基于ms香橙派AIpro实现垃圾回收AI识别方案二:昇思大模型平台jupyter快速入门体验
刚刚进来我们可以看到界面是全英文的,我们可以在“setting”中选择中文进行设置,需要重载一下Jupyter工具,即可以看到界面变成中文了,对于我这种英文不太好的建议使用中文,左侧中可以看到官方温馨的给我们提供了两种Demo示例:“初学入门”、“应用实践”,建议先从“初学入门”的10个案例进行学习,再通过“应用实践”的案例场景学习,来选择我们自己的场景的方案。使用Mnist数据集,自动下载完成后
昇思MindSpore 25天学习打卡营,是昇思MindSpore开源社区为开发者打造的能力提升项目,内容涵盖AI框架基础知识、经典神经网络实践、AI+X应用实践,以及大模型理论与实践。
昇思大模型平台
昇思大模型平台是集算法选型、创意分享、模型实验和大模型在线体验为一体的AI学习与实践社区,提供超强Ascend算力、免费课程资源、经典样例代码、企业落地案例。

大模型:
覆盖NLP和CV等场景。面向语言理解、语言生成,具有超强语言理解能力以及对话生成;可实现跨模态检索、图文生成、图片文档的信息提取等应用;可实现对遥感数据的目标检测等。
模型库:
覆盖全领域主流模型,可体验MindSpore大模型推理API,用户既可下载公开的预训练模型,也可以上传自行训练的模型文件,同时平台提供GITLAB一站式代码托管,支持文件批量上传,支持LFS大文件管理。

昇思大模型平台注册与登录
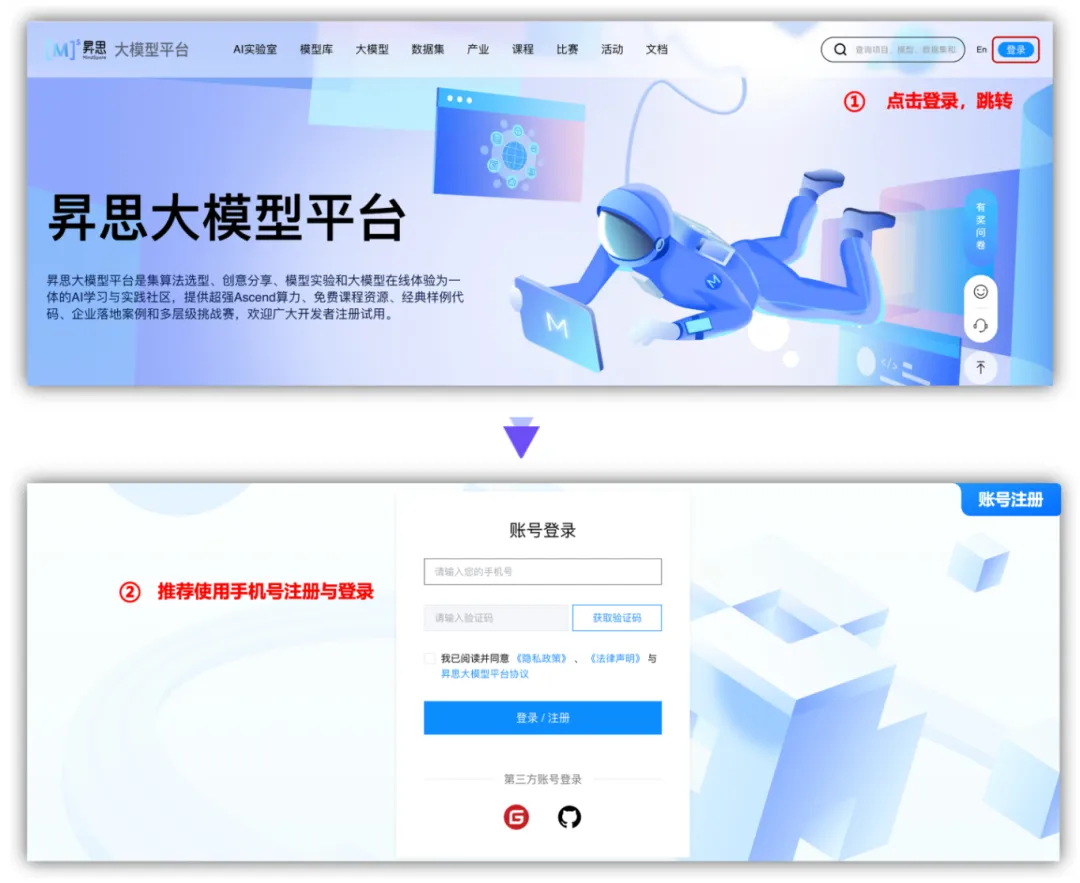
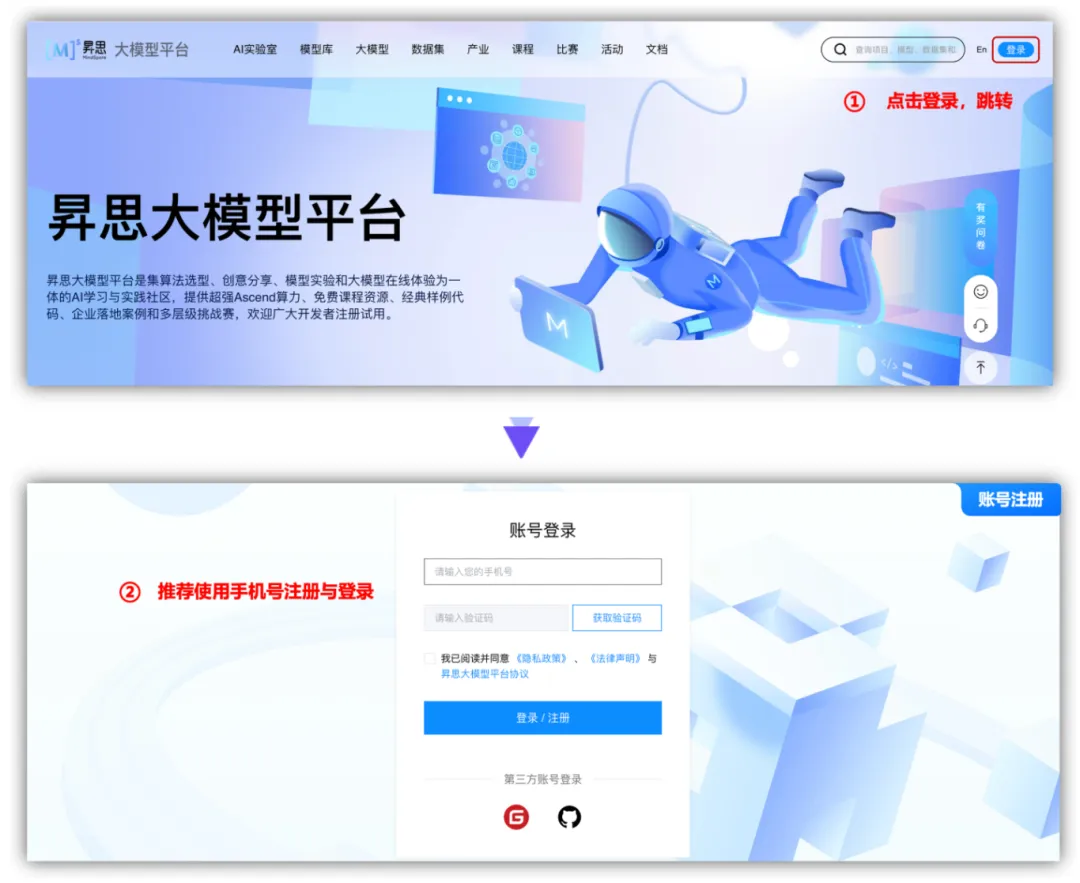
打开昇思大模型平台网址https://xihe.mindspore.cn/,跳转到账号注册登录页面,可以看到有3种方式:手机号、Gitee账号、Github账号,这里我们使用手机号进行登录。
登录后,可以跳到个人中心的主页面中,可以看到上面的导航栏有不少的模块,这里我们来使用一下“AI实验室”的模块,点击“AI实验室”中,里面会覆盖多领域任务,体验全流程开发,支持用户在线训练和推理可视化,可创建自己的项目空间。
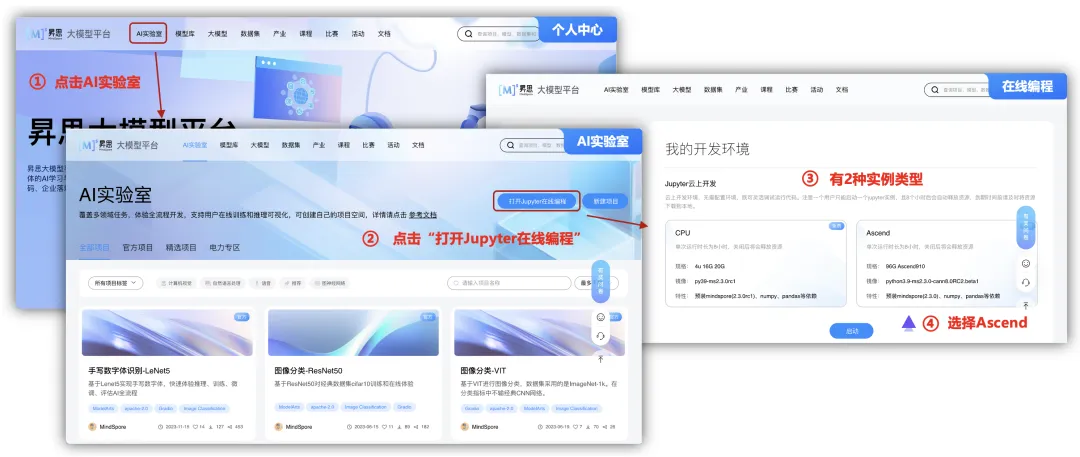
这里我们可以看到有2种实例的配置,都是直接使用Jupyter云上开发云上开发环境,无需配置环境,既可灵活调试运行代码,目前需要使用“Ascend”算力配置需要进行申请,也可以使用CPU的实例来测试,不过,还是推荐使用“Ascend”算力配置,速度很快。
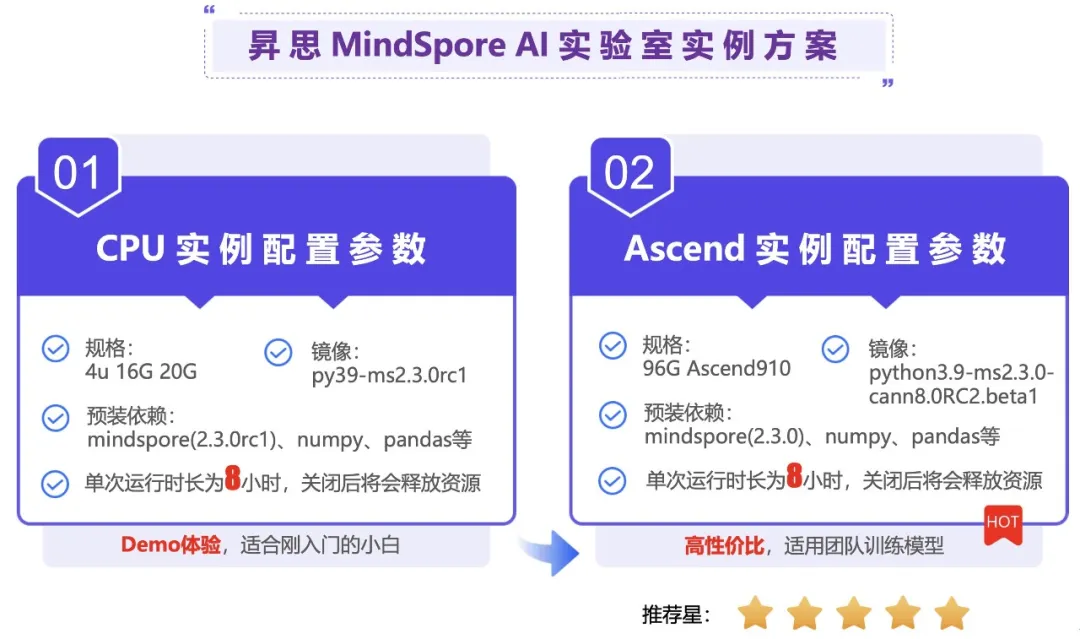
注:一个用户同时只能启动一个jupyter实例,且8个小时后会自动释放资源,到期时间前请及时将资源下载到本地。
选择“Ascend”实例后,点击“启动”按钮,就会进行初始化申请Ascend实例空间,这里需要等待不到1分钟即可完成初始化,如果按钮显示“查看jupyter”时,表示“Ascend”实例已经初始化完成,点击“查看jupyter”即可,打开云上Jupyter开发环境,进行AI的使用。

Jupyter云上开发体验
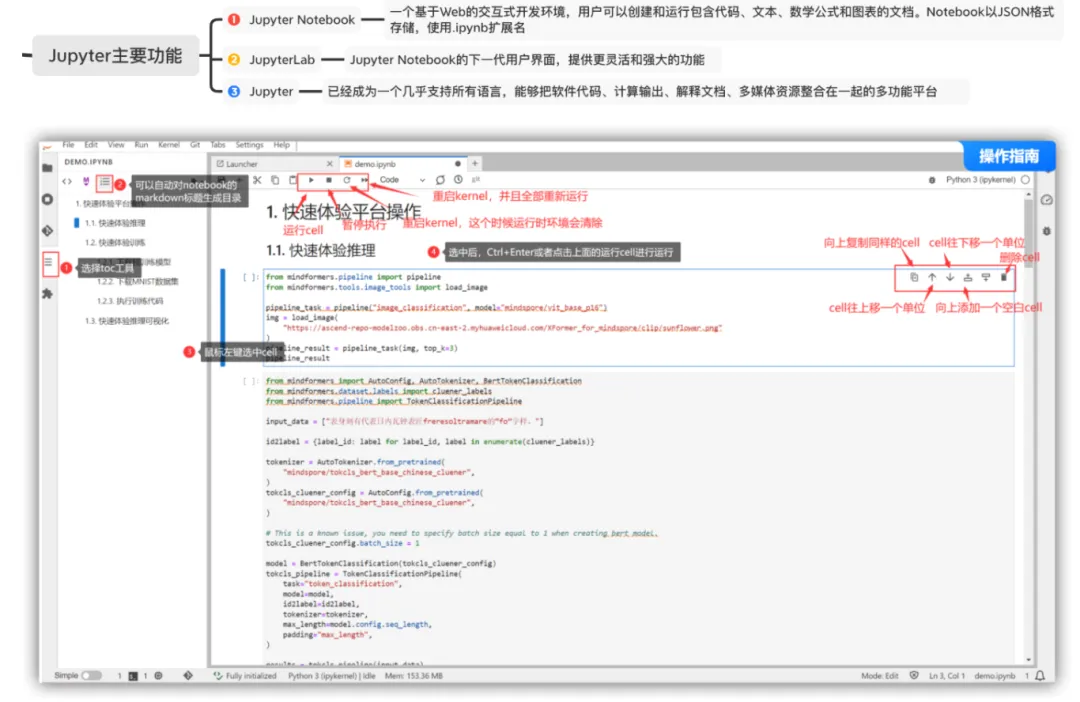
Jupyter是一个开源的交互式计算环境,允许用户通过Web浏览器创建和分享包含代码、方程式、可视化和叙述性文本的文档,它支持多种编程语言,如Python、R、Julia等,是数据分析、科学计算和机器学习领域的强大工具。
实例中使用的是Jupyter Lab 3.x,并集成了实用的插件,可以在Jupyter Lab上灵活运行调试代码和编写文档,通过Jupyter只需要将代码复制进去,点击执行即可得到一些结果,非常适合为小白、数据科学家、研究人员和开发者提供了一个灵活且强大的平台,用于创建、共享和展示计算性工作。
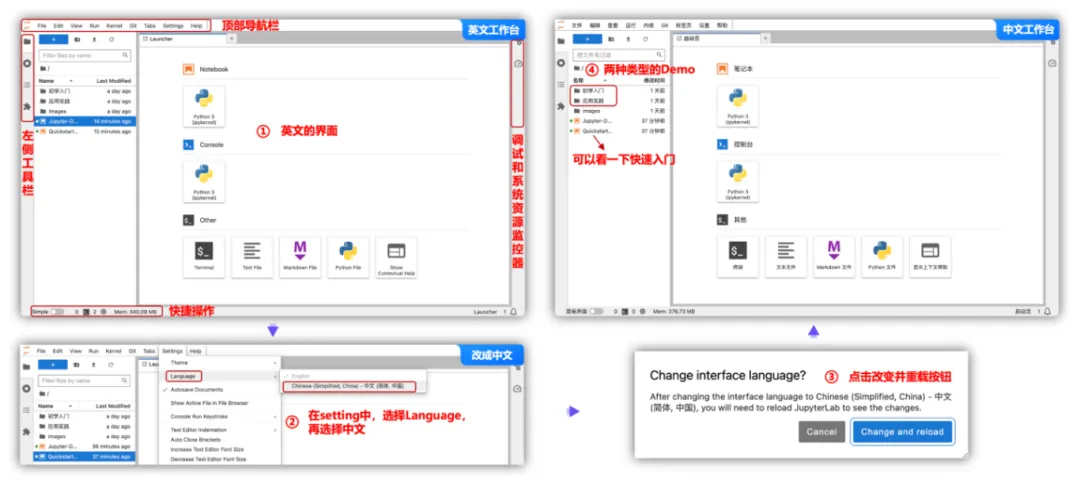
刚刚进来我们可以看到界面是全英文的,我们可以在“setting”中选择中文进行设置,需要重载一下Jupyter工具,即可以看到界面变成中文了,对于我这种英文不太好的建议使用中文,左侧中可以看到官方温馨的给我们提供了两种Demo示例:“初学入门”、“应用实践”,建议先从“初学入门”的10个案例进行学习,再通过“应用实践”的案例场景学习,来选择我们自己的场景的方案。

另外,可以看一下快速体验jupyter的基本功能,jupyter的执行顺序很重要,很多时候发现运行结果于预期不符,就是因为jupyter执行错乱导致的。
上面提到了“AI实验室”中提供了“初学入门”、“应用实践”2种Demo,作为初学者可以先尝试体验一下“初学入门 – 初学教程 – 快速入门”的课程,如下左图一找到并双击打开初学教程,即可看到有官方提供的文档,从“文件 – 新建启动页”可以找开Jupyter的主要工作台。
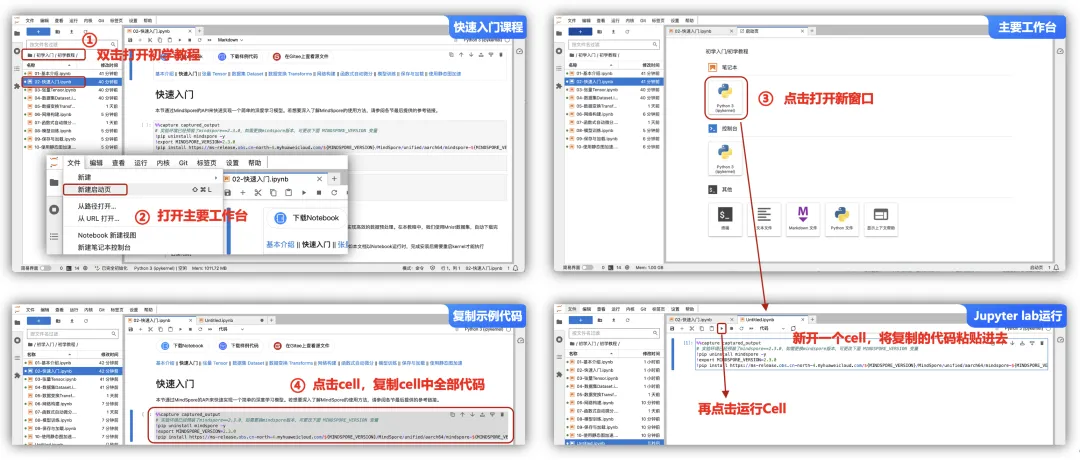
选择第一个python笔记本,将上面文档中的Cell代码直接进行复制,再放到Jupyter Lab中粘贴即可,不过,需要点击一下上面的“三角形”表示运行Cell项目。
01
安装相关依赖:
实验环境中已经预装了mindspore 2.3.0版本的,但是为了保险起见,还是建议先卸载mindspore,然后配置MINDSPORE_VERSION版本(如果想换成其它的版本,也可以修改),再进行安装,这里使用了华为的加速云地址下载,安装后,可以使用“!pip show mindspore”来查看版本。
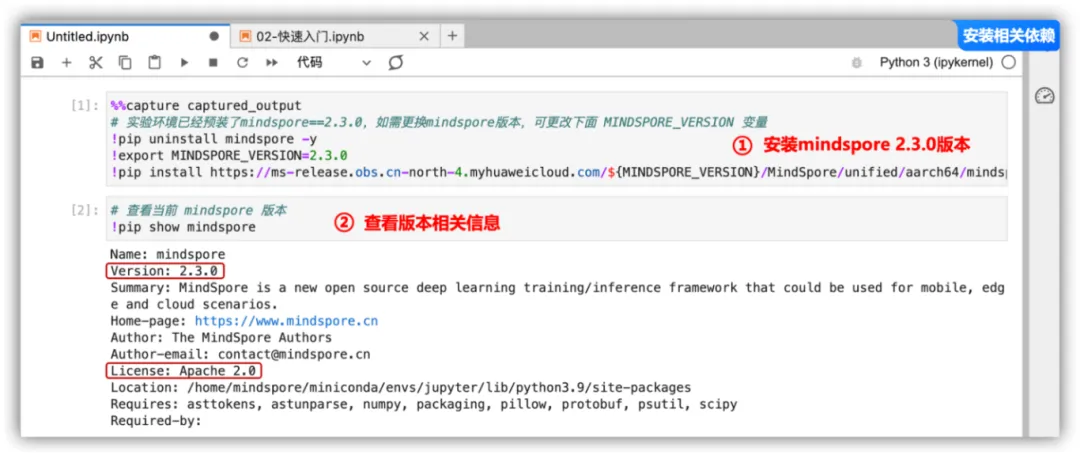
引入相关的包:
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset复制02
处理数据集:
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
使用download来下载文件并进行unzip解压缩,如果没有可以使用命令pip install download安装。
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)复制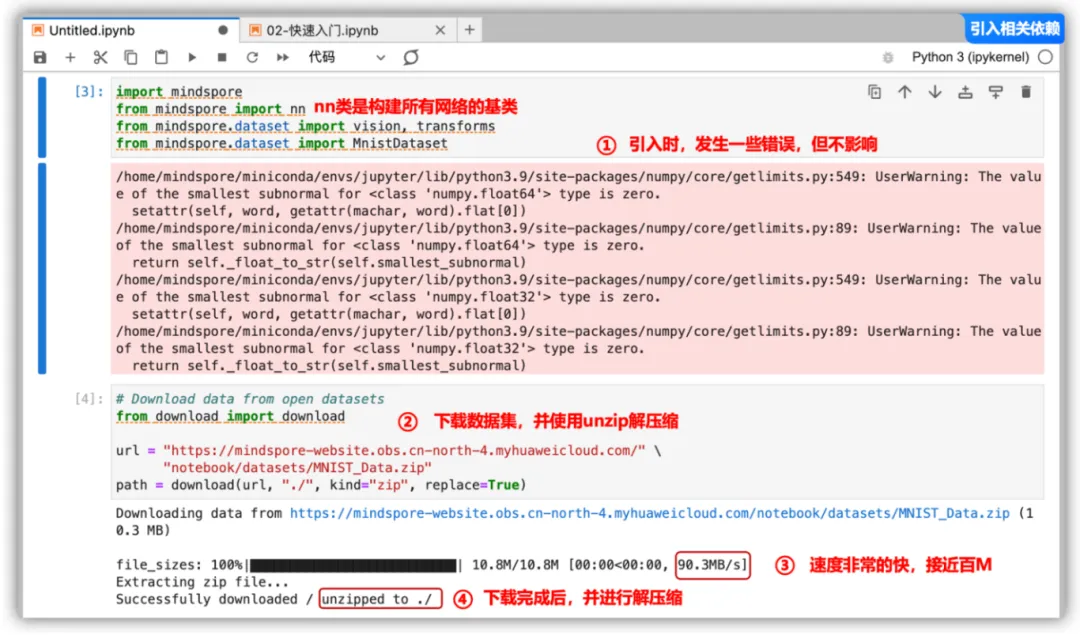
MNIST数据集目录结构如下:
MNIST_Data
└── train
├── train-images-idx3-ubyte (60000个训练图片)
├── train-labels-idx1-ubyte (60000个训练标签)
└── test
├── t10k-images-idx3-ubyte (10000个测试图片)
├── t10k-labels-idx1-ubyte (10000个测试标签)复制03
数据变换 Transforms:
数据下载完成后,获得数据集对象。
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
复制打印数据集中包含的数据列名,用于dataset的预处理。
print(train_dataset.get_col_names())
['image', 'label']复制MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。使用map对图像数据及标签进行变换处理,将输入的图像缩放为1/255,根据均值0.1307和标准差值0.3081进行归一化处理。
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
复制然后将处理好的数据集打包为大小为64的batch。
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
复制可使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype。
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break复制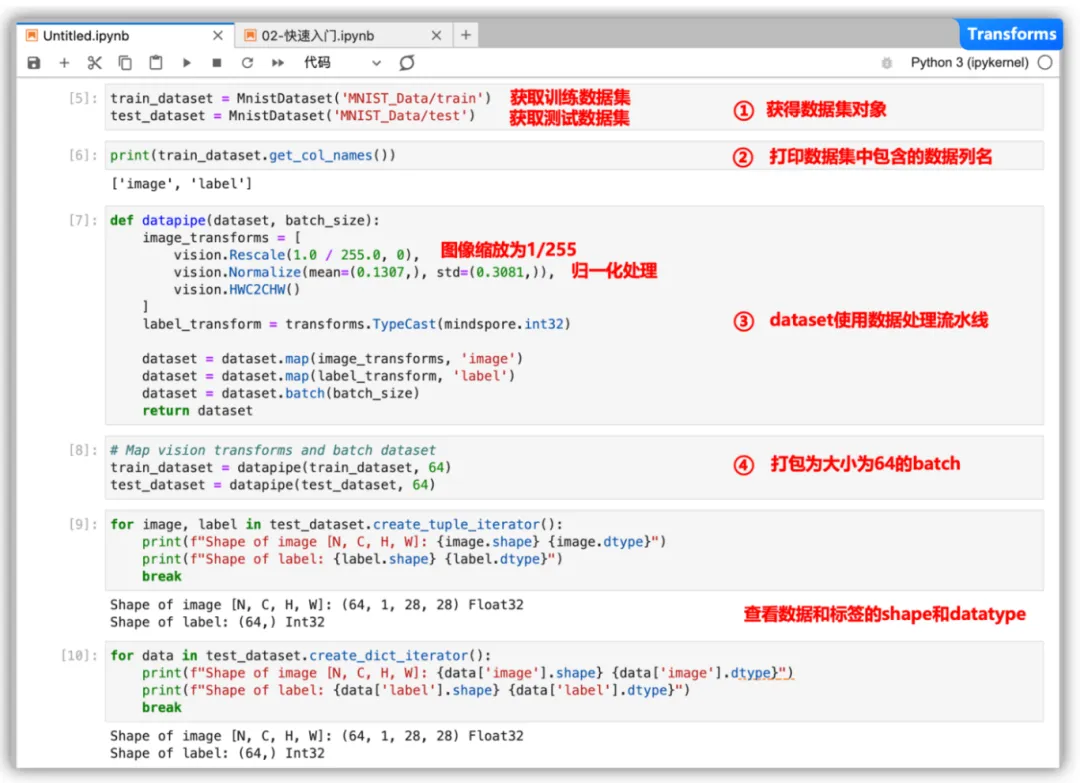
04
网络构建:
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)复制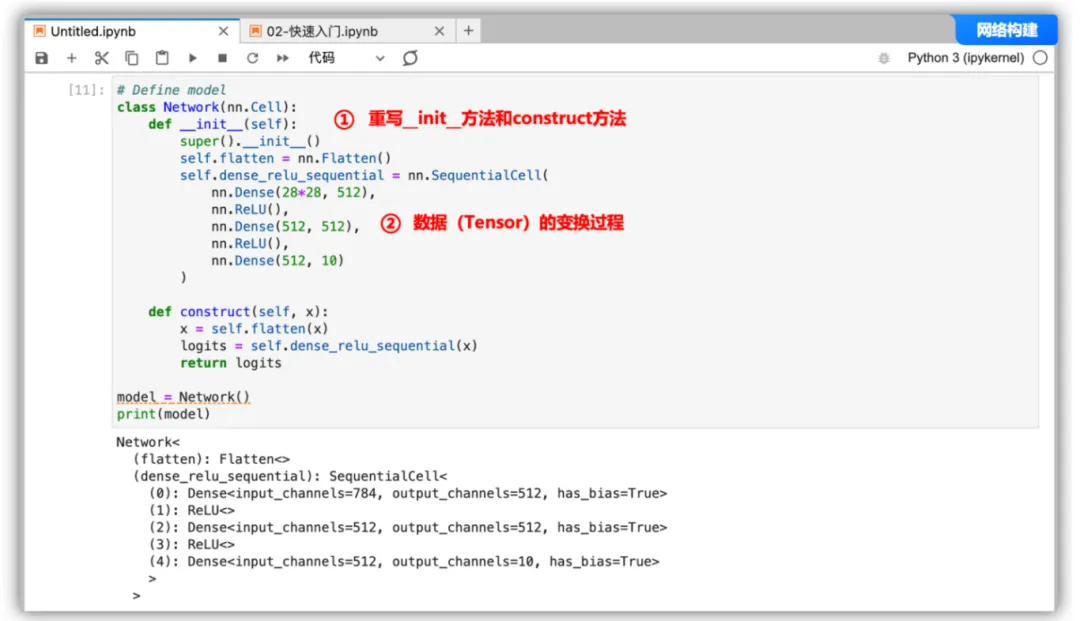
05
模型训练:
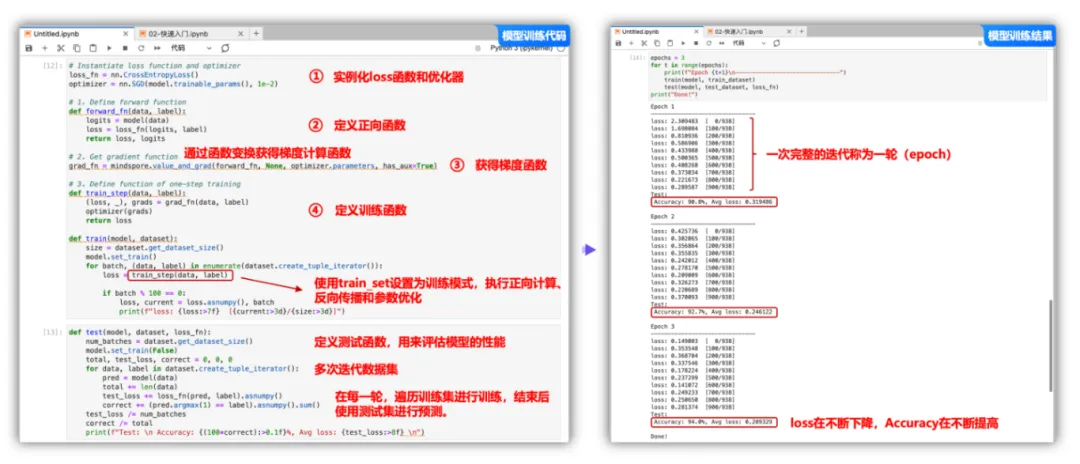
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
①正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
②反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
③参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
①定义正向计算函数。
②使用value_and_grad通过函数变换获得梯度计算函数。
定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 3. Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
复制除训练外,我们定义测试函数,用来评估模型的性能。
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")复制训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
06
保存模型:
模型训练完成后,需要将其参数进行保存。
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
Saved Model to model.ckpt复制07
加载模型:
加载保存的权重分为两步:
①重新实例化模型对象,构造模型。
②加载模型参数,并将其加载至模型上。
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)复制param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功。
加载后的模型可以直接用于预测推理。
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break复制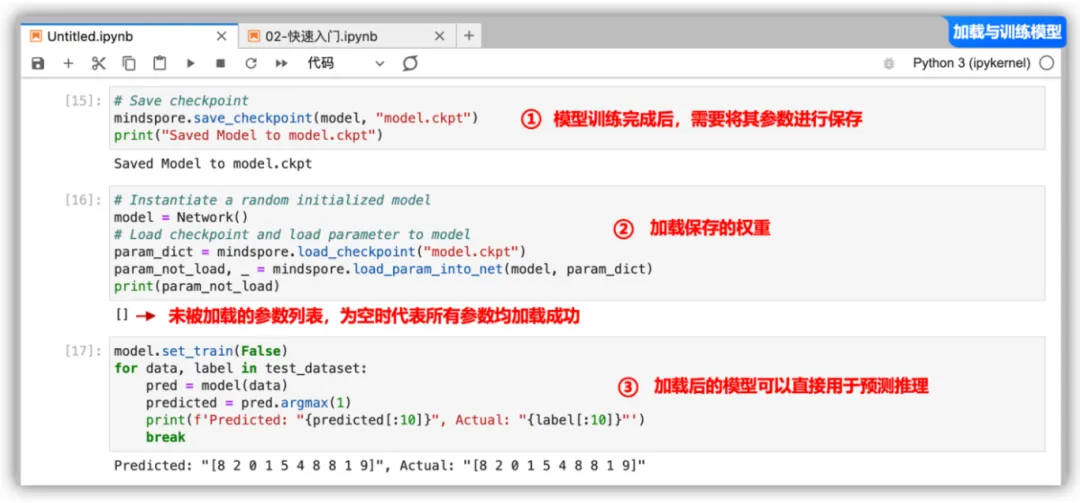
08
总结
上面我们通过MindSpore的API来快速实现一个简单的深度学习模型,从加载数据集、数据变换 Transforms、网络构建、模型训练、模型保存、加载模型,完成了一个简单的深度学习模型的闭环,可以体验到:
①能过jupyter云上开发环境,我们可以不用搭建自己的AI应用。
②MindSpore的API简化了大量深度学习的复杂度。
③通过使用华为云可以达到百M速度的下载,十分的高效。
④在模型训练中,可以在几分钟内就完成模型的训练,大大的简化了实验中等待的过程。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)