A Survey of Knowledge Graph Reasoning on Graph Types: Static, Dynamic, and Multi-Modal
您好,我们是一群热情洋溢的探索者,致力于深耕于知识图谱和大型语言模型(LLM)领域。我们的目标是挖掘、分析并分享那些能够启迪思维、推动科学进步的优质学术论文。我们坚信,知识的传播和交流是促进创新和社会发展的关键力量。A Survey of Knowledge Graph Reasoning on Graph Types: Static, Dynamic, and Multi-Modal在图类型上的
自我介绍:
您好,我们是一群热情洋溢的探索者,致力于深耕于知识图谱和大型语言模型(LLM)领域。我们的目标是挖掘、分析并分享那些能够启迪思维、推动科学进步的优质学术论文。我们坚信,知识的传播和交流是促进创新和社会发展的关键力量。
论文标题
A Survey of Knowledge Graph Reasoning on Graph Types: Static, Dynamic, and Multi-Modal
在图类型上的一项知识图谱推理调查研究:静态、动态、和多模态
论文链接
https://ieeexplore.ieee.org/document/10577554
摘要
知识图谱推理旨在基于挖掘知识图谱底层逻辑规则,从现有的事实中推断出新的事实,已成为一个快速发展的研究方向。事实证明,在很多AI应用领域,知识图谱的使用是非常有益的。例如,问题回答,推荐系统等。根据图的类型,现有的知识图谱推理模型被分为以下三个类别:静态模型,时序模型和多模态模型。在这个领域早期的工作主要集中于静态KGR,近期的工作尝试利用时序和多模态信息,这些工作更加的真实且更接近于现实世界。然而,没有一项研究文章和开源库完整的总结和讨论这些模型在这些重要领域。为了填补找个空白,我们首先对知识图谱推理追溯从静态到时序甚至到多模态知识图谱进行研究。具体而言,这些模型被重新审视基于两类分类学,顶层(图类型)和基础类型(技术和场景)。除此之外,还对性能和数据集进行了总结和介绍。更进一步的,我们提出了一些挑战和潜在的机遇给予读者启示。相应的开源库被分享在GitHub上:
https://github.com/LIANGKE23/Awesome-Knowledge-Graph-Reasoning
介绍
人类学习技能从两种主要来源,专业书籍和工作经验。例如,一个优秀的医生需要从学校获取知识,并从医院得到实习经历。然而,大多数现有的人工智能模型仅能模仿学习过程从经验中却忽略了前者,那么这将使得他们缺少可解释性和糟糕的性能表现。知识图谱将人类知识存储在直观的图结构中,被视为潜在的解决方案。然而,知识图谱的结构是不停的变化和持续的过程,甚至大部分知识图谱遭受不完备的问题,阻碍他们在知识图谱助力的应用性能,例如,问答和推理系统等等。为了缓解这些问题,知识图谱推理在这些年关注度逐渐上升。他的目的是从现有的知识图谱中推断出缺失的事实。将图1中的a作为目标知识图谱,知识图谱推理模型被期望去驱动逻辑规则在(A,father of,B)^(A,husband of,C)->(C,mother of,B),那么更进一步的推断出缺失的事实(Savannah,mother of Bronny)。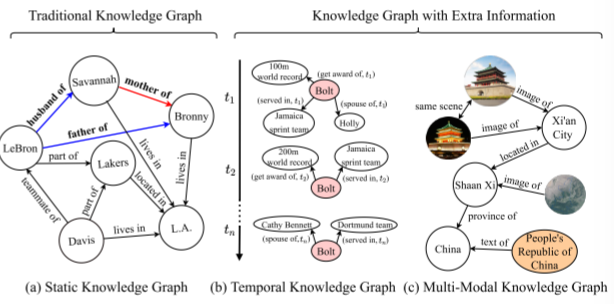
根据知识图谱中的信息类型,当前知识图谱能被粗略的划分为三类,静态图谱,动态图谱和多模态图谱,如图1所展示.传统知识图谱仅包括静态单一模态知识,这对于建立通用的基本KGR模型是有效的。然而,他们仍不能充分的描述真实世界场景,因为真实世界场景是由各种来源的信息所组成的。那么,近期的KGs(例如,动态KGs和多模态KGs)通过整合额外的时序和多模态信息基于静态KGs组成,这更加的正式和接近于真正的世界。然而,无论是哪种KGs类型,不完备问题仍然存在。因此,各种改进的KGR模型不断的在发展和研究在这些年李为了更好的推理性能。当然,一个有价值的信息是,对于和不同KGs类型KGR模型的核心问题是不同的。特别多,静态KGR模型集中在学习能力的通用表达。然而,如何融合额外的信息更好是时序和多模态KGR模型的关键。此外,以便进行更全面和系统的审查,两个下游任务,推理技术和推理场景,将在每个图类型中进一步讨论。
有很多KGR的研究论文。他们中的大多数仅关注静态KGR而忽略了其他KGR的最新发展,例如时序KGs和多模态KGs。【P. Hitzler, K. Janowicz, W. Li, G. Qi, and Q. Ji, “Hybrid reasoning in knowledge graphs: Combing symbolic reasoning and statistical reasoning,” Semant. Web, 2020.】首先将KGR任务分类符号推理和统计推理。另外,【J. Zhang, B. Chen, L. Zhang, X. Ke, and H. Ding, “Neural, symbolic and neural-symbolic reasoning on knowledge graphs,” AI Open, 2021.】划分KGR模型三种类型,为符号,神经和混合。在那之后,【W. Zhang, J. Chen, J. Li, Z. Xu, J. Z. Pan, and H. Chen,“Knowledge graph reasoning with logics and embeddings: Survey and perspective,” arXiv preprint arXiv:2202.07412, 2022.】和【Y. Chen, H. Li, H. Li, W. Liu, Y. Wu, Q. Huang, and S. Wan, “An overview of knowledge graph reasoning: Key technologies and applications,” Journal ofSensor and Actuator Networks, 2022.】提出了更加细粒度的分类,分为基于逻辑的和基于嵌入的KGR模型。最近,【M. Chen, W. Zhang, Y. Geng, Z. Xu, J. Z. Pan, and H. Chen, “Generalizing to unseen elements: A survey on knowledge extrapolation for knowledge graphs,” arXiv preprint arXiv:2302.01859, 2023.】分析了KGR模型对于未知元素的泛化性能。至于时序知识图谱,【B. Cai, Y. Xiang, L. Gao, H. Zhang, Y. Li, and J. Li, “Temporal knowl-edge graph completion: A survey,” arXiv preprint arXiv:2201.08236, 2022.】重新审视了现有模型根据事实时间戳捕捉时间动态的方式,但是并没有明确区分时间KGR 的插值和外推情景。作为最具影响力的多模态知识图谱调查,【X. Zhu, Z. Li, X. Wang, X. Jiang, P. Sun, X. Wang, Y. Xiao, and N. J. Yuan, “Multi-modal knowledge graph construction and application: A survey,” arXiv preprint arXiv:2202.05786, 2022.】更多的关注结构和应用,而不是对他们进行推理。相比较于现有的研究调查,我们进行了更加全面对于知识图谱的研究。详情可见下表: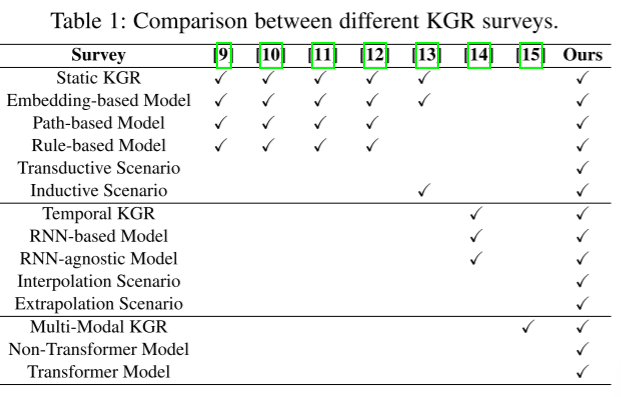
更具体的说,利用双层分类法进行审查,即顶层(图类型)和基层(技术和场景)。特别地,我们更关心讨论推理场景对于以上提到的模型,例如,静态KGR的转换和归纳方案,以及时间KGR的插值和外推方案。
总而言之,我们是第一个在不同图类型上全面调查现有KGR模型的,包括传统KGs(静态KGs)和带有额外信息的KGs(时间KGs和多模态KGs)。具体来说,我们首先进行初步介绍。下一步,我们系统性的回顾近期最先进的KGR模型从3段到5段基于双层分类法和性能表现。在那之后,我们组织和收集了经典的KGR数据集在第6段。之后,在第7段提出挑战和潜在的机遇。最后,在第8段总结文章。为了更好的赋予这篇文章价值,我们总结了主要的贡献如下:
- 全面的审查:我们全面研究了基于双层分类法的典型KGR模型,即顶层(图类型)和底层(技术、场景)。包括三种图类型(即静态、时间、多模态KGs)、十四种技术和四种推理场景,为KGR提供了系统的综述。
- 深刻的分析:我们分析现有KGR模型的长处和短处以及他们的适用范围,这将为读者提供有用的指导以便选择他们研究的基线。
- 有潜力的机遇:我们总结了KGR的挑战以及提出一些潜在的机遇给读者启发。
- 开源库:我们分享了手机的180先进模型和67个典型数据集在GitHub上。
准备工作
在本节中,我们首先正式定义静态、时序和多模态知识图。接下来,制定了不同类型的KGs和场景的推理任务。最后,介绍了KGR模型的分类准则。
定义和符号
知识图谱可以看作是图形化的知识库,他继承了传统知识库的大部分功能,例如存储和索引等,但是更加直观。现有的知识图谱能被粗略划分为三种类型,静态,时序和多模态知识图谱。根据先前的文献,将他们的定义声明如下, 注释被总结在表中:
定义1:静态知识图谱。静态知识图谱被定义为SKG={S,R,F},这里S和R和F分别被表述成实体集合,关系集合,和事实集合。这个事实被规范成三元组格式(eh,r,et)∈F,其中,eh,et∈S,并且r∈R。注意静态知识图谱也被称作传统知识图谱。“静态”一词是为了区别于其他KG类型。
定义2:时序知识图谱。时序知识图谱被定义为一种静态知识图序列在不同的时间戳下:TKG={SKG1,SKG2,…SKGt}。时间戳为t的KG快照定义为SKGt={S,R,Ft},其中S,R是实体和关系的集合,Ft是事实的集合在时间戳t∈T情况下。四重事实(eh, r, et, t)表示在时间戳t的头部eh和尾部et之间存在关系r。
定义3:多模态知识图谱。多模态知识图MKG由存在多个模态的知识事实组成的。根据其他模态数据的表示方式,有两个多模态KG[X. Zhu, Z. Li, X. Wang, X. Jiang, P. Sun, X. Wang, Y. Xiao, and N. J. Yuan, “Multi-modal knowledge graph construction and application: A survey,” ArXiv, 2022.],即N-MMKG和A-MMKG(见下图)。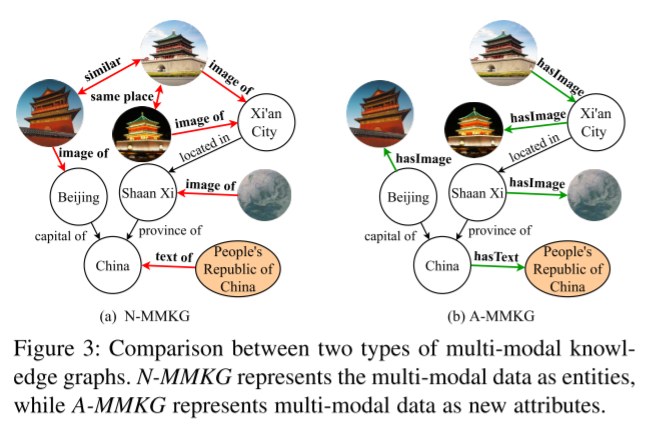
任务制定
KGR的目的是在现有的基于逻辑规则驱动下的事实中推断出新的事实。基于图类型,KGR能被分类成以下三个任务:静态KGR,时序KGR和多模态KGR。在他们之中,由于额外的时间和视觉信息分别被整合到时态和多模态KGR中,因此与静态KGR相比,任务表示存在细微差别。此外,还介绍了推理场景的两组术语,转换和归纳场景和插值和外推场景,以便更好地理解我们的分类法。时间分为转换和插值,多模态分为归纳和外推。
- 静态知识图谱推理:给定一个静态KG, E K G = { E , R , F } \mathcal{EKG}=\mathcal{\{E,R,F\}} EKG={E,R,F},KGR目的是利用现存的知识推断出需要的事实( e h q , r q , e t q e_{h}^{q},r_q,e_t^q ehq,rq,etq)基于概率计算的得分函数。依据缺失的元素类型,有以下三种下游任务。头部推理( ? , r q , e t q ?,r^q,e_t^q ?,rq,etq),尾部推理( e h q , r q , ? e_h^q,r^q,? ehq,rq,?)和关系推理( e h q , r , e t q e_h^q,r,e_t^q ehq,r,etq)
- 时序知识图谱推理:给定一个时序知识图谱, T K G = { S K G 1 , S K G 2 , . . . . . , S K G t } \mathcal{TKG=\{SKG_1,SKG_2,.....,SKG_t\}} TKG={SKG1,SKG2,.....,SKGt},其中 S K G t = { E , R , F t } \mathcal{SKG_t=\{E,R,F_t\}} SKGt={E,R,Ft}和时间戳 t ∈ T t \in \mathcal{T} t∈T,KGR的目的是推断出四元组事实 ( e h q , r q , e t q , t q ) (e_h^q,r^q,e_t^q,t^q) (ehq,rq,etq,tq)。和静态KGR相同,在特定的时间戳t^q也在相同的三个下游任务。
- 多模态知识图谱推理:多模态知识图谱推理和其他几个KGR类型相同,推理缺失的事实。除此之外,通常需要额外的融合模块来利用多模态信息以获得更好的推理性能。
- 转换和归纳推理场景:依据训练期间查询实体和关系的可见性,有两种推理场景类型。详见下图:
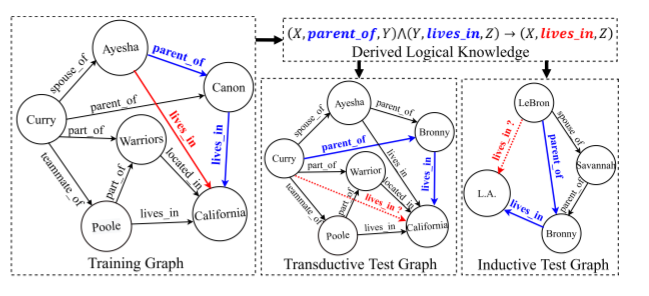
具体来说就是:在转换场景中,测试图中的实体在训练过程中都是可见的。而对于归纳场景,测试图中可能存在看不见的实体。在转换场景中,会存在原有的事实,即(Ayesha,parent_of,Canon)^(Canon,lives_in,California),而归纳中该事实则不存在。在转换场景中,查询事实中的实体和关系都在给定的KG中看到。在归纳场景中,候选的实体和关系可能超出给定的KG。这种两种场景通常在静态知识图谱中讨论。 - 插值和外推推理场景:根据查询事实 t q t^q tq的发生时间,时序KGR可以被分为两类。详情看下面图:
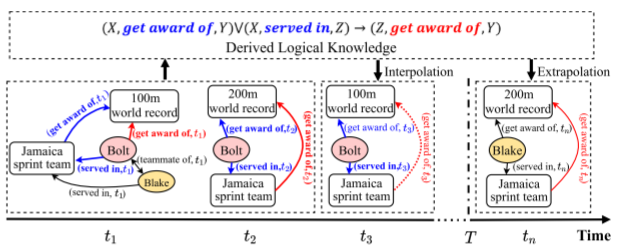
插值和外推场景。具体来说,给定时间戳为0到T的时间KG,插值推理的目的是推断时间t的查询事实,其中0≤t≤T;此外,外推推理的目的是推断时间t的查询事实,其中t≥T。这两种情况通常在时间KGR中讨论。也就是说,一个是在时间内部,一个是在预测。
分类设计
我们设计了一个双层方法分类来系统的回顾现有KGR模型。具体来说,采用三个分类标准对丛书的KGR模型进行分类,如:图类型、技术和场景。如图下所示: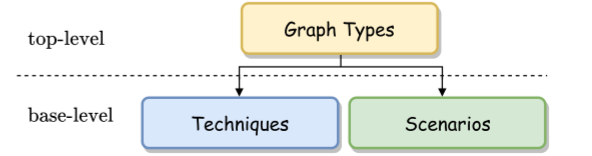 图类型是顶层分类法,它包含三种KG类型,即静态、时序和多模态KG。此外,基本层分类法由技术(14种)和场景(4种类型)组成。给定一个KGR模型,我们将首先根据顶层分类法对其进行分类,然后,我们将依据其具体的技术和场景进行进一步分类。正如前文所述,KGR针对不同的图类型,关注不同的技术和场景。具体地,(1)在技术方面,基于嵌入(五个子类型)、基于路径和基于规则的模型是静态KGR的典型技术.详见下图:
图类型是顶层分类法,它包含三种KG类型,即静态、时序和多模态KG。此外,基本层分类法由技术(14种)和场景(4种类型)组成。给定一个KGR模型,我们将首先根据顶层分类法对其进行分类,然后,我们将依据其具体的技术和场景进行进一步分类。正如前文所述,KGR针对不同的图类型,关注不同的技术和场景。具体地,(1)在技术方面,基于嵌入(五个子类型)、基于路径和基于规则的模型是静态KGR的典型技术.详见下图: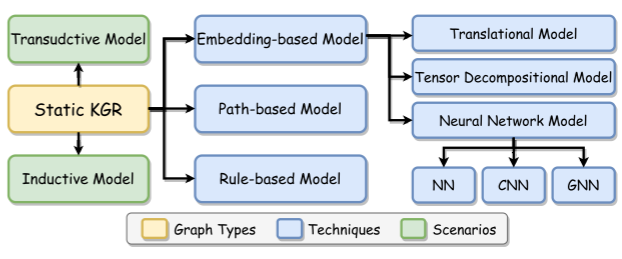
此外,基于rnn(3个子类型)和不可知rnn(2个子类型)模型是时序KGR模型设计的技术准则,见下图: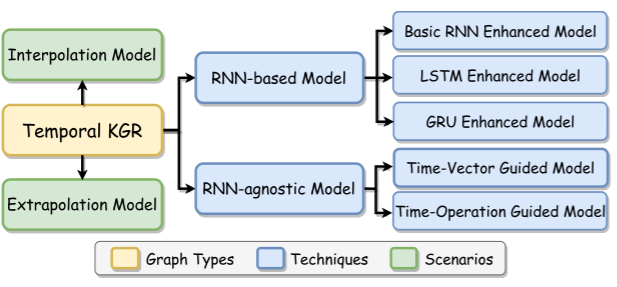
此外,基于Transformer和不可知Transformer是多模态KGR模型采用的技术准则。见下图: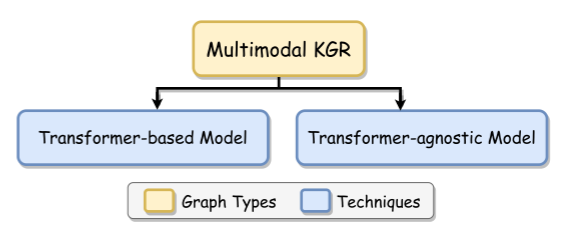
(2)至于推理场景,我们只讨论静态和时态KGR的分类,即静态KGR的转换和归纳场景,时态KGR的插值和外推场景。
静态知识图谱
我们系统的介绍了90个静态KGR模型基于技术和场景,见下表: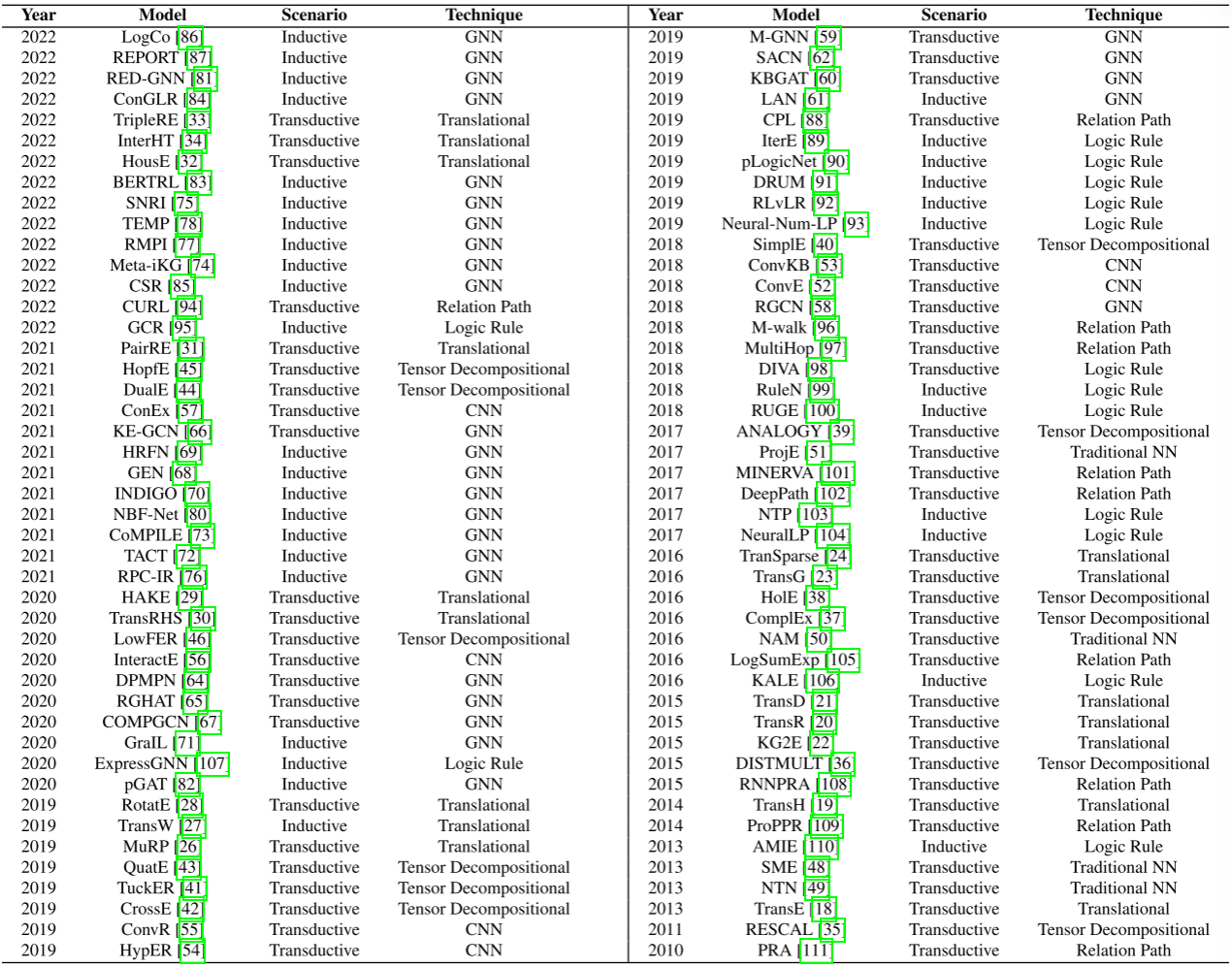
回顾推理技术
静态KGR模型能被分类成基于嵌入、基于路径、和基于规则模型,细节描述如下。
基于嵌入模型
基于嵌入模型学习嵌入向量基于现有的三元组事实和基于候选top k的评分实体。通常,一般来说由三种类型,平移,张量分解和神经网络模型。由于数量众多,基于嵌入的模型时间轴如下图所示: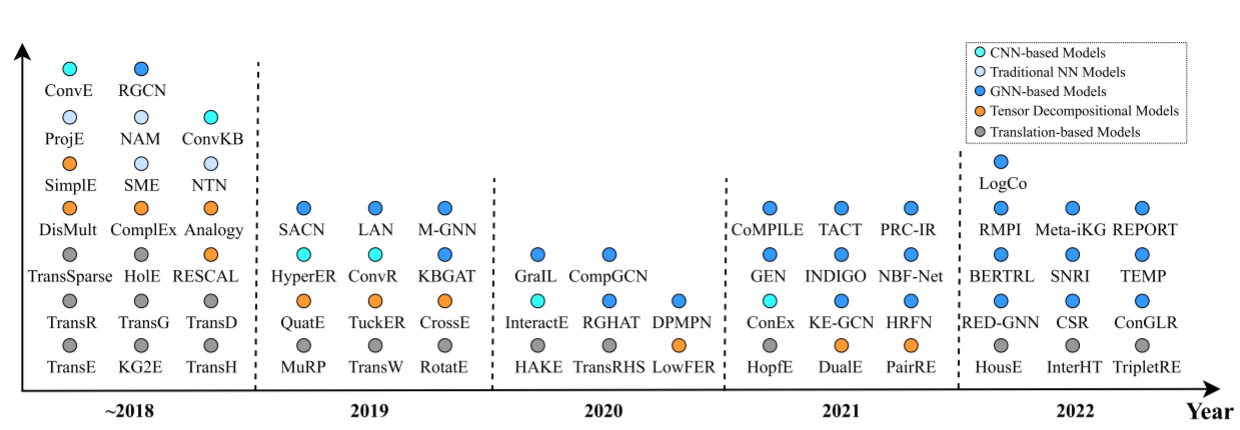
- 平移模型,平移模型将关系r看作是将实体e投影到潜在空间的平移变换。
TransE,是第一个平移模型,将关系作为一个简单的变换操作, e h + r ≈ e t e_h + r \approx e_t eh+r≈et。尽管被证明有效,但是他没有处理一些特殊关系,例如,一对多,多对一,对称关系和传递关系。为了解决这些限制,更多的平移模型被开发。在TransH中,实体被编码到关系特定的超平面中,这有了更好推理性能在一对多和多对一的关系上。除此之外,TransR利用实体和关系的不同潜在空间,对传递关系推理有更好的表达能力。在此之上,TransD首先考虑可伸缩性问题,通过为大型KG的实体和关系利用独立的空间投影。之后,利用概率原理对KGR中的不确定性进行建模。例如,KG2E利用高斯分布协方差并且TransG对一对多关系事实使用贝叶斯技术。与此同时,为了缓解异质性和不平衡问题,TranSparse提出了一个有效的解决方案,通过设计适应的平移矩阵,进而引导更好的表达能力。之后,TorusE在紧李群环面上投影嵌入。以及MuRP设计了一个M¨obius矩阵向量乘法,M¨obius添加实体嵌入投影,这些都展示出更好的准确性和可扩展性。期间,TransW首次用词嵌入丰富了实体嵌入和关系嵌入,在用看不见的实体或关系推断事实时获得更好的性能。此外,RotatE出了一个基于关系的评议方法在复杂的嵌入以获得更好的推理对称、反对称、反转和组成事实。在这之后,HAKE建模予以层次而不是基于极坐标空间的关系模式。那么TransRHS首次考虑关系层次结构通过将RHS无缝整合到嵌入中。此外,为了处理复杂的关系事实以统一的模型,PairRE建模每个关系表达用成对向量表达,实现复杂关系的自适应调整。HousE涉及一种基于设计的用于旋转和投影的Householder变换的新参数化。目前,对于更充分的相互作用,也有一些有趣的翻译模型的尝试,如TripleRE和InterHT。TripleRE创造性地将关系向量分成三个部分,利用残差的概念,达到了更好的性能。而InterHT增强了尾巴和头部之间的信息交互,提高了模型的容量。 - 张量分解模型,张量分解模型编码知识图谱为三种张量,分解为实体和关系的低维向量的组合。
作为第一个张量分解模型,RESCAL捕获潜在的实体向量语义,进一步利用矩阵将潜在因素之间的两两相互作用建模为矩阵。然而这个模型有着 O ( d 2 ) O(d^2) O(d2)的参数量。为了简化这个,DistMult使用双线性对角矩阵来减少参数量到 O ( d ) O(d) O(d)。接着,ComplEx归纳了DistMult通过使用机制的复杂嵌入,这提升了不对称关系模型。之后,HolE建模了holographic reduced representations
and circular correlation并且,Analogy设计双线性分数方法去类比推理的类别结构约束,它们都试图捕捉实体之间丰富的交互。然后,一些模型开始替换分解操作。SimplE增强了Canonical Polyadic(CP)分解应用于两个独立的实体嵌入,并且Tucker分解是第一次被使用于Tucker。更进一步的CrossE通过特定于关系的交互矩阵考虑实体自检的交叉交互。QuatE基于关系旋转的四元组表征给予头和尾模式匹配。受到他的启发,DualE映射这些嵌入到双重四元组空间目的是实现一个统一的平移和旋转操作框架。除此之外,HopfE在不失可解释性的前提下,利用了四维超球空间的结构属性和语义属性。近年来,除了表达能力,效率也越来越受到关注。提出了一种基于Tucker分解的因式双线性池化模型,称为LowFER,他是一种效率更高、重量更轻的。QuatRE用两种新颖的操作学习四元数嵌入,利用Hamilton积增强实体间的相关性,简化实体嵌入,减少计算量平移矩阵。 - 神经网络模型:神经网络模型在KG推理中取得了显著的效果。这有三个子类型被定义神经网络技术:传统的神经网络、卷积神经网络和图神经网络。
1)传统神经网络:SME首次编码实体和关系到潜在的空间使用神经网络。期间,在NTN中神经张量网络被用于关系推理在知识图谱中。之后,NAM提出一种关系调制神经网络(RMNN)并且神经网络在ProjE中共享变量,他们通过标准损失函数共同学习实体和关系的嵌入。这些传统的神经网络模型展现出巨大的潜力在静态知识图谱推理中,但它们学习的特征较浅,表达能力较差。
2)CNN模型:为了学习更深层的特征,卷积神经网络于MKGR模型相结合。ConvE首先利用2D卷积层在KGR上。ConvKB通过删除重塑操作来扩展ConvE,并捕获事实中的全局和过渡特征以进行信息表达。后来,HypER使用全连接层和特定关系的卷积过滤器为了更好的性能。此外,ConvR设计一个自适应的卷积网络,通过在实体和关系表示之间构建卷积过滤器来最大化实体-关系交互。之后,还有一些新颖的操作,例如特征重塑,特征置换和循环卷积,他们都被设计于InteractE以用于解决复杂的交互。此外,ConEx用卷积运算对复值嵌入上的仿射变换和厄米内积进行积分,这展现了很好的表达能力。CNN模型通常比传统的NN模型表现得更好。然而,图结构背后的信息不能很好地学习
3)GNN模型:图神经网络,被广泛应用于图任务,也能迅速应用于KG推理。RGCN使用这种特定关系变换去聚合邻居信息。接着,每个实体被编码成一个向量,然后被解码。例如,打分方法,基于实体表示重构事实。而RGCN省略了实体的差异,这阻碍了表达能力。为了缓解这一效应,注意机制被整合到许多模型中,例如,M-GCN,KBGAT和【P. Wang, J. Han, C. Li, and R. Pan, “Logic attention based neighborhood aggregation for inductive knowledge graph embedding,” in Proc. of AAAI, 2019.】。特别是,KBGAT利用基于注意力的特征嵌入虚的了更好的推理性能。之后,SACN利用图卷积神经网络权重作为编码器以及一个卷积神经网络被叫做Conv-TransE作为解码器,这是很有效的。在这之后,TransGCN同时使用关系的变换算子训练关系和实体嵌入。之后,DPMPN和RGHAT设计了一个两个GNN框架来同时编码信息在不同的层级上,例如,DPMPN使用全局和局部信息和RGHAT使用关系和实体信息。在那之后,KE-GCN扩散和更新了实体和边的嵌入。相同的情况,COMPGCN也学习不同实体和关系的表征组合操作。近期,越来越多的研究者开始尝试去解决知识图谱外的场景。GEN和HRFN学习实体嵌入基于元学习在可见到不可见与不可见到不可见事实。INDIGO被踢出它是基于GNN的利用成对的编码。此外,基于GraIL的模型他是一个传统的GNN模型群为了归纳场景的。这个GraIL原型,作为GNN模型的里程碑,首先利用RGCN去基于局部封闭子图执行推理。在此基础上,更多的工作开展起来。例如TACT,CoMPILE,MetaiKG,SNRI,RPC-IR等等。这些基于GraIL方法全都取得了有前途的归纳表现。在他们之中,TACT和CoMPILE都提高关系嵌入的重要性在任务中。具体来说,TACT使用关系之间的拓扑感知相关性,以生成三重评分的表示。这给RMPI和TEMP提供了启发。除此之外,CoMPILE增强信息交流在实体和关系之间以新颖的方法。在那之后,由对比及时驱动的获得成功。【K. Liang, Y. Liu, S. Zhou, X. Liu, and W. Tu, “Relational symmetry based knowledge graph contrastive learning,” 2022.】和【T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Proc. of ICML, 2020.】对比学习模型越来越被提出。例如,RPC-IR,SNRI等等。除此之外,Meta-iKG证明了元学习在KGR任务的有效性。在此之后,研究人员尝试更好的推理性能。NBF-net和RED-GNN实现更好有效性通过利用传统的算法。例如,采用bellman-ford算法和动态规划对以往GNN模型中的传播策略进行优化。此外,pGAT利用EM算法来获得更好的效率学习。在喝粥BERTRL和ConGLR利用上下文对于每个实体去推理KG。特别是,BERTRL能处理不可见的关系的事实。关于这个,CSR深入挖掘结构模式下的逻辑规则,而不是路径。
基于路径模型
基于路径模型挖掘被查询的头部和尾部之间的路径背后的逻辑知识来实现推理。
随机漫游推断,已经被广泛研究。例如,Path-Ranking算法(PRA)在路径约束下到处基于路径的逻辑规则。ProPPR通过结合文本内容进一步引入空间相似启发式,缓解PRA中的特征稀疏性问题。同时,还研究了基于神经网络的多跳路径模型,以获得更好的表达能力。通过迭代地使用组合性,RNNPRA利用RNN来组合用于推理的关系路径的含义。LogSumExp设计了一种跨所有元素的逻辑组合方法,并具有多重推理的注意机制。DIVA提出了统一的变分推理框架,它将多跳推理分为两步,即寻径和路径推理。深度强化学习(DRL)技术,如马尔可夫决策过程(MDP),最近被用于将实体之间的寻路重新表述为顺序决策任务。所设计的强化学习智能体根据实体间的相互作用学习寻找推理路径,并利用相应的策略梯度进行训练。具体来说,不同的细粒度方法被用于不同的模型。例如,DeepPath应用DRL在关系路陷阱学习上通过新颖的反馈,和关系的行动空间提高模型的表现能力和效力。此外,MINERVA寻找实体之间的路径作为一个顺序优化问题,通过最大化奖励期望,这排除目标答案实体以进行更有能力的推理。在这之后,MultiHop设计一个软反馈方法来替代仅依赖的二重奖励,以及dropout动作,这是的更效率的路径被发现。此外,M-Walk使用蒙特卡罗树搜索(Monte Carlo Tree Search, MCTS)来生成路径,CPL通过利用实体对应的文本语料库,提出了用于寻路和事实提取的协作策略学习。此外,CURL中提出了两个不同级别的AGENT,即实体级别的DWARF AGENT和集群级别的GIANT AGENT,它们相互协作以实现最优的推理性能。
基于规则模型
基于规则的模型旨在更好的利用逻辑规则的这种符号特征,逻辑规则通常以B->A的形式定义,其中A是一个事实,B可以是一组事实。
逻辑规则能被扩展用于KGR通过逻辑挖掘工具,例如AMIE,RuleN等等。那么,RLvLR设计了一种更大尺度的规则挖掘方法通过路径搜索技术。在那之后,如何在嵌入中注入逻辑规则以获得更好的推理性能已经引起了越来越多的研究关注。通常来说,有两种方法可以实现,一种是联合学习,一种是迭代训练。例如,KALE是一种通义的联合模型通过利用相容事实与规则嵌入之间的规范模糊逻辑连接。除此之外,RUGE是一个可迭代的模型使用软规则在嵌入修正。受此启发,这种迭代训练策略由嵌入学习、公理归纳和公理注入组成,由IterE设计。之后,研究者们将神经网络技术同基于规则的模型相结合,目的是缓解性能限制和巨大的空间消耗在之前的基于规则的模型上。神经定理证明者(NTP)利用设计的径向核挖掘逻辑规则。NeuralLP利用注意机制和辅助记忆来优化挖掘规则的梯度,Neural-Num-LP进一步将累积和运算和动态规划与NeuralLP相结合,学习数值规则。同时,提出了一种基于规则的端到端可微模型DRUM。在pLogicNet中设计了概率逻辑神经网络,在一阶逻辑挖掘中表现出良好的性能。ExpressGNN通过微调GNN模型来进一步推广它,以获得更有效的推理。此外,GCR通过挖掘所查询事实周围的邻域信息,为推理和推荐提供了良好的性能。
回顾推理场景
根据我们的观察,有56个直推模型和34个归纳模型,他们只有56.25%翻译模型是基于GNN模型的,37.5%是基于规则模型。具体来说,没有一个基于路径的模型显示出令人难以置信的推理归纳能力。尽管如此,大多数基于规则的模型都擅长归纳场景,这是合理的。由于基于路径的模型是建立在搜索特定路径的基础上的,所以当出现看不见的元素时,以这种方式训练的模型很难应用。而大多数基于规则的模型可以从KGs中推导出与实体不可知的逻辑规则,并且规则带来的不变性可以很容易地应用于归纳场景。此外,我们还分别对典型的SOTA静态KGR模型在直推和归纳场景下的性能进行了比较(见表4和表5)。结果支持上述分析。此外,基于嵌入的模型,特别是GNN模型,在这两种情况下都显示出良好的容量和兼容性,也是最近研究的大部分内容。
回顾和讨论
基于以上综述,我们可以得到以下观察结果,这些观察结果可能表明不同静态KGR模型的适用范围,并揭示静态KGR的未来趋势。(1)基于嵌入的模型一般具有较好的表达能力,但缺乏可解释性。同时,由于KGR模型需要高质量的关系事实表示和图结构,因此基于GNN的模型的开发受到了更多的关注,这是最适合GNN模型的。(2)基于路径和基于规则的模型比基于嵌入的模型更具可解释性,但它们的表达能力有限,且时间和空间的复杂性较大。(3)大多数基于路径的模型由于采用了路径搜索方案而更适合于转换推理,而基于规则的模型由于规则范式的泛化而自然地继承了归纳能力。(4)长期以来,转换推理模型不断出现,对学术研究和工业应用都产生了很大的影响。然而,由于可扩展性和表达能力的问题,研究人员最近把重点放在了归纳推理模型的开发上。作为一个简短的结论,我们鼓励更多地研究基于gnn的模型,这被认为是静态KGR最有前途的模型类型
个人总结
本质上,知识图谱是个三元组集合,然后依据将三元组进行不同的建模作为输入,分为了,基于嵌入的模型,基于路径的模型,基于规则的模型。根据如何处理三元组作为输入,以及如何建模其语义和关系,知识图谱的模型可以分为以下三类:
(1) 基于嵌入的模型(Embedding-based Models)
输入:直接以三元组 <h, r, t> 为输入,关注单跳关系。
建模方式:
为每个实体(h, t)和关系(r)学习低维向量表示(embedding)。
通过优化评分函数(如 TransE 的 h + r ≈ t),捕捉三元组的语义。
特点:
聚焦局部(单跳)关系,嵌入是“静态”的,针对训练图优化。
通常为传递模型(Transductive),难以泛化到新节点。
计算效率高,适合大规模图,但对复杂多跳关系建模能力有限。
例子:TransE、DistMult、ComplEx、RotatE。
适用场景:简单链接预测、实体分类。
(2) 基于路径的模型(Path-based Models)
输入:以三元组为基础,关注图中实体之间的多跳路径(如 <h, r1, e1, r2, t>)。
建模方式:
显式或隐式利用路径信息,捕捉复杂语义。
可能通过嵌入表示路径(如 PTransE 用 RNN 建模路径序列),或通过路径特征增强实体/关系表示(如 CompGCN)。
特点:
强调多跳关系的语义,可为传递模型或归纳模型(Inductive)。
比嵌入模型更能捕捉复杂关系,但计算复杂度较高。
路径选择和噪声处理是关键挑战。
例子:PTransE、Path-RNN、CompGCN、PRA。
适用场景:复杂关系推理、多跳路径预测。
(3) 基于规则的模型(Rule-based Models)
输入:以三元组为基础,挖掘路径模式并抽象为逻辑规则。
建模方式:
从图中挖掘显式逻辑规则(如 <X, 妻子, Y> ∧ <Y, 母亲, Z> → <X, 父亲, Z>)。
利用规则进行符号推理,推导新三元组或验证图的正确性。
特点:
高度可解释,规则以逻辑形式表达。
通常为归纳模型,规则可泛化到新节点或新图。
挖掘高质量规则成本高,覆盖率可能有限。
例子:AMIE、RuleN、AnyBURL。
适用场景:多跳推理、知识图谱补全、错误检测。
时序知识图谱推理模型
我们系统的介绍了58时序知识图谱模型以及现有的技术,例如他们如何整合时间信息和应用场景。详情看下表: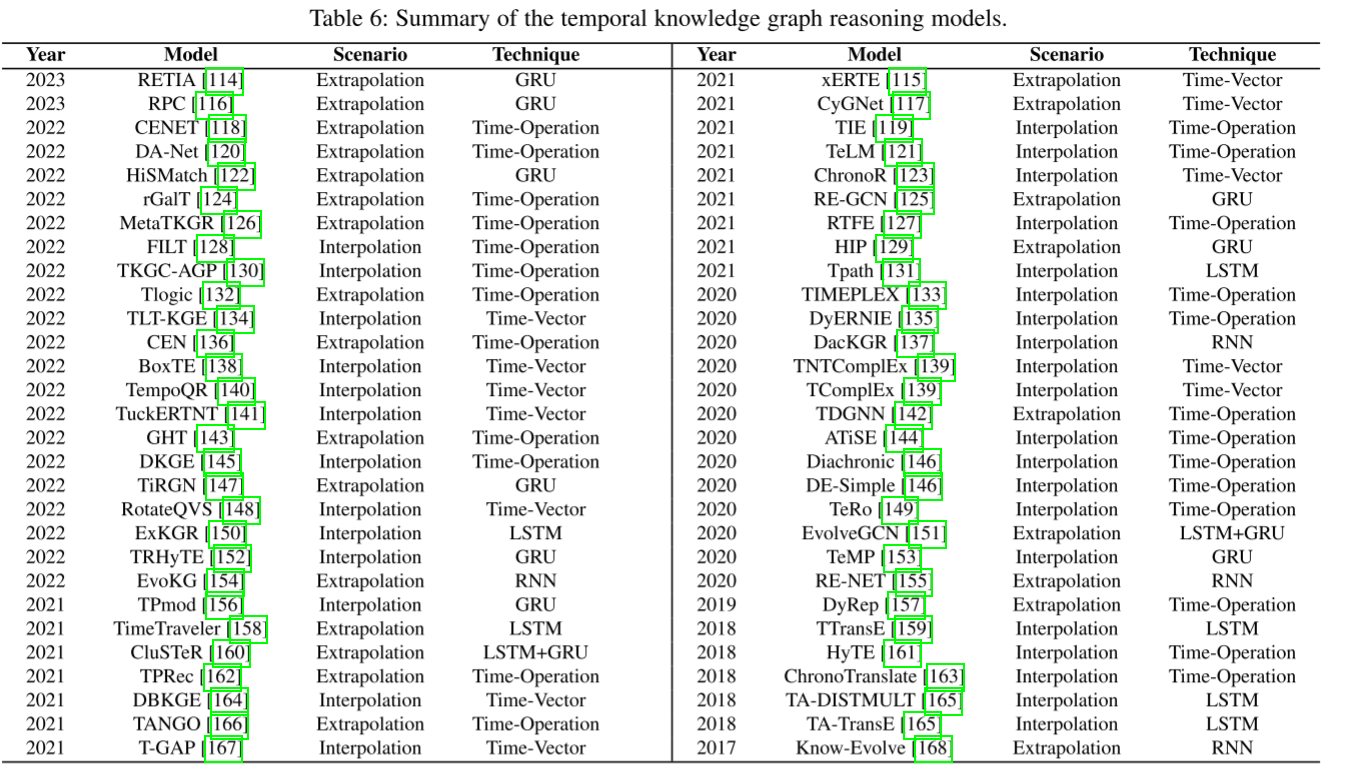
推理技术回顾
时序知识图谱模型能被分类为基于RNN和非RNN模型。细节如下
基于RNN模型
循环神经网络适合于挖掘随时间的变化。因此大多数时间KGR模型使用RNNs去直接建模时间信息。根据不同的RNN变种,这些模型被分为以下三种:基于RNN增强模型,LSTM增强模型和GRU增强模型。
- 基于RNN增强模型。一些时序KGR模型能有效果的建模时间信息使用基于RNN模型。举几个例子,Know-Evolve是一个经典的时序KGR模型,该模型生成非线性的实体嵌入随着时间推移。RE-NET应用GCN和RNN模型去捕获动态进化在时序知识图谱中图查询随着时间推移。EvoKG介绍RNN模型去挖掘动态结构信息并且建模实体交互信息同邻居。
- LSTM增强模型。长短时记忆网络(LSTM)也被广泛应用在挖掘时间特征中。例如,TTransE同增加时间限制和建模时间信息以翻译类似于与RNN的关系目的是这些翻译到头部表达在嵌入空间中从而扩展了TransE。TA-TransE和TA-DistMult也是两个扩展版本在TransE和DistMult合并了时间嵌入。更进一步,EvolveGCN采用图卷积的方法去建模图结构在静态的快照中,并且利用LSTM模型去演化GCN权重随着时间推移。CluSTeR使用LSTM和GRU模型,采用强化学习来发现进化模式。DacKGR执行多条基于路径推理在时间稀疏的KGs通过使用时间信息为了动态预测。为了捕获时间间隔信息和引导模型学习,TimeTraveler提出了一个交互时间编码模块和一个时间重塑反馈模块基于狄利克雷分布。TPath也引入LSTM模型去挖掘当前环境信息和生成关系嵌入以及时间嵌入通过环境激活功能。ExKGR引入LSTM在时序KGs中进行推理,并提供了推理路径。
- GRU增强模型。基于GRU模型这些年来受到的广泛关注。近期,TeMP被提出,它利用信息传递图神经网络(MPNNs)去学习基于结构的实体表示在一些时间戳中,并且从所有的时间戳中聚合表示使用一种编码器。RE-GCN将注意力集中在可简化的动态中,通过在最近几个时间戳上对固定长度的KG序列进行建模来生成实体嵌入。TPmod聚合实体的结构特征和关系和学习动态权重在不同的事件上。HIP模型传递来自时间、结构和重复透视图的信息,这些透视图分别用于挖掘图的动态演变、同一时间步的事件交互以及已知事件。TRHyTE使用GRU首先去转换实体到潜在空间并且编码事实到关系的时间超平面为了关系感知的时间表示生成。TiRGN使用两个编码器去挖掘信息在局部和全局层面。HiSMatch提出不同的编码器去挖掘历史查询结构和候选实体的语义信息。
非RNN模型
非RNN在原有的静态MKGR模型上进行扩展,通过合并时间信息而不是使用RNN架构。根据时间信息如何去引导模型,他们被粗略的划分为两种类型,1.时间向量引导。2.时间操作引导。
- 时间向量引导模型。时间向量引导模型之间生成额外的时间嵌入 t t t作为额外的附件时间信息并且融合他们到事实嵌入中。TComplEx和TNTComplEx都源于ComplEx,其中附加考虑时间信息的四阶张量空间由它们建模。在构造子图的过程中,时间嵌入被用于计算权重表示在xERTE中。接着,T-GAP编码了特殊查询的结构模型在TKG中,并且使用基于路径的推理方法。CyGNet尝试去解决实体预测任务通过编码历史事实同客观实体相关联在每一个查询中并且时间索引向量被生成。ChronoR在RotatE的基础上构建,它将关系和时间嵌入相连接去获取全部的旋转嵌入应用在最终的实体表示中。更进一步的,DBKGE提出了一个在线的推理算法,随着时间的推移平滑节点的表示向量。BoxTE引入了一个新颖的盒子表示对于TKGR任务基于静态的KGR的BoxE方法。TuckERTNT提出了一个张量分解方法受到4-order 维度的扩展时间嵌入的Tucker分解方法。TempoQR生成特定于问题的时间向量,并利用这些向量来聚合特定实体及其时间戳。TLT-KGE捕获语义和时间信息作为夫空间的不同轴。RotateQVS目的考虑隐空间中随旋转操作的时间信息变化。
- 时间操作引导模型。时间操作引导模型利用一些特殊的操作,像是编码事实进入特定设计好的时间超平面和生成基于时间反馈,目的是使用时间信息来代替直接融合基于生成的时间嵌入 t t t。ChronoTranslate分别学习实体的普遍表示和时间特定表示。HyTE将每个时间戳表示为嵌入空间中的可学习超平面,将实体和关系嵌入投影到超平面中,并在投影上使用TransE评分功能。作为图学习和KGR的模型,DyRep捕获历史中的交错动态,这进一步参数化的时间关注表示网络。受到RotatE的启发,TeRo引入了一个时间引导的旋转操作方法在头和尾实体中,去演化事实的语义分数。历时嵌入将实体和关系嵌入与时间信息配对,映射到KGR模型空间中,从而定义了产生特定模型(如DE-TransE和DE-SimplE)的框架。由于在图随着时间的演化时间新的不确定,ATiSE映射实体和关系嵌入到高斯空间中根据时间戳。TDGNN引入一个新的时间聚合器去组合邻居的特征和时间信息从边中,目的是去计算最终的表示。为了挖掘动态图演化,DyDRNIE定义速度特征在切空间中并且鼓励实体表示去演化依据它。TPRec是一个兴趣推荐系统方法,它提出了一个有效的时间感知关系组件去构建一个合作KG使用时间感知的并且利用时间感知模块去推理。TeLM利用一个线性时间规则和多矢量编码器实现四阶张量分解进行推理。RTFE将时态KG视为一条马尔可夫链,从前一个状态过渡到下一个状态,然后通过在时间戳之间传递更新的参数/特征,递归地跟踪时态KG的状态转换。此外,TIE将经验重放和时间正则化结合到KGR中,学习时间感知增量嵌入。随着时间的推移,CEN[利用了长度感知CNN,通过简单到难的课程学习策略来处理历史事实。DKGE为每个实体和每个关系引入两种不同的表示。TLogic执行时间随机漫步,并在此基础上提取时间逻辑规则,从而获得更好的可解释性。TKGC-AGP利用多元近似高斯过程在事实编码上。除此之外,FILT利用元学习框架来推断时态KGR中不可见实体的事实。之后,rGalT首先在图内和图间两个层面设计了注意机制,利用历史语义。与此类似,DANet也试图学习不同历史时间戳上重复事实的注意权重。MetaTKGR通过对未来事实的临时监督信号作为即时反馈,动态调整从最近事实中为新实体采样和聚合邻居的策略。此外,CENET学习历史和非历史依赖关系来推断最潜在的事实。
推理场景回顾
根据观测结果,共有34种插值模型和24种外推模型(见表6)。其中,42.57%的外推模型属于时间操作模型,47.62%属于基于rnn的模型。特别是,我们观察到在基于rnn的模型中,插值模型和外推模型的比例非常接近(10:8)。同时,在TimeOperation模型中也可以发现类似的观察结果(12:9)。结果表明,基于rnn的模型和time-Operation模型在这两种情况下都表现出良好的兼容性。而且,最近的大多数研究都是这种类型的。与它们相比,时间向量模型只能在插值场景中表现更好,因为它们不能以如此原始的方式充分地获取时间信息。此外,我们对典型的SOTA时间KGR模型进行了公平的性能比较(见表7和表8)。根据研究结果可以得出类似的结论,支持上述分析。
观察与讨论
基于以上综述,我们可以进一步得到以下观察结果,这些观察结果可能表明不同时间KGR模型的适用范围,并揭示时间KGR的未来趋势。基于以上综述,我们可以进一步得到以下观察结果,这些观察结果可能表明不同时间KGR模型的适用范围,并揭示时间KGR的未来趋势。(1) 非rnn模型,即时间向量引导模型和时间操作引导模型,通常将时间信息作为附加属性,并以不同的技术将其整合到之前的静态KGR模型中。与基于rnn的模型相比,这种方式更加灵活。(2)时间矢量引导模型将时间信息作为额外的时间矢量t进行编码。这些模型虽然简单,但其性能主要取决于时间编码器和嵌入融合模块是否合适。与这些模型不同,时间操作引导模型设计特定的时间操作,这是特定于任务的。(3)基于rnn的模型通常比其他模型能更好地模拟时间信息,并且更容易用于外推场景。(4)外推推理仍处于早期阶段,仅占时间KGR模型的30%左右,仍有进一步探索的空间。总之,我们鼓励对基于rnn的模型进行更多的研究,rnn被认为是时态KGR最有前途的模型类型。
多模态知识图谱推理模型
在这一小节,我们将系统介绍32个MKGR模型,详情见下表: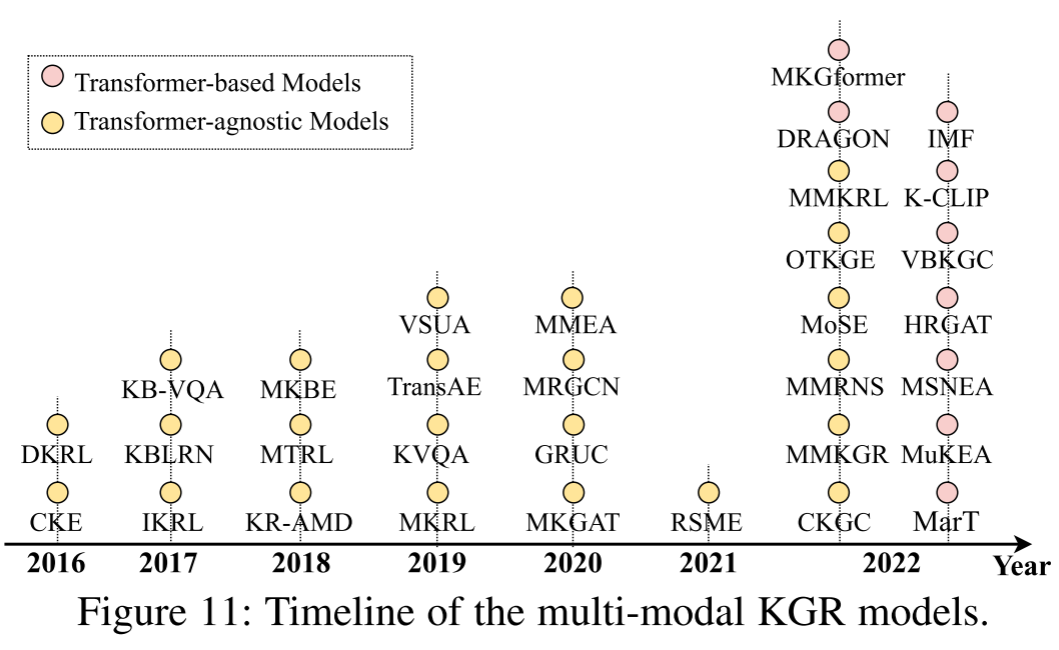
关于推理技术的回顾
直接将静态KGR模型应用到多模态场景通常结果是次优的,因为缺乏融合模块对于扩展的多模态信息。例如,文本呢,图像等等。基于融合这些多模态信息的技术,我们粗略的将MKGR模型划分为两类。一类是基于transformer的,另一种是不基于transformer的。
基于transformer模型
基于Transformer的模型在扩展到不同模态时具有良好的能力,因此通常被用作多模态问题的统一范式。尽管一些常用的多模态预训练transformer模型,例如VisualBERT,ViLBERT,也可以用于多模态KGR。由于这些多模态知识图谱和他的多模态数据的鞭挞,直接应用他们在更高的MPT模型到多模态知识图谱上进行MKGR可能不会带来很好的推理效果。受此启发,研究者们开始尝试去开发基于transformer的模型在MKGR上这些年。VBKGC利用与训练的transformer去编码多模态特征并且设计了一个多模态打分函数用于优化。之后,Knowledge-CLIP利用CLIP模型考虑多模态概念之间的语义连接,获得更好的预训练模型。之后,MarT首次提出了一个模态不可知的推理框架使用transformer在类比推理上。另外,一个混合transformer有着多级融合被设计在MKGformer,它统一学习范式在不同的下游任务上以一个通义框架。在这之后,HRGAT构建一个超节点图去聚合多模态特征生成通过transformer。除此之外,MSNEA和IMF使用对比学习在多模态对其方面。之后,MuKEA结合KGR在视觉理解和推理。DRAGON也提供一种方法在与训练上以一种自监督方法对于文本和知识图谱。然而,基于transformer的多模态KGR仍然处于一个早期阶段。
非transformer模型
大多数MMKGR模型生成和融合特征并不是使用transformer结构的,而是设计不同的方法用于编码额外的模态信息通过扩展原有的非模态的KGR模型,例如TransE。这些方法被命名为非transformer模型。
CKE是第一个联合执行推理和协同过滤的模型,这使其能够同时生成表示并捕获KGs中的隐式规则。之后,DKRL利用利用语言神经网络在知识库中的实体描述,为推理提供更具表达性的语义。受此启发,IKRL第一个设计一个基于注意力的神经网络来考虑视觉信息在实体图片上。诸如注意力的方法也被TransAE所使用。KBLRN第一个提出一个端到端的推理方法。它将神网络技术与潜在的、关系的和数值特征的专家模型相结合。在这之后,KR-AMD和MKRL利用文本数据作为附属数据的一部分来提高推理效果。除此之外,受到基于transfomer的静态KGR模型的启发,MTRL是一个基于翻译的模型有这三个能量方法与视觉、语言和结构信息相对应。此外,MKBE和MRCGN利用不同的神经编码器和解码器关系模型进行嵌入学习和多模态数据推理。MMKGR第一次调查如何有效的提高多模态额外数据特征的问题,目的是进行多跳推理在KG区域中用一个统一的注意力网络。MKGAT更好的增强推荐系统以多模态图注意力技术在多模态KG上进行信息传播。KG-VQA和VSUA在图像和额外的知识上执行推理,这提供了一个直观的方法去解释生成的答案。与他相似的是,KVQA整合知识和图像进行推理。MMEA设计一个联合损失用于多模态对立。此外。MoSE探索三个集成推理技术去整合模态分割预测通过模态重要性。最近,RSME设计了一个带有MRP度量的遗忘门,用于多模态KGR选择有价值的图像。这尝试去减少与实体不相应的图片噪声影响。HMEA投影多模态特征到一个超平面通过GCN。然而,OTKGE模建模多模态融合方法程序作为一个运输计划移动不同的模态嵌入到一个统一的空间通过最小化沃瑟斯坦距离。除此外MM-RNS和CKGC利用对比学习策略。MMKRL利用强化学习在MKGR。
观察和讨论
基于上述的回顾和性能对比(详见下表),我们可以进一步得到以下观察结果:最初,大多数多模态KGR模型是基于基于嵌入的静态KGR模型开发的,而不是基于路径的或基于规则的KGR模型。这主要是因为大多数现有的多模态KGR模型通过潜在空间的特征融合来利用额外的多模态信息。具体来说,不同的编码器是针对不同模式的功能而设计的。最近,研究人员倾向于研究统一的学习框架,如基于预训练transformer的模型,用于多模态特征。尤其是在大型语言模型(LLM)蓬勃发展之后。这些模型符合人工通用智能的要求,在这个时代更具有实用性和可扩展性。(3)与其他两种类型的KGR相比,多模态KGR的研究还处于起步阶段,针对多模态情景的模型仅占18%。总之,有很多空间需要深入探索。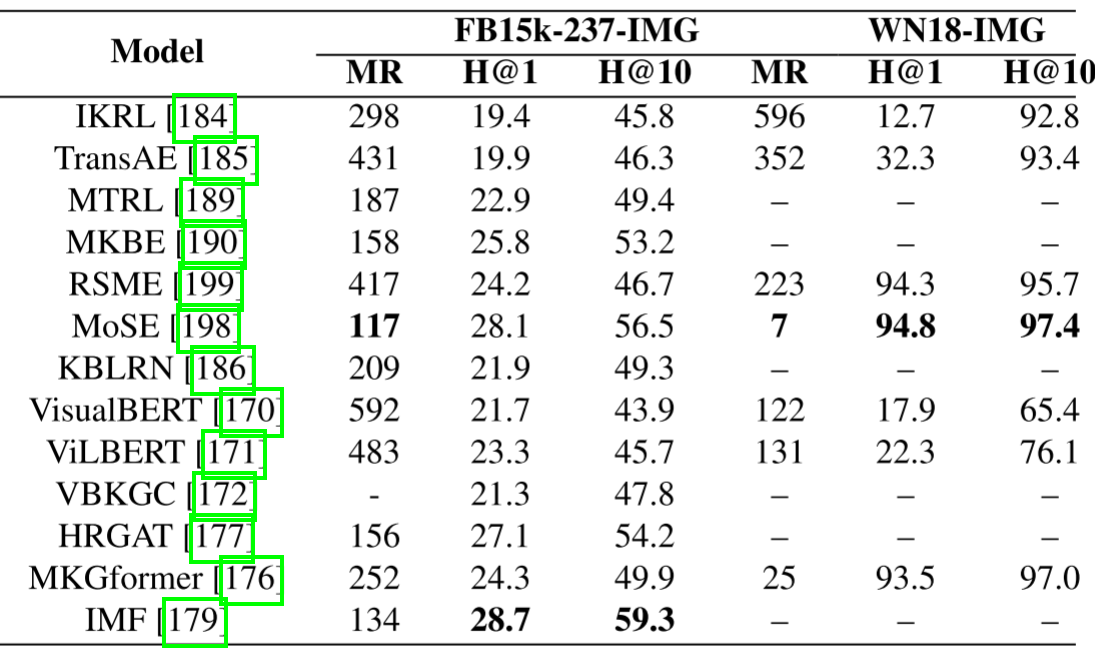
数据集
我们全面总结了典型的KGR数据集,特别是时序和多模态KGR数据集,并给出了它们的描述和统计如下。
静态KGR数据
传统的静态KGR数据集,例如,38直推数据集和15个归纳数据集。统计数据如下表。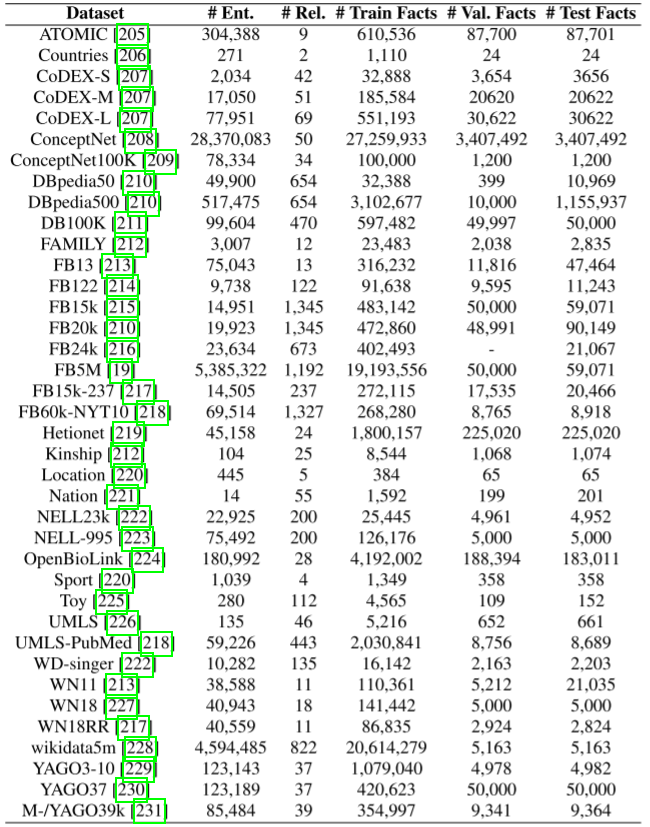
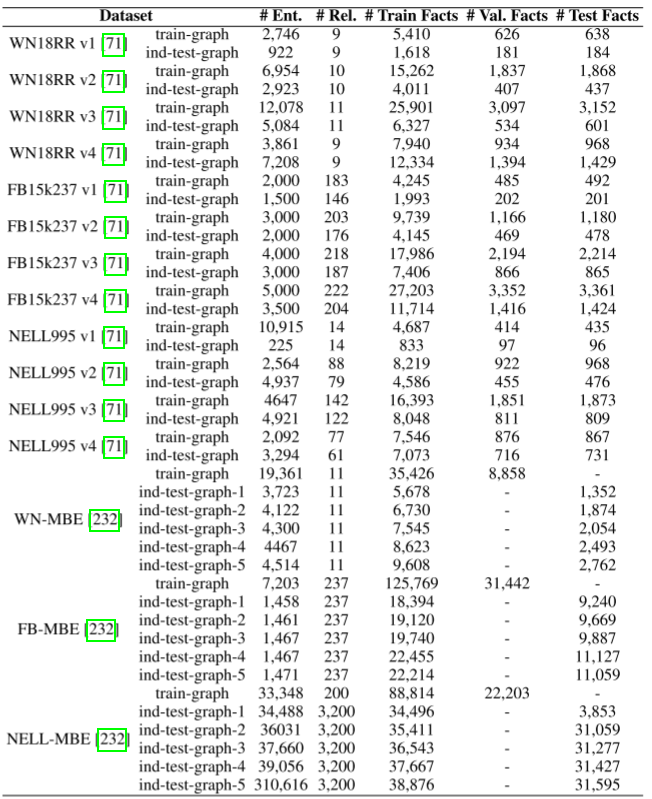
具体描述如下:
- ATOMIC,是一个用于日常推理的KG,它由人类行为的反应、效果和意图以及对每个实体的描述组成
- Countries,由基于公共地理数据的国家间关系组成
- CoDEX,是一组从Wikidata和Wikipedia中提取的补全数据集,其中包含三种不同大小的子kg,即CoDEX-S, CoDEX-M, CoDEX-L
- Conceptnet,将带有标记边缘的单词和短语连接起来,以增强人工智能应用程序更好地理解单词的含义
- DBpedia,由各种维基媒体项目中创建的信息的结构化内容组成。根据实体集的大小,我们可以从中派生出几个子集,即DBpedia50、DBpedia500和DB100K。
- FAMILY,由家庭成员之间的关系构成
- FreeBASE,是一个从多个来源生成的大型知识库,如Wikipedia、NNDB、Fashion Model Directory等。根据实体集的大小,我们可以从中导出几个子集,包括FB13[213]、FB122[214]、FB15k[215]、FB20k[210]、FB24k[216]、FB5M[19]、FB15k-237[217]、FB60k-NYT10[218]。
- Hetionet,是基于公共资源的生物医学研究衍生的知识图谱。它描述了化合物、疾病、基因、解剖结构、途径、生物过程、分子功能、细胞成分、药理学分类、副作用和症状之间的关系
- Kinship,描述阿利亚瓦拉部落的亲属关系
- Nation,包含国家间的关系
- NELL,是基于永无止境的语言学习者建立的知识库,它试图随着时间的推移学习阅读网络。根据实体集的大小,我们可以从中派生出几个子集,如Location[220]、sports[220]、NELL23k[222]、nell995
- OpenBioLink,是一个大规模、高质量、极具挑战性的生物医学KG
- Toy,是否使用小型KG进行测试和调试
- UMLS,统一医学语言系统的KG系统,通过与PubMed语料库的合作,扩展到uml -PubMed
- WordNet,是一个语义关系的词汇数据库,例如词之间的同义词、下义词和异义词。根据实体集的大小,我们可以从中派生出几个子集,如WN11[213]、WN18[227]、WN18RR
- Wikidata,提供了维基百科的公共来源,其中WD-singer[222]和wikidata5m[228]是子集
- YAGO,作为一个轻量级的、可扩展的本体,它建立在维基数据的基础上,并与WordNet统一。根据关系大小,可以推导出YAGO3-10[229]、YAGO37[230]、YAGO39k[231]。
时序KGR数据集
总结了18个典型的时序KGR数据集。统计数据如表下所示,描述如下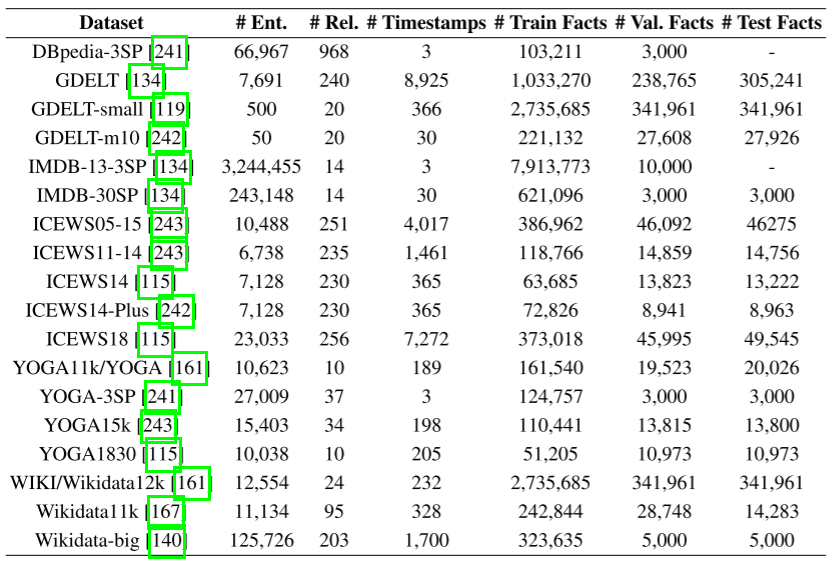
- DBpedia-3SP,从DBpedia中提取的子集在三个不同的时间戳
- GDELT,是来自全球事件、语言和语气数据库的密集KG。从中提取GDELT-m10[242]和GDELT-small [119]
- IMDB,是由电影、电视剧、演员、导演等实体组成的KG,也被称为互联网电影数据库。IMDB-30SP[134]和IMDB-13-3SP[134]从不同时间戳的数据集中提取
- ICEWS,综合危机预警系统(Integrated Crisis Early Warning System)是一个包含带有特定时间戳的政治事件的数据库。在此基础上建立了一些典型的时间KGs,即ICEWS05-15[243]、ICEWS11-14[243]、ICEWS14[115]、ICEWS14- plus[242]、ICEWS18[115]。
- Wikidata,对于时态,KGR比静态维基数据集包含额外的时间信息。WIKI/Wikidata12k[161]、Wikidata11k[167]和Wikidata-big[140]是基于不同时期生成的
- YAGO,对于时间KGR包含额外的时间信息。YOGA11k/YOGA[161]、YOGA15k[243]、yoga3sp[241]和YOGA1830[115]是根据不同时期产生的。
多模态KGR数据集
总结了11个典型的多模态KGR数据集。统计数据如表下所示,描述如下。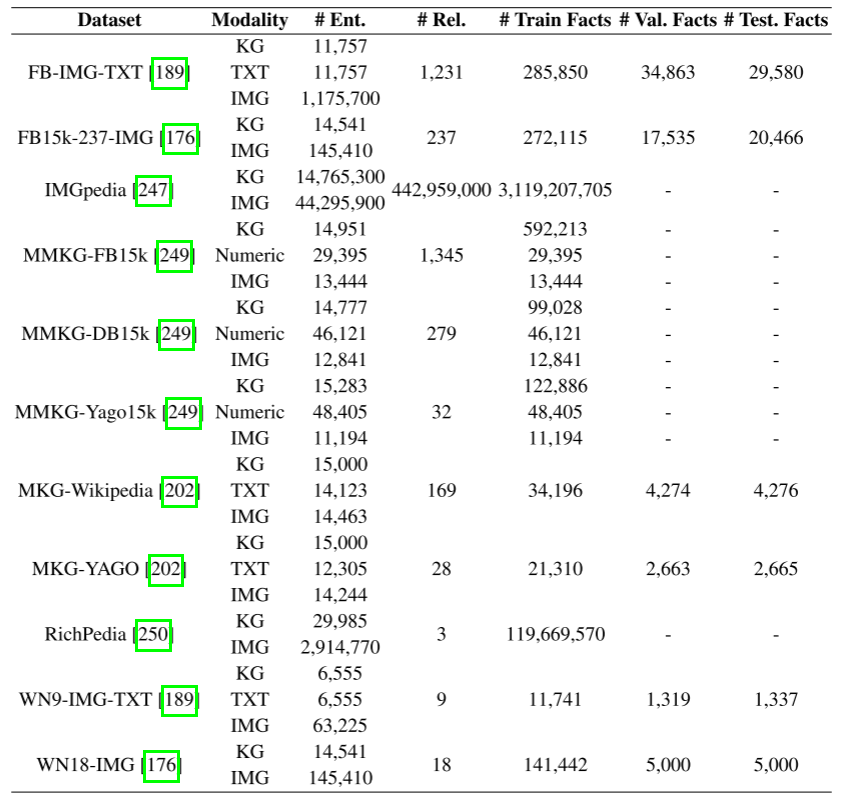
- FB-IMG-TXT,是文字描述和图片相结合的KG。三部分是经典KG数据集FB15k[215]的子集,图像提取自ImageNet[246]。与之相比,FB15k-237 - img[176]将三胞胎的范围改为FB15k-237 [217]
- IMGpedia,是KG,它包含了来自维基共享数据集的图像的视觉信息
- MKG,由两个子集组成,即MKG-Wikipedia和MKG-YAGO。它们都包含由网络搜索引擎生成的可视化实体。但是,它们的三元组分别是从Wikipedia和YAGO中提取的
- MMKG,提供了三个子集,包括MMKGFB15k-IMG, MMKG-DB15k, Yago15k-IMG-TXT,它将特定的kg与数字文字和图像集成在一起
- Richpedia,由三联体、文字描述和图像组成。文本描述来源于维基数据,相应的视觉资源是从网站上抓取的。
- WN9-IMG-TXT,是文字描述和图片相结合的KG。三部分是经典KG数据集WN18[227]的子集,图像提取自ImageNet[246]。与之相比,WN18- img[176]将三元组的范围改为整个WN18。
挑战和机遇
根据对先前的现存的KGR模型分析,我们提出一些未来工作的方向
分布外的推理
在现实场景中,新的实体和关系不断出现在KGs中,而这些在原始KGs中没有得到充分的探索。利用这些未被探索的元素对事实进行推理称为分布外推理,这对KGR模型设计提出了更高的要求。最近的一些尝试为推断看不见的实体提供了潜在的解决方案,即归纳推理模型,如[71],[72],[73],[75]。这些模型在不考虑实体的具体含义的情况下挖掘图结构下的逻辑规则,取得了令人满意的效果。对于看不见的关系推理,少量KGR模型[74],[85],[126]倾向于提高模型的泛化能力,使得训练好的模型可以很好地扩展到事实较少的看不见的关系。换句话说,这些少量的KGR模型可以根据之前学习的类似知识快速学习新的任务。此外,BERTRL[83]试图根据语言模型计算的文本语义来处理这种情况。然而,当语言模型没有得到很好的训练时,这些模型的性能会急剧下降。综上所述,分布外推理任务的KGR模型仍处于早期阶段,值得未来深入探索。
大规模推理
工业用KGR一般都是大规模的,这就需要更高效的KGR模型。为此,已有的一些研究尝试逐步优化传播过程[251]。例如,NBF-net[80]集成了bellman-ford算法,以替代基于gnn的KGR模型中原来基于dfs的聚合过程。此外,A * Star [251] Net进一步利用贪心算法优化了聚合过程。此外,还采用了图聚类的思想[252],[253],[254]。例如,CURL[94]首先根据实体语义将kg划分为不同的簇,然后将寻路过程细化为两级,即簇内级和簇间级。它减少了对整个图的不必要的搜索。同样,许多作品在子图而不是完全图上进行推理,如GraIL[71]、CSR[85]等。但它们中的大多数都牺牲了推理的精度,这一点仍有待于更全面的模型的探索。
多关系推理
如图13 (a)所示,两个实体之间存在多关系事实的情况在kg中很常见。然而,与图13 (b)和©所示的单关系和双关系事实相比,它们在结构上更多样化,在语义上更复杂。因此,现有的KGR模型主要关注单关系和双关系事实,甚至往往将多关系事实视为单关系和双关系事实,而忽略了一些事实。这样的KGR模型不能准确地模拟真实情况,丢失了大量有意义的语义信息,导致表达能力不足。在未来,有必要研究如何利用多关系事实来提高推理能力。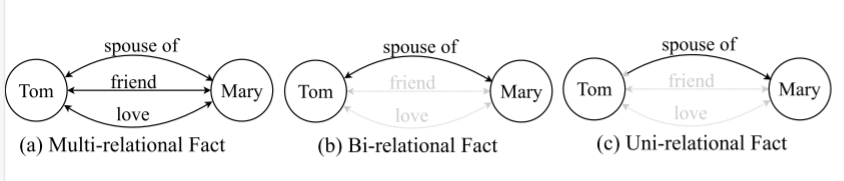
多模态推理
基于多源信息融合的知识推理可以通过结合文本语料库或其他形式的附加信息来减少知识图的不连通性和稀疏性。基于多模式数据融合的知识推理可以优势互补,提高推理性能。然而,现有的多模式KGR模式仍处于早期阶段。他们仍然倾向于直接将不同模式的嵌入连接在一起以计算最终分数。这种简单的融合模式已经显示出其良好的性能,但开发更细粒度和可扩展的模式仍然是值得的。例如,自适应融合模式,权衡不同模式的重要性,是值得探索的。
可解释性推理
对于各个领域的深度学习模型来说,可解释性是一个普遍而重要的问题。虽然KGR模型通常更易于解释,但在这个主题中仍然值得进行更多的探索,特别是基于嵌入的KGR模型。目前,越来越多的KGR模型是基于神经网络开发的,如GNN[255]。他们大多有很强的表达能力,但缺乏可解释性。相比之下,基于规则和基于路径的KGR模型更具可解释性,但计算量大,表达能力差[256]。为了在表达能力和可解释性之间实现良好的权衡,有一些尝试将基于嵌入的模型与基于规则和基于路径的模型集成在一起,如ARGCN[232]。它基于RGCN[58]生成的嵌入构建奖励函数,使那些基于路径的模型更具可解释性。然而,这些尝试中的大多数仍然是粗糙的。
知识图推理应用
虽然近年来提出了大量的KGR方法,显示了KGR在理论领域的巨大潜力,但KGR的应用仍需要更多的研究[257]。如今,知识图谱被广泛应用于许多下游应用,如医药、金融、剽窃检测等。医学知识推理模型旨在帮助医生从电子病历中诊断疾病。例如,[258]和[259]都对从电子医疗数据库构建的KG进行推理。利用Bert等预训练语言模型来生成实体的文本嵌入,这在现有的多模态KGR模型中被证明是有效的。此外,KGR模型还可以帮助反欺诈检测,这是金融领域的一项重要任务。例如,[260]提出了一种基于案例的推理方法,以帮助人们对信息进行验证,从而提前辨别欺诈。此外,[261]通过以持续学习的方式进行KGR方法来执行抄袭检测。
知识图谱与大型语言模型
大型语言模型(llm)[262],即ChatGPT, GPT-4,是今年非常流行的,由于它们具有良好的推理能力和泛化能力[263],具有巨大的影响。然而,这些模型仍然存在两个问题,即:(1)可解释性差;(2)处理新数据时可扩展性差,如果与KGR模型很好地配合,这些问题可能会得到解决。例如,QA-GNN[264]首次尝试使用llm进行文本预处理,并进一步指导KGR上的推理步骤。DRAGON[181]是一种基于llm的多模态KGR逻辑推理方法。同时,由于越来越多的数据被训练,一些研究者认为LLM在未来是一个更通用的KG,它还可以实现索引、推理、存储等功能。关于LLM和KG之间联系的各种假设都是合理的,我们不能说哪个更有价值。但可以肯定的是,LLM与KG之间的探索与研究也将是未来的热点之一。
结论
我们的调查基于双层分类法全面回顾了现有的KGR模型,即顶层(图类型)和底层(技术、场景)。包括三种图类型(即静态、时间、多模态KGs)、十四种技术和四种推理场景,为KGR提供了系统的综述。此外,我们总结了知识图推理面临的挑战,并指出了一些潜在的机会,以启发读者。在GitHub上共享了180个最先进的KGR模型(即论文和代码)和67个典型数据集的相应开源存储库,以方便社区。
PS:整理的PPT和资料稍后上传到公众号,直接回复论文名字,即可获取!
关注我们
欢迎大家关注我们,我们将会分享更多有关知识图谱和LLM方向的论文:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)