AI问数:幻想的破灭与落地重生
支持markdown和Json格式数据的传入【主要是接收数据库数据】支持Excel文件的直接传入,并且支持多Excel,多Sheet的数据读取和运算具备强大的运算功能,运算结果100%准确(解决了大模型运算不准的问题),可根据用户设定规则、问数需求进行分析运算,并输出运算后的markdown表格信息,可同时生成多个不同维度的运算结果表可生成可视化的图表,柱状图,饼状图,折线图,雷达图,散点图,漏斗

AI问数是一个很热门的AI应用场景,之所以热门,是因为AI自然语言交互与内容生成的能力打开了人们的想象空间:如果AI和数据库链接,通过自然语言对话理解人类意图,生成sql查询数据,那岂不是想查什么数据就查什么数据,想要AI怎么分析就怎么分析吗,于是人们怀揣着希望,怀揣着对AI数据分析场景颠覆的梦想出发了。
现实困境
但现实却给出了残酷的一击,AI问数毕竟是B端场景,C端的AI通用大模型无法理解B端的业务逻辑,难以有效理解人们的查询意图,分析意图,离人们开始的想象差了十万八千里。
不少厂商在这一块付出了诸多的努力,比如RAG背景知识补充,语义指标设定,元数据,知识图谱关联等,然后又会遇到企业数据表结构混乱,数据不精准,缺乏数据治理等等问题,甚至看到大家开玩笑的说:人工智能,越人工,越智能。

回到现实,目前我们所看到的场景,其本质是:想通过各类工具手段,来增强大模型的能力,弥补其对企业内业务理解不深刻,行话不清楚,表结构关联不知道的问题。基本上都是这个思路,而这个思路,很像是徒劳,因为意图理解在AI大模型本身,外物只能辅佐,不能改变。
重生之路
那是否AI问数就没有出路了呢?其实不然,AI问数依然是一个非常优秀的AI应用场景,但在目前,他似乎承担了很多的不堪承受之重。今天,我想从另一个角度来和大家聊聊这件事,AI问数幻想泡沫破灭之后的重生之路。
AI问数一直是被裹挟着往前走的,因AI在C端带给人们的惊人效果,让人们把AI问数给架在了天上,对场景的理解是直接建立在C端AI能力之上的,通过自然语言交互实现数据分析,想怎么问就怎么问,直接跳过了实际需求层面,现在,让我们回归本质。
需求层面的思考
1、伪需求的识别
在实际的AI问数落地项目中,是不需要做到想问啥就问啥的,这是个伪需求,他往往来源于我们自己的想象或者甲方的想象,经常有朋友向我吐槽,说老板的要求太高了,他认为AI就是万能的,就要做到想问啥就问啥。

我就笑笑和朋友说:就算AI是万能的吧,你假设一个极端场景:你真的做出来了想问啥就问啥的AI问数应用,你们的业务环节你自己清楚的,有哪些数据你也清楚的,那么现在站在老板的视角,他拿到手之后,他会问哪些问题,他真的会去问吗,或者拿到后他是否问个几次玩玩之后满足好奇心和虚荣心之后又了然无趣的甩到一边了呢。
朋友陷入了沉思,毕竟企业内大部分环节已相对固定,数据内容也就那些,具体的场景边界是什么呢?这里说明了一个关键的问题,站在落地的角度,不能为了AI而AI,他的出现能解决哪些问题才是关键。
2、核心价值定位
AI问数的核心价值,对于用户而言,在方便,在快,在门槛低,比如通过Dify这类平台可快速搭建问数chatflow,可按不同的维度取数分析,生成图表,输出分析文本等,也不用像以前一样总是等待IT人员花费几个月才能看到可视化的页面,这是他的优势,而不是在天马行空的能力上。
3、场景扩展
对用户而言,AI问数并不单单是数据库接入的场景,还有和Excel对话的能力,企业内各岗位人员也有着大量的Excel数据,这些数据也非常关键,我们无法保证所有的数据都在系统之内,所以对AI问数的理解不应该只限定在和数据库的交互上,ChatExcel也是关键场景。
4、深度分析需求
对用户真正有用的数据,是那些隐藏在背后,肉眼无法直接看到的数据,是需要通过运算而得出,通过指标来对比好与坏的数据,所以,要想AI问数产生价值,就绝不能仅仅局限于从数据库取数,而是要基于业务进行深度的数据运算分析。
落地实践层面
1、业务理解的重要性
大部分IT人员在企业内做AI问数的时候,都有一个非常真实的现象,你花精力梳理了表结构,做了字段说明,打通了从nl2sql,再到执行取数,到分析的全过程,做出来了AI问数,但业务人员却没啥兴趣用,还总抱怨说问的东西都答不出来,你看着业务人员问的那些率,指标,里想这怎么可能回答的出来。
我一直认为:AI技术的出现,不代表业务场景需求理解的降维。AI问数做不好,80%是对AI能力边界没理解,缺少业务场景边界限定及业务理解的深度。不知道用户什么场景,不知道用户想问什么,想通过AI,技术来弥补这一层,这是不可能的。

2、系统性工程思维
AI问数的落地是系统性工程:
-
调研
-
业务场景理解
-
问数场景边界
-
语义分析转换
-
准确性保障
-
定制开发
-
测试验证
-
落地交付
一项都不可以少,正如前面所讲,不会因为AI技术的出现而改变了项目成功的关键步骤,AI只是其中一环。
3、务实的数据处理
对大部分企业而言,是没有必要去做所谓的数据治理的,把用户的数分场景摸清楚,想问的,在意的调研清楚,对数据库做一些实实在在的可用的视图就可以了,真的没有必要大张旗鼓的搞什么数据治理,千万不要用技术能力来弥补业务场景调研的缺失。
4、三阶段分离策略
整个AI问数分为:
-
取数
-
运算
-
分析
三个大阶段,大部分的方案将这三个融合到一个nl2sql上面,这也是AI问数效果不佳的关键原因之一,如果把取数,运算,分析分为三个阶段各司其职,那么准确性会好很多。
解决方案与实践
以上是我们探究AI问数落地感受到的真实情况。
要想真正的让AI问数发挥价值,还是要抛开AI魔幻的外衣,理解AI大模型的能力边界,理解AI在这个过程中所发挥的作用,最终还是要服务于业务,理解业务场景,做好场景限定,做好语义转换,做好数据获取,做好数据运算,做好使用培训,做的广,不如做的专。
也许,AI问数场景在经历了高期望的幻想破灭之后,才会迎来他真正的繁荣期,务实的,落地的,把AI能力结合到问数的场景中,让不会sql的人,也可以方便的从数据库中获取到数据,让不会数据分析的人也可以轻松的得到分析结果,让不会操作Excel的人,也能通过AI轻松完成数据处理工作。
所以,我们在AI问数落地的时候会更加注重应用场景和需求,借助AI的能力构建有效的AI问数工具,解决用户的核心痛点。
1、核心落地思路
在落地层面,我们的核心思路为:
-
要支持sql数据的传入,也要支持Excel数据的传入
-
把取数,运算,分析三个阶段分开处理
-
把运算作为核心,植入基于业务需求的核心运算规则,给出运算结果
-
要能生成可视化图表和文本分析结果
-
考虑到数据隐私,完全本地化,私有化,不调用任何外部的MCP和API接口
以此为核心思想,在实际落地项目中经过3个月,累计12个版本的迭代研发,我们基于Dify打造了一个可灵活自定义的轻量级方案,完成了我们数据分析本地版插件的开发,支持各类AI深度问数场景的构建。
一个支持数据库数据,支持Excel数据,支持各类复杂运算的插件诞生了。
下面是数据分析<本地版>插件的参数配置页面
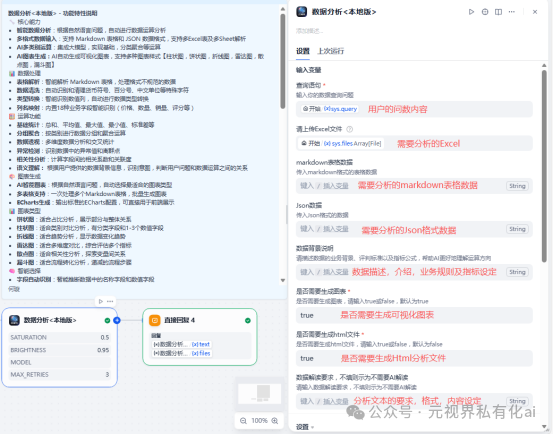
2、核心功能介绍
-
支持markdown和Json格式数据的传入【主要是接收数据库数据】
-
支持Excel文件的直接传入,并且支持多Excel,多Sheet的数据读取和运算
-
具备强大的运算功能,运算结果100%准确(解决了大模型运算不准的问题),可根据用户设定规则、问数需求进行分析运算,并输出运算后的markdown表格信息,可同时生成多个不同维度的运算结果表
-
可生成可视化的图表,柱状图,饼状图,折线图,雷达图,散点图,漏斗图等,可同时生成多个图表
-
可生成分析结果,并支持设定输出规则,格式,重点内容等
-
可输出Html文件,通过精美的页面呈现运算结果,可视化图表,分析文本
3、案例演示
案例演示:公安话单分析
AI问数
案例演示:跨表同比数据运算
案例演示:跨表同比数据运算
商业化价值
对于AI的问数场景构建,需求和场景依然很多,市面上软件厂商的收费都很高,动辄都是几十万一年,还不一定能达到效果。大部分个人,企业的ai问数场景完全没有必要去花费那么大的价钱,并且大部分的问数场景都需要结合自己的业务场景设定指标定义达到深度的问数效果,那我们这样一个,允许企业/个人自行进行二次开发的轻量级方案就非常适合企业内的ai问数场景构建,并且目前的功能已经非常强大了,我们解决了大模型算数不准的问题,具备意图理解,指标设定,能运算,能分析,还可以生成可视化图表,可轻松构建基于数据库,或者excel的智能问数,最重要的,他是纯本地的,没有任何的外部api链接,不存在数据安全方面的问题,是真正的企业Ai智能问数神器!
经过我们团队内部讨论之后,为进一步推动ai深度问数应用的落地覆盖,我们决定对外公开,并且准备了以下内容。
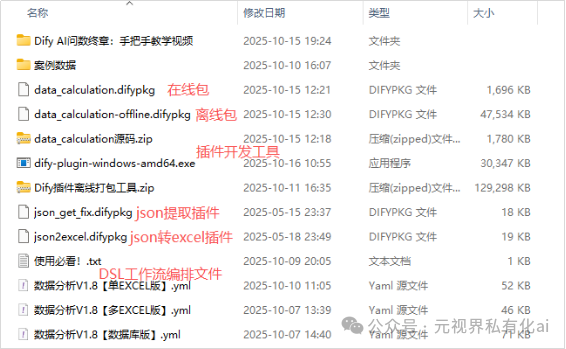
开放策略
考虑到要完全达到你企业所需的深度AI问数场景效果,肯定是需要二次开发的,所以我们直接开放了源码,并提供了一整套的手把手从插件调试,环境配置,插件安装,场景搭建,源码二开,插件打包的教程。

无论你是个人学习,还是在工作中提升效率,还是想在企业内搭建问数智能体,这一套工具和教程完全可以满足。
但同时考虑到,为了防止我们的插件工具被滥用,我们仅对外公开30份,希望能提供给真正有需要的小伙伴和企业。
更多的功能/案例介绍及获取方式请看以下视频:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)