Context Engineering—上下文工程
概述:对比提示词工程、问题、应对措施;论文:架构、其他
概述
Context Engineering,上下文工程,基于提示词工程(Prompt Engineering)加以改进和优化。
对比提示词工程
提示词工程:用人类设计的自然语言引导模型做事,主要关注如何设计和优化单次的提示指令,让AI模型更好地理解用户意图并产生期望的输出。
上下文工程则是一个更加宽泛和系统性的概念,包含提示词工程所有技巧,还扩展到整个AI系统的上下文管理。关注:如何为AI系统提供完整的工作环境,包括背景知识、历史记录、工具调用、数据检索等各个方面,让AI在这个精心构建的上下文环境中更好地完成复杂任务。
包括但不限于:设计和管理提示链、调整指令和系统提示、管理提示中的动态元素(如用户输入、日期时间等)、搜索和准备相关知识(如RAG)、查询增强、工具定义和指令(对于智能体系统而言)、准备和优化少样本示例、结构化输入和输出、短期记忆管理以及长期记忆检索等。
问题
当Agent执行长耗时任务时,其上下文会不断累积,这不仅会超出窗口限制、增加成本与延迟,更会引发一系列性能衰退问题,可归纳为4种:
- Context Poisoning:上下文中毒,当一次错误的生成(幻觉)被写入上下文后,它会像毒药一样污染后续的每一步推理,导致Agent偏离正确的轨道,最终得出错误结论;
- Context Distraction:上下文干扰,当上下文中充斥大量信息时,即使这些信息都是正确的,也可能压倒(overwhelm)模型在预训练阶段学到的核心指令或能力,使其分心,忘记最初目标;
- Context Confusion:上下文混淆,当上下文中包含与当前任务不相关,但形式上又可能产生关联的冗余信息时,模型会被这些噪音所迷惑,从而影响其决策的准确性;
- Context Clash:上下文冲突,当上下文中的不同部分包含相互矛盾或不一致信息时,模型会陷入决策困境,不知道应该相信哪一部分,导致行为的不可预测性。
管理上下文,本质上就是管理AI的注意力与记忆力,是构建可靠Agent的基石。
应对措施
对上述4类问题的应对措施,简称四大支柱:
- Write:写入,构建Agent的外部记忆。可写入到内存、文件、数据库。
- Select:选择,从外部存储中,智能地检索与当前任务最相关的信息,并将其动态载入LLM的上下文窗口。几种方式:
- Compress:压缩,在信息保真度与成本间取得平衡。在保留核心信息的前提下,对上下文进行精简,以减少Token消耗、降低延迟。几种方式:
- Context Summarization:上下文总结,利用LLM将冗长的信息(如对话历史、工具输出)提炼成摘要
- Context Trimming:上下文裁剪,采用更直接的、基于启发式规则的过滤方法,如移除最旧的消息,或使用一个训练好的模型来删除无关信息
- Isolate:隔离,为专注与安全划分认知边界,防止恶意或错误的上下文信息影响系统的行为。涉及对输入的验证、对上下文来源的审核以及对输出的监控。几种方式:
- MAS架构,参考Multi-Agent多智能体系统(三);
- 环境隔离,如代码执行Sandbox模式;
- 监控:如LLMOps;
其他策略包括:
- 拼接历史对话:将近期交互内容拼入上下文,保持会话连贯;
- 系统指令前置与结构统一:通过
系统提示+用户输入+输出模板格式化组织,明确行为规则; - 引入链式推理与任务分层:通过
step-by-step提示、子任务拆解等方式,提升模型的任务完成能力;
一定程度上提升模型的对话连贯性与多轮任务能力,但(在工程实践上)可能仍存在瓶颈:
- 信息碎片化,管理无法精细:上下文工程没有机制区分什么信息该记、什么时候记、记到哪,怎么注入到合适的位置,任务越复杂越容易混乱。
- 信息留不住,状态无法累积:上下文工程只能在临时窗口中拼接历史内容,对任务背景、用户偏好,缺乏良好的状态记忆。
- 信息用不好,经验无法迭代:模型没有反思与动态对齐能力,只是任务执行器,无法从失败或历史中吸取经验,来帮助模型进行迭代。
自动化Context Engineering可能包括智能的上下文选择、动态的上下文优化、基于性能反馈的上下文调整等。
论文
A Survey of Context Engineering for LLM,GitHub
现代AI系统的上下文包含六个核心组件:系统指令 c i n s t r c_{instr} cinstr、外部知识 c k n o w c_{know} cknow、工具定义 c t o o l s c_{tools} ctools、持久记忆 c m e m c_{mem} cmem、动态状态 c s t a t e c_{state} cstate、用户查询 c q u e r y c_{query} cquery。每个组件都有自己的获取、处理和优化策略,而组装函数𝒜负责将它们有机结合。就像搭建一个复杂的信息处理流水线,每个环节都需要精心设计。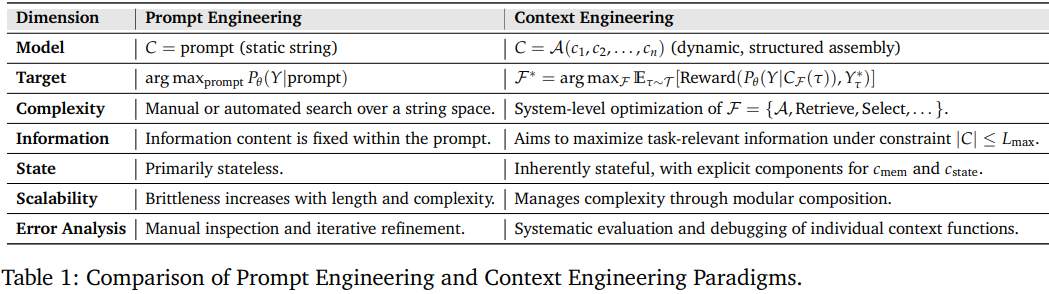
| 维度 | 提示工程 | 上下文工程 |
|---|---|---|
| 模型 | 静态字符串 | 动态、结构化组装 |
| 目标 | 优化单次提示 | 系统级函数优化 |
| 复杂度 | 在字符串空间上进行手动或自动搜索 | 需进行系统级优化 |
| 信息 | 信息内容固定在提示词内 | 在约束下最大化任务相关信息 |
| 状态 | 主要无状态 | 显式记忆与状态管理 |
| 可扩展性 | 随长度和复杂性增加而变得脆弱 | 通过模块化组合管理复杂性 |
| 错误分析 | 手动检查和迭代优化 | 对各个上下文函数进行系统评估和调试 |
架构
提出双层架构:
- 基础组件:作为底层,提供基础能力
- 系统实现:作为上层,构建复杂应用。
基础组件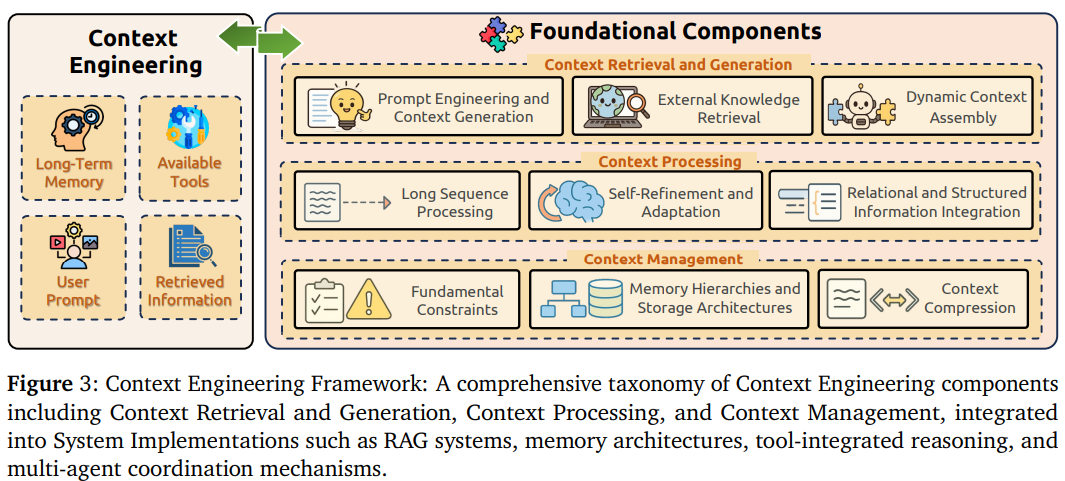
基础组件包括三个阶段:
- 上下文检索生成:包含三个关键技术分支:
- 提示工程与上下文生成:包括CoT、思维树(Tree-of-Thoughts,ToT)、图思维(Graph-of-Thoughts,GoT)等高级推理技术,还有零样本和少样本学习范式,以及认知架构集成等方法;
- 外部知识检索:涵盖检索增强生成基础技术、知识图谱集成(如KAPING框架)、结构化检索方法,以及智能体和模块化检索系统等前沿方向;
- 动态上下文组装:包括组装函数和编排机制、多组件集成策略,以及自动化组装优化技术,让不同来源的信息能够智能地组合起来。
- 上下文处理:包含四个核心技术方向:
- 长上下文处理:包括状态空间模型(SSM,如Mamba)、稀疏注意力机制、位置插值技术(如YaRN、LongRoPE)、FlashAttention等内存优化方法,以及StreamingLLM等流式处理技术;
- 上下文自我细化与适应:涵盖Self-Refine、Reflexion、N-CRITICS等自我改进框架,还有多方面反馈机制、元学习范式,以及长CoT等高级推理方法;
- 多模态上下文:包括视觉-语言模型集成、跨模态注意力机制、多模态对齐技术,以及视频理解、音频处理等专门技术;
- 关系和结构化上下文:涵盖知识图谱嵌入(如GraphToken)、图神经网络集成、结构化数据表示方法,以及文本化编码和程序化表示等创新方法。
- 上下文管理:包含三个关键技术领域:
- 基础约束处理:包括中间遗失现象的解决方案、上下文窗口优化技术、计算复杂度管理,以及位置偏差缓解方法;
- 记忆层次结构与存储架构:涵盖MemGPT等操作系统启发的记忆管理、MemoryBank等动态记忆组织系统、分层缓存机制,以及认知启发的记忆架构;
- 上下文压缩技术:包括上下文自编码器(ICAE)、递归上下文压缩(RCC)、Activation Refilling(ACRE)、QwenLong-CPRS按自然语言指令动态压缩、Heavy Hitter Oracle(H₂O)(通过淘汰低贡献Token提升吞吐量29倍)等技术,以及多智能体分布式处理方法。
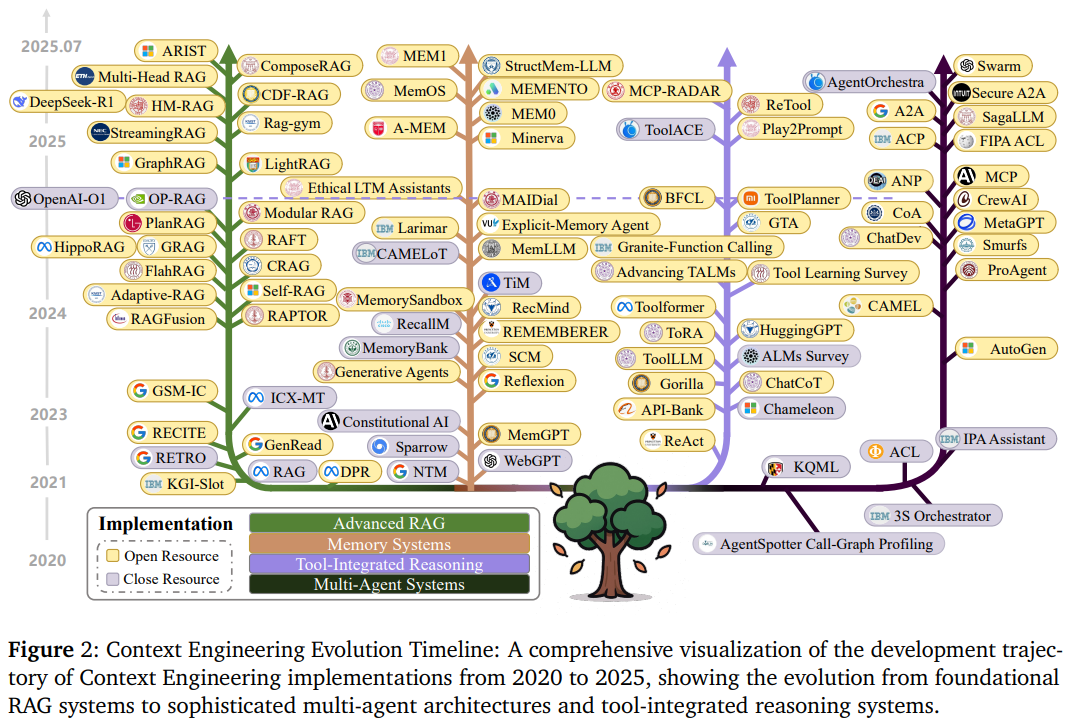
系统实现涵盖RAG、记忆系统、工具集成和多智能体四大方向。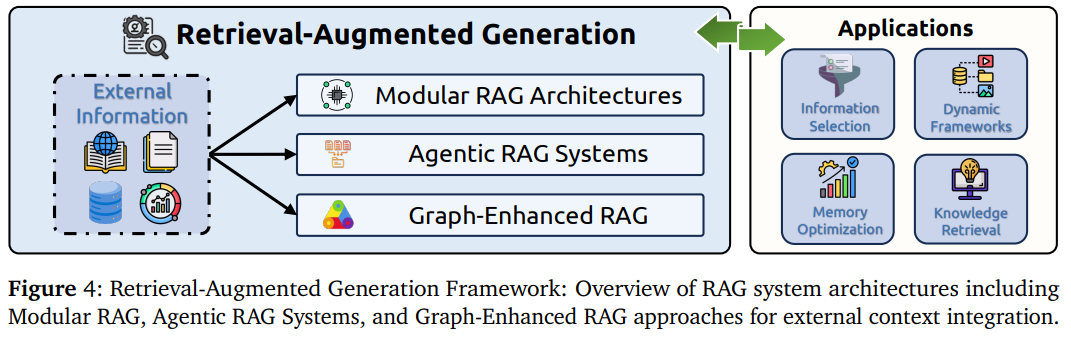
RAG系统的演进:从传统RAG到模块化RAG、智能体RAG和图增强RAG的技术发展路径。
- 模块化RAG架构:包括FlashRAG工具包、KRAGEN生物医学框架、ComposeRAG组合式架构等,支持灵活的组件组合和独立优化,就像搭积木一样组合不同的检索和生成组件
- 智能体RAG系统:涵盖PlanRAG规划式检索、自反思RAG(Self-RAG)、CDF-RAG闭环处理等智能体框架,能够自主规划检索策略,像一个会思考的研究员一样工作。
- 图增强RAG:包括GraphRAG分层索引、LightRAG双层检索、HippoRAG个性化PageRank等技术,利用知识图谱提供更精确的关系推理和多跳推理能力。想象您在开发一个医疗诊断助手,传统RAG只能根据症状关键词找到相关资料,但新一代系统能理解疾病之间的复杂关系,规划多步检索路径。
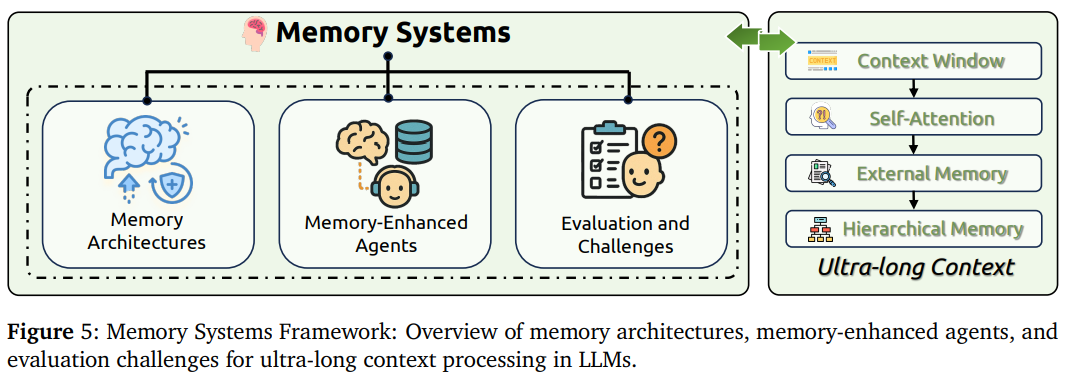
记忆系统的架构设计:涵盖记忆架构、记忆增强智能体和评估挑战三个核心维度,实现AI的长期记忆能力。
- 记忆架构:包括短期记忆(上下文窗口、键值缓存)、长期记忆(外部存储、参数记忆)、分层记忆系统等基础架构,以及MemOS等结构化记忆框架。
- 记忆增强智能体:涵盖Charlie Mnemonic、RecMind推荐系统、Voyager自主智能体等实际应用,还有REMEMBERER经验记忆、反思记忆管理等学习机制。
- 评估与挑战:包括LongMemEval基准测试、MADail-Bench对话评估、episodic memory评估等专门评估框架,以及记忆一致性、时间推理等技术挑战。关键是要解决遗忘和记忆的平衡问题:既要记住重要信息,又要避免信息过载。
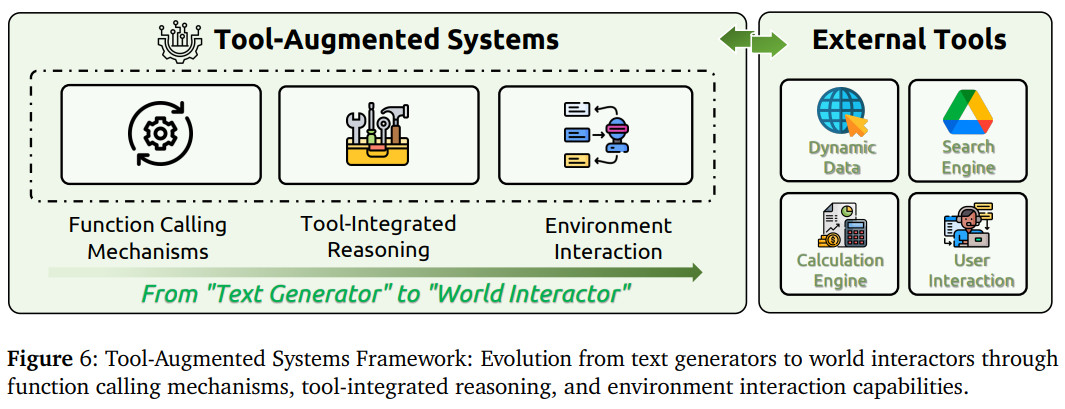
工具增强系统的发展历程:从基础的文本生成器演进为具备复杂工具调用和环境交互能力的智能体。
- 函数调用机制:包括Toolformer自监督学习、ReAct思维-行动循环、ToolLLM大规模工具学习等训练方法,以及Fine Tuning和Prompt Engineering两种主要实现途径。
- 工具集成推理:涵盖Program-Aided Language Models(PAL)、ToRA数学推理、Chain-of-Code代码生成等推理框架,还有强化学习优化的工具使用策略。
- 智能体-环境交互:包括Search-R1动态搜索、VisTA视觉工具选择、ReVeal自进化代码智能体等高级交互系统,以及MCP-RADAR、GTA等评估框架。如何在推理过程中智能地选择和使用工具,如何在复杂环境中持续行动和学习,这些都是这个领域的核心挑战。
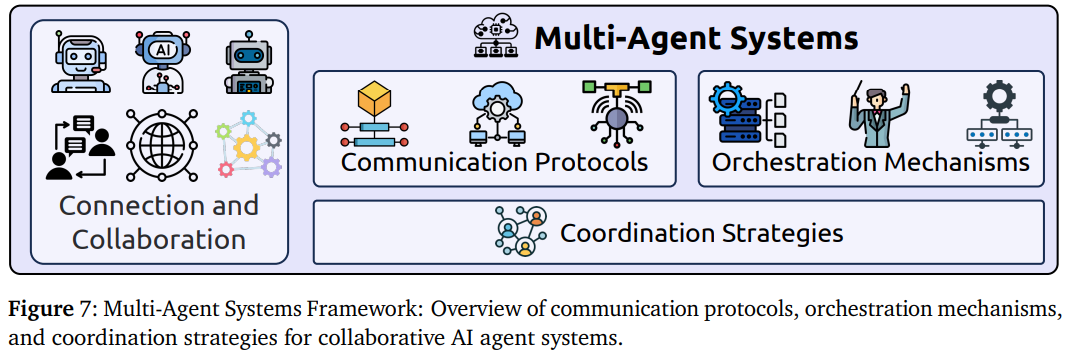
多智能体系统的协作架构:通信协议、编排机制和协调策略构成了现代多智能体系统的核心技术栈。
- 通信协议:包括传统的KQML和FIPA ACL标准,以及现代的MCP、A2A(Agent-to-Agent)、ACP(Agent Communication Protocol)、ANP(Agent Network Protocol)等新兴协议标准。
- 编排机制:涵盖AutoGen动态响应生成、CAMEL集成编排、CrewAI适应性框架等编排系统,以及先验编排和后验编排等不同策略。
- 协调策略:包括SagaLLM事务支持框架、分布式上下文管理、容错机制等技术,以及集中式vs分散式、层次化vs扁平化等不同的协调模式。想象一个软件开发项目:需求分析智能体、架构设计智能体、代码生成智能体和测试智能体需要无缝协作,这就需要标准化的协议和智能的协调机制。
上下文扩展包括长度扩展(处理更长的序列)和多维扩展(整合更多类型的信息)。
其他
核心不对称性(Core Asymmetry)
问题本质:LLMs在上下文理解(如复杂文档分析、多源信息整合)上表现卓越,但在长文本生成(如报告撰写、多步规划)中暴露出三大缺陷:
- 逻辑连贯性断裂
- 事实一致性下降(如早期结论被遗忘)
- 规划深度不足
实验证据:
- 延伸思维链任务中,性能因中间信息丢失下降多达73%
- 自动评估显示,生成质量随长度增加呈指数级衰减

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)