【全网最细】Python + Neo4j 社区版:从零搭建你的第一个知识图谱
本文手把手教你从零部署Neo4j图数据库社区版,并用Python构建西游记人物关系图谱。首先介绍知识图谱的核心概念,通过对比Excel表格展示其网状数据优势。详细讲解Java环境配置、Neo4j下载解压和启动流程,以及如何通过浏览器访问7474端口进入可视化界面。重点演示使用Python的neo4j驱动,编写代码批量创建节点和关系,最后在Neo4j Browser中实现数据可视化查询。教程采用实战
摘要: 在大数据与 AI 时代,数据之间的关系价值连城。传统的 SQL 数据库难以处理复杂的网状关系,而 知识图谱 和 图数据库 Neo4j 正是为此而生。
本文将带你从 0 基础出发,手把手教你部署 Neo4j Community Edition(社区服务器版),如何通过浏览器访问其可视化界面,并使用 Python 代码构建一个生动的人物关系图谱。拒绝繁琐理论,全是实战干货!
一、 核心概念:图谱与 Neo4j
在动手之前,我们用大白话把两个核心概念捋清楚。
1. 什么是知识图谱?
知识图谱本质上就是把世界上的事物(节点)和它们之间的联系(关系)画成一张巨大的网。
-
Excel 思维:罗列数据(行与列)。
-
图谱思维:链接数据(点与线)。例如:
(孙悟空)--[师弟]-->(猪八戒)。
2. 为什么选择 Neo4j?
Neo4j 是图数据库领域的绝对霸主。
-
高性能:查询深度关系(如“朋友的朋友的朋友”)速度秒杀 MySQL。
-
可视化:自带 Web 界面,数据不再是枯燥的表格,而是生动的网络图。
二、 环境部署:Neo4j 社区版 (Community Edition)
很多教程推荐 Desktop 版,但社区版更轻量、更硬核,且更接近服务器真实环境。以下是 Windows/Mac 通用的部署步骤。
步骤 1:准备 Java 环境(必读!)
Neo4j 是基于 Java 开发的,因此必须先安装 JDK。
-
Neo4j 5.x 版本:需要安装 JDK 17。
-
Neo4j 4.x 版本:需要安装 JDK 11。
-
如果不确定,请先在终端输入
java -version检查。如果没有安装,请去 Oracle 官网下载 JDK 17 安装。
步骤 2:下载 Neo4j 社区版
-
访问 Neo4j 下载中心。
-
找到 Neo4j Community Edition。
-
根据你的系统(Windows 或 macOS/Linux)下载对应的压缩包(zip 或 tar)。
步骤 3:解压与启动
这是一个绿色免安装软件,解压即可用。
-
将下载的压缩包解压到一个你喜欢的文件夹(路径最好不要有中文)。
-
打开终端(CMD 或 PowerShell),进入解压后的
bin目录。 -
输入启动命令:
-
Windows:
neo4j.bat console -
Mac/Linux:
./neo4j console
-
当看到控制台输出类似 Started. 或者 Remote interface available at http://localhost:7474/ 的字样时,说明数据库引擎已成功启动!
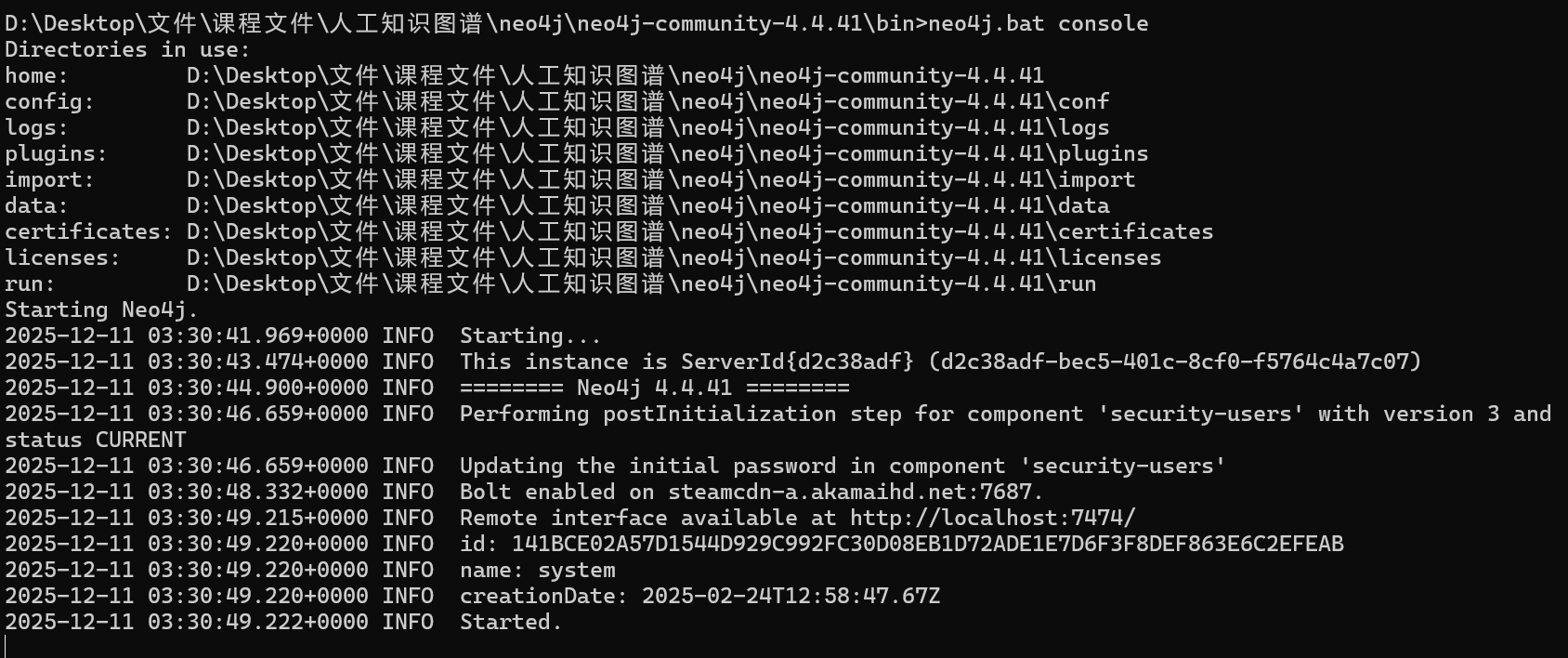
三、 访问网页版控制台 (Neo4j Browser)
社区版虽然是命令行启动,但它自带了一个强大的网页可视化界面。
1. 如何进入?
保持刚才的黑色终端窗口不要关闭(关闭它数据库就停了),打开你的 Chrome 或 Edge 浏览器,输入:
👉 http://localhost:7474
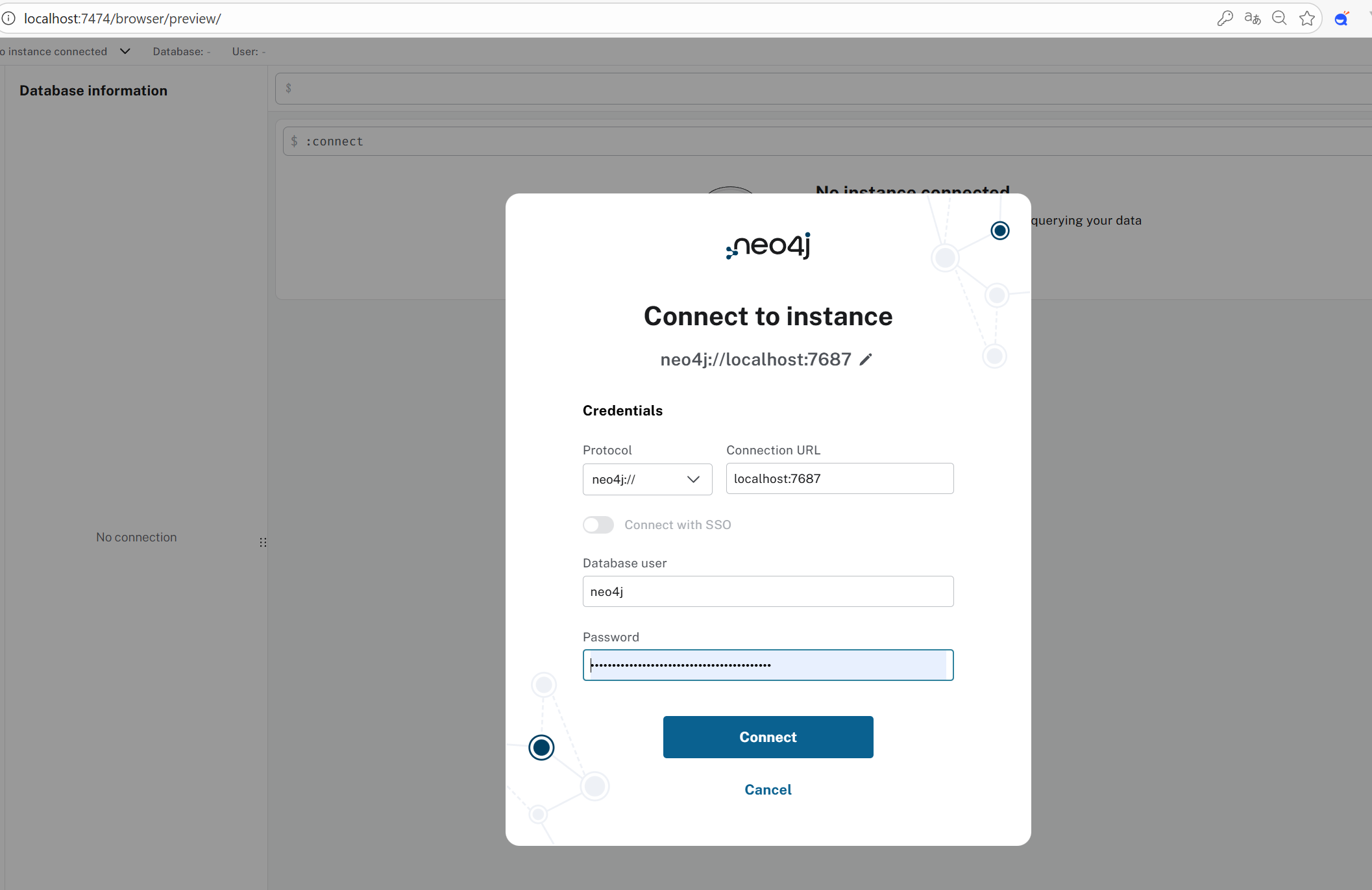
2. 登录配置
第一次访问会看到登录框:
-
Connect URL: 保持默认
bolt://localhost:7687 -
Username: 输入默认用户名
neo4j -
Password: 输入默认密码
neo4j
点击 Connect 后,系统会强制要求你修改新密码。
-
输入新密码(例如
123456),一定要记住它!
进入后,当你看到有一个 $ 符号的输入框,说明你已经成功进入了 Neo4j 的可视化世界。
四、 实战:使用 Python 构建知识图谱
环境通了,接下来我们用 Python 来自动化构建一个 “西游记人物关系图谱”。
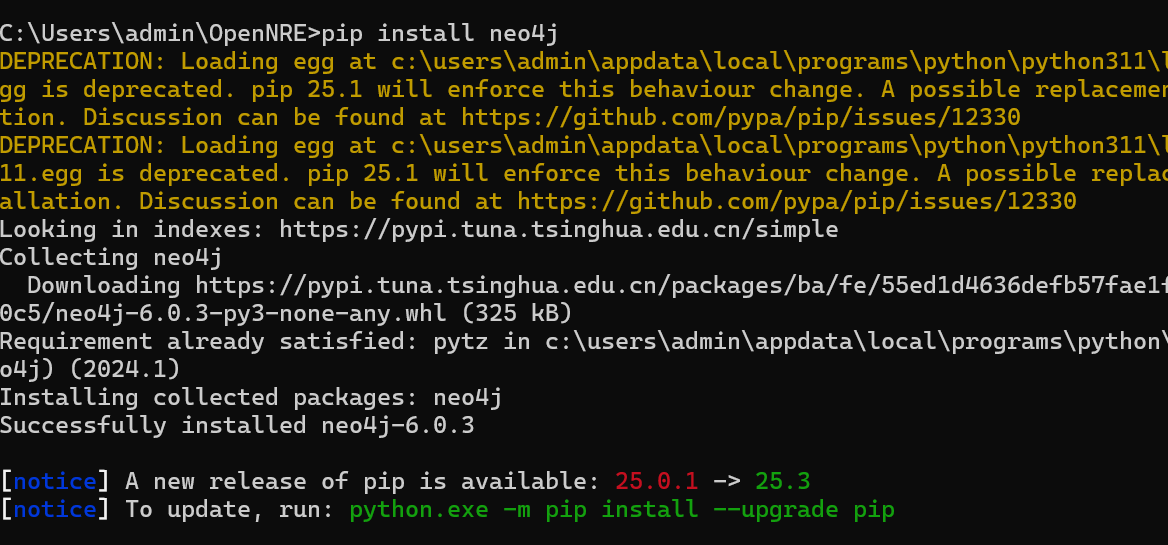
1. 安装 Python 驱动
打开一个新的 CMD 窗口(不要动刚才跑数据库的那个),运行:
Bash
pip install neo4j
2. 编写构建代码
新建一个 Python 文件 build_graph.py,复制以下代码。该代码封装了连接逻辑,采用了 MERGE 语法防止重复创建数据。
Python
from neo4j import GraphDatabase
class KnowledgeGraph:
def __init__(self, uri, user, password):
"""
连接 Neo4j 数据库
"""
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
"""
关闭连接
"""
self.driver.close()
def create_relation(self, person1, relation, person2):
"""
创建节点和关系
"""
with self.driver.session() as session:
# Cypher 语句说明:
# MERGE 只有在节点不存在时才创建,存在则复用
query = """
MERGE (p1:Character {name: $name1})
MERGE (p2:Character {name: $name2})
MERGE (p1)-[r:RELATION {type: $rel}]->(p2)
RETURN p1, p2, r
"""
session.run(query, name1=person1, name2=person2, rel=relation)
print(f"构建成功:{person1} --[{relation}]--> {person2}")
def clear_data(self):
"""
清空数据库(慎用!)
"""
with self.driver.session() as session:
session.run("MATCH (n) DETACH DELETE n")
print("数据库已重置。")
# --- 主程序入口 ---
if __name__ == "__main__":
# 1. 配置连接信息
# 社区版默认地址是 bolt://localhost:7687
URI = "bolt://localhost:7687"
USER = "neo4j"
PASSWORD = "123456" # 【重要】这里改成你在网页端设置的新密码
# 2. 准备图谱数据
data = [
("唐僧", "师徒", "孙悟空"),
("唐僧", "师徒", "猪八戒"),
("唐僧", "师徒", "沙僧"),
("孙悟空", "师兄弟", "猪八戒"),
("孙悟空", "结拜", "牛魔王"),
("牛魔王", "夫妻", "铁扇公主"),
("铁扇公主", "母子", "红孩儿"),
("东海龙王", "被抢", "孙悟空")
]
# 3. 运行构建
kg = KnowledgeGraph(URI, USER, PASSWORD)
try:
kg.clear_data() # 清空旧数据,方便演示
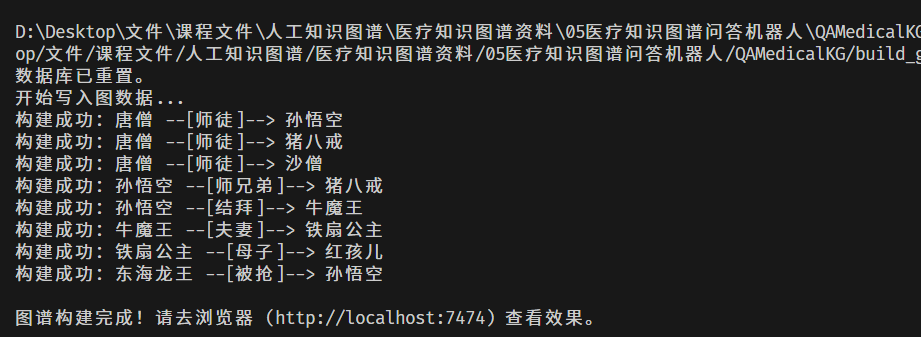
print("开始写入图数据...")
for p1, rel, p2 in data:
kg.create_relation(p1, rel, p2)
print("\n图谱构建完成!请去浏览器 (http://localhost:7474) 查看效果。")
except Exception as e:
print(f"连接失败,请检查密码或Java环境: {e}")
finally:
kg.close()
3. 运行代码
运行脚本,如果控制台输出“构建成功”,说明数据已经通过 Bolt 协议飞入了你的本地数据库。
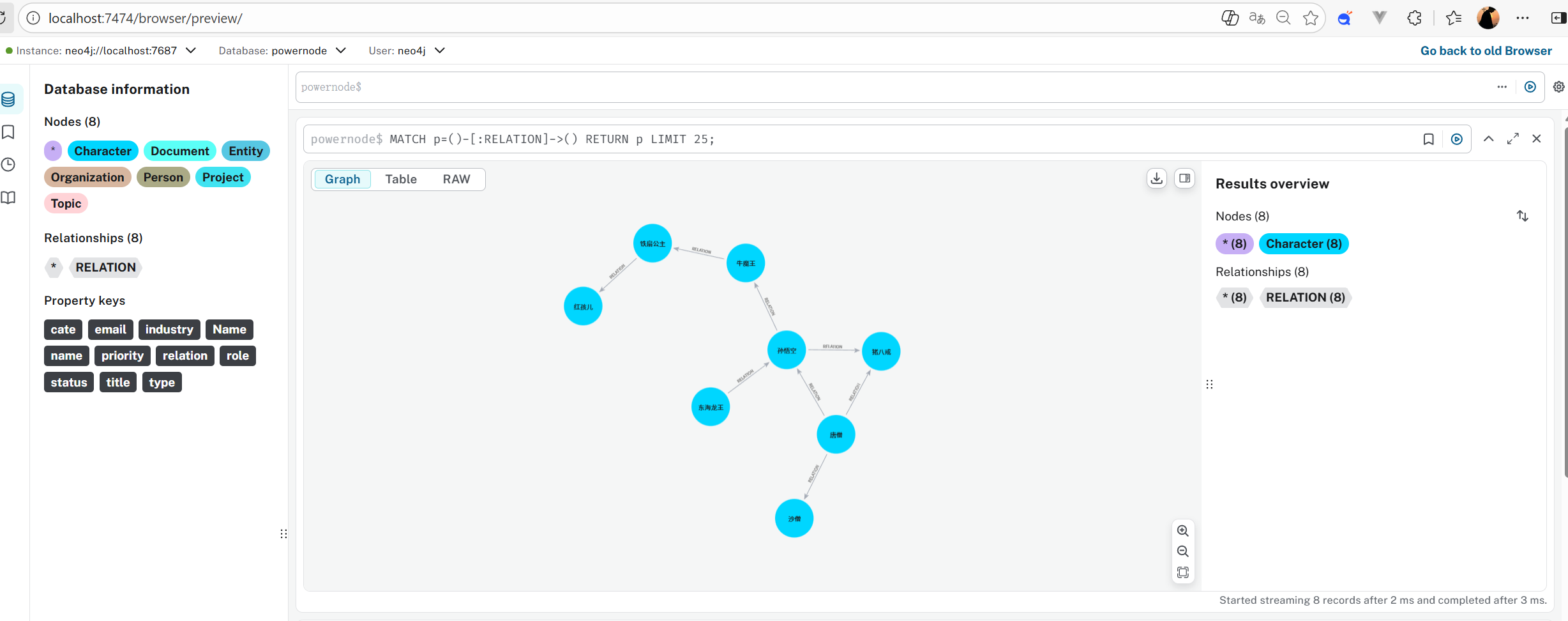
五、 见证时刻:可视化查询
回到浏览器 http://localhost:7474。
-
在顶部的
Cypher$输入框中,输入查询所有数据的命令:MATCH (n) RETURN n -
点击右侧蓝色的播放按钮 ▶️。
瞬间,一张错综复杂的人物关系网就会呈现在你眼前!
-
Tips:你可以用鼠标拖拽节点,它们会像弹簧一样弹动(力导向图效果),非常解压。也可以点击节点,在底部修改颜色和大小。
-
六、 新手必读:一个数据库能存多个图谱吗?
这是很多小伙伴最容易困惑的问题:
“博主,我现在建了西游记图谱,如果我想再建一个三国演义图谱,需要重新建一个数据库吗?”
答案是:不需要!
在 Neo4j 中,我们通常把所有数据都放在同一个库里,但是通过 Label(标签) 来进行逻辑隔离。这就好比在一个 Excel 文件里,用不同的 Sheet 来区分数据。
-
西游记图谱:给节点打上
:WestJourney标签。-
查询时:
MATCH (n:WestJourney) RETURN n
-
-
三国演义图谱:给节点打上
:SanGuo标签。-
查询时:
MATCH (n:SanGuo) RETURN n
-
只要查询时带上标签,它们就是两个完全独立的平行宇宙,互不干扰;如果不带标签查,你就会看到孙悟空和诸葛亮同台竞技(这正是图数据库做跨域关联分析的优势所在)!
1. 标签 (Label) 在代码的哪里?
回顾一下我们上一篇文章的核心代码,标签就在 Cypher 语句的冒号后面:
Python
# 之前的写法
query = """
MERGE (p1:Character {name: $name1}) <-- 这里的 :Character 就是标签
...
"""
如果你想把标签改成“西游记”,最笨的办法是直接把 :Character 改成 :XiYou。但这样代码就不灵活了。
2. 进阶写法:让 Python 动态传标签 (推荐)
我们可以修改 Python 函数,让它接收一个 label 参数。这样同一个函数,既能建西游记,也能建三国。
注意: 在 Neo4j 的驱动中,标签名不能通过 $参数 传递(这是为了安全),只能通过 Python 的 f-string (字符串格式化) 拼接到语句中。
请将你的 create_relation 函数修改为如下版本:
修改后的 Python 代码 (build_graph.py)
Python
# 增加了一个 label 参数
def create_relation(self, label, person1, relation, person2):
with self.driver.session() as session:
# 【重点】使用 f-string (f"...") 将 label 变量拼接到 Cypher 语句中
# 注意看 p1:{label},这里的大括号是 Python 的占位符
query = f"""
MERGE (p1:{label} {{name: $name1}})
MERGE (p2:{label} {{name: $name2}})
MERGE (p1)-[r:RELATION {{type: $rel}}]->(p2)
RETURN p1, p2, r
"""
# 注意:上面用了 f-string 后,Cypher 原本的大括号 {} 需要写成双重大括号 {{ }} 来转义
session.run(query, name1=person1, name2=person2, rel=relation)
print(f"[{label}] 构建成功:{person1} --[{relation}]--> {person2}")
# --- 主程序调用方式 ---
if __name__ == "__main__":
# ... (连接部分省略,同上篇) ...
kg = KnowledgeGraph(URI, USER, PASSWORD)
# 1. 导入西游记数据 (打上 XiYou 标签)
xiyou_data = [("孙悟空", "师弟", "猪八戒"), ("唐僧", "徒弟", "孙悟空")]
print("--- 开始构建西游记 ---")
for p1, rel, p2 in xiyou_data:
kg.create_relation("XiYou", p1, rel, p2) # <--- 看这里,传入标签
# 2. 导入三国数据 (打上 SanGuo 标签)
sanguo_data = [("刘备", "兄弟", "关羽"), ("关羽", "兄弟", "张飞")]
print("\n--- 开始构建三国 ---")
for p1, rel, p2 in sanguo_data:
kg.create_relation("SanGuo", p1, rel, p2) # <--- 看这里,换了个标签
kg.close()
3. 运行后的效果
当你运行这段代码后,Python 会自动执行以下操作:
-
把
xiyou_data里的数据,全部盖上:XiYou的章,存入数据库。 -
把
sanguo_data里的数据,全部盖上:SanGuo的章,存入数据库。
4. 怎么在浏览器里分开看?
现在你去 Neo4j Browser (localhost:7474),就可以分开查询了:
-
只想看西游记:
CypherMATCH (n:XiYou) RETURN n(此时你绝对看不到关羽)
-
只想看三国:
CypherMATCH (n:SanGuo) RETURN n(此时你绝对看不到孙悟空)
-
想看数据库里所有东西(大杂烩):
CypherMATCH (n) RETURN n
总结
你不需要在 Excel 或原始数据里手动加一列叫“标签”。 你只需要在 Python 循环读取数据的时候,告诉代码:“现在读的这个列表是西游记的,请用 XiYou 标签;待会儿读那个列表,请用 SanGuo 标签”即可。
七、 总结与下一步
恭喜!你已经学会了最硬核的 Neo4j 社区版 的搭建与使用。
回顾一下流程:
-
下载社区版解压。
-
命令行
neo4j console启动服务。 -
浏览器访问
localhost:7474。 -
Python 脚本批量写入数据。
下一步挑战: 现在的图谱只能“看”,还不够智能。 在下一期文章中,我将讲解 《进阶篇:如何结合 BERT 模型与 Neo4j 实现智能问答系统 (KBQA)》,教你做一个能回答“孙悟空的大嫂是谁?”的 AI 机器人。
如果你觉得这篇文章对你有帮助,欢迎点赞、收藏、关注三连!有任何安装报错,请在评论区留言!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)