Qwen3-Next:长上下文 + 高稀疏MoE + 混合注意力 = 下一代大模型架构革命
Qwen3-Next提出新一代大模型架构创新,通过混合注意力机制(75% Gated DeltaNet + 25% Gated Attention)、极致稀疏MoE(80B总参/3B激活)、训练稳定性优化及多Token预测技术,实现突破性进展。该架构在仅消耗Qwen3-32B 9.3%训练成本下,性能持平甚至超越235B旗舰模型,推理吞吐提升10倍以上,支持256K长上下文处理。核心优势体现为:更

核心突破:混合注意力架构 + 极致稀疏MoE + 多Token预测 + 长上下文原生支持
大模型的未来 = Context Scaling + Parameter Scaling
Qwen团队提出未来大模型两大演进方向:
- Context Length Scaling —— 支持更长上下文(32K → 256K → 1M+)
- Total Parameter Scaling —— 更大总参,更高稀疏度(80B总参,仅激活3B)
Qwen3-Next 就是为此而生的新一代架构 —— 在训练成本仅为Qwen3-32B的9.3% 的前提下,实现性能持平甚至超越旗舰模型Qwen3-235B,推理吞吐提升10倍以上。
用1/10的成本,实现10倍的推理效率,性能不降反升 —— 这就是Qwen3-Next的“性价比奇迹”。
二、模型架构四大核心创新
1️⃣ 混合注意力机制:Gated DeltaNet + Gated Attention
传统注意力瓶颈:标准Attention(O(n²))慢,线性Attention(如Mamba)召回弱。
Qwen3-Next 解法:3:1 混合架构
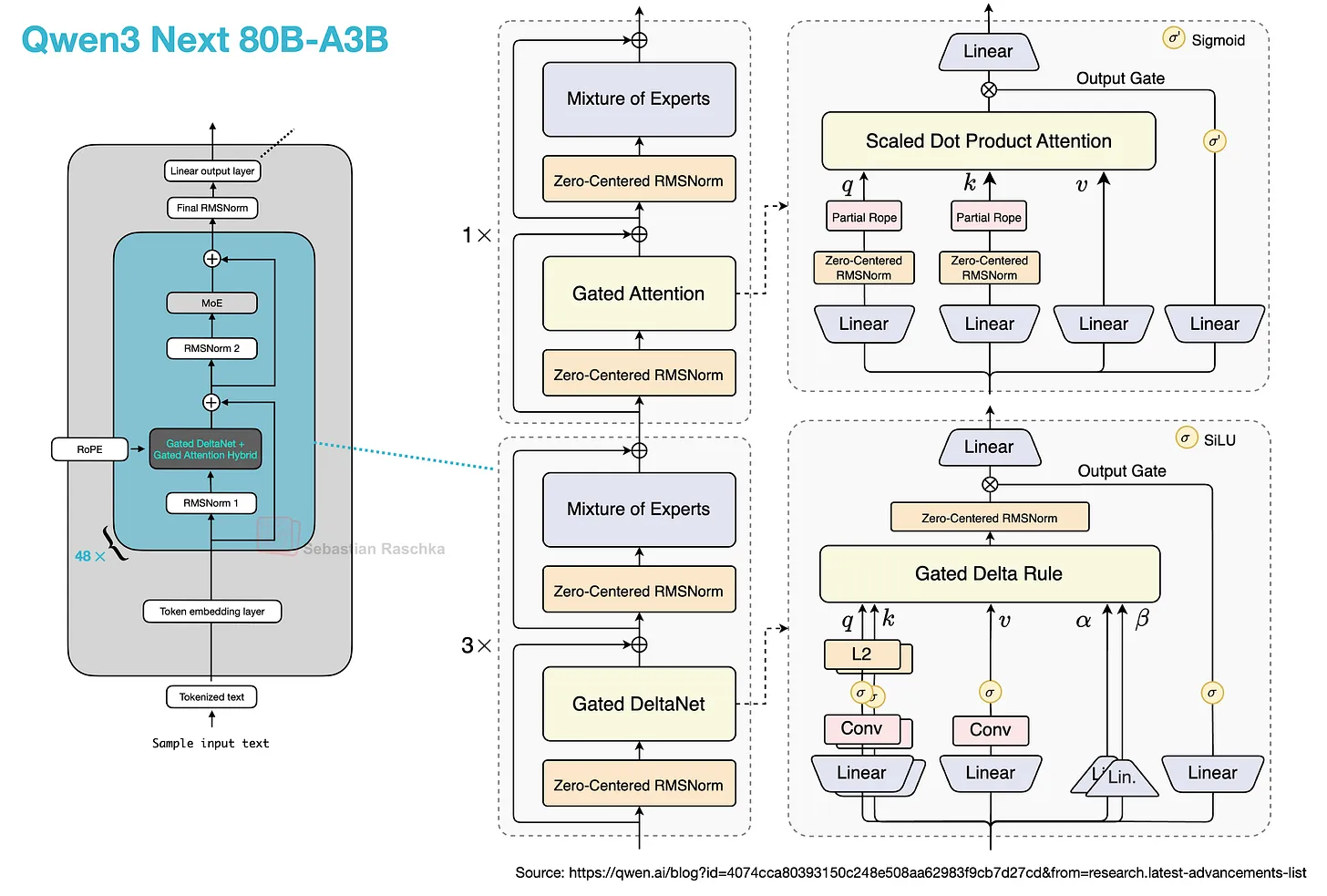
| 组件 | 占比 | 优势 | 优化细节 |
|---|---|---|---|
| Gated DeltaNet | 75% | 高效长序列建模,强ICL能力 | 替代滑动窗口/Mamba2 |
| Gated Attention | 25% | 保留强召回能力,增强局部聚焦 | 输出门控 + 头维256 + 局部RoPE |
实验结论:混合架构 > 单一架构(无论纯Attention或纯线性)
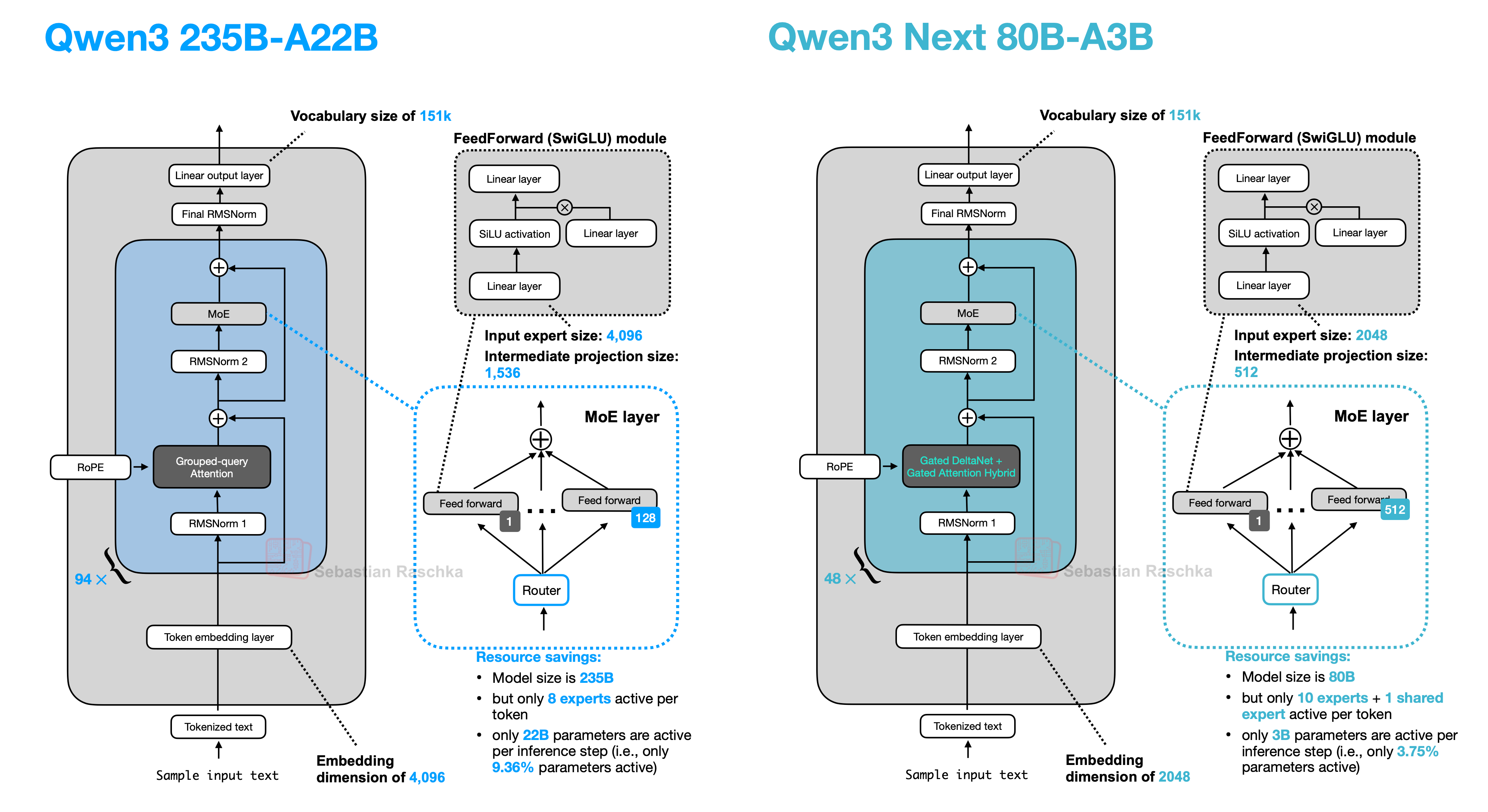
2️⃣ 极致稀疏 MoE:80B总参,仅激活3B(3.7%)
| 模型 | 总专家数 | 激活专家数 | 共享专家 | 稀疏度 |
|---|---|---|---|---|
| Qwen3-MoE | 128 | 8 | ❌ 无 | 6.25% |
| Qwen3-Next | 512 | 10+1 | ✅ 有1个 | 3.7% |
创新点:
- 专家总数↑ → 总参↑ → 能力↑
- 激活专家数微增 → 成本可控
- 引入1个共享专家 → 稳定训练 + 通用能力兜底
- 全局负载均衡损失 → 专家利用率↑,避免“专家躺平”
3️⃣ 训练稳定性优化:从Norm到初始化
| 问题/改进类型 | Qwen3(存在问题) | Qwen3-Next(改进方案) | 效果 |
|---|---|---|---|
| Norm 相关问题 | 部分层 Norm Weight 异常高 → 导致数值不稳定 ❌ | • Zero-Centered RMSNorm → 中心化归一化,稳定梯度 • Norm Weight 加权衰减 → 防止权重无界增长 ✅ |
训练更稳定,收敛更快,实验可复现性提升 ↑ |
| MoE Router 初始化 | (隐含问题:专家启动偏差) | • Router 参数初始化归一化 → 专家公平启动,减少偏差 ✅ | 专家利用率更均衡,训练初期更稳定 |
4️⃣ 多Token预测(MTP):推理加速的秘密武器
类似“投机解码”,但原生集成,训练推理一致。
优势:
- 提升 Speculative Decoding 接受率
- 优化 多步推理性能
- 主干模型性能同步提升(不只是加速模块)
支持框架:SGLang / vLLM(需指定
--speculative-algo NEXTN)
Qwen3 与 Qwen3-Next 架构与改进对比总表
| 模型类型 | 型号 | Qwen3 原始架构 / 问题 | Qwen3-Next 改进措施 | 效果 / 优势 |
|---|---|---|---|---|
| Dense(密集模型) (6 个) |
Qwen3-0.6B Qwen3-1.7B Qwen3-4B Qwen3-8B Qwen3-14B Qwen3-32B |
架构继承 Qwen2.5: • Grouped Query Attention (GQA) • SwiGLU 激活函数 • RoPE • RMSNorm + Pre-normalization 关键问题: • ❌ 移除 QKV-bias • ❌ 部分层 Norm Weight 异常高 → 数值不稳定 |
• ✅ Zero-Centered RMSNorm → 中心化归一化,稳定梯度 • ✅ Norm Weight 加权衰减 → 防止权重无界增长 • ✅ 新增 QK-Norm → 提升训练稳定性 |
• 训练更稳定 • 收敛更快 • 实验可复现性 ↑ |
| MoE(混合专家模型) (2 个) |
Qwen3-30B-A3B Qwen3-235B-A22B |
架构基础: • 沿用 Qwen2.5-MoE 细粒度专家分割 • 每 token 激活 8 专家(128 专家池) 关键问题: • ❌ 无共享专家 → 专家必须高度专业化(易失衡) • ❌ Router 初始化未归一化 → 专家启动偏差 • ❌ 部分层 Norm Weight 异常高 → 数值不稳定 |
• ✅ 全局负载均衡损失 → 避免专家“偷懒” • ✅ Router 参数初始化归一化 → 专家公平启动,减少偏差 • ✅ Zero-Centered RMSNorm + Norm Weight 衰减(同 Dense) |
• 专家利用率更高且均衡 • 训练初期更稳定 • 以更少激活参数实现更高任务性能 • 整体训练稳定性与可复现性显著提升 |
三、预训练:15T Token,10倍效率提升
| 指标 | Qwen3-32B | Qwen3-Next-80B-A3B | 提升幅度 |
|---|---|---|---|
| 预训练Token | 36T | 15T(子集) | ↓ 58% |
| GPU Hours | 100% | 9.3% | ↓ 90.7% |
| 激活参数(Non-Emb) | 32B | 3B | ↓ 90.6% |
| 性能表现 | Baseline | 持平或略优 | ✅ |
更少数据 + 更少计算 + 更少激活参数 = 更优性能 → 架构创新碾压暴力堆料。
四、推理效率:长上下文吞吐提升10倍+
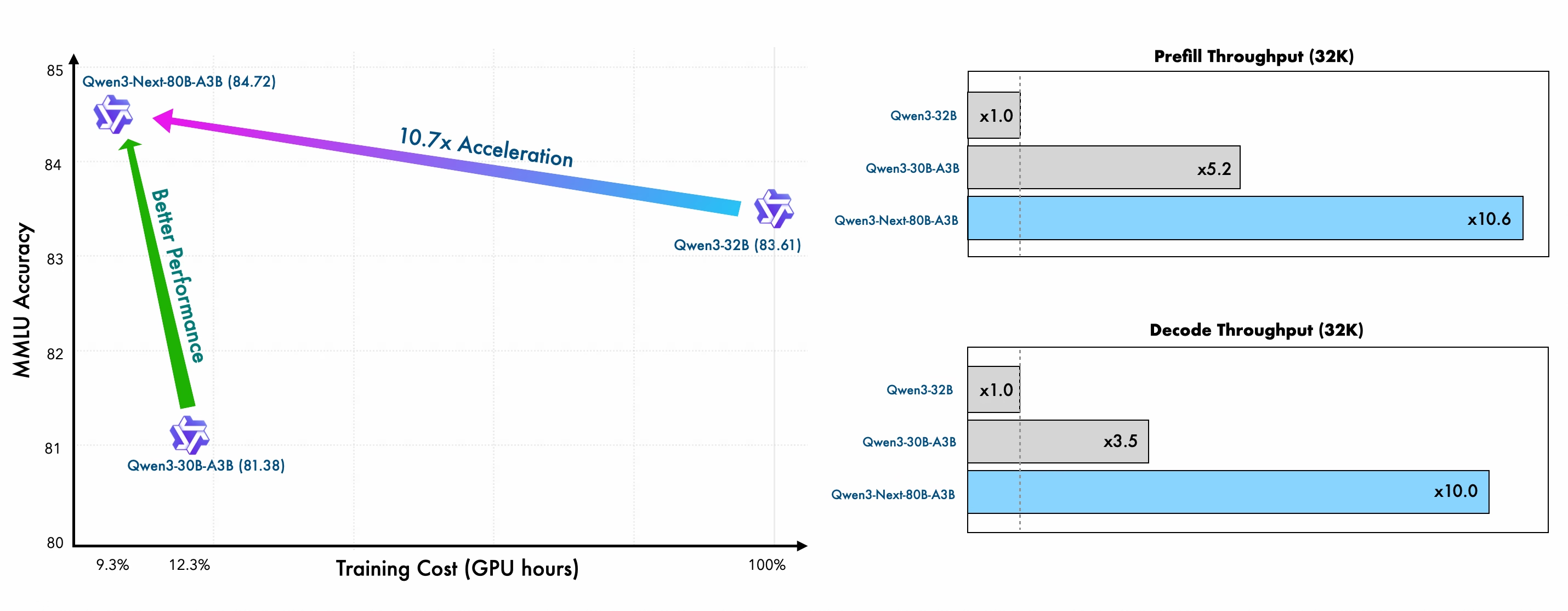
Prefill阶段(输入处理)
| 上下文长度 | 吞吐提升 vs Qwen3-32B |
|---|---|
| 4K | 7x |
| >32K | 10x+ |
Decode阶段(输出生成)
| 上下文长度 | 吞吐提升 vs Qwen3-32B |
|---|---|
| 4K | 4x |
| >32K | 10x+ |
关键价值:真正实现长文档、长对话、长代码的实时交互体验。
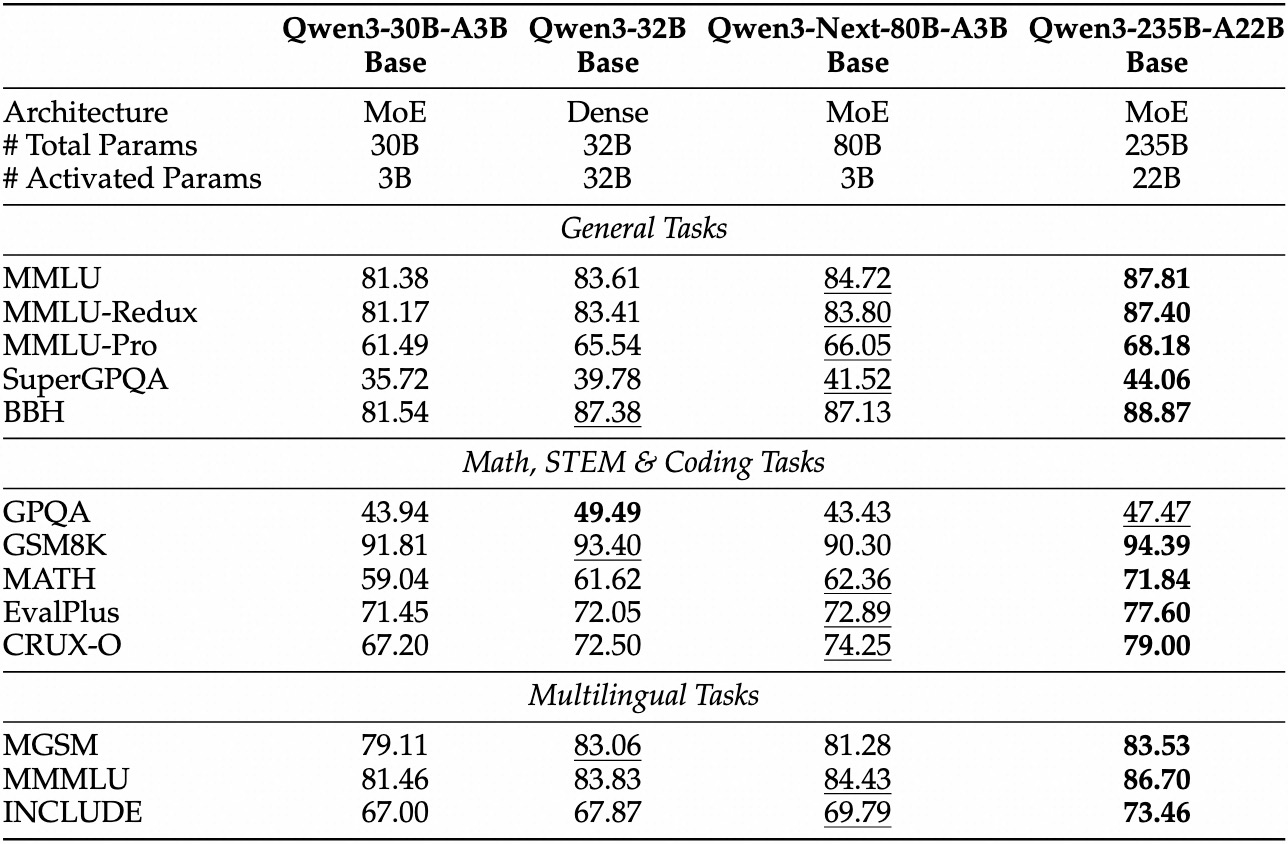
五、模型性能:小身材,大能量
Base模型:Qwen3-Next-80B-A3B-Base
- 激活参数仅为Qwen3-32B的1/10
- 性能全面超越Qwen3-32B-Base & Qwen3-30B-A3B
Instruct模型:媲美235B旗舰
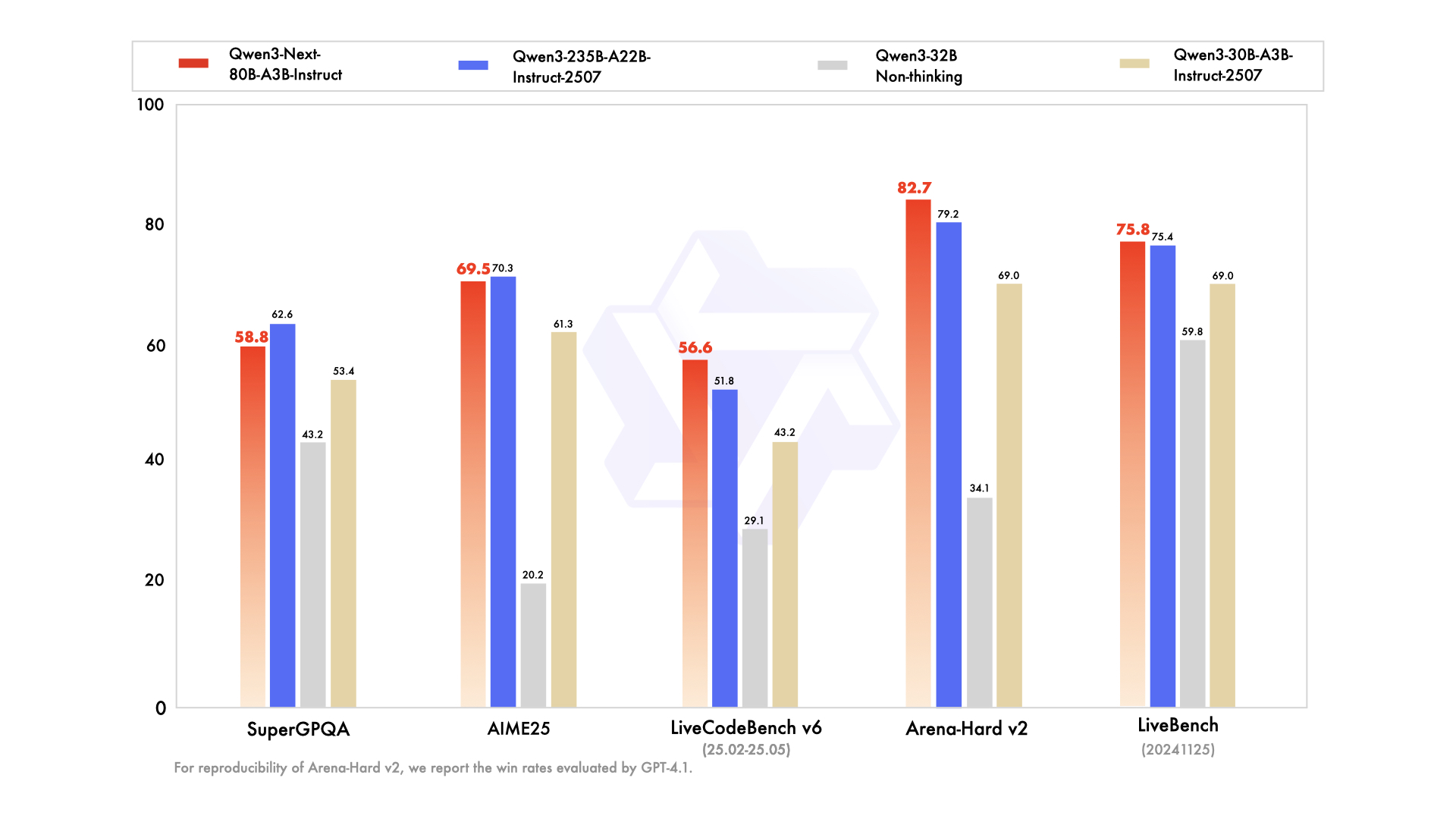

| 模型 | RULER(长上下文) | 通用能力 | 256K表现 |
|---|---|---|---|
| Qwen3-30B-A3B-Instruct-2507 | ❌ 较弱 | 中等 | 不支持 |
| Qwen3-235B-A22B-Instruct-2507 | ✅ 强 | 极强 | ✅ 支持 |
| Qwen3-Next-80B-A3B-Instruct | ✅ 更强 | ✅ 持平 | ✅ 超越235B |
在256K长上下文任务中,80B稀疏模型 > 235B稠密模型 → 混合注意力架构的绝对优势。
Thinking模型:推理能力逼近旗舰,超越Gemini
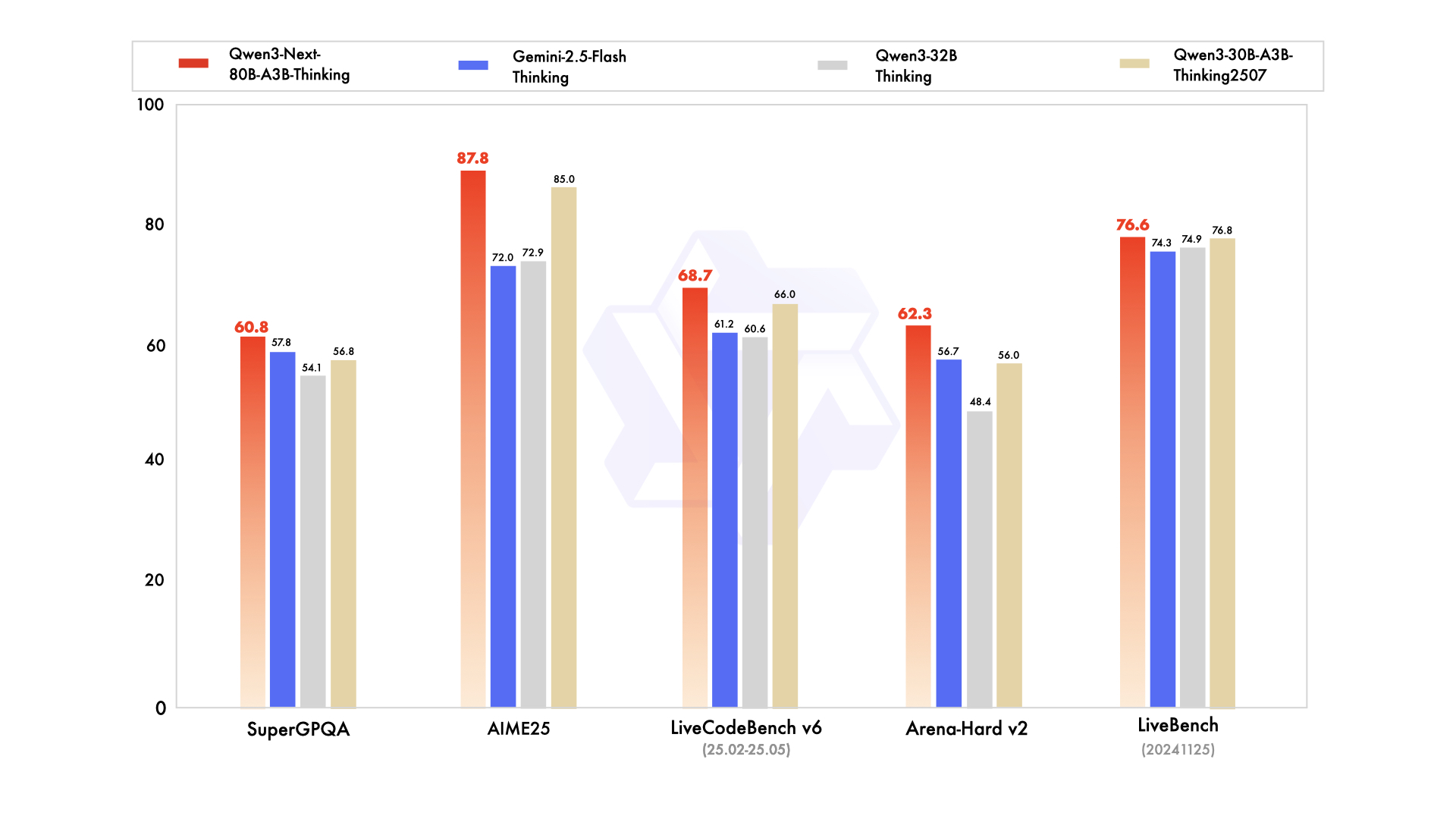
| 模型 | 数学/代码/推理能力 | 对比Gemini-2.5-Flash-Thinking |
|---|---|---|
| Qwen3-30B/32B-Thinking | 中等 | ❌ 落后 |
| Gemini-2.5-Flash-Thinking | 强 | — |
| Qwen3-235B-A22B-Thinking-2507 | 极强 | ✅ 超越 |
| Qwen3-Next-80B-A3B-Thinking | 极强 | ✅ 超越 |
在多项基准测试中逼近235B旗舰,部分指标反超闭源Gemini。
六、开始使用:开源 + 云服务 + 智能体
1️⃣ Hugging Face(Transformers)
pip install git+https://github.com/huggingface/transformers.git@main
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-Next-80B-A3B-Instruct",
device_map="auto",
torch_dtype="auto"
)
注意:当前Transformers不支持MTP,建议用SGLang/vLLM。
2️⃣ 高性能推理:SGLang / vLLM
SGLang(推荐用于MTP)
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 \
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--speculative-algo NEXTN \
--speculative-num-steps 3
vLLM
pip install git+https://github.com/vllm-project/vllm.git
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
3️⃣ 智能体开发:Qwen-Agent
from qwen_agent.agents import Assistant
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
}
tools = ['code_interpreter', {'mcpServers': {...}}]
bot = Assistant(llm=llm_cfg, function_list=tools)
内置工具调用模板 + 解析器,智能体开发效率提升10倍。
4️⃣ 超长上下文(>256K):启用YaRN缩放
方法一:修改 config.json
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
方法二:启动参数(vLLM示例)
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' \
--max-model-len 1010000
注意:仅在需要时启用,避免影响短文本性能。
七、总结:Qwen3-Next 的划时代意义
| 维度 | Qwen3 | Qwen3-Next | 革命性提升 |
|---|---|---|---|
| 架构 | 标准Attention + MoE | 混合Attention + 高稀疏MoE | 效率↑ 性能↑ 稳定性↑ |
| 成本 | 高训练成本 | 训练成本仅9.3% | 开源模型训练门槛↓ |
| 推理 | 长上下文效率低 | >32K吞吐提升10倍 | 实时长文档交互成为可能 |
| 性能 | 235B为旗舰 | 80B媲美235B,部分超越 | 小模型干翻大模型 |
| 生态 | 开源 | 开源 + 云服务 + 智能体 + MTP支持 | 全栈开发者友好 |
Qwen3.5 正在路上
Qwen团队表示将持续优化Qwen3-Next架构,开发Qwen3.5,目标:
- 更高智能水平
- 更强生产力工具
- 更深智能体集成
- 更广多模态支持
Qwen3-Next 不是升级,是重构 —— 它重新定义了“高效大模型”的标准:
更低的成本,更高的性能,更长的上下文,更快的推理。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)