Ollama入门宝典:从本地到云端,打造你的免费私有大模型
这意味着,你的 64GB 内存既是系统内存,也是显存!我将站在工程师的视角,手把手带你从零开始,用最硬核的方式玩转 Ollama,从本地部署到云端算力租赁,彻底告别 API 焦虑,为我们后续搭建 Dify 和 Agent 工作流打下最坚实的地桩。使用它们,可以显著提升模型的可管理性,将原本散乱的文件和脚本变成标准化的服务,极大地提高了我们的工作效率。这就好比 Docker 的镜像(Image),它

大家好,我是独孤风。
最近在社群里,很多做大数据的同学问我:“风哥,现在 AI 这么火,作为一名跟数据打交道的工程师,我们该怎么切入?是不是要去学怎么训练模型?”
我的观点一直很明确:数据工程师转型 AI,核心不在于“造模型”(那是算法科学家的事),而在于“用模型”——即 AI 工程化(AI Engineering)。
如果你问我,开启 AI 工程化之路的第一步是什么? 不是去啃 Transformer 的论文,也不是去买昂贵的 OpenAI API,而是——先在你的电脑上,把 Ollama 跑起来。
在大数据时代,如果你不懂 Hadoop 或 Spark,你算不上入门;在云原生时代,如果你不懂 Docker,你寸步难行;而在如今的 GenAI 时代,如果你不懂 Ollama,你将失去构建本地化、私有化 AI 应用的基石。
为什么我强调大数据工程师必须会 Ollama? 因为我们最懂数据的价值和数据的隐私。当我们在做 RAG(检索增强生成)、搭建企业内部知识库、或者清洗敏感数据时,把数据传给公有云往往是合规红线。
Ollama,就是让你在本地(Local)安全、免费、高效调用大模型能力的那个“神器”。
今天这篇文章,不讲虚的理论。我将站在工程师的视角,手把手带你从零开始,用最硬核的方式玩转 Ollama,从本地部署到云端算力租赁,彻底告别 API 焦虑,为我们后续搭建 Dify 和 Agent 工作流打下最坚实的地桩。
通过本文档,可以快速的入门Ollama,成功的搭建Ollama并且部署本地大模型。是从0到1的入门文档,更多Ollama的高级功能,可以关注后续的文章更新。
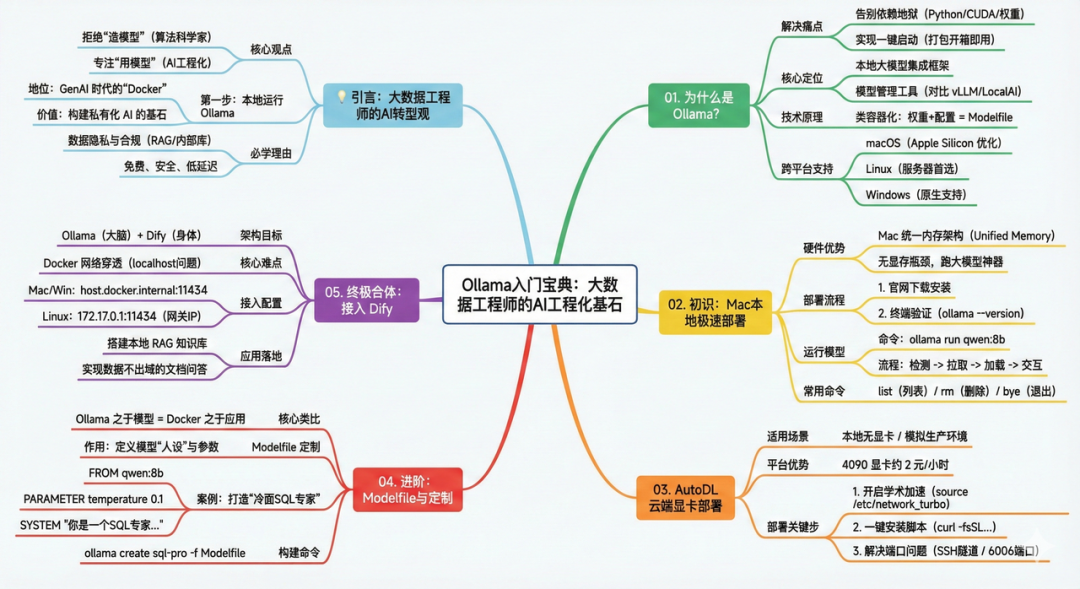
本文整体结构如下:

文档版权为公众号 大数据流动 所有,请勿商用。
01. 为什么是 Ollama?(Ollama概述)
在深入实战之前,我们需要先达成一个共识:Ollama 到底是什么?它解决了什么核心痛点?
1.1 从“依赖地狱”到“一键启动”
时光倒流几年前,要在本地部署一个私有的大模型,对于非算法背景的工程师来说简直是一场噩梦。
没有 Ollama 之前,你需要在主机上进行极其复杂的环境配置:
-
安装特定版本的 Python(还得防着与系统环境冲突)。
-
安装 PyTorch、TensorFlow 等深度学习框架。
-
配置 NVIDIA CUDA 驱动、cuDNN 等底层库。
-
下载几十 GB 的模型权重文件,还要自己写 Python 脚本来加载。
这一套流程下来,往往还没看到模型运行,就已经因为各种“依赖冲突”和“环境报错”劝退了。
Ollama 改变了这一切。
它把大模型运行所需的所有依赖——从底层驱动接口到上层推理引擎——全部“打包”提供好了。你不需要关心 PyTorch 是哪个版本,也不用担心 CUDA 兼容性,你只需要安装 Ollama,一切就绪。
1.2 大模型领域的“模型管理工具”
当涉及到大语言模型(LLMs)的落地时,单纯有模型是不够的,我们需要高效的模型管理工具。
在目前的开源生态中,Ollama、XInference 和 LocalAI 是这类工具的代表。使用它们,可以显著提升模型的可管理性,将原本散乱的文件和脚本变成标准化的服务,极大地提高了我们的工作效率。
而在这些工具中,Ollama 凭借其极致的易用性和类 Docker 的设计理念,成为了目前最主流的选择。
1.3 Ollama 的核心定位
Ollama 是一个托管在 GitHub 上的开源项目,其项目定位非常清晰:一个本地运行大模型的集成框架 (Get up and running with large language models locally)。

从技术原理上讲,Ollama 借鉴了容器化的思想:它通过将模型权重 (Weights)、配置文件 (Config) 和必要数据封装进一个由 Modelfile 定义的包中。
这就好比 Docker 的镜像(Image),它把模型运行所需的一切都封装在了一起,从而实现了大模型的下载、启动和本地运行的自动化部署及推理流程。
目前他在github标星已经157K!支持的模型茫茫多。

1.4 跨平台支持
作为一款成熟的工程化工具,Ollama 提供了完美的跨平台支持。目前已全面兼容:
-
macOS (对 Apple Silicon 芯片有神级优化)
-
Linux (服务器端部署首选)
-
Windows (原生支持,不再强制依赖 WSL)
无论你使用的是哪个操作系统,Ollama 的安装过程都被设计得非常简单,真正做到了“对开发者友好”。
1.初识 Ollama:Mac 本地极速部署
如果说 Docker 还需要配置一下 Daemon,JDK 还需要配一下环境变量,那么在 Mac 上安装 Ollama 的难度,甚至低于安装一个微信。
在开始之前,我想先聊聊硬件。在 AI 圈子里,Mac (Apple Silicon) 目前被称为“本地推理的神器”。
传统的 PC 架构中,CPU 内存(RAM)和显卡显存(VRAM)是物理隔离的。模型推理时,数据需要在两者之间搬运,且受到显存容量的死板限制(比如 4090 只有 24GB)。
而 Apple 的 M1/M2/M3 芯片采用了统一内存架构 (Unified Memory)。这意味着,你的 64GB 内存既是系统内存,也是显存!这让 Mac 可以在没有昂贵专用显卡的情况下,轻松跑起来 70B 甚至更大参数的模型。Ollama 对这种架构做了底层的 Metal 框架适配,效率极高。
2.1 保姆级安装步骤
下载安装包
打开浏览器,访问 Ollama 官网下载页。
网站会自动识别你的系统,点击巨大的 "Download for macOS" 按钮,下载一个 dmg安装包。
安装运行
双击下载的文件,拖拽安装就可以,你会得到一个有着可爱羊驼图标的 Ollama.app。
双击运行。
期间可能会要求你输入 Mac 的开机密码,这是为了安装命令行工具ollama 到系统路径。
(之前的版本会下载zip包,解压后安装会提示是否移动到应用程序目录,按步骤执行即可)
-
验证安装
-
安装完成后,可以直接启动Ollama 了。
-
但作为工程师,我们更习惯与终端打交道。打开你的 Terminal (终端) 或 iTerm2,输入以下命令:
ollama --version-
如果你看到了类似 ollama version is 0.13.x 的输出,恭喜你,地基已经打好了。
dugufeng@MacBookPro ~ % ollama --version
ollama version is 0.13.02.2 界面运行大模型
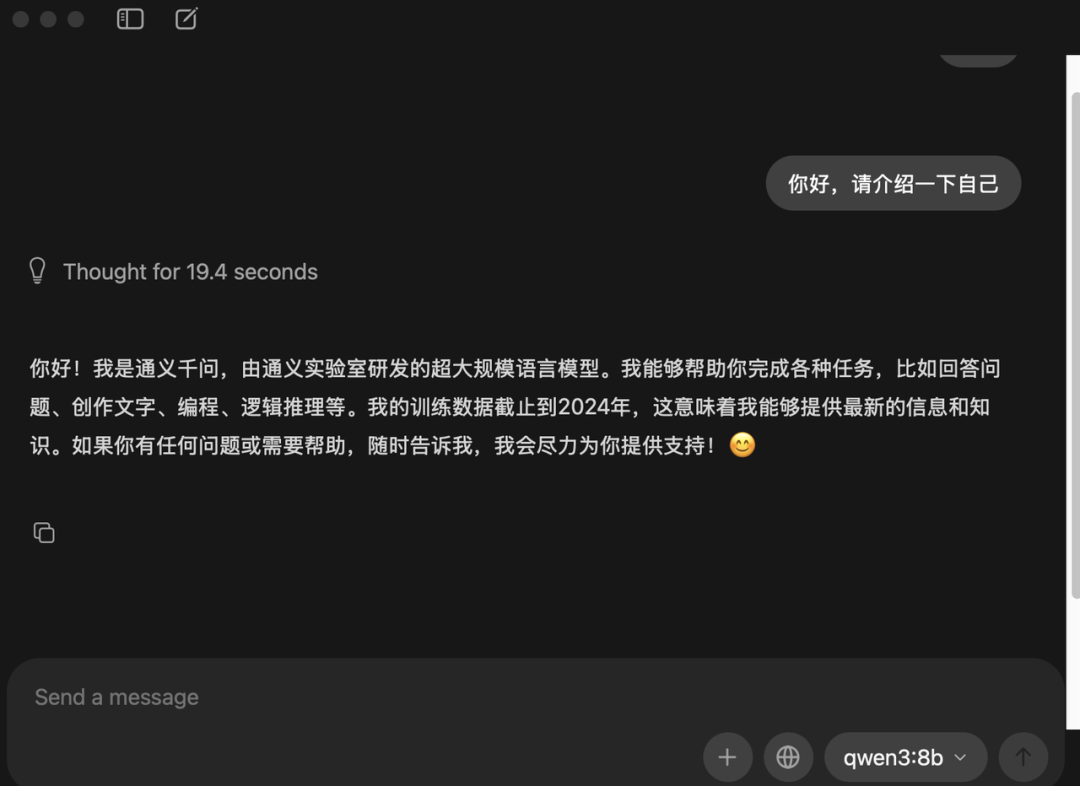
环境装好了,我们立刻来跑一个模型。可以通过两种方式,第一种就是在界面上直接选择,现在已经支持非常多的模型。
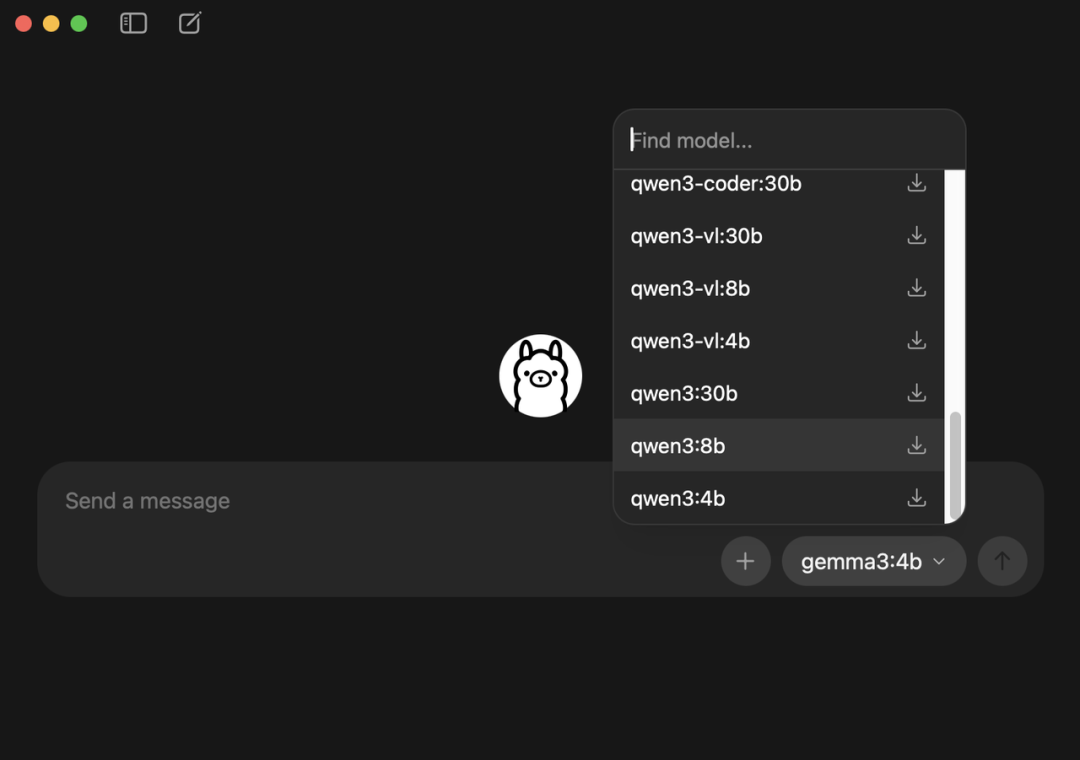
我们这里选择 qwen:8b进行下载。(要注意下内存,7B参数的模型大概需要8G内存,13B需要16G内存,33B需要32G内存)
耐心等待下载完成,之后就可以对话了,非常的方便。
2.3 命令行操作
当然所有的页面操作都可以在终端完成,也更灵活,输入以下简单命令:
Bash
ollama run qwen:8b发生了什么?
当你按下回车的那一刻,Ollama 就像 Docker 一样开始工作:
-
检测本地:检查你本地是否有 qwen:8b 的镜像。
-
自动拉取:如果没有,它会自动从 Ollama Library 下载。
-
加载推理:下载完成后,自动将模型加载到内存/显存中。
-
启动交互:进入聊天界面。
你会看到类似这样的进度条:
pulling manifest
pulling 00e1317cbf74... 100% ▕████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB
verifying sha256
digest
writing manifest
success当屏幕上出现 >>> 提示符时,不管是断网还是联网,你都已经拥有了一个私有的 AI 助手。你可以直接用中文问它:
>>> 你好,请介绍一下你自己。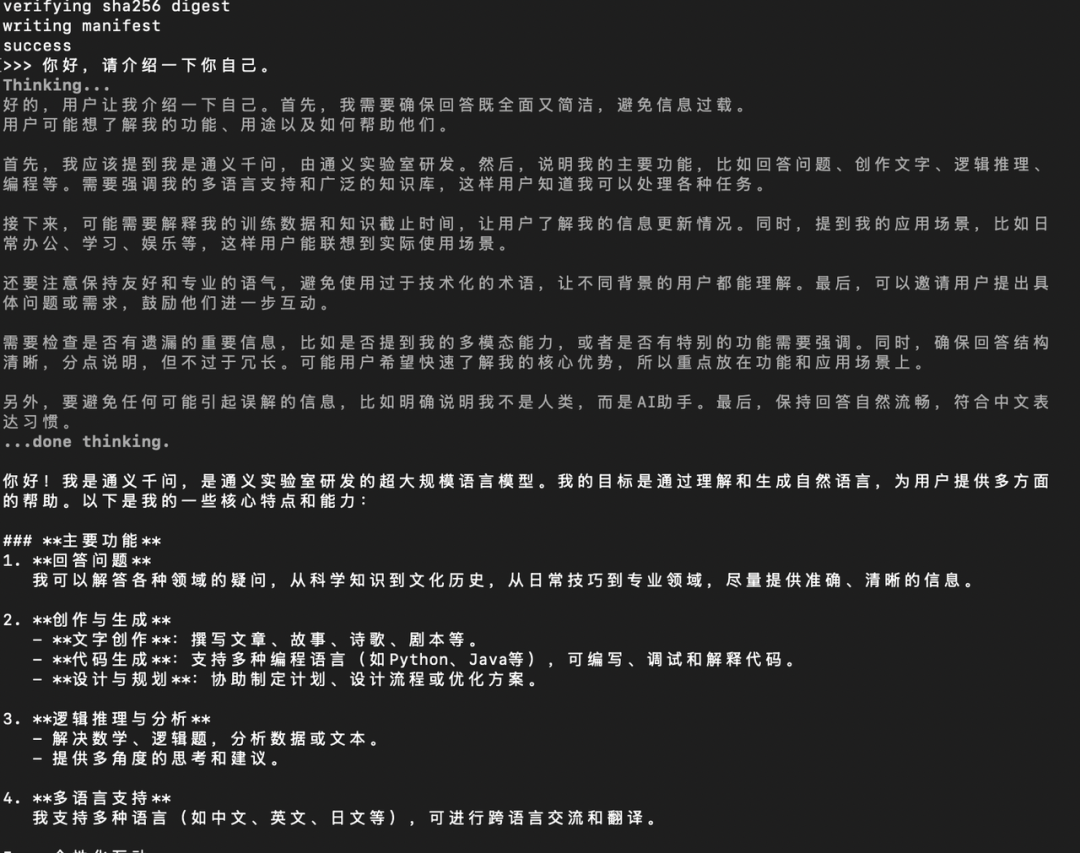
它会迅速吐字回复。你会发现,在 M 系列芯片的加持下,生成的速率(Tokens/s)非常快,完全不输给在线 API。
既然我们把 Ollama 比作 Docker,那它们的操作逻辑几乎是一模一样的。这里有几个你必须掌握的命令:
-
退出聊天:在对话界面输入 /bye 或者按 Ctrl + d。
-
查看已安装模型:
ollama list-
删除模型(释放空间):
ollama rm qwen3:8b注:Windows 和 Linux 用户
虽然本节重点演示了 Mac,但 Ollama 对 Windows 和 Linux 的支持同样优秀。
Windows:官网直接下载 .exe,安装逻辑与 Mac 一致。
Linux:提供了一键安装脚本(后文服务器部署部分会详细讲)。
无论哪个平台,安装后的命令操作是完全通用的。
2.AutoDL 云端显卡部署指南
“我的电脑是轻薄本/Intel 芯片,没独立显卡,跑不动大模型怎么办?”
“本地环境和未来的生产环境不一样,我没有显卡如何学习生产环境的真实情况呢?”
别急!我们可以用“空间换金钱”**。去 AutoDL 租用按小时付费的云端显卡,配合 Ollama 远程调试。
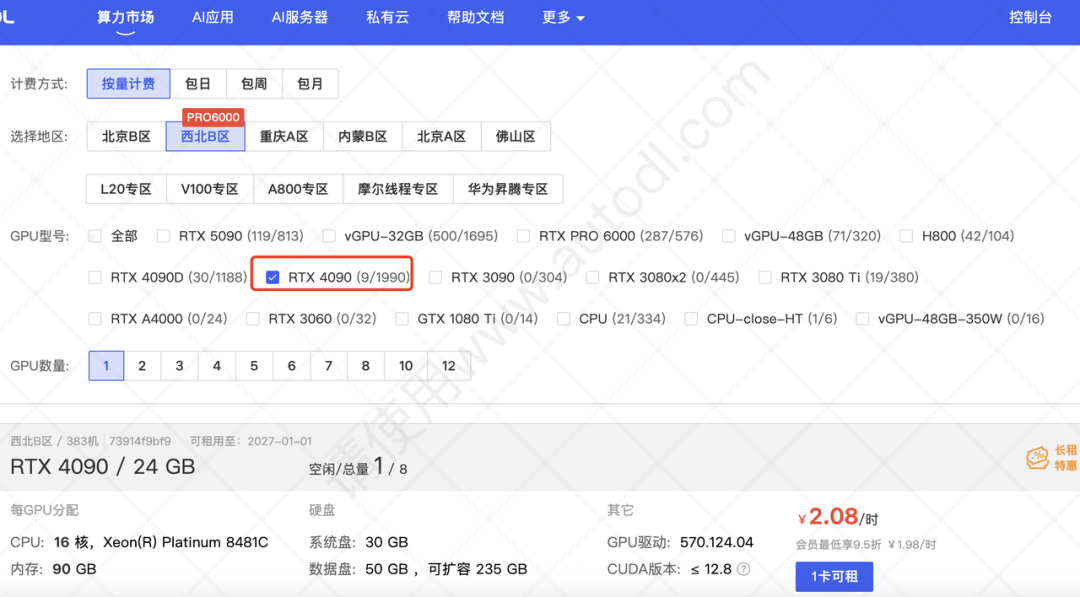
3.1 为什么选 AutoDL?
高性价比:相比于公有云昂贵的包月费用,AutoDL 提供按小时计费的 GPU。以 RTX 4090 (24GB 显存) 为例,平均花费仅需 2元/小时 左右。
这样我们先学会了基本操作,花不了几十块钱,但如果需要长期的模拟生产环境调试,当然还是买显卡比较划算。
灵活性:随开随用。由于按时间收费,建议大家养成“上班开机,下班关机”**的好习惯,把成本控制在极致。
AutoDL是一款面向开发者、企业及创新团队的全方位云计算平台,致力于为人工智能、大数据、高性能计算等前沿领域提供灵活高效的算力支持。平台以高性价比的GPU算力资源为核心,结合先进的虚拟化技术与弹性扩展能力,满足从个人开发者到大型企业的多样化需求。通过智能调度算法和按需付费模式,用户可高效利用资源,显著降低计算成本。
当然该平台支持AIGC领域的文本生成、图像创作、视频合成等创新应用,助力内容生产效率提升;为深度学习研究者提供分布式训练、模型优化及推理加速服务,覆盖计算机视觉、自然语言处理等场景;在云游戏领域,通过低延迟渲染和实时流媒体技术,实现4K/8K超高清游戏体验;针对渲染测绘、元宇宙构建等复杂场景,提供高精度图形处理、实时三维建模与跨平台部署能力;同时,HPC(高性能计算)领域的科学模拟、基因测序等任务也能通过集群计算和并行优化技术高效完成。还配套完善的开发工具链、API接口及专业级技术支持,帮助用户快速构建、部署和优化应用,推动技术创新与商业落地。
我们暂时只需要他的显卡租用功能。
3.2 选购与配置
登录平台后,进入“算力市场”。我们的目标是一台便宜的 RTX 4090。
可以简单对比下价格,和地区以及显卡型号有关。
我们这里选择租一台RTX 4090,选择一卡可租。
选定显卡后,进入配置页面,我们选择“按量计费”。基础镜像建议选择:
-
框架:PyTorch 2.3.0
-
CUDA版本:12.1
-
Python版本:Ubuntu 22.04 Python 3.13
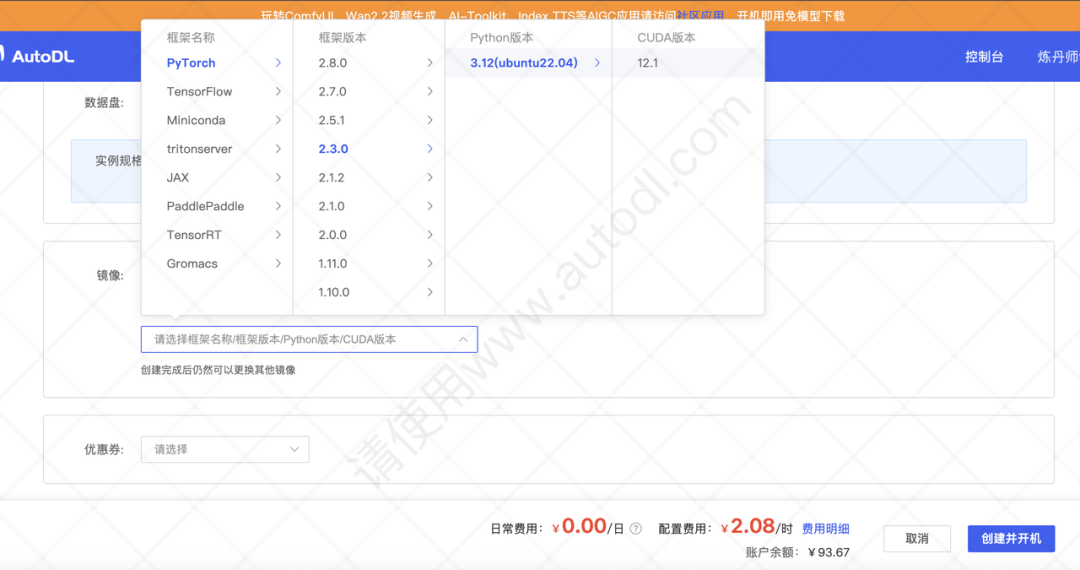
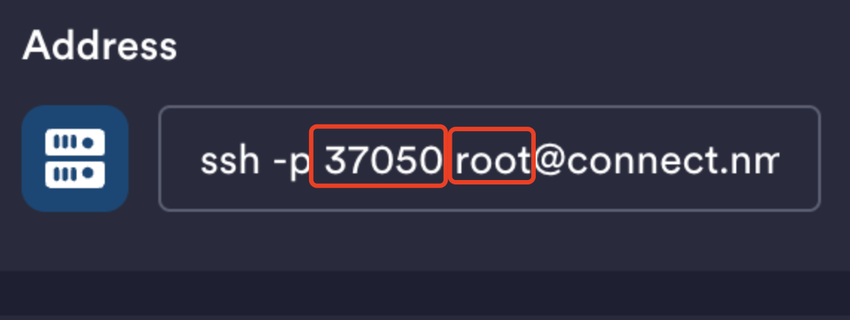
点击创建并开机。开机后,复制控制台提供的 登录指令 和 密码。 可以使用 XShell 或 Termius 等工具进行远程连接。

注意:复制的登陆指令是SSH命令,在这里可以看到用户名和端口号,自行填入就可以了。
输入正确的用户名和密码以后,登陆成功!
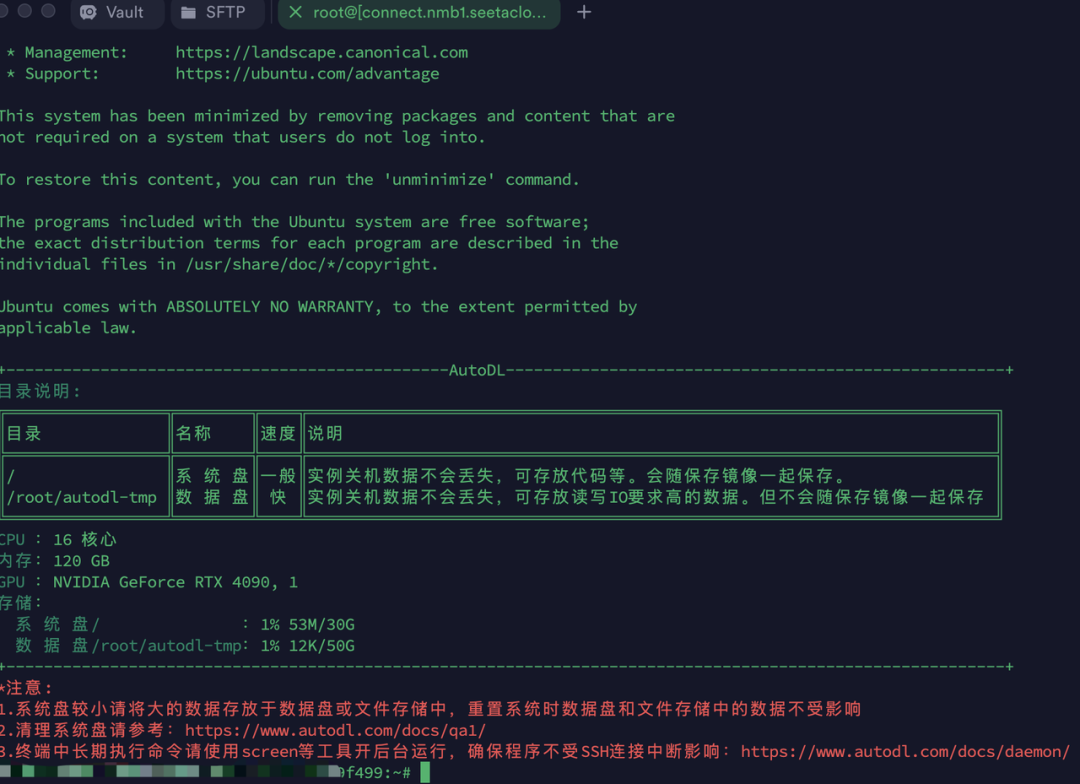
现在你就已经拥有了一台有着4090显卡的服务器了。
环境准备:开启“学术加速”
这是在 AutoDL 上部署最关键的一步。 由于国内网络环境原因,直接从 GitHub 或 HuggingFace 下载模型速度极慢。AutoDL 贴心地提供了学术资源加速功能(俗称“魔法”)。
必须执行的操作: 每次打开一个新的终端窗口,第一件事就是执行以下命令:
source /etc/network_turbo
##会提示设置成功##注意:仅限于学术用途,不承诺稳定性保证3.3 Linux下部署Ollama
还是回到ollama官网,点击Linux,这里给出了部署ollama的方法。

我们来创建ollama目录,然后执行该命令。
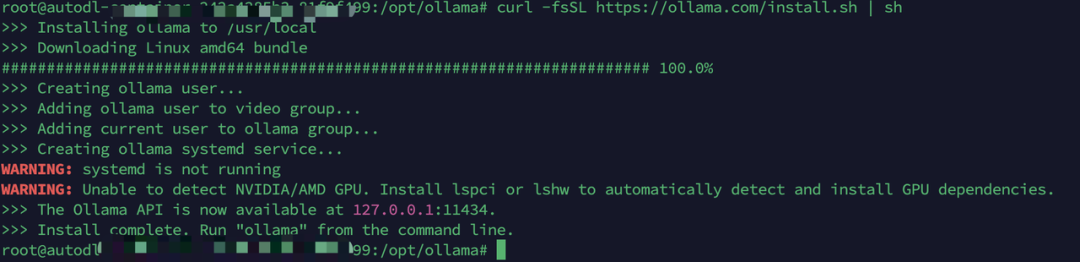
cd /opt
mkdir ollama
cd ollama/
curl -fsSL https://ollama.com/install.sh | sh等待一段时间,如果看到这样的提示,下载成功。
执行命令启动ollama服务。
ollama serve会看到下面的显示,启动成功。
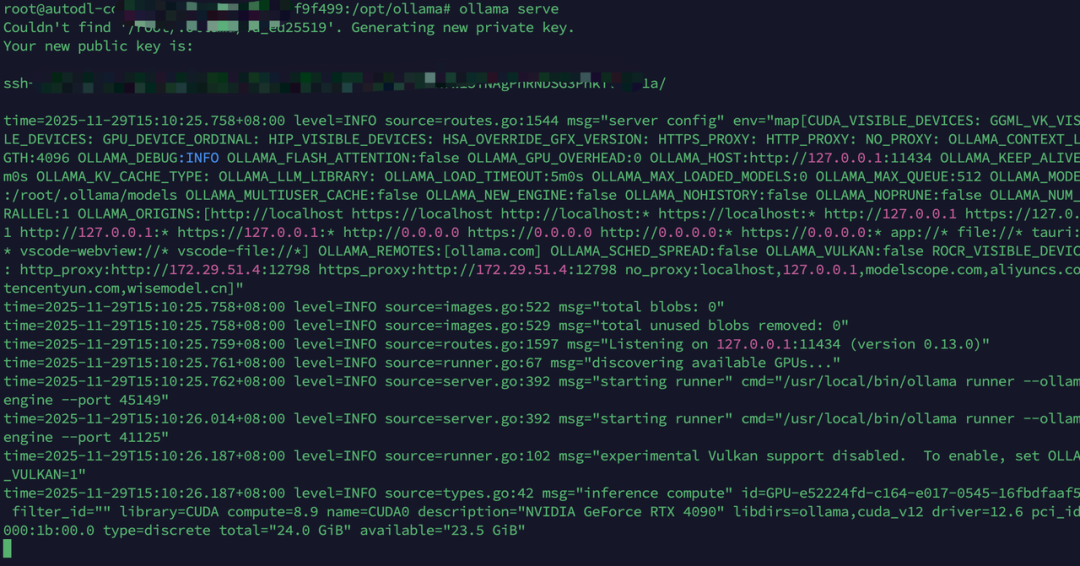
此时ollama已经启动了,但是这个页面还是在启动中,我们新开一个窗口。
和之前一样的操作,下载一个qwen3:8b的模型。
ollama run qwen3:8b由于缓存和学术加速,下载神速。

这样,我们在服务器上部署ollama也彻底搞定了,感觉体验一下,感受下4090的速度!
对了,如果不用了,服务器别忘了关机,还在扣钱呢!
长期关机的服务器会在15天后被释放,如果长期使用的话,大家记得偶尔开机一下,不然还要从头部署一遍。
3.Ollama 命令详解与模型定制
既然我们反复强调“Ollama 就是大模型界的 Docker”,那么它的操作逻辑自然也沿袭了 Docker 的极简风格。
作为一个合格的工程师,掌握 CLI(命令行)是基本功。别被图形界面惯坏了,只有命令行才是最高效的生产力工具。
4.1 常用命令速查表 (Cheat Sheet)
这里的每一条命令,都对应着 Docker 的经典操作。建议大家多敲几遍,形成肌肉记忆。
💡 小贴士:
退出对话:在聊天界面,输入 /bye 或者按下 Ctrl + d 即可优雅退出。
多行输入:在聊天界面,使用 """ 包裹文本,可以输入多行 Prompt。
终端输入 ollama,可以查看所有的命令。
```
dugufeng@MacBookPro ~ % ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
signin Sign in to ollama.com
signout Sign out from ollama.com
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
```4.2 进阶必修:Modelfile —— 定制你的专属模型
很多同学觉得开源模型“不够聪明”或“不听话”,往往是因为没有给它设定正确的系统提示词 (System Prompt)。
Ollama 的杀手级功能就是 Modelfile。
它之于 Ollama,就像 Dockerfile 之于 Docker。它允许你把基础模型、参数设置、系统人设打包成一个新的模型。
场景实战:打造一个“冷面 SQL 专家”
假设我们不需要模型跟我们寒暄(“你好,我是 AI 助手...”),我们需要它做一个莫得感情的 SQL 写手。
步骤 1:创建 Modelfile 文件
在任意目录下创建一个名为 SQL_Expert 的文件(无后缀):
# 1. 指定基础模型 (基于 qwen3:8b)
FROM qwen3:8b
# 2. 设置创造力参数 (Temperature)
# 范围 0-1。0.1 非常严谨(适合代码),0.8 非常发散(适合写诗)
PARAMETER temperature 0.1
# 3. 设置上下文窗口大小 (默认 2048,写长代码建议调大)
PARAMETER num_ctx 4096
# 4. 注入灵魂:System Prompt (系统人设)
SYSTEM """
你是一名拥有 20 年经验的大数据架构师,精通 MySQL、Hive 和 ClickHouse。
你的任务是将用户的自然语言需求转换为高效的 SQL 查询语句。
规则:
1. 直接输出 SQL 代码块,不要包含任何解释性文字或寒暄。
2. 关键字必须大写。
3. 总是假设表名为 'target_table'。
"""步骤 2:构建模型 (Build)
在终端执行构建命令:
# 语法:ollama create <新模型名> -f <Modelfile路径>
ollama create sql-pro -f SQL_Expert只需一秒钟,Ollama 就会读取配置,并在本地创建一个名为 sql-pro 的新模型。
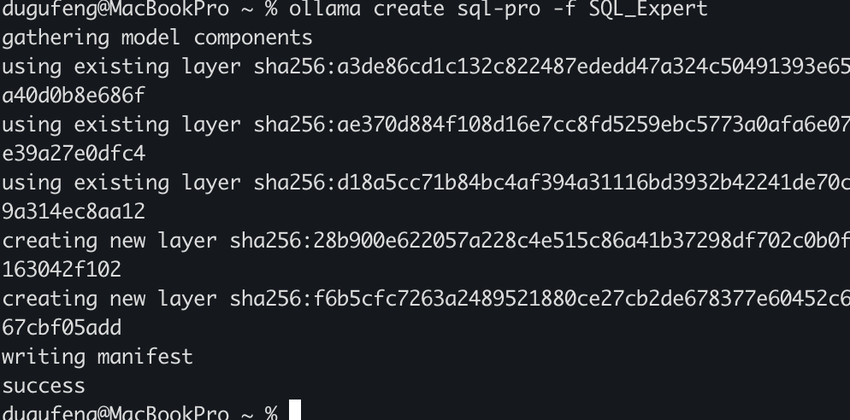
步骤 3:运行验收
现在,运行这个新模型:
ollama run sql-pro当你输入:“查询最近 7 天销售额最高的前 10 个用户”,它不会回复“好的,这是您的查询...”,而是会直接甩给你一段标准的代码:
SELECT user_id, SUM(sales_amount) as total_sales
FROM target_table
WHERE sales_date >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
GROUP BY user_id
ORDER BY total_sales DESC
LIMIT 10;这就是工程化的力量。 通过 Modelfile,我们可以为团队构建出“Python 助手”、“周报润色专家”、“客服陪练”等各种专用 AI,这才是本地部署真正的价值所在。
4.终极合体:Dify 接入 Ollama,构建你的 AI 应用工厂
万事俱备,只欠东风。
Dify是一个AI应用工厂,可以用大模型打造很多的AI应用。后续也可以关注大数据流动的相关文章学习Dify相关课程。
现在,你的左手边是 Ollama(一个拥有强大推理能力的“大脑”),右手边是 Dify(一个拥有完善工作流和 RAG 能力的“身体”)。
我们要做的,就是把它们连起来。一旦打通,你就拥有了一个完全免费、数据不出域的 AI 应用工厂。
5.1 核心概念:Docker 网络穿透
在连接之前,有一个“工程师必须懂”**的网络知识点,这能帮你避开 90% 的连接报错。
通常情况下,我们是这样运行的:
-
Ollama:运行在宿主机(你的 Mac/Windows 或 AutoDL 的 Ubuntu)上,监听 localhost:11434。
-
Dify:运行在 Docker 容器里。
问题来了:Docker 容器里的 localhost 指的是容器自己,而不是你的宿主机。如果 Dify 试图访问 localhost:11434,它会找不到 Ollama。
解决方案:我们需要使用 Docker 特有的 DNS 或网关 IP 来“穿透”容器,访问宿主机。
5.2 接入实操步骤
第一步:指定 Ollama 监听端口
在启动时(或配置环境变量)设置:
Bash
```
OLLAMA_HOST=127.0.0.1:6006 ollama serve
OLLAMA_HOST=127.0.0.1:6006 ollama run qwen3:8b
```如果使用AutoDL平台,需要配置一下自定义服务。
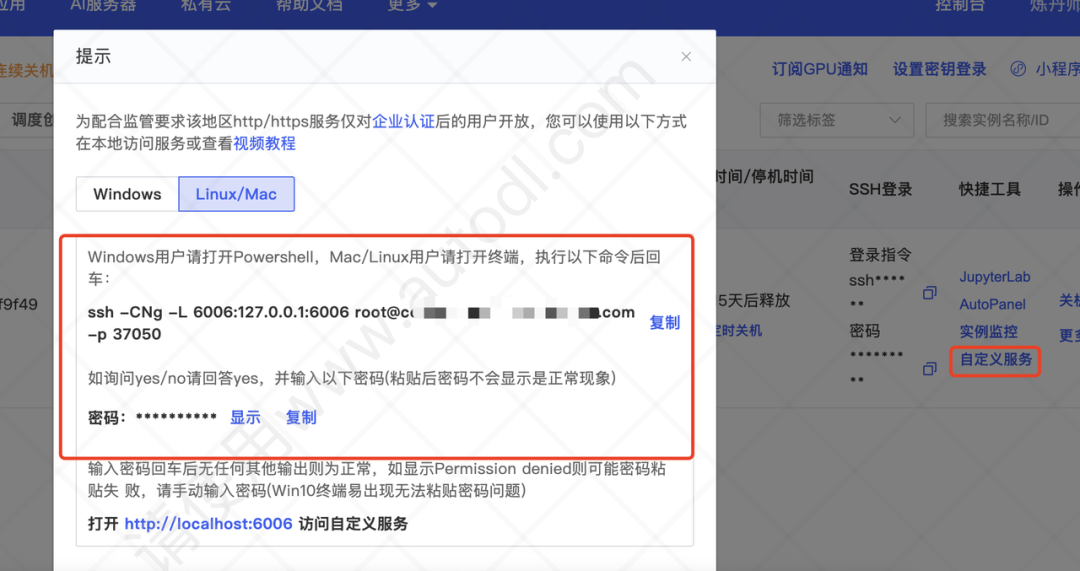
在Dify机器上按这个命令与ollama服务器建立连接。这样显示就是对了。

第二步:在 Dify 中添加模型
-
登录你的 Dify 平台。
-
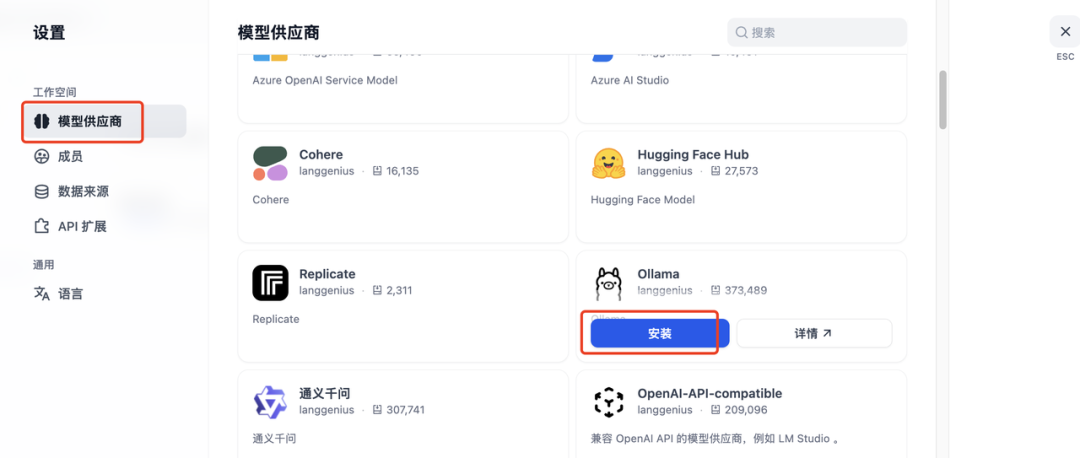
点击右上角头像 -> 设置 -> 模型供应商 (Model Providers)。
-
向下滚动,找到 Ollama 图标,点击 添加模型 (Add Model)。
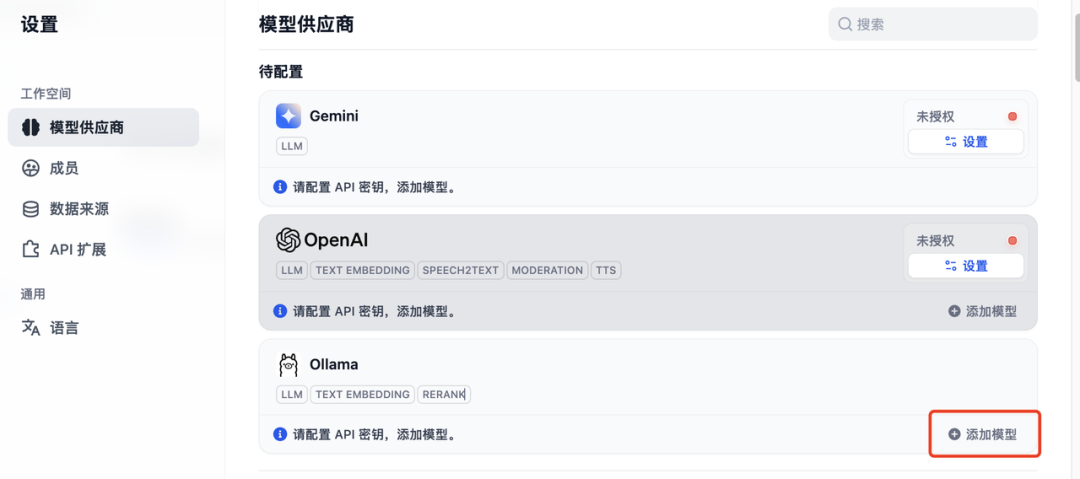
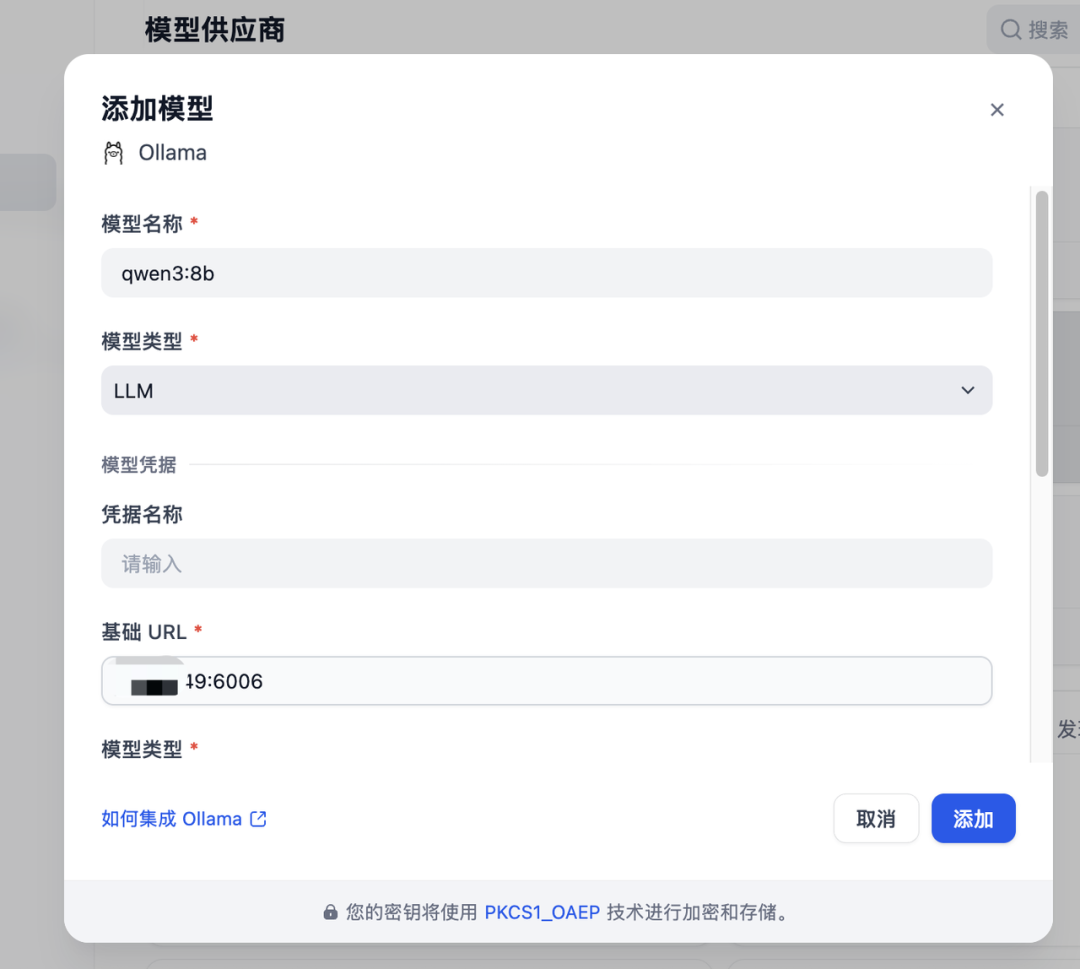
第三步:填写关键参数 (最关键的一步)
安装好以后,在ollama这里点击添加模型。
这里需要填写 基础 URL (Base URL):
Docker Desktop 提供了一个特殊的 DNS 来指向宿主机。
-
模型名称:qwen3:8b (必须与 ollama list 中的名字完全一致)
-
基础 URL:http://内网地址:6006
-
模型类型:对话 (Chat)
-
上下文长度:4096 (根据显存情况调整)
第四步:保存与测试
点击 “添加”。Dify 会尝试 ping 这个地址。
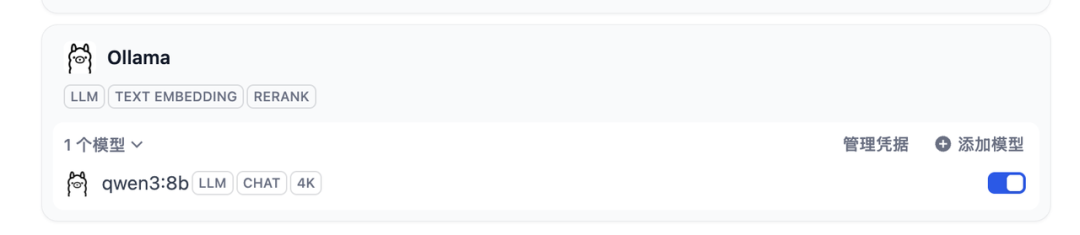
-
✅ 成功:没有任何报错,模型状态显示为“正常”。
-
❌ 失败:如果提示 Connection refused,请检查上一节提到的 OLLAMA_HOST=0.0.0.0 是否配置正确,或者防火墙是否放行了端口。
最后等一会,这样显示就是成功!
5.3 见证奇迹:跑通第一个 RAG 流程
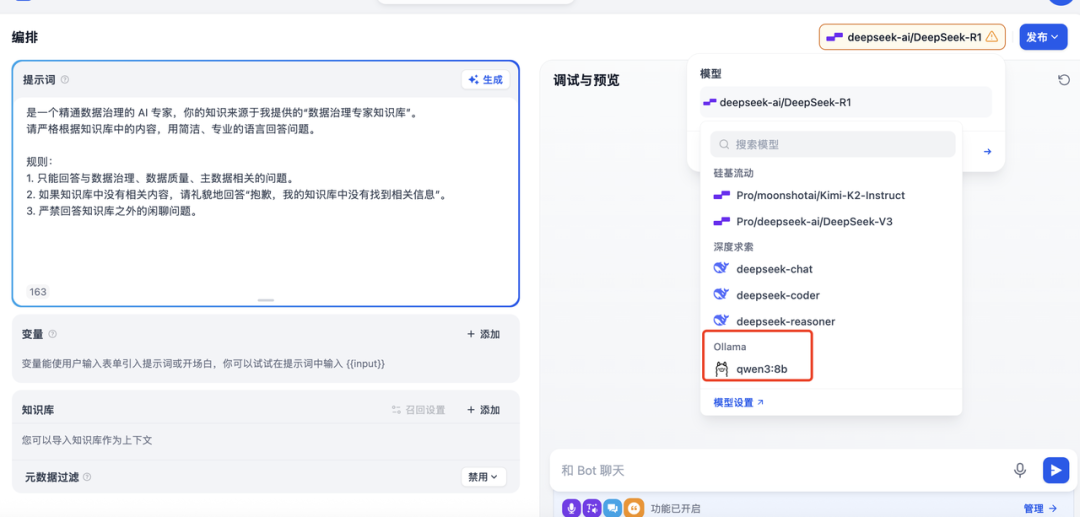
接入成功后,Ollama 就变成了 Dify 模型列表中的一个选项。
-
创建应用:在 Dify 首页创建一个“聊天助手”。
-
选择模型:在右上角模型选择器中,切换到 Ollama / qwen3:8b。
-
上传知识库:
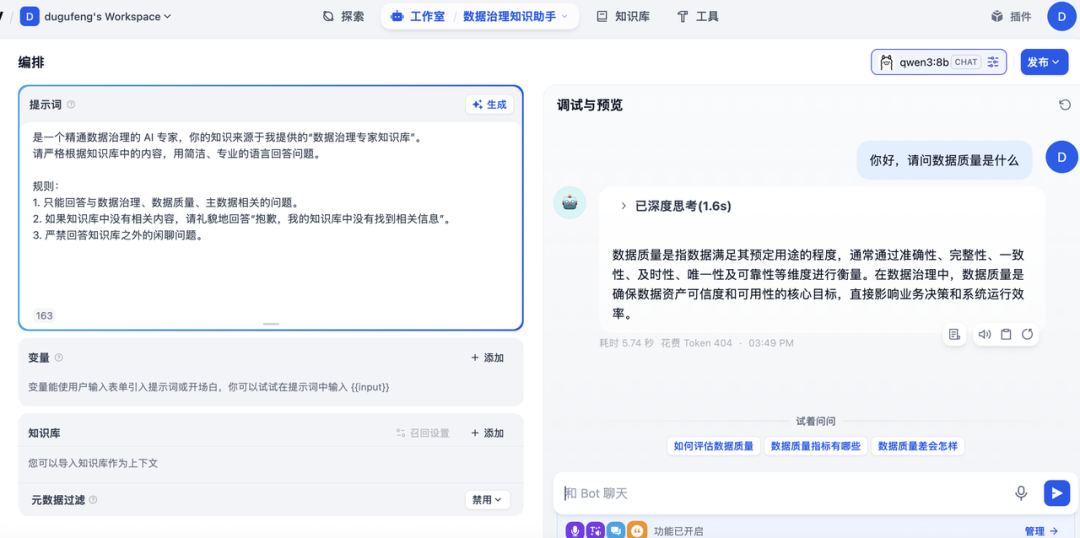
这一刻,你已经从一个单纯的“调包侠”,进化为了拥有私有 AI 算力的“AI 工程师”。
💡 独孤风的总结
至此,我们的《Ollama 入门宝典》系列教程的第一阶段——基建篇,就全部结束了。
我们一起走过了:
-
认知升级:理解了 Ollama 在 AI 工程化中的核心地位。
-
本地部署:在MAC上极速启动了大模型。
-
云端借力:利用 AutoDL 解决了算力瓶颈。
-
应用落地:成功将“大脑”接入了 Dify“身体”。
接下来的文章,我们将利用这套环境,深入实战WorkFlow(工作流)与 Agent(智能体)开发。我会教大家如何让本地的 Ollama 不仅能聊天,还能帮你写代码、查网页、甚至Text2SQL(自然语言查库),数据可视化等等。
我是独孤风,关注大数据流动,在大数据转型的路上,我们一起狂飙。大家加油!
最后,为了方便大家交流 AI 落地经验,我建了一个
「AI 工程化实战群(Workflow+Agent)」 学习交流群。
群里我会定期分享 Ollama实操经验、Dify 优质工作流源码 和 实战避坑指南。并将之前发表的文章资料打包送给大家。
独行快,众行远。这是一个“技术共建”的高质量社群,拒绝广告和纯伸手党。
如何进群 & 获取资料?
-
点亮文末“在看”。
-
在公众号后台回复关键词:【AI工程化进群】。
👇 戳左下角「阅读原文」,也可直接访问我们的开源仓库点个 Star ⭐️

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)