【智能体】一文掌握Agentic AI,值得收藏。
一文掌握Agentic AI
Agentic AI详解
1、 Agentic AI 概述与核心概念
Agentic AI(代理式人工智能)代表了人工智能领域的一次范式转变,其核心在于自主性与主动性。
与传统AI系统仅被动响应指令不同,Agentic AI系统能够理解用户目标、自主制定计划并执行行动,无需人类持续引导。
1.1 定义与演进路径
Agentic AI 的演进经历了三个明显阶段:
- 生成式AI阶段:以ChatGPT为代表的生成模型,具备强大的内容创造能力但缺乏自主行动力
- AI智能体阶段:集成外部工具调用、函数执行与序列推理,能够完成多步骤工作流
- 代理式AI阶段:由多个专职智能体组成,通过协作分解任务、通信协调实现复杂目标
1.2 核心能力特征
Agentic AI 系统的三大核心能力包括:
- 规划能力:将高层次目标分解为连贯的多步策略,并动态调整执行路径
- 工具使用:调用与协调外部资源,如API、数据库或其他模型,扩展系统能力边界
- 记忆机制:在长时范围内保留、检索与管理信息,维持任务执行的连贯性

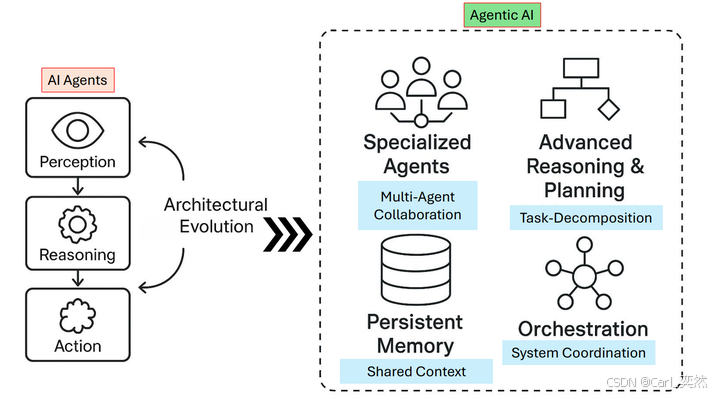
2、 Agentic AI 的技术架构与范式转变
2.1 从流水线范式到模型原生范式
2.1.1 基于流水线的范式
早期Agentic AI系统采用"流水线"架构,其核心能力由外部结构在工作流式架构中协同实现:
-
规划:依赖外部符号规划器或通过提示工程引导模型生成推理链
-
工具使用:表现为单轮或多轮函数调用框架,如ReAct的"思维-行动-观察"循环
-
记忆:通过对话摘要维持短期记忆,采用检索增强生成实现长期记忆
该范式下,智能体的策略函数为复合函数形式: π p i p e l i n e = f o r c h e s t r a t i o n ∘ π L L M π_{pipeline} = f_{orchestration} ∘ π_{LLM} πpipeline=forchestration∘πLLM,其中外部流水线对模型内部策略的输出施加约束与操控。
2.1.2 模型原生范式
新兴的模型原生范式将智能体视为单一、统一的模型,通过端到端训练学习自主执行高层次功能:
-
规划内化:通过大规模强化学习实现模型自主思考与规划,如OpenAI的o1和DeepSeek的R1
-
工具使用内化:将工具调用融入推理过程,模型学习何时以及如何调用多种工具
-
记忆内化:通过扩展原生上下文窗口和参数化记忆实现长短时记忆的内部管理
2.2 AI Agentic Mesh:企业级自治架构
AI Agentic Mesh是一种分布式智能体系统,通过标准化协议、安全身份和协调机制连接,形成企业AI的"神经系统"。其核心特征包括:
-
自治与协调:代理独立行动但在网格内受协调
-
互操作性:不同供应商的模型通过通用协议进行交互
-
治理与可观测性:身份、权限、审计跟踪和监控嵌入架构
-
可扩展性:新代理可插入或停用而不会破坏系统稳定性
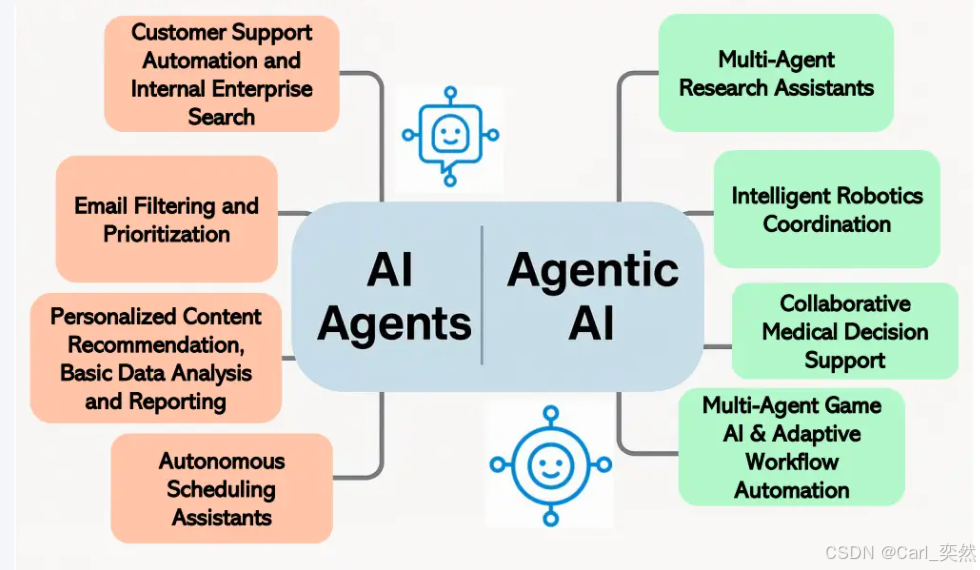
3、 Agentic AI 的关键技术栈
3.1 企业级技术栈组成
根据Uber的Agentic AI技术栈分析,企业级部署需要整合以下核心组件:
-
编排层:多代理编排,将目标分解为子任务并排序执行
-
人在回路治理:自主系统需要防护栏,人类验证关键输出
-
数据与评估管道:多模态注释、偏好数据收集和共识标记
-
测试与验证:模型评估管道、红队测试和连续监控仪表板
-
基础设施与集成:云原生和API优先的可扩展性,能够接入企业系统
3.2 算法引擎:大规模强化学习
推动Agentic AI从流水线向模型原生范式转变的核心动力是大规模强化学习在大语言模型训练中的应用。强化学习将学习从对静态数据的模仿转变为面向结果的探索,支撑了跨语言、视觉与具身领域的统一解决方案——LLM + RL + Task框架。
与传统的监督微调相比,强化学习通过探索式学习使智能体获得核心能力,无需昂贵的逐步监督,展现了在推动LLM自主演化行为策略、适应新环境方面的变革潜力。
3.3 核心架构模式与技术实现
3.3.1 规划与推理引擎
思维链(Chain-of-Thought)技术
class ChainOfThoughtReasoning:
def __init__(self, base_model):
self.model = base_model
def step_by_step_reasoning(self, problem):
reasoning_steps = []
current_state = problem
# 多步推理循环
for step in range(10): # 最大推理步数
prompt = f"""
当前问题: {current_state}
推理步骤 {step+1}: 分析当前状况,给出下一步推理
"""
reasoning = self.model.generate(prompt)
reasoning_steps.append(reasoning)
# 检查是否得出结论
if self._is_conclusion(reasoning):
break
current_state = reasoning
return reasoning_steps
def _is_conclusion(self, reasoning):
# 判断推理是否得出结论
conclusion_indicators = ["因此", "所以", "结论是", "答案是"]
return any(indicator in reasoning for indicator in conclusion_indicators)
树状搜索规划
class TreeSearchPlanner:
def __init__(self, model, max_depth=5, beam_width=3):
self.model = model
self.max_depth = max_depth
self.beam_width = beam_width
def beam_search_planning(self, initial_state, goal):
# Beam Search算法实现
beams = [([], initial_state, 0.0)] # (actions, state, score)
for depth in range(self.max_depth):
new_beams = []
for actions, state, score in beams:
# 生成可能的下一步动作
possible_actions = self._generate_actions(state)
for action in possible_actions:
# 评估动作效果
new_state = self._simulate_action(state, action)
action_score = self._evaluate_action(state, action, goal)
new_score = score + action_score
new_beams.append((actions + [action], new_state, new_score))
# 选择得分最高的beam_width个路径
beams = sorted(new_beams, key=lambda x: x[2], reverse=True)[:self.beam_width]
# 检查是否达到目标
for actions, state, score in beams:
if self._is_goal_reached(state, goal):
return actions, state, score
return beams[0] # 返回最佳路径
3.3.2 工具使用与函数调用
动态工具调度系统
class ToolUsageEngine:
def __init__(self, available_tools):
self.tools = available_tools
self.tool_registry = self._build_tool_registry()
def _build_tool_registry(self):
registry = {}
for tool in self.tools:
registry[tool.name] = {
'function': tool.execute,
'description': tool.description,
'parameters': tool.parameters,
'return_type': tool.return_type
}
return registry
def select_tool(self, task_description, context):
"""基于任务描述选择最合适的工具"""
tool_scores = {}
for tool_name, tool_info in self.tool_registry.items():
# 计算工具与任务的匹配度
relevance_score = self._calculate_relevance(
task_description, tool_info['description']
)
# 检查参数匹配度
param_match_score = self._check_parameter_match(
context, tool_info['parameters']
)
tool_scores[tool_name] = relevance_score * 0.7 + param_match_score * 0.3
best_tool = max(tool_scores.items(), key=lambda x: x[1])
return best_tool[0], tool_scores
def execute_tool_sequence(self, tool_sequence, parameters):
"""执行工具调用序列"""
results = []
execution_context = parameters.copy()
for tool_call in tool_sequence:
tool_name = tool_call['tool']
tool_params = self._resolve_parameters(
tool_call['parameters'], execution_context
)
try:
result = self.tool_registry[tool_name]['function'](**tool_params)
execution_context[f"{tool_name}_result"] = result
results.append({
'tool': tool_name,
'parameters': tool_params,
'result': result,
'success': True
})
except Exception as e:
results.append({
'tool': tool_name,
'parameters': tool_params,
'error': str(e),
'success': False
})
break
return results
3.3.3 记忆系统架构
分层记忆管理
class HierarchicalMemorySystem:
def __init__(self, embedding_model, vector_store):
self.embedding_model = embedding_model
self.vector_store = vector_store
self.memory_hierarchy = {
'episodic': [], # 情景记忆
'semantic': [], # 语义记忆
'procedural': [] # 程序性记忆
}
def store_memory(self, content, memory_type='episodic', metadata=None):
"""存储记忆到相应层次"""
memory_entry = {
'content': content,
'type': memory_type,
'timestamp': datetime.now(),
'embedding': self.embedding_model.encode(content),
'metadata': metadata or {}
}
self.memory_hierarchy[memory_type].append(memory_entry)
# 向量化存储用于检索
self.vector_store.add(
vectors=[memory_entry['embedding']],
metadata=[{
'type': memory_type,
'content': content,
'timestamp': memory_entry['timestamp']
}]
)
def retrieve_relevant_memories(self, query, top_k=5, memory_types=None):
"""检索相关记忆"""
query_embedding = self.embedding_model.encode(query)
# 从向量存储检索
results = self.vector_store.query(
query_embeddings=[query_embedding],
n_results=top_k
)
# 按记忆类型过滤
if memory_types:
filtered_results = [
r for r in results
if r['metadata']['type'] in memory_types
]
else:
filtered_results = results
return self._rank_memories(filtered_results, query)
def _rank_memories(self, memories, query):
"""基于相关性和时效性对记忆排序"""
ranked_memories = []
for memory in memories:
# 计算相关性分数
relevance_score = self._calculate_relevance(
memory['metadata']['content'], query
)
# 计算时效性分数(越新分数越高)
recency_score = self._calculate_recency(
memory['metadata']['timestamp']
)
total_score = relevance_score * 0.8 + recency_score * 0.2
ranked_memories.append((memory, total_score))
return sorted(ranked_memories, key=lambda x: x[1], reverse=True)
4、 Agentic AI 的应用场景与实施案例
4.1 零售业:利物浦百货的Agentic AI购物体验
墨西哥最大的百货公司利物浦将Agentic AI融入日常购物体验,适应消费者从"搜索浏览"向"提问决策"的转变。其系统特点包括:
-
全周期交互:客户可提问、获得答案并在同一流程中完成购买
-
运营效率:通过集成agentic系统,创建新的"代理渠道"
-
品牌控制与合规:确保AI代理在执行交易时正确代表品牌
4.2 金融业:劳埃德银行的AI金融助手
劳埃德银行集团正在其移动应用中试点AI驱动的金融助手,定位为24/7的"财务伴侣",提供个性化辅导、支出洞察以及储蓄和投资指导。技术特点包括:
-
分解请求:使用Agentic AI分解请求、规划行动并使用工具执行任务
-
内存功能:提供更全面的体验并确保安全、受控的行为
-
强大防护:在银行应用的安全环境中依赖策划的银行数据
5、 Agentic AI 的挑战与限制
5.1 核心技术瓶颈
- 幻觉累加问题:在智能体链式调用中,单一环节的错误会被后续步骤引用,导致错误在任务链条中被不断放大
- 工具调用与环境适应能力弱:在多个工具的组合调度、异常处理、上下文状态保持等方面缺乏足够的智能
- 泛化与迁移能力不足:大多数Agent仍属于"精调+特定场景设定"下的窄域应用,难以跨任务、跨领域灵活迁移
- 长期记忆机制不完善:依赖短时上下文窗口,缺乏对用户长期行为、历史任务链的持久记忆能力
5.2 市场与技能挑战
当前AI代理工具市场面临"选择悖论",过多的工具选项导致决策瘫痪。据Gartner报告,“目前的代理AI模型、平台和产品供应已经超过需求”,且行业面临技能差距。
AI代理工具的定价被描述为"不透明、不可预测且不足以覆盖提供商成本",与客户期望的"简单、可预测且与业务价值挂钩"的定价之间存在脱节。
6、 总结
Agentic AI 代表了人工智能从“工具”向“助手”的范式转变,其核心在于自主决策、动态反馈和多模态交互能力。
通过掌握主流框架与工具、设计合理的提示工程、构建安全可靠的系统,开发者可以构建出真正具备自主能力的智能体,为各行各业带来变革性影响。
我是小鱼:
- CSDN 博客专家;
- AIGC 技术MVP专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)