【简】深度强化学习理论及其应用综述
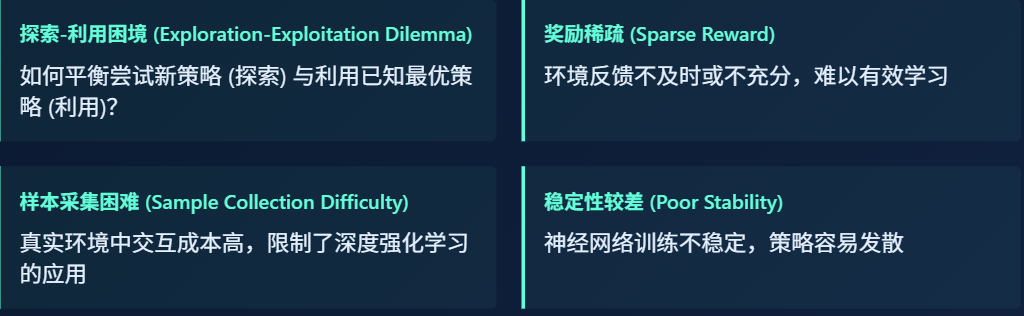
方面,随着深度强化学习理论和应用研究不断深入,其在游戏、机器人控制、对话系统、自动驾驶等领域发挥重要作用;另一方面,深度强化学习受到探索-利用困境、奖励稀疏、样本采集困难、稳定性较差等问题的限制,存在很多不足. 面对这些问题,研究者们提出各种各样的解决方法,新的理论进一步推动深度强化学习的发展,在弥补缺陷的同时扩展强化学习的研究领域,延伸出模仿学习、分层强化学习、元学习等新的研究方向. 文中从深度

1 深度强化学习的基本理论
1. 1 深度强化学习原理

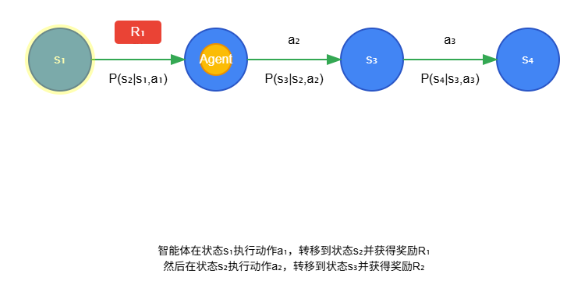
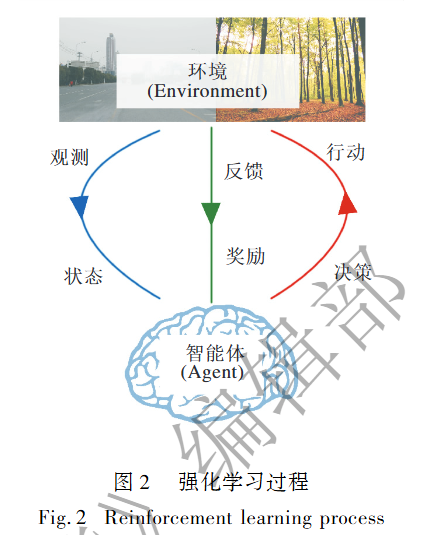
在强化 学 习 过 程 中, 决 策 的 主 体 称 为 智 能 体( Agent) . 智能体首先需要对其所处的状态进行观测,并根据观测结果( Observation) 进行决策, 采取相应行动. 该行动一方面与环境( Environment) 发生交互,环境以奖励的形式对智能体的行动给出相应的反馈;另一方面,该行动改变智能体的状态. 一个循环结束后,智能体开始新一轮的观测,直到智能体进入终止状态,此时一次完整的迭代结束,如图 2 所示. 智能体将此次迭代中的所有状态及其相应的动作以 状 态 - 动 作 序 列 的 形 式 记 录 下 来, 生 成 轨迹( Trajectory):
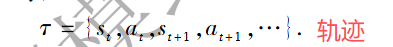
同时统计每一步的即时回报, 计算此次迭代中获得的累计回报 G t G_t Gt ,将这些信息作为策略更新时的训练样本.
1. 2 值函数和策略搜索
1. 2. 1 值函数

1. 2. 2 策略搜索

1. 2. 3 演员-评论家模型

1. 3 基于模型的强化学习和免模型的强化学习

1.4 深度强化学习的理论困境
1. 4. 1 探索-利用困境

2. UCB算法 (Upper Confidence Bound)
- 核心思想:平衡已知最优动作的利用和未知动作的探索
- 计算公式:动作分数 = 平均奖励 + √(2lnN/n)
- 平均奖励:利用项(当前已知最优)
- √(2lnN/n):探索项(鼓励尝试次数少的动作)
- 案例:老虎机问题中,有3台老虎机A、B、C:A玩了 n A = 10 n_A =10 nA=10次,平均奖励5 。B玩了 n B = 5 n_B =5 nB=5次,平均奖励6 。C玩了 n C = 2 n_C=2 nC=2次,平均奖励3。 总次数N=17, ,计算B的分数(那么 n B = 5 n_B=5 nB=5):6 + √(2ln17/5) ≈ 6 + 1.5 = 7.5
虽然A的平均奖励较低,但B的探索项更高.
动作分 数 A = 5 ( 平均奖励 ) + ( 2 ln ( N / n ) ) ∼ 5 + 1.030 = 6.030 动作分数_A =5(平均奖励) + \sqrt{(2\ln (N/n) )} \sim 5+1.030=6.030 动作分数A=5(平均奖励)+(2ln(N/n))∼5+1.030=6.030
动作分 数 C = 3 ( 平均奖励 ) + ( 2 ln ( N / n ) ) ∼ 3 + 2.0688 = 5.0688 动作分数_C =3(平均奖励) + \sqrt{(2\ln (N/n) )} \sim 3+2.0688=5.0688 动作分数C=3(平均奖励)+(2ln(N/n))∼3+2.0688=5.0688
所以选择B.可参考链接:《第二章 多臂老虎机问题 知识点总结》 (含背景,累计懊悔、增量式更新期望奖励、ϵ-贪婪策略、上置信界算法(UCB)\汤普森采样算法(Thompson sampling)、代码实现)
3. Noisy Network
- 核心思想:在神经网络权重中加入参数化噪声
- 实现方式:每个权重 w = μ + σ ⊙ ε w = μ + σ⊙ε w=μ+σ⊙ε,其中ε是随机噪声; 噪声参数 μ 和 σ μ和σ μ和σ是可训练的
- 例子:在Atari游戏中: 传统DQN使用ε-greedy,动作选择要么完全随机(ε)要么完全确定(1-ε)
- Noisy DQN通过权重噪声实现平滑探索,不需要ε-greedy
- 比如在Breakout游戏中,噪声会让小球击打方向有细微变化
《 Atari游戏介绍》 ,《Atari 2600游戏合集 - 强化学习经典应用环境》 ,《用DQN解决Atari game》
4. 最大化熵算法
-
核心思想:在目标函数中加入策略熵项
-
公式: J ( θ ) = E [ 累积奖励 ] + α H ( π ( ⋅ ∣ s ) ) J(θ) = E[累积奖励] + αH(π(·|s)) J(θ)=E[累积奖励]+αH(π(⋅∣s))
- H ( π ) H(π) H(π)是策略熵,α是温度系数
-
例子:在机器人控制中:传统方法可能只学习到一种行走方式
最大化熵会鼓励学习多种行走方式(如大步、小步等)
这在复杂地形中特别有用,因为需要多种应对策略
1. 4. 2 奖励函数设计的困难与稀疏奖励问题
如何有效地评估策略的好坏是智能体学习效率的关键,目前,策略评估主要依赖于奖励函数,而奖励函数又依赖于人类专家的设计. 对于一些复杂的决策问题,难以设计好的奖励函数. 为此研究人员提出 元 学 习 ( Meta Learning) 、 模 仿 学 习 ( ImitationLearning) 等方式,让智能体学习从好的策略中总结相应的奖励函数,用于指导强化学习过程.

最简单的模仿学习是行为克隆( Behavior Clone) ,根据专家指导, 采取监督学习的方式直接学习策略. 行为克隆仅适用于简单策略的学习,对于更复杂的策略,模仿学习采用的方法是两步迭代式训练法.
一种经典的两步迭代模仿学习方法是学徒学习( Apprenticeship Learning) [46] ,
1️⃣ 在第 1步中,专家首先要对奖励函数建模,将奖励函数定义为一系列基本损失函数的线性组合</font>:
智能体在此基础上优化奖励函数,从策略池中采样智能体策略. 对比专家 策 略, 最 大 化 专 家 策 略 对 应 的 累 积 回 报 的优势

2️⃣在第 2 步中,智能体利用第 1 步中学习到的奖励函数指导强化学习过程,更新策略,将更新后的策略存入策略池中. 经过迭代可以得到最终的奖励函数和目标策略.
近两年的模仿学习研究主要聚焦于机器人控制领域的应用, 其中一个较重要的发现是 OpenAI 团队[48] 提出的对抗模仿学习 ( Generative Adversarial Imitation Learning,GAIL) 模型. GAIL 将生成对抗网络引入模仿学习中,使用生成器生成行动,使用判别器判别行动是否来源于专家策略,获得较好效果. 一些其它的工作包括简化模仿 学 习 的 复 杂 性[49] , 提 高 样 本 的 利 用 效率[50] 、提高算法的鲁棒性[51] 等也受到研究者们的关注.
1. 4. 3 策略优化过程中面临的挑战

3. 深度强化学习应用及其面对的挑战
3. 1 机器人控制

3.2 游戏

3.3 其他领域

4. 未来展望与挑战


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)