人工智能基础知识笔记十二:相似性计算方法
本文介绍了向量相似性计算在机器学习和数据科学中的核心作用,重点分析了8种常用方法。余弦相似度适合文本分析但对长度不敏感;欧氏距离直观但受高维影响;曼哈顿距离对异常值鲁棒;点积高效但需归一化;马氏距离考虑特征相关性但计算复杂;Jaccard适用于二元数据;预训练模型捕捉语义但资源消耗大。每种方法各有特点,选择时应结合数据特性(如维度、稀疏性)和任务需求(方向或距离敏感)。这些相似性度量支撑着推荐系统
1、简介
计算向量相似性是机器学习和数据科学中的核心任务,常见于推荐系统、NLP、图像检索等领域。通过数学建模将抽象的“相似性”转化为可计算的数值,核心是距离、角度、分布或语义的量化。为数据之间的关联提供可解释的度量,支撑上层应用(如推荐、分类、检索等)。计算向量相似性的方法有很多,余弦相似度(Cosine Similarity)、欧氏距离(Euclidean Distance)、曼哈顿距离(Manhattan Distance)、点积(Dot Product)、皮尔逊相关系数(Pearson Correlation)、Jaccard相似度、马氏距离(Mahalanobis Distance)、KL散度 & JS散度(信息论方法)、预训练模型相似度(如BERT、CLIP)等。选择具体方法需结合数据特性(如稀疏性、维度)和任务目标(如方向敏感还是绝对距离敏感),选择合适的计算相似性的方法。
2、集中计算相似度的方法
2.1、余弦相似度(Cosine Similarity)
通过计算向量之间的夹角余弦值衡量方向相似性,与向量长度无关。例如:文本相似度中,两篇文档的词频向量方向越接近,内容越相似。
计算方式:向量点积除以模的乘积:
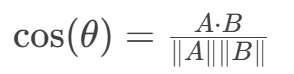
优点:
-
不受向量长度影响,适合文本TF-IDF或词向量等场景。
-
范围[-1,1],直观易解释。
缺点:
-
忽略向量绝对大小(如两个用户评分向量可能方向相同但评分尺度不同)。
适用场景:
-
文本相似度(如文档、词嵌入)、用户兴趣匹配。
2.2、欧氏距离(Euclidean Distance)
将向量视为空间中的点,通过计算点之间的几何距离衡量相似性。距离越小,相似性越高。欧氏距离是两点间的直线距离。
计算方式:
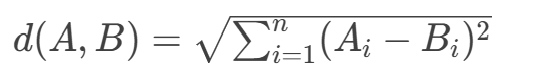
优点:
-
几何直观,反映向量绝对差异。
缺点:
-
对高维数据敏感(“维度灾难”),需归一化处理。
适用场景:
-
低维空间中的聚类(如KNN)、图像像素级相似度。
2.3、曼哈顿距离(Manhattan Distance)
将向量视为空间中的点,通过计算点之间的几何距离衡量相似性。距离越小,相似性越高。曼哈顿距离是坐标轴方向的路径总和。
计算方式:
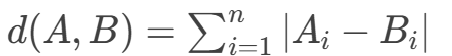
优点:
-
对异常值比欧氏距离更鲁棒。
缺点:
-
高维数据中表现可能不佳。
适用场景:
-
网格路径规划、稀疏特征(如用户行为计数)。
2.4、点积(Dot Product)
点积(又称内积)是向量运算中的一种基本操作,用于衡量两个向量在方向上的对齐程度,同时考虑它们的长度。
计算方式:
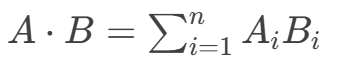
在几何上,点积也可以表示为:

其中:
-
∥A∥∥A∥ 和 ∥B∥∥B∥ 分别是向量的模(长度)。
-
θθ 是两向量之间的夹角。
优点:
-
计算高效,适合大规模数据。
缺点:
-
受向量长度影响大,通常需归一化。
适用场景:
-
快速初筛(如召回阶段)、结合长度信息的相似度(如推荐系统)。
2.5、马氏距离(Mahalanobis Distance)
马氏距离是一种考虑数据分布特性的距离度量,通过引入协方差矩阵解决特征相关性和尺度不一致的问题。
计算方式:
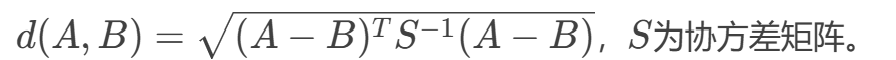
若 S是单位矩阵(特征独立且方差为1),马氏距离退化为欧氏距离。
优点:
-
考虑特征相关性,适用于非独立同分布数据。
缺点:
-
计算成本高(需逆矩阵)。
适用场景:
-
异常检测、多元统计分析。
2.6、预训练模型相似度(如BERT、CLIP)
使用神经网络提取高维语义特征,再计算特征向量的相似性(如跨模态图文匹配)。
计算方式:
- 用神经网络提取特征后计算余弦相似度。
优点:
-
捕捉深层语义(如跨模态图文匹配)。
缺点:
-
计算资源消耗大。
适用场景:
-
语义搜索、跨模态检索。
2.7、Jaccard相似度
通过计算集合的交集与并集比例衡量相似性,适用于二元特征(如用户是否购买某商品)。
计算方式:交集大小除以并集大小:
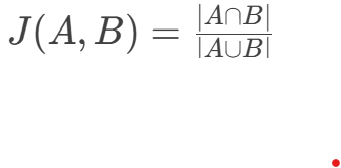
优点:
-
适合二元向量或集合。
缺点:
-
忽略元素频率信息。
适用场景:
-
用户行为交集分析(如购物车商品)、文档词集匹配。
3、总结
| 方法 | 优势 | 劣势 | 典型场景 |
| 余弦相似度 | 方向敏感,长度无关 | 忽略大小差异 | 文本、嵌入向量 |
| 欧氏距离 | 几何直观 | 高维失效 | 低维空间聚类 |
| Jaccard | 集合操作高效 | 忽略频率 | 用户行为交集 |
| 马氏距离 | 处理相关性 | 计算复杂 | 多元异常检测 |
| 预训练模型 | 语义理解强 | 资源消耗大 | 跨模态语义匹配 |
| 点积 | 计算高效 | 受向量长度影响大,通常需归一化 | 快速初筛和结合长度信息的相似度 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)