EMNLP25 | “大模型在环“技术新突破:Dial-In LLM 推动中文客服意图聚类新范式
总体框架思想(概念化综述与方法论见:LLM-in-the-loop (概念综述),在本研究中将 LLM 深度嵌入聚类循环的关键决策位:不仅承担预处理或事后润色的辅助角色,而是直接参与“评估 → 命名 → 合并 → 再聚类”的闭环迭代过程;:以传统聚类的效率为“骨架”,用微调后的中文 LLM 做“语义裁判”和“命名批注”,实现自动发现簇数、语义一致性评估、可解释命名与后校正合并的闭环流程。:聚类结果
TL;DR:本文提出LLM-in-the-loop(大模型在环)意图聚类框架:以传统聚类的效率为“骨架”,用微调后的中文 LLM 做“语义裁判”和“命名批注”,实现自动发现簇数、语义一致性评估、可解释命名与后校正合并的闭环流程。在10 万+真实客服通话构建的1,507 意图中文数据集上,方法著超越现有基线,实现了量化指标与下游任务表现的双重提升。
-
论文:Dial-In LLM: Human-Aligned LLM-in-the-loop Intent Clustering for Customer Service Dialogues
-
录用:EMNLP 2025 主会(Long Paper)
-
链接:https://arxiv.org/abs/2412.09049
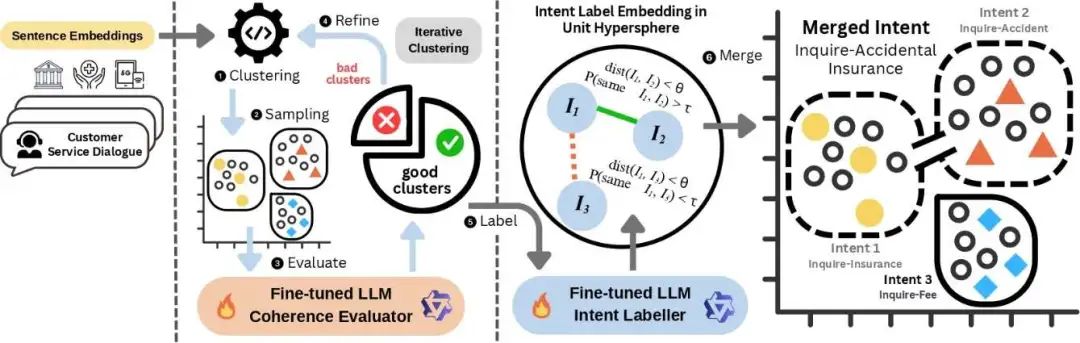
在客服对话中,准确识别用户意图 是智能客服系统的核心能力。然而,现有方法普遍存在三大问题:
-
过度依赖词向量相似度:传统方法依赖embedding 距离度量,过度强调语序结构,忽略语义信息。
-
类别缺乏可解释性:聚类结果常以“向量团”展示,可解释性差,缺少统一的命名规范与可迁移的业务含义,难以转化为可应用的意图知识库。
-
直接调用大模型成本过高:逐句调用 LLM(如为每句生成关键词或校正标签)虽可改善效果,但调用量与 token 成本高、结果受提示词与温度等因素波动,工程上难以稳定规模化落地。
🚀 解决思路:LLM-in-the-loop(LLM 在环)的人类对齐聚类
我们参考并拓展了我们在另一篇工作中提出的“LLM-in-the-loop”总体框架思想(概念化综述与方法论见:LLM-in-the-loop (概念综述),在本研究中将 LLM 深度嵌入聚类循环的关键决策位:不仅承担预处理或事后润色的辅助角色,而是直接参与“评估 → 命名 → 合并 → 再聚类”的闭环迭代过程;传统聚类算法负责高效搜索与收敛,LLM 负责语义对齐与解释友好,从而在效率、准确性与可解释性之间取得平衡。
⚙️ 方法论:从“候选聚类”到“高质量、可解释意图库”
-
初步聚类(高效):使用传统算法(如K-means)进行快速聚类,得到候选类别,为后续 LLM 评估提供素材。
-
大模型评估器(人类对齐):采用微调后的小参数LLM对聚类结果进行 语义一致性判断,保留“好聚类”,拆分“差聚类”。
-
微调后的小参数中文 LLM(如 Qwen 2.5-7B/14B、ChatGLM3-6B)在人类对齐的簇判定上>95%。
-
代表性采样采用凸包采样(优于随机);过度投票或高维采样反而降效,“简单更稳”;
-
二元判定优于 1–4 分制(一致性更高、可操作性更强);
-
承上启下:评估结果直接反馈到簇数选择与样本流转,让后续迭代以人类语义一致性为目标函数推进。
-
大模型批注员(可解释性):本文提出 “动作-目标“(Action–Objective)命名规范(如“询问-优惠”“解答-金额”),由微调 LLM 为通过评估的好簇生成简洁、任务导向的标签。
-
-
可用性增强:把“向量团”转化为可用的意图词表,便于知识库沉淀、检索与对话路由;同时为后校正的几何-概率合并提供语义锚点(标签向量)。
-
-
迭代优化:通过循环迭代,逐步收敛到 语义一致、可解释 的意图类别。
-
后校正(合并近义簇):将簇标签embedding并归一到单位超球,以角距离构建语义亲和图,再用 vMF(von Mises-Fisher)混合估计“同意图概率”,超过阈值的簇做稳健合并。
-
📊 实验亮点
-
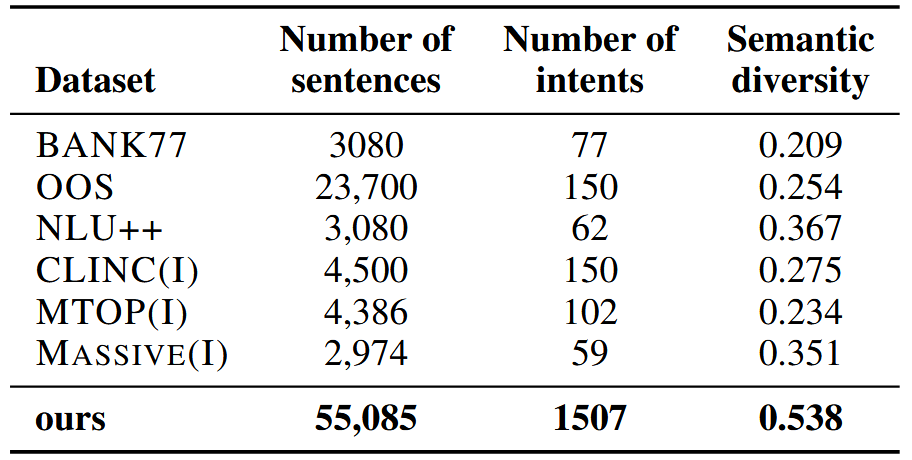
大规模中文数据集:本文构建了迄今最大规模的 中文客服意图数据集,涵盖 10 万+真实通话(银行 / 电信 / 保险等), 55,085 条独立句子,由25位人类专家标注的 1507 个高质量意图簇。
-
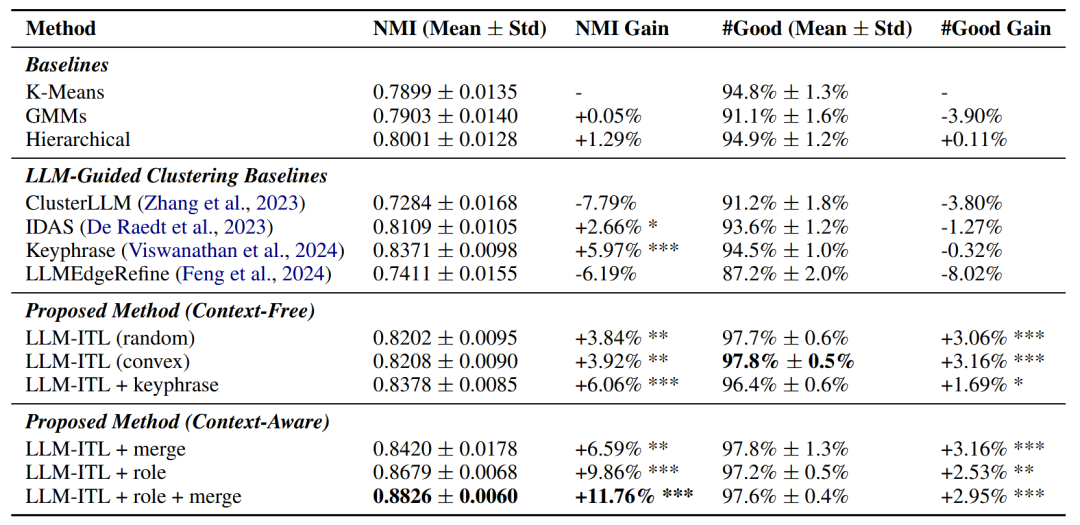
性能提升显著:与传统方法相比:
-
-
聚类质量更高(NMI指标提升11.76%)。
-
调用成本更低(在Bank77基准中,本文提出的方法仅需480 次 LLM 调用,而 ClusterLLM 方法需 1,024+ 次)。
-
-
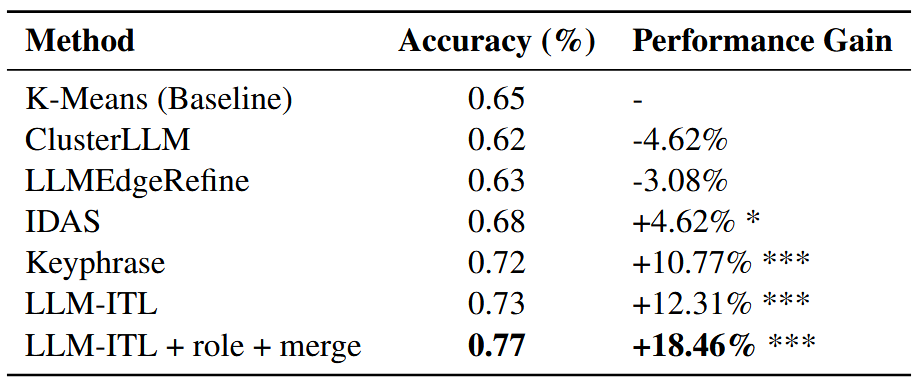
下游任务验证:我们将各方法生成的聚类结果用于训练 BERT 意图分类器进行验证。实验结果表明,所提出的 LLM-ITL 方法生成的数据可使分类准确率达到约 77%,相比基线提升 12 个百分点(相对提升约 18%)。与其他方法相比,LLM-ITL 生成的簇更加干净、一致,标签质量更高,能够直接转化为高价值的数据资产,从而显著提升实际系统的意图识别性能。
🌟 实践价值
-
智能客服场景优化:精准意图识别提升自动应答效率,助力人工客服。
-
大模型在环有效证明:LLM-in-the-Loop框架实现高效、可解释聚类,兼顾语义对齐与成本控制,具教育、医疗等场景扩展潜力。
-
让 LLM 做“工具”,不做“全能工”:聚焦 LLM utility(如评估,命名,分类),以少量、短输出的 LLM 调用即可闭环推进全流程,实现降本增效。
📝总结
Dial-In LLM 证明:LLM-in-the-loop并不是把 LLM “套个壳”,而是在算法循环中嵌入人类对齐的语义决策。这使得意图聚类既快、又准、还能解释,并真正服务于面向生产的意图体系构建与维护。欢迎查看原文以获更多实验细节:
论文:https://arxiv.org/abs/2412.09049
作者介绍

洪梦泽,21岁,香港理工大学博士二年级学生。研究方向为大模型在环(LLM-in-the-loop)技术与数据挖掘。以第一作者身份在NAACL、EMNLP等国际顶会发表多篇论文,并担任香港文汇报专栏作家及多个学术会议审稿人。
个人主页:https://mengze-hong.github.io

-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)