网络爬虫/网页抓取工具 (Web Scraping Tools)
网络爬虫/网页抓取工具 (Web Scraping Tools)
广泛应用的数据采集助手
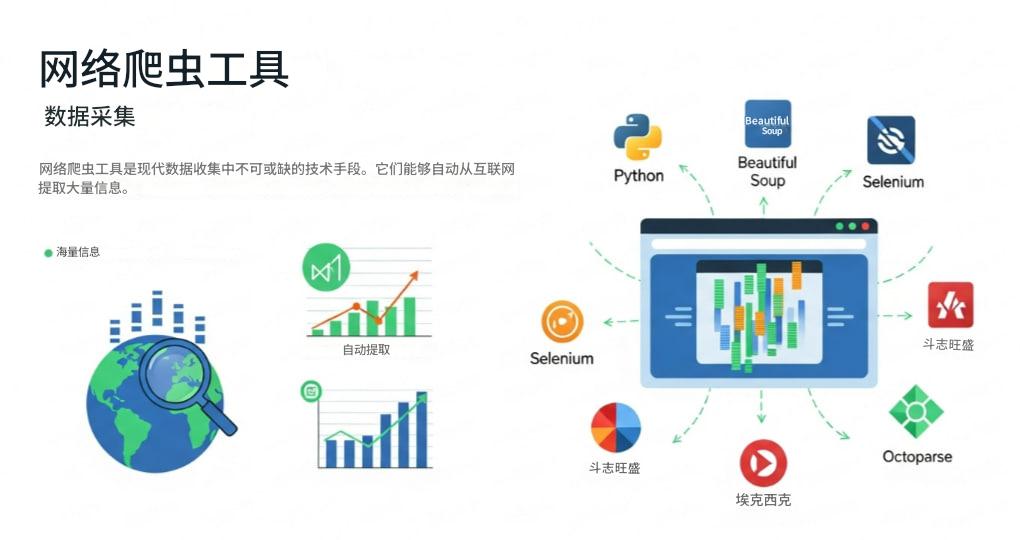
网络爬虫/网页抓取工具是现代数据时代的重要基础设施,它们能够自动化地从互联网上收集海量信息。这些工具通过模拟人类浏览网页的行为,将网页中的非结构化数据(如文本、图片、链接等)转化为结构化数据,便于后续分析。无论是市场调研、舆情监测,还是学术研究,这些工具都发挥着不可替代的作用。它们可以抓取社交媒体的动态、电商平台的商品信息、新闻网站的报道,甚至学术论文的摘要,为各类决策提供数据支持。随着互联网数据的爆炸式增长,这类工具的需求也日益旺盛,成为企业和研究机构不可或缺的技术手段。
技术实现与工作方式
网络爬虫的核心原理是通过HTTP请求获取网页内容,然后解析HTML文档,提取所需数据。开发者通常会使用Python等编程语言,结合如requests、BeautifulSoup或lxml等库来实现这一过程。高级框架如Scrapy则提供了更强大的功能,包括异步处理、中间件管理、分布式爬取等,能够应对复杂的数据抓取需求。许多工具还内置了代理IP轮换、用户代理随机化、验证码识别等功能,以应对目标网站的反爬机制。这些技术手段确保了爬虫在高效抓取数据的避免被封禁或干扰目标网站的正常运行。
实际工具与解决方案
在实际应用中,有多种网络爬虫工具可供选择。Scrapy是一个功能强大的开源框架,适合开发者构建定制化的爬虫项目,尤其适用于大规模数据采集。Bright Data则提供专业的代理网络和爬取服务,能够处理高并发请求和复杂的反爬策略,适合企业级用户。八爪鱼采集器是一款面向非技术用户的设计,通过可视化界面操作,内置大量模板,简化了数据抓取流程。Apify平台支持多种编程语言,并提供云端部署选项,方便用户快速启动和扩展爬虫任务。ScraperAPI则专注于解决反爬问题,通过自动处理代理、验证码等障碍,让用户无需关注底层技术细节。
多领域价值与影响
网络爬虫工具在多个领域展现出巨大价值。在商业领域,它们帮助企业监控竞争对手的价格和产品信息,优化营销策略;在媒体领域,它们用于收集新闻标题和摘要,构建舆情分析系统;在科研领域,它们为学者提供学术文献的元数据,加速研究进程。这些工具还支持个人开发者快速获取数据,用于训练机器学习模型或构建个人项目。使用这些工具时也需遵守法律和道德规范,避免侵犯网站版权或违反robots协议,确保数据采集的合法性与合理性。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)