从19%掉速到400%提速:AI协作的正确姿势,我用这8步跑通了
实测证明:不是AI让你变慢,而是你不会用AI!拆解实战案例与人-AI协作六步法,让代码效率逆风翻盘。
AI 让资深程序员 “慢了” 19% ?
最近,AI 圈流传着一个让程序员瞠目结舌的实验结果:一群经验丰富的开发者在使用 AI 编程助手完成任务时,效率 不升反降,竟比纯手动编程 慢了 19% !
要知道,这些“老司机”原以为借助 AI 能提速 24%,结果却事与愿违。更令人意外的是,即便亲历了效率下降,他们仍坚信 AI 让自己 更快 完成了任务——心理上感觉提速了 20%。
AI 不是号称提高效率的神器吗?怎么反而拖了后腿?资深程序员越用 AI 越慢,这听起来像天方夜谭,却由数据摆在眼前。背后究竟发生了什么?

研究分析:AI 提速幻觉与 19% 掉速真相
首先,让我们剖析上述实验的细节。METR团队招募了 16 位资深开源开发者,让他们在各自熟悉的超大型代码库(平均 22K+ 星标,百万行代码规模)中完成总计 246 个真实任务,包括漏洞修复、功能新增等。
每个任务随机分配为“允许使用 AI”或“禁止使用 AI”两种模式:允许时开发者可借助任意 AI 助手(主要是 Cursor Pro,内置当时最先进的 Claude 3.5 / 3.7 模型)编程;禁止时则完全手工完成。每个任务平均耗时约两小时。
实验结果非常意外:使用 AI 时,开发者平均完成任务的用时反而增加了 19% —— AI 助手非但没有加速,反而让他们变慢了!
更诡异的是,这些参与者原本预期 AI 能让自己提速 24%,实验结束后回顾仍以为快了 20%——可数据却明摆着实际 慢了 19% 。
显然,大家产生了强烈的“AI 提速幻觉”。
这一发现与此前不少 AI 编码研究形成鲜明对比。
GitHub 自家的对照实验表明,使用 Copilot 能让开发者完成任务的速度提升 55% (AI组平均用时 1 小时 11 分钟,对照组则要 2 小时 41 分钟)。

另有研究发现,引入 AI 助手后,程序员单位时间内完成的工作量增加了约 26% 。
METR 的作者也强调,此次 19% 掉速 主要出现在“资深工程师 + 熟悉代码库”的特定场景,并不代表 AI 在其他情形下一无是处。
例如,对于经验尚浅的开发者或面对全新的代码项目,AI 依然可能提供显著的效率提升。
那么,为什么这些经验丰富的工程师会被 AI “拖慢” 呢?
根本原因在于 AI 使用过程隐藏的成本 :AI 无法魔法般直接产出完美代码,反而引入了额外的步骤和开销:
-
反复校正 AI 输出:开发者花费大量时间检查并纠正AI给出的代码。AI 的建议往往方向正确但细节不符,需要不断调整修改。每当AI代码不够可靠时,程序员就得反复调试、修复,相当于“在教AI写代码”,徒耗时间。
-
交互沟通开销:使用 AI 意味着引入额外的沟通成本。开发者需要花时间精心编写提示词(prompt),可能要多次迭代才能让 AI 产出满意结果;同时还得等待模型响应。这些过程都会消耗时间。如果任务本身很短小,这些额外步骤可能抵消 AI 带来的益处——安全领域的一项实验就发现,在几分钟内即可手工完成的简单任务中,仅 加载 Copilot 所花的时间就足以让熟练程序员写完答案。
-
“轻松”造成的错觉:让 AI 参与编码降低了人的认知负荷。有人将这种体验比作“先拿到一份初稿再润色”,而不是对着空白编辑器从零开始——整个过程的确 省力 了许多。由于不那么烧脑,开发者主观上感觉“好像”更快了,其实这只是 舒适感提高,并不代表效率提升。正如研究者所说,程序员并非一味追求用时最短,他们往往更愿意选择 省力但可能更慢 的路径。
综合来看,资深程序员在当前 AI 协作下掉速 19% 的现象,是多重因素共同作用的结果。但这并不意味着 AI 注定无用。
相反,METR 团队指出现有 AI 工具的使用 还有改进空间:例如优化提示策略、针对项目进行定制训练、尝试更高效的人机协同模式等,都有望把目前 -19% (负数) 的拖累转变为正向提速。
换言之,问题不在于 AI 是否有用,而在于我们如何更有效地使用 AI。
AI 助攻,聊天页面加载从 5.1 s 缩短到 1.2 s
我最近负责优化公司产品的一个聊天对话列表页面,它加载缓慢,首次打开竟需要 5.1 秒才能完全呈现。对即时通信场景来说,这样的速度简直不可接受。
作为一名资深程序员,我起初尝试了常规的性能排查:检查前端资源加载、分析接口响应时间、查看数据库慢查询日志…… 折腾一圈下来,并未找到明显的瓶颈所在。
页面数据主要是加载用户最近的几十条会话记录及各自的最新一条消息。
我隐隐感觉问题可能出在 后端数据获取 上,但一时间难以定位具体瓶颈。
情急之下,我决定向 AI 求助。我将页面的加载流程和相关代码片段描述给了 ChatGPT,请它帮忙分析性能问题。
ChatGPT 很快给出了一个切中要害的猜测:N+1 查询 导致的延迟。它提示我检查后端代码是否对每个会话分别查询数据库获取最后一条消息。
如果是这样,那当有 50 个会话时,就会执行 1 + 50 次数据库查询(先查询会话列表,再为每个会话查询最新消息),大量的数据库往返自然会严重拖慢页面加载。
这正是问题所在!
我们之前的实现确实如此 —— 每个聊天会话都单独查询一次数据库,典型的 N+1 查询模式。
找到病因,方案也呼之欲出:将多次零散的查询合并为一次批量查询。ChatGPT 建议我编写一条 SQL 将所有聊天的最新消息一次性取出,然后在应用层进行映射即可。
我采纳了这个思路,对后端代码进行了重构。
如下伪代码所示,优化前后逻辑对比明显。
优化前 - 逐个获取每个聊天的最新消息(N+1 查询):
chats = get_user_chats(user_id) # 查询会话列表
for chat in chats:
last_msg = db.query(f"SELECT content, time FROM messages WHERE chat_id = {chat.id} ORDER BY time DESC LIMIT 1")
chat.last_message = last_msg.content
render(chats)优化后 - 批量获取所有聊天的最新消息(合并查询):
chats = get_user_chats(user_id) # 查询会话列表
chat_ids = [chat.id for chat in chats]
last_msgs = db.query(f"SELECT chat_id, content, MAX(time) as time FROM messages WHERE chat_id IN ({','.join(map(str, chat_ids))}) GROUP BY chat_id")
# 将查询结果映射回各聊天会话
for chat in chats:
chat.last_message = last_msgs[chat.id].content
render(chats)部署修改后,我使用性能测试工具进行了测量:页面加载时间从原先的 5.1 秒 骤降到约 1.2 秒,提速超过 4 倍!!!
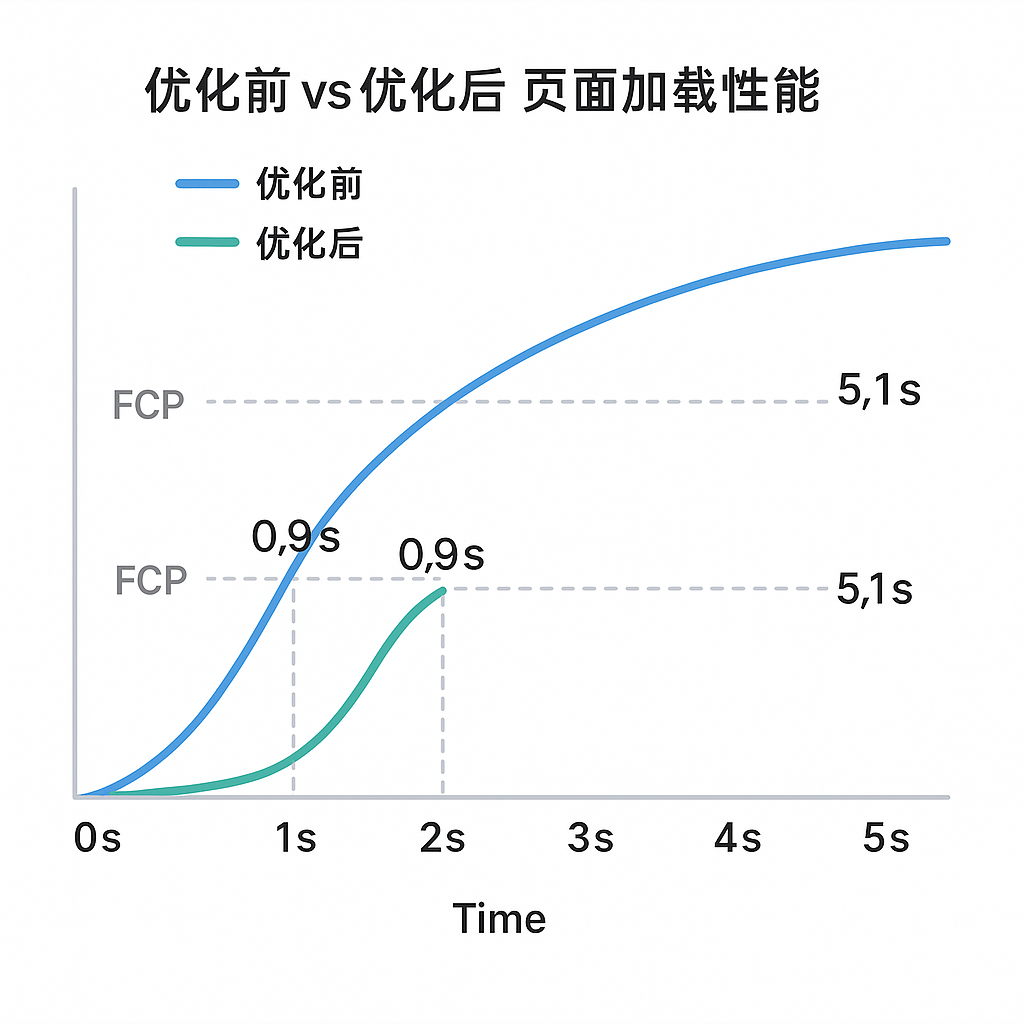
用户再也不会感觉到卡顿,页面呈现几乎是秒开。
这次实战让我切身感受到:正确运用 AI,完全可以把 “减速” 翻转为 “提速” 。
ChatGPT 几分钟内就 pinpoint(精确指出)了瓶颈所在,给出了有效的优化建议。如果完全靠我自己排查,可能还要花费更长时间甚至走不少弯路。
这次 AI 助攻的经历,无疑是对“资深程序员用 AI 反而更慢”论调的一次有力反证。
人 - AI 协作循环与提示技巧
如何才能像上面案例那样,把 AI 真正用出生产力?
关键在于掌握高效的人机协作方法。
基于实践经验,我将这种协作归纳为一个 六步循环,并辅以若干提示设计原则和进阶的多智能体用法:
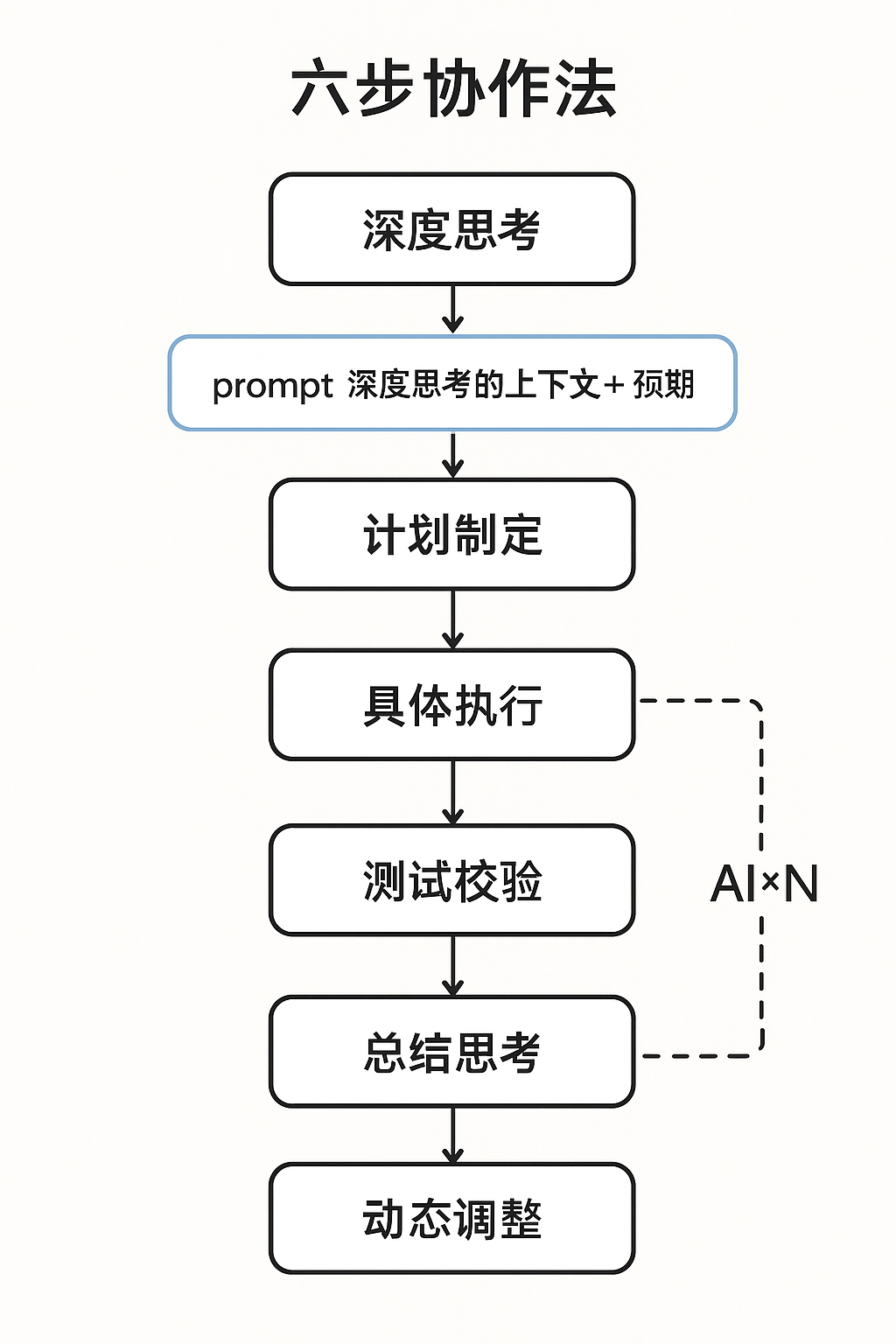
人机协作的六步循环
1)明确目标:首先,人类开发者要清楚定义要解决的问题和预期目标。例如,是要修复哪个 Bug、优化哪段代码的性能、还是生成什么文档。目标明确是合作的前提。
2)提供上下文:在向 AI 提问之前,准备好必要的背景信息。包括相关的代码片段、错误日志、输入输出示例等。把这些上下文提供给 AI,有助于它理解问题环境,避免给出风马牛不相及的答案。
3)拟定提示:精心编写 Prompt(提示词)向 AI 提问。说明想让它扮演的角色(如“代码审查助手”)、任务要求以及期望的输出格式。问题可以分解为子任务,让 AI 逐步解决。“请先给思路,再给代码” 往往比一上来就要完整代码效果更好。
4)获取 AI 方案:让 AI 生成初步的解答或代码。此时保持开放心态,像对待同事的方案那样来看待 AI 输出。必要的话,可以多让它生成几版方案备用。
5)评估与完善:仔细审查 AI 给出的结果。检查代码是否符合预期、有没有错误或隐患。可以直接运行测试用例验证功能是否正确,或用小规模数据测性能。如果发现问题,整理反馈(比如指出哪个部分不对或需要改进),然后向 AI 进一步提问求改进方案。人类在这一环节起主导作用,保证最终方案可靠可行。
6)实现与验证:将 AI 产出的方案整合到实际项目中,实现具体功能或优化。之后再次进行全面的测试和性能验证,确保改进确实达到了预期目标。如果结果不理想,则进入下一轮循环,重新分析问题并调整AI协作思路。
以上六步并非一次性线性完成,经常需要多次迭代循环。
例如,可能要反复尝试不同 Prompt,或多轮问答逐步逼近解决方案。
熟练的人机会话往往是 循环递进 的过程 —— 每一轮都比前一轮了解得更多、提出的问题更有针对性,最终收敛到满意答案。
优秀 Prompt 的设计原则
在这个协作循环中,编写高质量的 Prompt 至关重要。
有几条 提示词设计 的原则可以大大提高 AI 给出满意答案的概率:
-
具体明确:清晰描述需求,不要含糊其辞。指明要解决的问题、约束条件和期望输出。例如 “请帮我优化这段 Java 代码的性能,要求内存占用不增加” 比 “这代码怎么优化?” 要有效得多。
-
提供背景:让 AI 掌握必要的信息。可以在提示中附上相关代码片段、数据结构说明,或者之前尝试的方法。背景越充分,AI 回答越有针对性。
-
分步引导:如果问题复杂,尝试让 AI 分步骤作答。你可以要求:“先给思路,再给详细实现。” 这样 AI 会先输出解决问题的总体思路,待你确认后再产出具体代码,从而减少跑题风险。
-
指定角色和风格:在 Prompt 中指定 AI 的角色或回答风格。比如:“假设你是一个资深 Python 后端工程师,帮我审查这段代码…… ” 这样 AI 会以专家视角给出更专业的建议。又如要求输出以表格、JSON 等特定格式,AI 也会据此调整答案格式。
-
给出示例:如果期望特定格式或风格,可以提供范例。例如“按照以下格式返回结果:
\n 优化前用时: X ms\n优化后用时: Y ms”。AI 有了例子更容易照葫芦画瓢。 -
多轮迭代:不要指望一个 Prompt 解决所有问题。循序渐进 地提问,每次聚焦一个方面,并根据上一次 AI 的回答不断 refine(细化)要求。逐轮逼近,你会发现答案质量大幅提高。
多智能体“竞标”模式
除了改进人与单个 AI 的交互,还有一种更高级的协作模式:多智能体竞标。
简单来说,就是引入多个 AI 来“竞争”解决方案,择优采用,类似头脑风暴和优胜劣汰的结合。
举个例子:面对一个棘手的算法问题,你可以同时让 ChatGPT 生成三个不同的解决思路,然后比较哪种思路最简洁高效,再请 AI 根据最佳思路生成最终代码。
又或者,让两个不同的大模型(比如 GPT-4 和另一个开源模型)分别尝试修复同一个 Bug,对比谁的方案更优。
你甚至可以让同一个 AI 分饰两角:一个扮演代码生成者,另一个扮演代码审查官,先由生成者给出方案,再让审查官挑错改进,最终你整合二者的结果。
这种多 Agent 协作有点像让多个“AI 同事”各展所长、互相校验。
由于每个模型或提示可能擅长的角度不同,通过竞争与合作,我们更有机会获得高质量的答案。
经过多方案 PK、交叉验证 后筛选出的往往是更优解。虽然实施多智能体模式会增加一定沟通成本,但在面对复杂挑战、需要创意或高可靠性方案时,它能显著提高成功几率。
掌握以上方法论和技巧后,我们就有望将 AI 从一个“减速器”变成强力的“加速器”。
接下来,我们还需要选对工具并充分加以利用,让实践事半功倍。
工具建议与实操模板
拥有方法论,还需要趁手的工具和模板来落地执行。
以下是一些实用建议,可以帮助你更高效地实践人机协作:
-
Prompt 模板示例:准备一套可复用的提示词模板,能大大节省与 AI 沟通的时间。例如,当你进行性能优化时,可以使用类似的模板:
- 角色:资深 Python 性能调优专家 - 任务:请帮我优化以下代码的运行效率 - 代码片段:(此处粘贴出现性能问题的代码) - 要求:指出性能瓶颈,给出具体的优化方案和修改后的代码。必须确保功能与原代码等价。上面模板包含了角色定位、具体任务、代码上下文以及明确的要求。实际使用时,你只需替换代码片段和任务描述即可。类似地,你可以准备 “Bug 排查模板” + “单元测试生成模板” + “代码风格重构模板” 等,根据不同场景快速套用,避免每次都从零开始思考如何对 AI 提问。
-
性能验证工具:在接受 AI 给出的优化方案后,一定要通过工具来验证性能改进的真实性。不要单凭主观感觉判断 “好像更快了”,而要让数据说话。常用的方法包括:
借助这些工具,我们可以客观评估 AI 方案的效果,做到心中有数。
-
基准测试:编写小型基准测试(Benchmark)来对比优化前后的运行时间、内存占用等指标。
-
Profiling 剖析:使用性能分析工具找出瓶颈。例如前端可以借助浏览器的 Performance 面板、后端可以使用 profiling 工具(Python 的
cProfile、Java 的 JFR 等),数据库调优则有慢查询日志和EXPLAIN分析等。 -
监控与日志:在实际环境中部署后,关注监控系统的指标变化(如响应时间、CPU 使用率),以及日志中的错误是否减少。持续的量化观察能避免 “优化过头” 或方向偏误。
-
-
AI 能力矩阵记录:建议建立一个属于你自己的 AI 能力矩阵 ,用来记录 AI 在不同任务上的表现,以便日后参考和改进。做法很简单:把你经常会用 AI 帮忙的任务列出来,并对每种任务 AI 的实际效果打个分、写点心得。随着 AI 模型升级和你提问技巧的提高,这个矩阵可以定期更新。举个例子,你的能力矩阵表格或清单可以是这样的:
任务类型
AI 助力效果
使用心得
单元测试生成
★★★★☆(非常高)
基本一次提示就能出可用案例
性能优化建议
★★★☆☆(中等)
提示需具体,结果需验证
大型系统架构设计
★★☆☆☆(较低)
输出思路可参考,细节不可靠
从上表可以看出,你清楚哪些场景下 AI 得心应手,哪些场景还 力不从心 。以后遇到类似需求,就能迅速决定要不要借助 AI、如何借助 AI,以及需要重点留意哪些潜在问题。这张 “能力矩阵” 也是你个人在人机协作道路上的成长日志,持续完善它,可以帮助你不断调整策略,扬长避短,发挥 AI 所长。
掌握了以上工具与技巧,我们已经为人机协作铺好了道路。
最后,谈谈心态层面的启发与反思。
摆脱“工具决定论”,掌控 AI 协作主导权
我们需要在心态上完成从被动到主动的转变。
那种认为 “用了新工具就自然会怎么怎么样” 的 工具决定论 是靠不住的 —— AI 工具既可能拖慢进度,也完全可以提速,关键取决于 使用它的人 。
对于开发者来说,最重要的是摆正人与工具的关系: AI 决定不了你的效率,只有你自己能决定。
我们既不能盲目迷信 AI 可以包办一切,也不应因为一次不良体验就全盘否定 AI 的价值。
相反,我们要做的是掌握 AI 的脾气秉性,与之不断磨合,找到最适合自己的用法,将主导权牢牢握在自己手中。
前面提到的资深程序员用 AI 反而慢 19% 的那个实验,它并非在告诉我们 “AI 无用”,而是在敲响警钟:如果不用对方法,神兵利器也可能变成累赘。
然而,我们也亲眼看到,通过改进协作方式,完全可以打破这个魔咒,实现从 -19% 到 +400% 的惊人飞跃!
工具本身从来不是决定因素,使用工具的人才是。
正如目前业内流行的一句话:
AI 不会取代程序员,但 善于使用 AI 的程序员 会取代不会使用 AI 的程序员。
未来,AI 必将成为开发者日常工作中不可或缺的力量。与其害怕被新技术淘汰,不如积极拥抱并驾驭它。
让我们摒弃“工具决定一切”的偏见,以学习者的姿态不断探索人与 AI 协作的新边界。
在实践中积累,在反思中成长 —— 当我们能够驾轻就熟地与 AI 搭档共舞时,每一位开发者都将拥有前所未有的生产力跃升。
握紧手中的方向盘,AI 将是助力我们驶向更高效、更创新未来的强劲引擎!!!
参考资料
-
METR 研究团队. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. 2025年7月10日.
-
Anna Tong. AI slows down some experienced software developers, study finds. Reuters 科技新闻, 2025年7月10日.
-
GitHub Copilot 官方博客. Quantifying GitHub Copilot’s impact on developer productivity and happiness. 2022年7月.
-
Microsoft 研究白皮书. Productivity Findings with Copilot for Security (Jan 2024)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)