Meilisearch — Rust 打造的轻量级搜索新锐
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个 "开箱即用" 的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供 “所见即所得” 的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'
2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'
3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'
4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'
返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}
注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
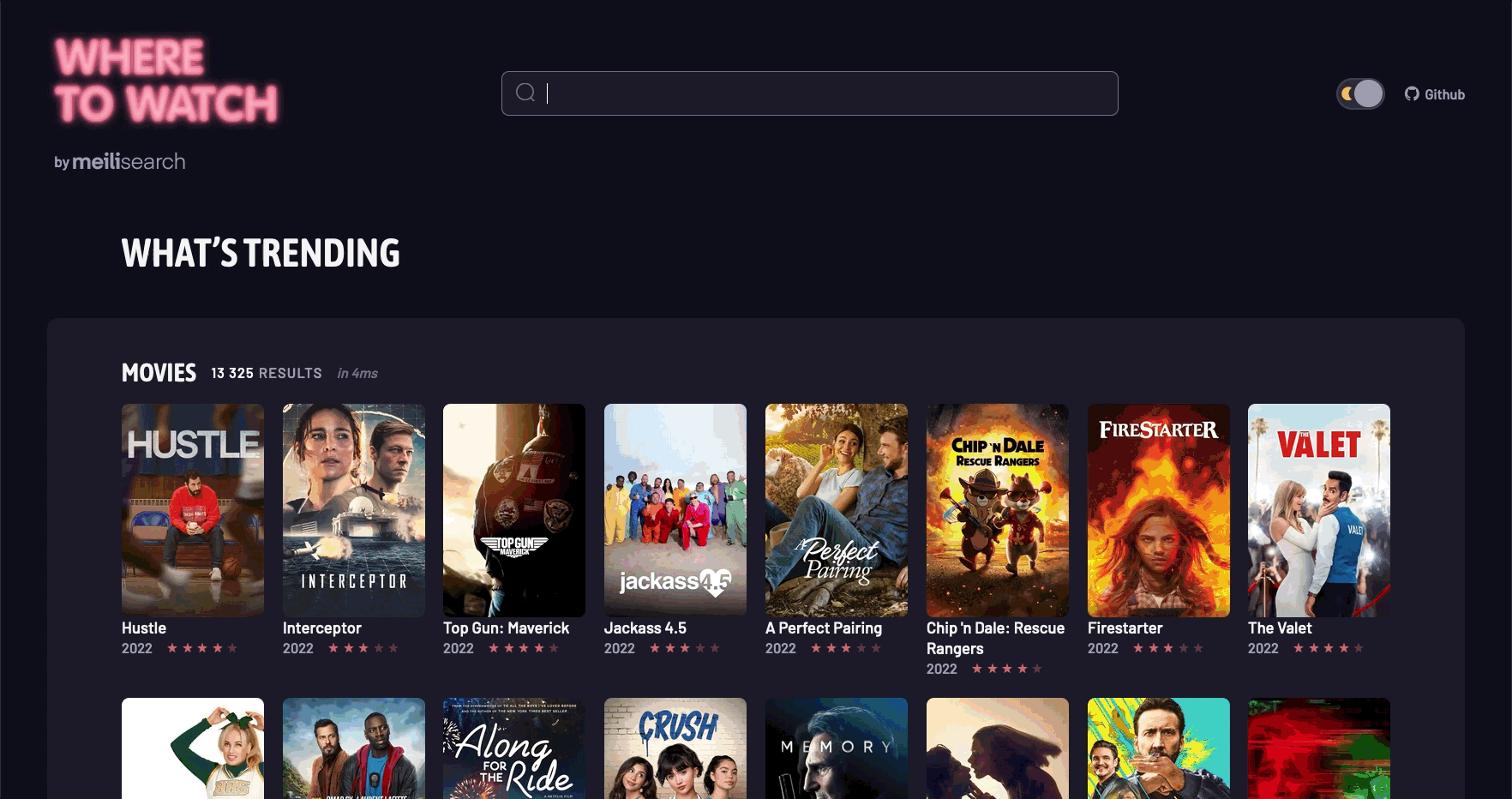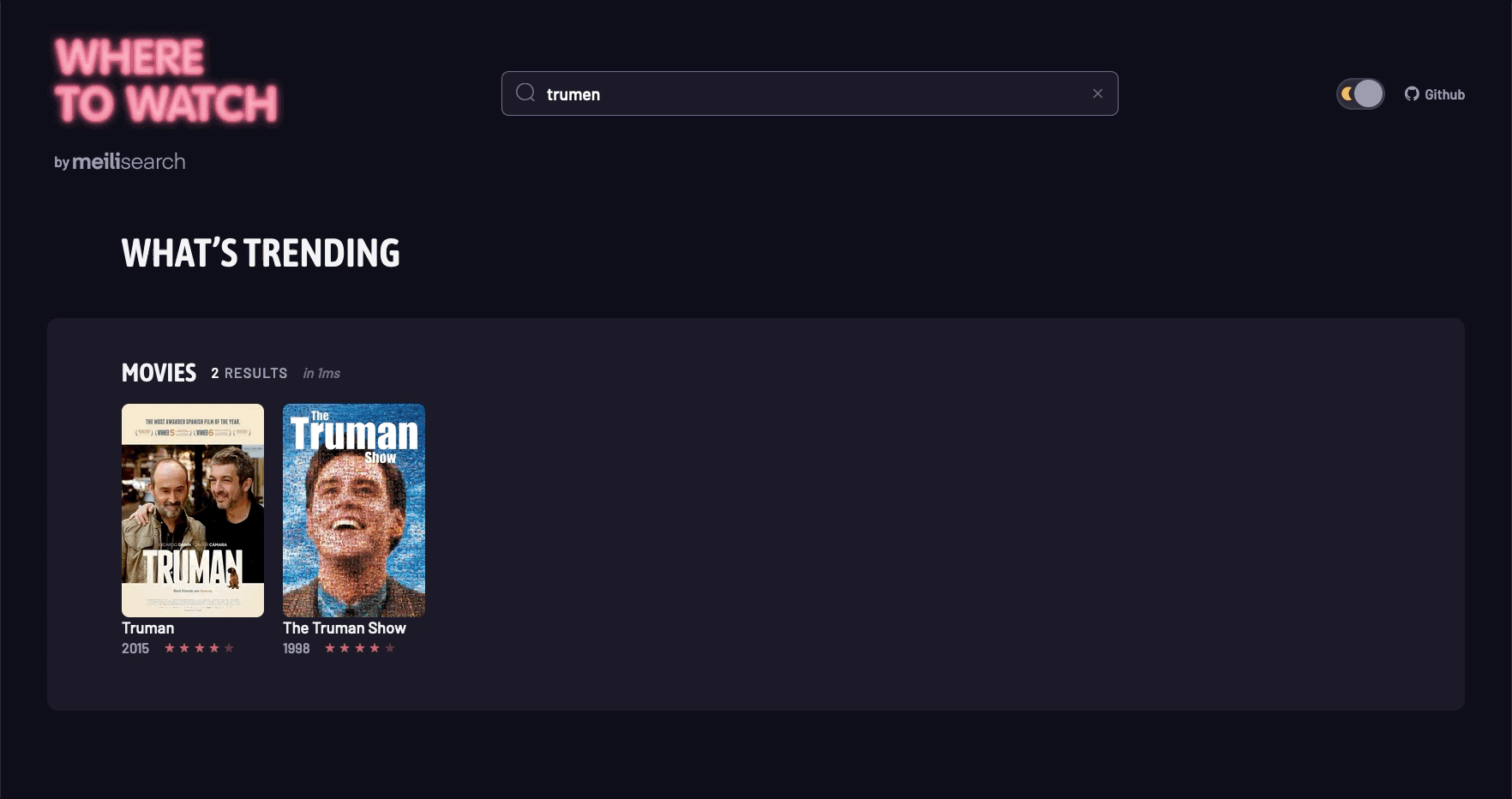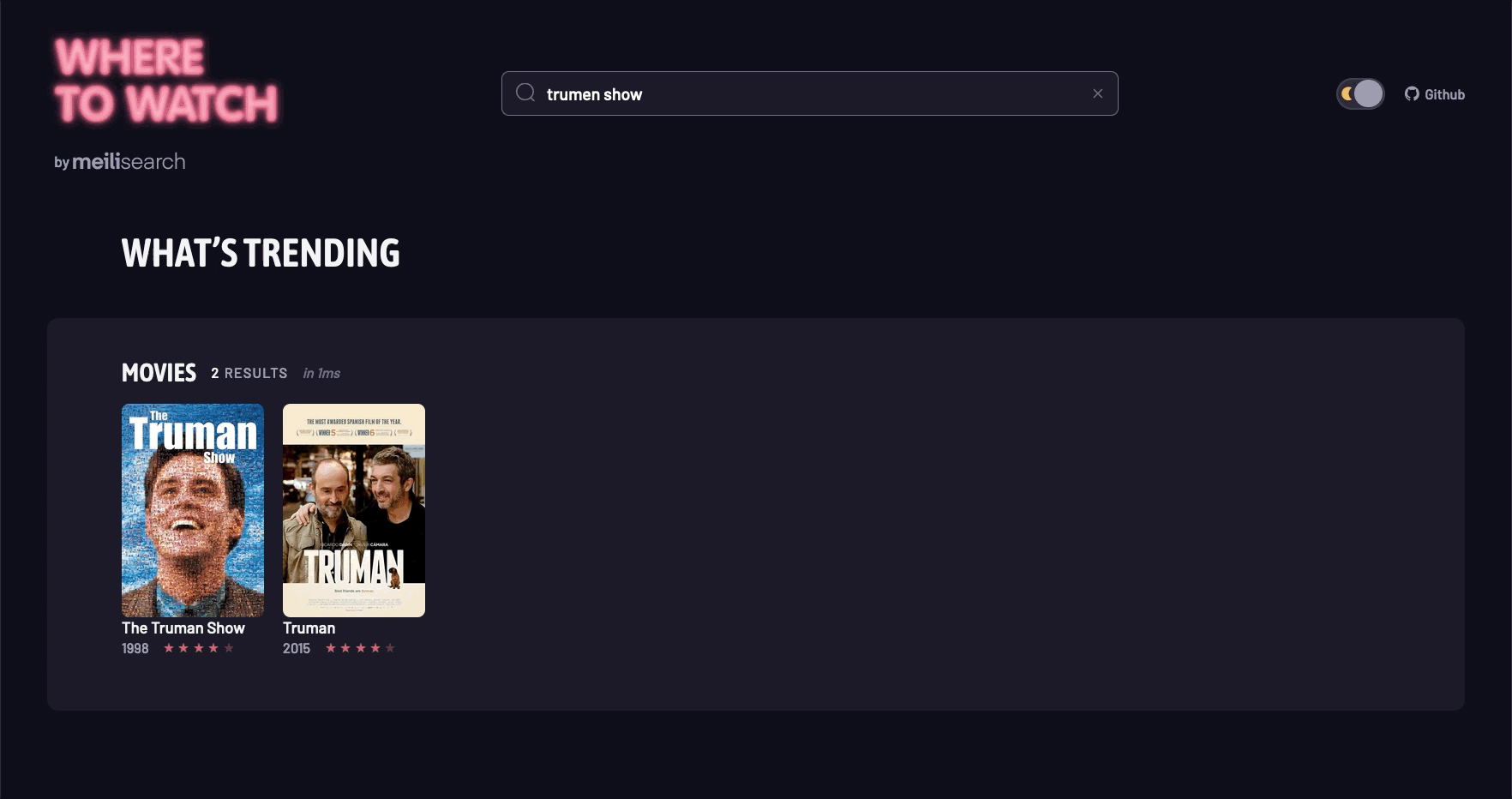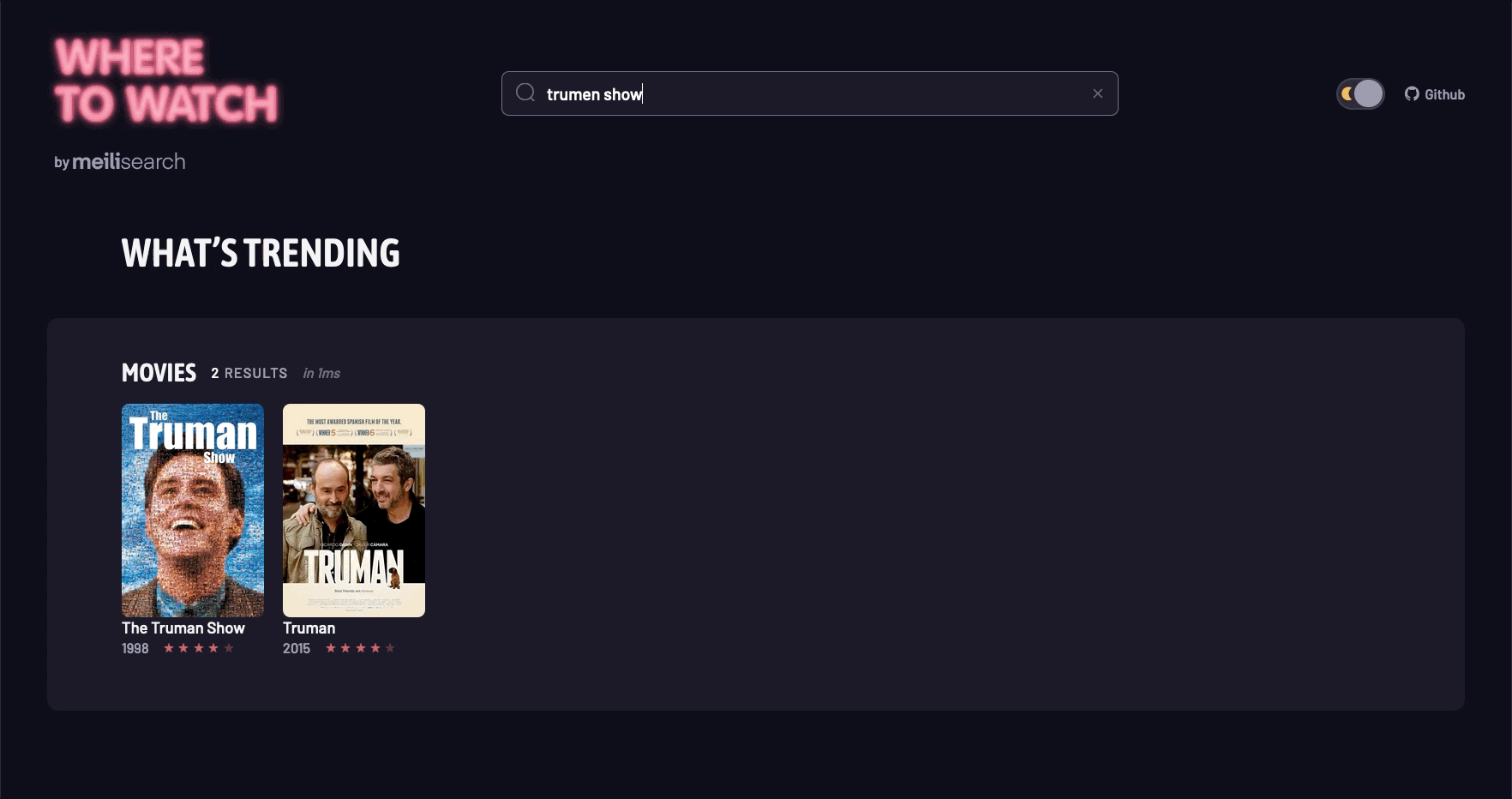
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)