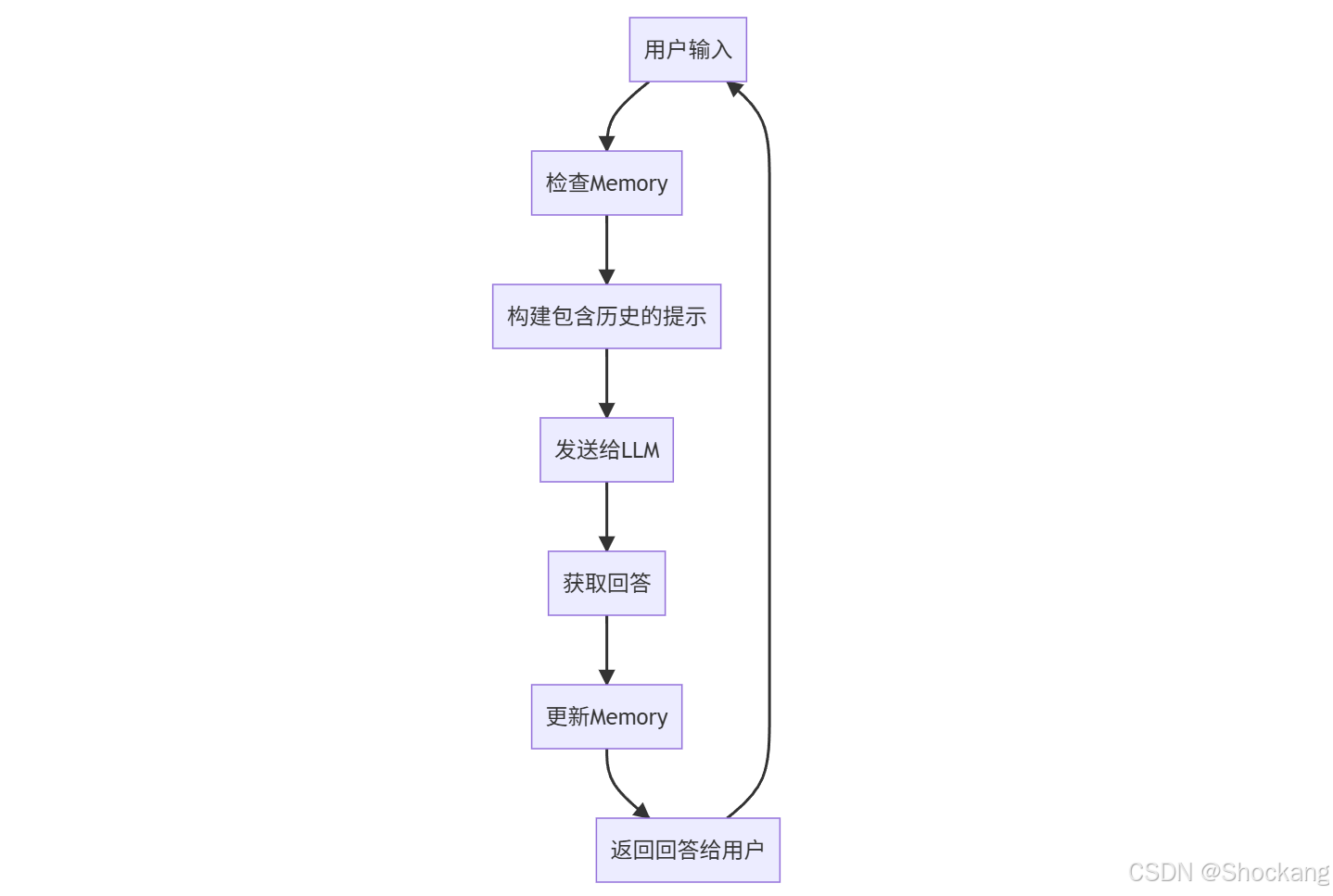
8. 本章小结 📝
本章我们深入探讨了LangChain中的Chain(链)概念,了解了它如何帮助我们构建复杂的AI应用。主要内容包括:
-
Chain的基本概念:链作为LangChain的核心组件,将多个步骤组合成一个可调用单元,使信息能够从一个组件流向另一个组件。
-
四种基本内置链:
- LLMChain:将提示模板和LLM结合
- SequentialChain:将多个链按顺序连接
- RouterChain:根据输入动态选择要使用的链
- RetrievalChain:从知识库检索信息并回答问题
-
链的调用方法:run、call、invoke、predict和batch等不同调用方式,适用于不同场景。
-
自定义链:如何通过继承Chain类创建自己的链,以满足特定需求。
-
处理文档的预制链:
- Load-Retrieve-Generate链
- Map-Reduce链
- Refine链
- Stuff链
-
Memory功能:让LLM拥有记忆力,实现连贯对话:
- ConversationBufferMemory
- ConversationBufferWindowMemory
- ConversationSummaryMemory
- ConversationTokenBufferMemory
- ConversationEntityMemory
-
为链添加Memory:如何在创建链时或在自定义链中添加Memory组件。
通过本章的学习,我们已经掌握了LangChain中Chain的核心概念和使用方法,这是构建高级AI应用的重要基础。链使我们能够灵活地组合不同功能模块,创建智能、连贯的交互式体验。
9. 实践练习 🏋️♀️
为了巩固所学知识,推荐尝试以下练习:
-
基础练习:创建一个简单的LLMChain,使用不同的调用方法尝试获取结果。
-
顺序链练习:构建一个SequentialChain,实现"用户输入话题→生成故事大纲→扩展为完整故事"的流程。
-
路由链练习:创建一个RouterChain,能够将不同类型的问题分发给不同的处理链。
-
文档处理练习:使用RetrievalQA链实现一个简单的文档问答系统,尝试不同的检索方法。
-
Memory练习:为对话链添加不同类型的Memory,比较它们在长时间对话中的表现差异。
-
进阶挑战:创建一个自定义链,能够处理多种输入格式,并集成Memory功能。
通过这些练习,你将能够更深入地理解和应用LangChain中的链和内存概念,为构建复杂的AI应用奠定坚实基础。🚀
希望这份总结能帮助你更好地复习LangChain课程中关于Chain的内容!链是LangChain中非常核心的组件,掌握好链的使用将极大提升你开发AI应用的能力。如有任何疑问,欢迎随时提出!😊

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)