Large Language Models for Wireless Networks: An Overview from the Prompt Engineering Perspective
—最近,大型语言模型(LLMs)已成功应用于许多领域,展示了卓越的理解和推理能力。尽管这些LLMs具有巨大的潜力,但通常需要专门的预训练和微调以适应特定领域应用,如无线网络。这些适应过程可能会对计算资源和数据集要求极高,而大多数网络设备的计算能力有限,且高质量的网络数据集较为稀缺。为此,本研究从提示工程(prompt engineering)的角度探索了LLM驱动的无线网络,即设计提示以引导LLM
摘要——最近,大型语言模型(LLMs)已成功应用于许多领域,展示了卓越的理解和推理能力。尽管这些LLMs具有巨大的潜力,但通常需要专门的预训练和微调以适应特定领域应用,如无线网络。这些适应过程可能会对计算资源和数据集要求极高,而大多数网络设备的计算能力有限,且高质量的网络数据集较为稀缺。为此,本研究从提示工程(prompt engineering)的角度探索了LLM驱动的无线网络,即设计提示以引导LLM生成所需输出,而无需更新LLM参数。与其他LLM驱动的方法相比,提示工程能够更好地与无线网络设备的需求相契合,例如更高的部署灵活性、更快的响应时间和较低的计算能力要求。具体而言,本研究首先介绍了LLM的基本原理,并比较了不同的提示技术,如上下文学习、链式推理和自我修正。接着,我们提出了两种新的提示方案,旨在网络应用中的迭代优化和网络预测:用于网络优化的迭代提示和用于网络预测的自我修正提示。案例研究表明,所提出的方案能够实现与传统机器学习技术相当的性能,并且我们的提示驱动方法避免了专门的模型训练和微调,这也是现有机器学习技术的瓶颈之一。
关键词——大型语言模型,无线网络,提示工程
I. INTRODUCTION
作为生成式人工智能(generative AI)的一个子领域,大型语言模型(LLMs)已受到工业界和学术界的广泛关注[1]。生成式AI和LLM的进展为6G网络提供了有前景的机会,包括强大的推理和规划能力、多模态理解、6G传感、语义通信[2]、集成卫星-空中-地面网络[3]等。尽管具有巨大的潜力,但将LLM集成到无线网络中仍面临几个挑战。首先,无线网络是复杂的大规模系统,涉及多个知识领域,即信号处理和传输、网络架构和设计、协议、标准等。直接将通用领域的LLM应用于特定领域的网络任务可能导致性能不佳。其次,LLM的发展依赖于高质量的数据集进行微调适应,但高质量的网络数据集有限,例如SPEC5G和Tspec-LLM[1]。此外,LLM在计算资源方面的需求非常高。LLM的预训练和微调通常在高性能的GPU上实现,如NVIDIA A100和H100,但无线网络设备通常计算和存储能力有限。LLM涉及广泛的技术,如预训练、微调LLM以完成特定任务、检索增强生成(retrieval augmented generation,RAG)、提示工程等。因此,识别一种高效的方法,以更好地将LLM适应到无线网络中是至关重要的。
鉴于上述机会和挑战,本研究提出了提示工程,这被认为是一种资源高效和灵活的方法,能够使用LLM并具有快速的实现速度[4]。这些优势将有助于克服上述LLM应用挑战,例如部署困难和对计算资源的需求。具体而言,提示指的是设计输入提示来引导预训练的LLM生成期望的输出。它利用了预训练LLM固有的推理能力,并避免了反向传播和梯度更新的需求。因此,提示工程具有几个关键特点:
-
资源高效:提示只需要正向传递模型,不需要存储用于反向传播的中间激活。这样一种资源高效的方法可以缓解网络服务器和设备的计算负担。
-
更高的灵活性:基于提示的方法可以通过制作相应的文本示范和查询,快速适应各种任务,而无需额外的编码步骤[5]。这表明它是一种高效的方法,可以定制LLM来应对各种网络任务。
-
快速实现:提示工程依赖于LLM的推理能力,并避免了更新LLM参数所需的时间成本。因此,较低的响应时间可以更好地支持低延迟网络服务。最后,尽管提示LLM可以显著提高性能,但它不是LLM使用的单一解决方案[6]。例如,将提示工程与微调结合使用,可能会创建一个更强大的框架,既具有提示灵活性,又具备模型专用化。然而,本研究的重点是开发提示技术,以充分挖掘LLM的潜力。

| 方法 | 关键原理 | 优势 | 潜在困难 | 计算资源与时间成本 | 可能的无线网络应用 |
|---|---|---|---|---|---|
| 预训练LLMs | 1) 从数百亿个令牌中进行训练,以进行下一个令牌预测。 2) 预训练是LLM开发和使用的基础步骤。 |
预训练使LLMs具备理解、推理和指令跟随能力,能够应对下游任务。 | 预训练极其资源密集,要求长时间训练,并消耗大量计算资源,且需要大量的GPU或TPU。 | 高热设计功率GPU,如NVIDIA H100-80G或A100-80G,训练Llama3.1-40B大约需要30.84M GPU小时。 | 一个专用网络LLM表示出巨大优势,但从头开始训练网络LLM由于计算资源的要求可能不合适。 |
| 微调 | 微调是指通过部分或完全更新模型权重或引入额外适配模块,将预训练的LLM适应于特定任务。 | 微调显著减少了训练时间和计算成本,相比于预训练,生成适合特定任务的LLM模型。 | 1) 微调时需要考虑过拟合风险和失去泛化能力。 2) 需要标注数据,可能需要额外的人工劳动。 |
成本可能因模型大小和微调方法的不同而有所不同。如果完全微调一个7B参数模型,使用8个A100-80G GPU,可能需要100-200 GPU小时来处理一个100M令牌数据集。 | 微调是一种将LLM应用于无线网络的现实方法,将通用领域LLM适应于特定任务,如网络故障排除和配置。 |
| 检索增强生成(RAG) | RAG将LLM与外部知识库结合,使得模型在推理时能够检索相关信息并提供更准确的响应。 | RAG通过利用外部知识源来提高LLM的响应准确性,生成更及时的结果。 | 1) RAG增加了额外的集成复杂性,因为它需要高效的检索算法。 2) RAG高度依赖于结构良好的知识库,需要专用的计算资源。 |
1) 成本取决于检索方法和知识库的大小。推理可能需要几秒钟到几分钟不等。 2) 需要平衡检索速度和准确性。 |
1) RAG是实现LLMs的一种更实际的方法,尤其是在现有的网络特定数据集可用时。 2) 它确保LLM访问到最相关和最新的网络数据。 |
| 提示工程 | 提示工程是指设计特定的输入提示来引导预训练LLM生成所需的输出,而无需对模型进行重新训练或调优。 | 1) 提示工程具有低计算成本和快速实现的特点。 2) 它可以轻松地适应不同的任务,而无需额外训练。 |
1) 需要具备设计有效提示的专业知识。 2) 受限于预训练LLM的内在能力和上下文窗口大小。 |
1) 无需反向传播和梯度更新,计算资源需求最小。 2) 与其他方法相比,时间成本显著较低。 |
1) 提示工程能够在动态无线网络环境中实现快速决策和响应。 2) 它与许多网络任务高度契合。 |
注:本表的目的是介绍每种技术的特点,它们在LLM开发和应用中的不同用途。这些方法可以结合使用,以实现更好的性能,例如微调网络LLM和提示工程。
VI. CASE STUDIES
本节介绍了两个关于网络优化和预测问题的案例研究。
- 网络优化:该案例研究涉及基站功率控制问题,这是无线网络领域的一个基本优化任务。所考虑的问题公式旨在最小化基站的功率消耗,同时保持用户的平均数据速率阈值。我们考虑了三个相邻的基站,及其关联的用户数量动态变化,范围为5到15个用户,每个基站的平均数据速率阈值为1.5 Mbps/用户,并且信道增益使用了3GPP城市网络模型。该案例研究包括:
-
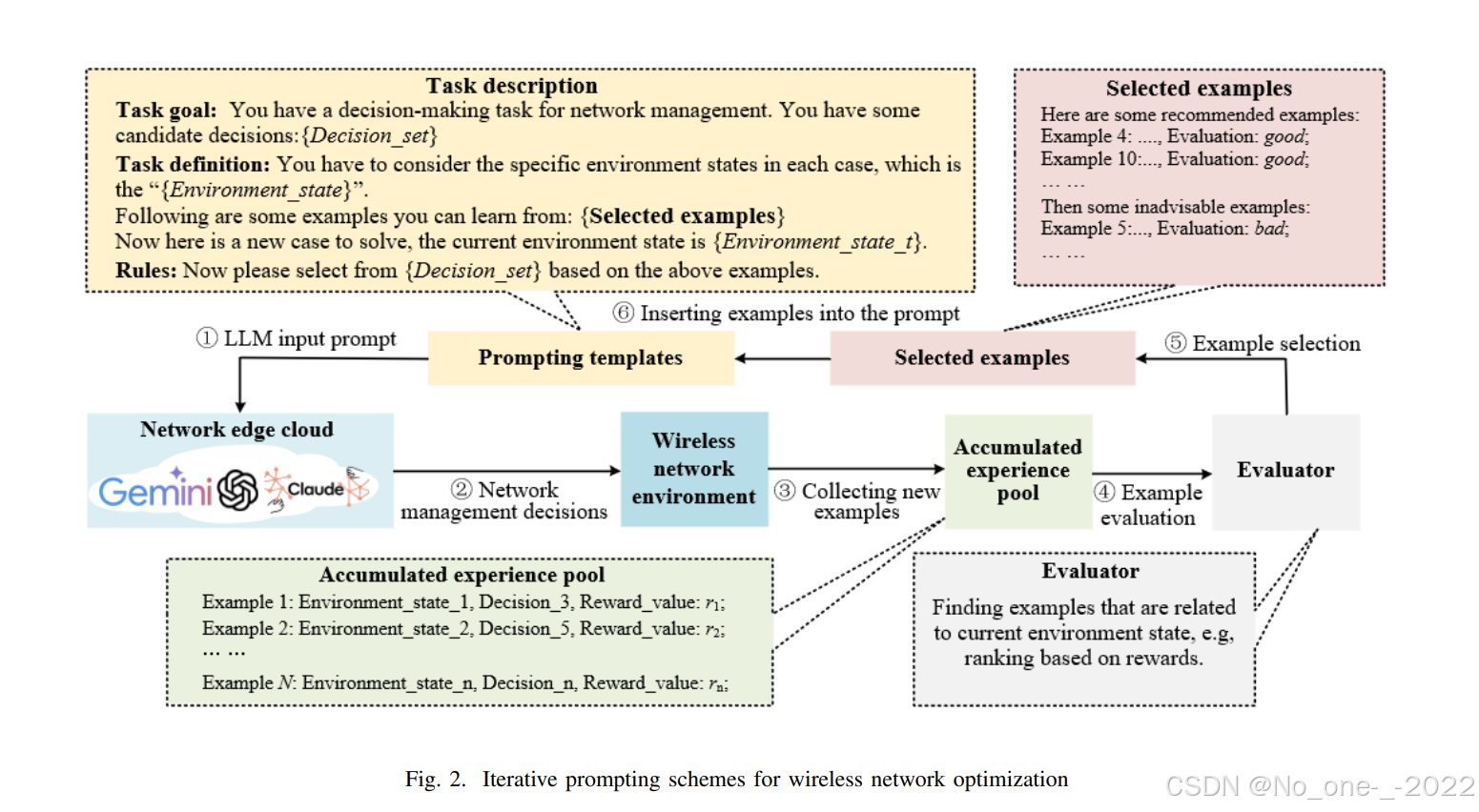
① 迭代提示:我们考虑了两个LLM模型:Llama3-7b-instruct 作为小规模模型,Llama3-70b-instruct 作为大规模模型。我们部署了如图2和第IV节中介绍的迭代提示技术(iterative prompting technique),其中LLM将探索环境,积累经验,并进行迭代学习。
-
② DRL基准:DRL被作为基准,该模型在训练后被广泛应用于解决网络优化问题。我们应用了经典的深度Q学习算法,其中神经网络有3层,经验池大小为10000,批量大小为64,学习率为0.005。
- 网络预测:评估数据集是来自米兰市的一个公开可用的网络流量数据集[14],记录了用户交互的时间和基站管理这些交互。原始的100×100基站网格重新组织成25×25=625个聚合基站。每个聚合基站覆盖一个大约1km×1km的区域,共包括8923个样本。为了评估,我们随机选择一个基站,并将数据集划分为70%用于训练,10%用于验证,剩余20%用于测试。仿真算法包括:
① 自我修正:我们提出的自我修正提示使用GPT-4作为基础模型进行一天后的交通预测,基于前一天的历史交通数据。它遵循图3和第V节中定义的自我修正提示技术。
② LLM相关基准:我们包括GPT-4和GPT-3.5没有自我修正作为两个LLM相关基准,以更好地展示自我修正的能力。
③ 传统基准:自回归集成移动平均(ARIMA)和LSTM作为两个传统基准。通过大量实验,ARIMA基准模型的最佳参数确定为自回归( p = 2 p=2 p=2)、差分( d = 1 d=1 d=1)和移动平均( q = 2 q=2 q=2)组件。我们部署LSTM作为最优基准,因为它已专门针对目标网络流量数据集进行训练。相比之下,自我修正和LLM相关基准没有针对目标任务的任何先验知识。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)