Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis
自动化程序修复(APR)技术因有望为开发人员简化漏洞修复流程,已受到广泛关注。近年来,基于大型语言模型(LLM)的 APR 方法在修复真实世界漏洞方面展现出潜力。然而,现有 APR 方法往往直接使用 LLM 生成的补丁,未进行进一步优化,因缺乏程序特定知识导致效果受限。此外,这些 APR 方法的评估通常基于 “完美故障定位” 假设,而这一假设可能无法准确反映其在真实场景中的有效性。为解决这些局限性
结合大型语言模型与程序分析的混合自动化程序修复技术
基本信息
博客贡献人
谷雨
期刊
ACM Transactions on Software Engineering and Methodology(TOSEM)
作者
标签
Program Repair,Large Language Model,Program Synthesis
摘要
自动化程序修复(APR)技术因有望为开发人员简化漏洞修复流程,已受到广泛关注。近年来,基于大型语言模型(LLM)的 APR 方法在修复真实世界漏洞方面展现出潜力。然而,现有 APR 方法往往直接使用 LLM 生成的补丁,未进行进一步优化,因缺乏程序特定知识导致效果受限。此外,这些 APR 方法的评估通常基于 “完美故障定位” 假设,而这一假设可能无法准确反映其在真实场景中的有效性。为解决这些局限性,本文提出一种创新的 APR 方法 ——GiantRepair。该方法的核心思路是:LLM 生成的补丁即便未必正确,也能为补丁生成过程提供有价值的指导。基于此,GiantRepair 首先从 LLM 生成的补丁中构建补丁框架,以限定补丁搜索空间;随后通过框架实例化,生成适配特定程序的上下文感知型高质量补丁。为评估该方法的性能,我们开展了两项大规模实验。结果表明,GiantRepair 不仅比直接使用 LLM 生成的补丁能修复更多漏洞(在 Defects4J v1.2 数据集上平均修复率提升 27.78%,在 Defects4J v2.0 数据集上提升 23.40%),且在 “完美故障定位” 和 “自动化故障定位” 场景下,分别比当前最先进的 APR 方法多修复至少 42 个和 7 个漏洞。
计算机科学分类体系(CCS Concepts)
- 软件及其工程 → 软件维护工具;基于搜索的软件工程
额外关键词(Additional Key Words and Phrases)
程序修复、大型语言模型、程序合成
1. 引言
随着现代软件系统规模与复杂度的持续增长,软件漏洞的发生率也随之上升,给企业和终端用户带来了巨大的经济损失与运营风险。修复这些漏洞需要开发人员投入大量时间与精力。因此,旨在为有漏洞代码自动生成正确补丁的自动化程序修复(APR)技术,已成为学术界与工业界的研究热点。
过去几年,研究人员提出了众多 APR 方法,旨在提升自动生成补丁的质量,使其更适用于真实场景。这些方法包括通过预定义修复模板、启发式规则以及约束求解技术生成补丁。尽管这些方法在修复部分真实漏洞时已被证明有效,但能正确修复的漏洞数量仍十分有限。究其原因,在于这些方法难以应对真实应用中多样化补丁的庞大搜索空间。例如,基于模板的方法依赖专业知识与人工操作构建模板;基于启发式的方法在补丁空间快速扩张时效果会下降;而基于约束的方法则面临可扩展性问题。尽管基于深度学习的 APR 方法借助深度学习技术的最新进展,大幅提升了修复能力,但许多先前研究指出,其修复能力依赖于训练数据的质量,难以修复训练过程中未接触过的漏洞。
近年来,大型语言模型(LLM)在各类软件工程任务中展现出良好效果,例如代码搜索、程序合成、缺陷检测、代码摘要等。部分最新研究也探索了 LLM 在 APR 中的应用。初步结果表明,LLM 能够正确修复真实世界的漏洞,包括一些现有 APR 方法无法修复的漏洞。这些积极成果表明,LLM 在开发更高效的 APR 方法方面具有潜力。
尽管近期研究已探索将 LLM 应用于 APR,但仍存在需解决的显著局限性:(1)现有基于 LLM 的 APR 方法直接使用 LLM 生成的补丁,未进行进一步优化或改进。然而,LLM 在生成包含局部变量、领域特定方法调用等程序特定元素的补丁时,往往难以保证准确性。这意味着,即便 LLM 生成的补丁 “接近” 理想解决方案,也可能无法通过测试用例。如何有效利用这些 “不正确” 的补丁提升整体修复能力,仍是一个尚未充分探索的问题。(2)目前对基于 LLM 的 APR 方法的评估,均基于 “完美故障定位” 假设 —— 即已知漏洞位置。但这一场景并不现实,因为实际中自动化故障定位技术的准确性往往较低。在更贴近实际的 “自动化故障定位” 场景下,基于 LLM 的 APR 方法的真实性能仍需深入研究。
为解决这些局限性,需要对基于 LLM 的 APR 方法进行更全面、更贴近实际的评估。这包括探索如何更好地利用 LLM 生成的 “不正确” 补丁中的有效信息,以及在更具挑战性的 “自动化故障定位” 场景下评估这些技术的性能。解决这些局限性,对于理解基于 LLM 的方法在 APR 领域的真实潜力与实际适用性至关重要。
本文旨在解决上述两个局限性。具体而言,为解决第一个局限性,我们提出一种新型 APR 方法 ——GiantRepair。该方法的核心思路是:LLM 生成的补丁即便未必正确,仍能为补丁生成过程提供有价值的指导。具体来说,GiantRepair 首先利用 LLM 高效生成一组多样化的候选补丁,然后将这些候选补丁抽象为捕获补丁核心结构的补丁框架。这些补丁框架随后用于指导后续的 “上下文感知型补丁生成” 过程 —— 在该过程中,补丁会被优化和实例化,以适配特定的程序上下文。这种两步式方法具有以下优势:首先,现有研究表明,尽管 LLM 具备强大的编码能力,但在生成领域特定代码元素时精度不足。因此,从 LLM 生成的补丁中提取补丁框架,有助于限定可能的补丁搜索空间(因为 LLM 能为修复过程指明明确方向),同时避开生成内容中无用的部分。相比从零开始生成补丁,这种方式能让补丁生成过程更高效、更有效。其次,通过结合 LLM(用于初始补丁生成)与上下文感知优化(用于补丁实例化)的优势,GiantRepair 能够生成可正确修复真实漏洞的高质量补丁。为解决第二个局限性并全面评估 GiantRepair 的性能,我们不仅在 “完美故障定位” 假设下(如先前研究所采用的方式)评估其有效性,还在更贴近实际的 “自动化故障定位” 场景下进行评估。这有助于我们更好地理解 GiantRepair 在真实场景中的适用性。
我们使用广泛认可的 Defects4J 基准测试集,开展了两项大规模实验,在两种不同应用场景下评估 GiantRepair:(1)在第一个场景中,我们对比了单独使用 LLM 与集成 GiantRepair 后的修复结果。结果显示,在 Defects4J v1.2 和 Defects4J v2.0 数据集上,GiantRepair 分别使单独 LLM 的修复性能平均提升了 27.78% 和 23.40%。(2)在第二个场景中,我们将 GiantRepair 与现有 LLM 集成,构建了一个独立的 APR 工具,并将其修复结果与当前最先进的 APR 方法进行对比。在 “完美故障定位” 假设下,GiantRepair 成功修复了 171 个漏洞,比性能最佳的先进 APR 方法至少多修复 42 个漏洞;在更贴近实际的 “自动化故障定位” 场景下,GiantRepair 仍比性能最佳的 APR 方法至少多修复 7 个漏洞。
总体而言,实验结果证明了 GiantRepair 的有效性与通用性,为 APR 领域的未来研究提供了新视角。结果凸显了通过更好地利用 LLM 输出提升 APR 效果的潜力。综上,本文的主要贡献如下:
- 一种创新的 APR 技术,结合了 LLM 的能力与上下文感知型补丁优化;
- 一种新型补丁生成方法,通过从 LLM 生成的补丁中提取补丁框架,限定补丁搜索空间以实现更优 APR;
- 在两种应用场景下的全面评估,实验结果证实了该方法的有效性与通用性;
- 开源了实现代码与所有实验数据,以助力该领域的未来研究;开源地址:https://github.com/Feng-Jay/GiantRepair
2. 激励性示例
本节通过实验中的两个真实案例,展示如何利用 LLM 生成的 “不正确” 补丁指导补丁生成过程,进而说明我们提出 “上下文感知型补丁生成方法” 的必要性。列表 1 展示了 Defects4J 数据集中 JacksonDatabind-51 漏洞的开发人员补丁与 LLM 生成的补丁。在本文中,以 “+” 开头的代码行表示新增行,以 “-” 开头的代码行表示删除行。
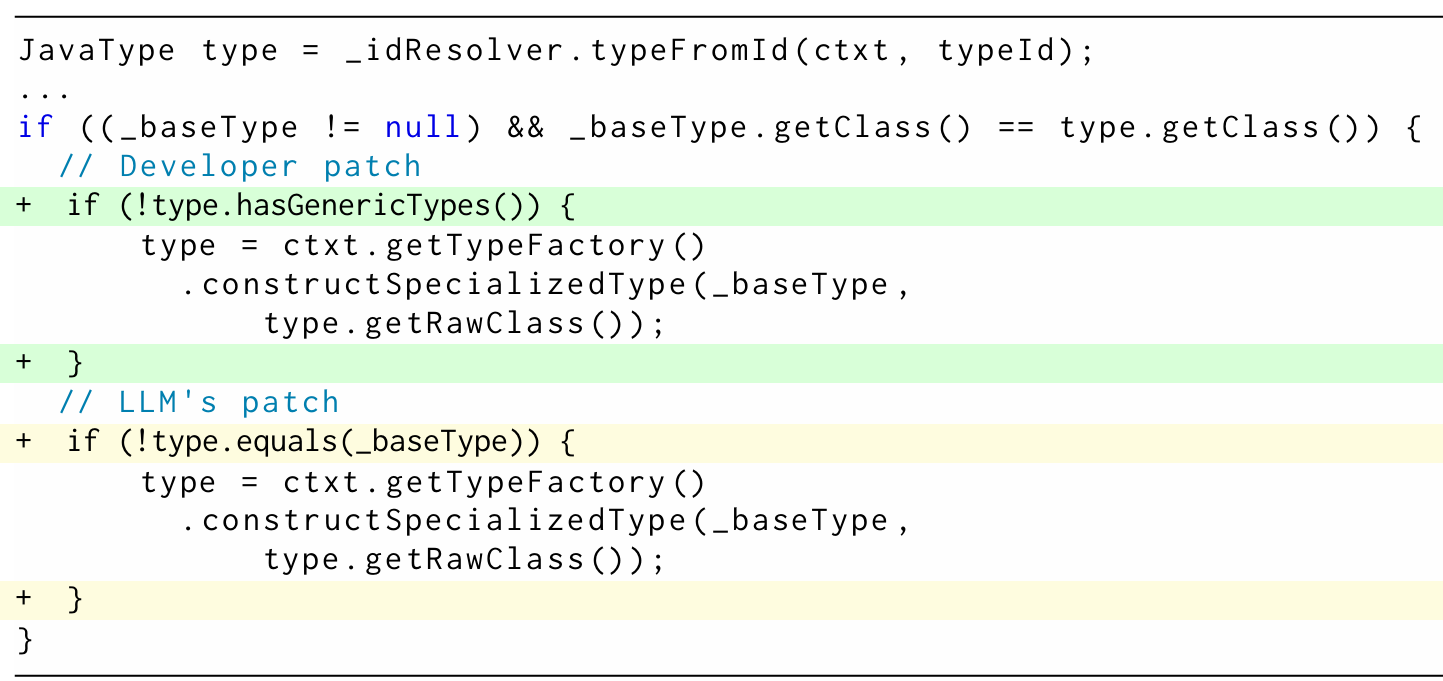
列表 1:Defects4J 数据集中 JacksonDatabind-51 漏洞的补丁
开发人员补丁表明,修复该漏洞需要新增一个 if 条件。具体而言,该漏洞的根源在于语句 “type = ctxt.getTypeFactory ().constructSpecializedType (…)” 错误地覆盖了 type 的泛型信息。因此,在执行该语句前,必须先验证当前 type 是否包含泛型,而方法调用 “hasGenericTypes ()” 正是用于实现这一验证。然而,LLM 生成的补丁使用 “!type.equals (_baseType)” 作为条件,与预期解决方案在语义上并不等价。这是因为 “type 与_baseType 相等” 并不意味着 “type 包含泛型参数”。例如,当 type 与_baseType 均为无泛型的 SimpleType(如 String)时,LLM 生成的补丁会阻止 if 块内的赋值语句执行,而理想行为恰好相反。现有 APR 方法修复该漏洞面临诸多挑战:(1)难以定位确切的漏洞代码行;(2)难以判断是否需要新增 if 语句;(3)特定条件表达式(!type.hasGenericTypes ())具有领域特定性,无法通用。这些挑战导致潜在补丁的搜索空间极大,因此实验中所有现有方法(包括最新的基于 LLM 的 APR 方法)均未能成功修复该漏洞。
对比 LLM 生成的补丁与开发人员补丁可发现,二者存在一定相似性 —— 均新增了一个以方法调用为条件的 if 语句。尽管 LLM 生成的补丁缺乏领域特定知识(即方法调用 “hasGenericTypes ()”),但它通过提供相似的补丁结构(如 if 语句),为缩小潜在补丁搜索空间提供了有价值的指导。然而,由于真实场景的多样性与复杂性,如何有效利用这些 LLM 生成的补丁提升 APR 效果,仍是一个难题。例如,列表 2 展示了另一个真实漏洞的修复案例:理想补丁需要为变量 “result [resultOffset]” 新增一个赋值语句,而 LLM 生成的补丁却新增了一个 for 循环语句。在这种情况下,LLM 生成的补丁中仅有部分内容可用 —— 复用整个 for 循环无法通过测试用例。此外,还需更新数组访问中变量 x 和 y 的索引,才能构建正确的补丁。

列表 2:Defects4J 数据集中 Math-10 漏洞的补丁
为应对上述挑战,本文提出一种 “上下文感知的自适应补丁生成方法”,旨在有效复用 LLM 生成的补丁。如前所述,LLM 生成的补丁包含有价值的补丁结构。因此,该方法的核心思路是:从 LLM 生成的补丁中构建补丁框架,以限定补丁搜索空间;随后通过静态分析实现 “上下文感知的框架实例化”,生成高质量补丁。这种方式能够生成适配特定程序的补丁。
3 方法原理
本节详细介绍我们提出的方法 ——GiantRepair。如前所述,该方法的核心思路是:LLM 生成的补丁即便未必正确,仍能为补丁结构提供有价值的指导,从而限定补丁搜索空间。因此,补丁生成过程包含两个关键组件:框架构建与补丁实例化。(1)框架构建组件(3.1 节):通过对抽象语法树(AST)进行树级差异分析,对比漏洞代码与补丁代码,从 LLM 生成的补丁中提取一组代码修改;随后通过一系列抽象规则,将这些修改抽象为补丁框架。(2)补丁实例化组件(3.2 节):利用静态分析,为这些框架填充符合约束(如上下文有效、类型兼容)的程序元素,生成可执行补丁。最后,GiantRepair 根据补丁排序策略(3.3 节),通过运行测试用例评估补丁的正确性。图 1 展示了该方法的整体流程,后续小节将详细介绍每个步骤。
3.1 框架构建
如 2 节所述,在不同上下文下,LLM 生成的补丁中并非所有代码修改都是理想的。因此,需要将补丁中的代码修改拆解为独立组件,以便单独应用。为实现这一目标,GiantRepair 包含 “修改提取” 过程 —— 通过对比漏洞代码与补丁代码的树级差异,识别所有具体的代码修改。随后,每个识别出的修改会被抽象为补丁框架,用于后续补丁生成。
3.1.1 修改提取
为提取具体的修改,GiantRepair 会执行树级代码匹配与差异分析。具体而言,GiantRepair 会尝试匹配漏洞代码与补丁代码中的代码元素,然后针对二者间的差异元素生成代码修改。本研究中,我们采用 “语句级” 代码匹配,而非 “表达式级” 匹配,原因如下:(1)语句匹配效率更高,且不易产生错误匹配 —— 不同语句的差异性较大,而细粒度的表达式在不同位置重复的可能性更高;(2)语句级代码修改的搜索空间相对较小,更便于框架构建与实例化。
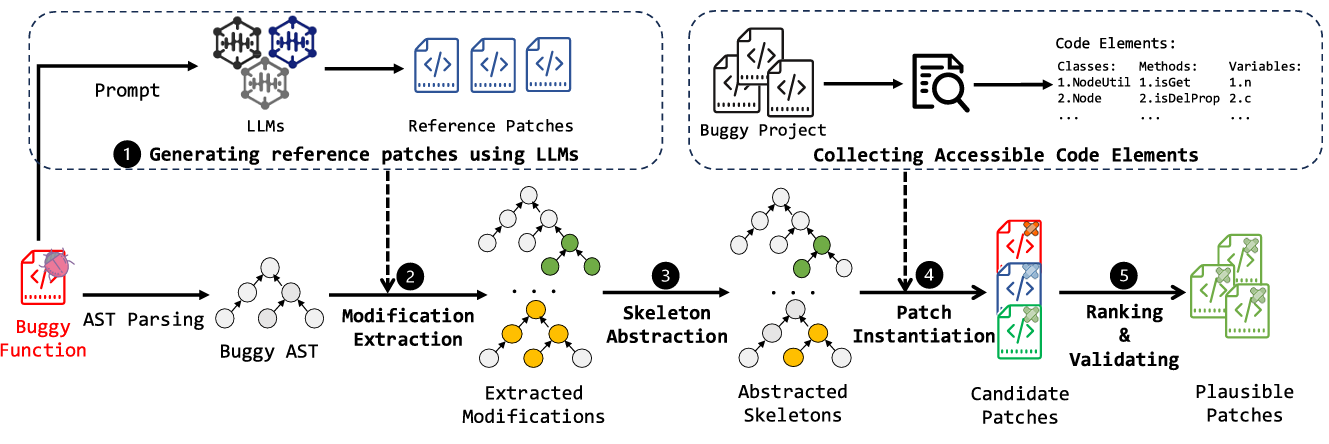
图 1 GiantRepair概览

算法 1 AST节点匹配
算法 1 展示了 GiantRepair 中的匹配算法,该算法受 GumTreeDiff 启发。其中,函数 “type (a)” 表示节点 a 的 AST 节点类型(如 IfStatement),“children (a)” 返回节点 a 的子语句集合。该算法以两个 AST 节点(分别来自漏洞代码与补丁代码)为输入,采用贪心策略自上而下递归执行匹配过程 —— 只要两个 AST 节点(即语句)的类型相同,即可相互匹配(第 12 行)。在此过程后,漏洞代码中的一个语句可能会与补丁代码中的多个语句匹配(根据第 14 行)。为获得最佳匹配并提取最少修改,GiantRepair 会移除冗余匹配,通过衡量匹配语句间的相似度保留最佳匹配(第 3 行)。公式(1)定义了两个语句间相似度的计算方式。在该公式中,“原子语句(atomic stmts)” 指无法进一步拆解的语句(如 ExpressionStatement),“组合语句(ensembled stmts)” 指由其他语句组合而成的语句(如 IfStatement)。此外,函数 “editDistance (a, b)” 计算节点 a 和 b 对应的代码片段之间的令牌级编辑距离,“” 表示节点 a 的子语句集合。
(1)
通过算法 1 获得匹配结果后,GiantRepair 会在语句级提取具体的修改。假设语句 a 来自漏洞代码,语句 b 来自补丁代码,GiantRepair 会根据匹配结果生成以下修改:
- Update (a, b):若 a 与 b 匹配但代码不完全相同,则用语句 b 替换语句 a;
- Insert (b, i):若 b 未与任何语句匹配,但其父节点 P 与语句 P' 匹配,则将语句 b 作为 P' 的第 i 个子语句插入漏洞代码(i 为 b 在 P 中的索引);
- Delete (a):从漏洞代码中删除语句 a。
直观而言,将所有提取的修改应用于漏洞代码后,即可得到与补丁代码完全一致的代码。
3.1.2 框架抽象
如前所述,从 LLM 生成的补丁中提取的修改包含有价值的指导信息。具体而言,这些修改往往在正确位置进行变更,且具有与正确修复相似的 AST 结构。然而,直接应用这些修改未必能生成正确补丁 —— 因为它们可能引入不适用于当前修复上下文的错误程序元素。为解决这一问题,GiantRepair 引入 “代码抽象” 过程:在通过上述算法获得具体修改后,通过移除具体程序元素、保留代码结构,构建补丁框架,以限定后续补丁生成的范围。具体而言,GiantRepair 仅对 “Update (a, b)” 和 “Insert (b, i)” 修改中的语句 b 执行抽象过程;对于 “Delete (a)” 修改,由于不会向程序中引入新元素,因此无需抽象。
表 1 针对不同 AST 节点类型的补丁框架构建抽象规则
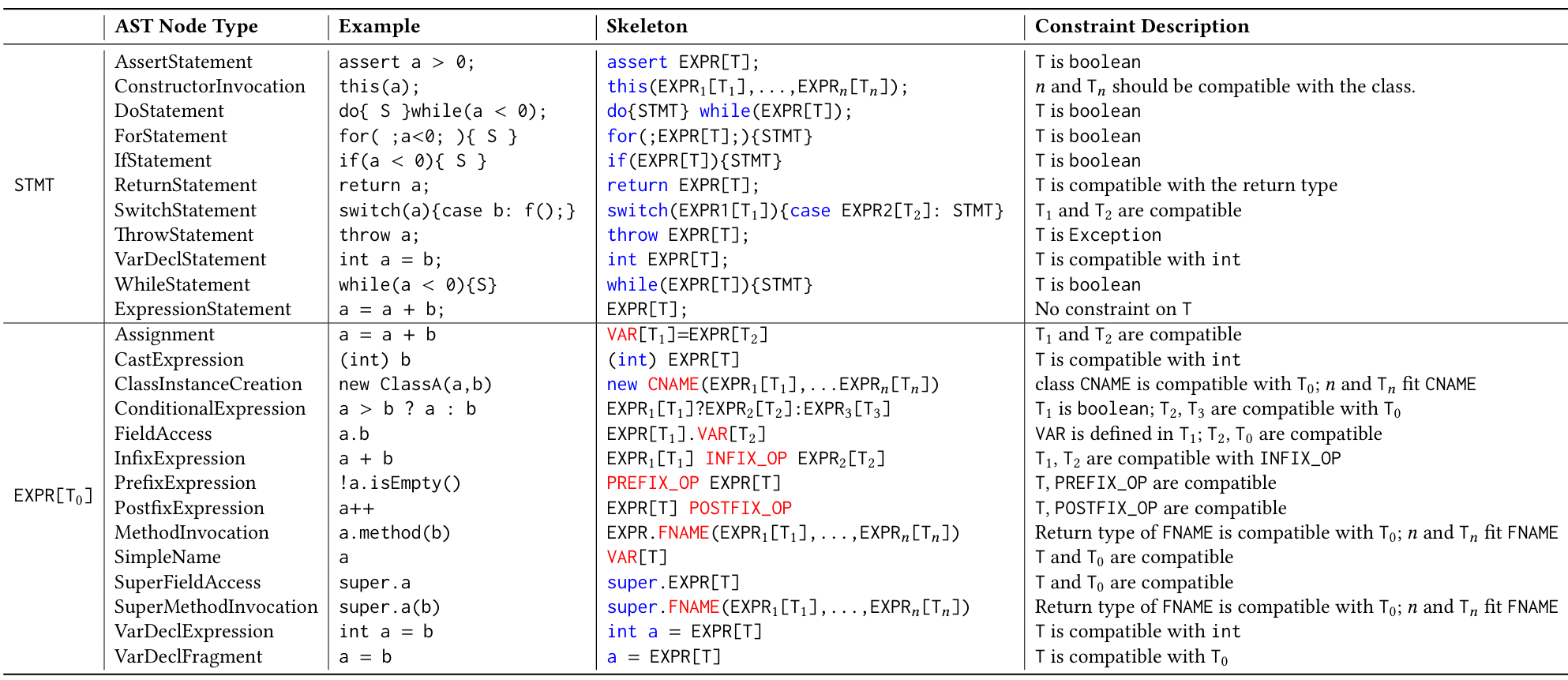
(框架中蓝色令牌为关键字,在抽象过程中从源代码扩展而来;红色令牌需通过静态分析实例化,用于生成补丁。其中,EXPR [T] 表示表达式 EXPR 的类型受 T 约束。)
更详细地说,我们根据 Java 开发工具包(JDK)中的 AST 节点定义,制定了一套代码抽象规则。表 1 详细列出了这些规则。表中第一列是抽象符号,这些符号会根据第二列所示的实际 AST 节点类型进一步抽象。也就是说,抽象过程是按照代码的抽象语法树结构,自上而下递归执行的,直到无法通过任何规则进一步抽象(如单个变量或运算符)。为便于理解框架构建规则(第四列),我们为每种 AST 节点类型提供了一个简单示例(第三列)。最后一列描述了在实例化框架生成补丁时必须满足的约束条件。以断言语句 “assert a>0;” 为例,其抽象框架为 “assert EXPR [boolean]”,其中 “EXPR” 会根据 “中缀表达式(InfixExpression)” 的规则进一步抽象为 “VAR INFIX_OP 0”。需要注意的是,我们不会对代码中的常量值(如 0)进行抽象,因为它们不属于程序特定元素,可以直接复用。因此,最终框架为 “assert VAR INFIX_OP 0;”,其中 “VAR” 必须是数值类型的变量(如 int、float),“INFIX_OP” 必须是逻辑比较运算符(如 >、<)。通过这种方式,既能保留 LLM 生成补丁的结构以有效限定补丁搜索空间,又能通过静态分析对抽象令牌(红色标注)进行实例化,以适配特定程序。
3.2 补丁实例化
根据上述构建的补丁框架,补丁实例化过程的核心是:将框架中的抽象令牌替换为符合约束条件的具体程序元素。具体而言,最终框架中共有四类需实例化的抽象令牌(见表 1):变量(VAR)、类(CNAME)、方法调用(FNAME)以及运算符(INFIX_OP、PREFIX_OP、POSTFIX_OP)。尽管框架已能有效限定补丁搜索空间,但随机生成补丁仍可能面临较大搜索空间,导致效率低下,且在有限时间预算内易失败。因此,GiantRepair 在框架实例化过程中引入 “上下文感知型补丁生成策略”,包含以下三项优化:
- 元素选择:所有使用的元素必须在特定上下文下可用,且符合补丁框架的约束。对于运算符,由于数量极少(<10),GiantRepair 在框架实例化时会枚举所有类型兼容的运算符;对于其他三类令牌,GiantRepair 通过静态分析收集所有可用元素:对于变量,记录其类型与作用域;对于类,记录其继承关系与可访问字段;对于方法调用,记录其完整签名(包括所需参数、返回类型及所属类)。通过检查框架关联的约束,可判断这些程序元素的可用性。
- 上下文相似度:GiantRepair 考虑两类相似度 —— 实例化补丁与漏洞代码的相似度、实例化补丁与 LLM 生成补丁的相似度。第一类相似度的设计灵感来自先前研究,这些研究指出,真实场景中的理想补丁往往仅涉及少量代码修改;第二类相似度的设计灵感来自本文的核心发现与 LLM 的优异表现 ——LLM 能为补丁生成提供有价值的素材。为实现这一目标,GiantRepair 首先会尽可能保留漏洞代码与 LLM 补丁中共同使用的代码元素(如变量);对于不同元素,会优先选择与 LLM 补丁 “更接近” 的补丁。具体而言,使用通用的令牌级编辑距离衡量补丁间的接近程度。原因在于,实例化补丁与 LLM 补丁具有相同框架,二者的主要差异集中在变量名与函数名上;而 “接近程度” 可通过是否使用与 LLM 补丁相同的变量或函数调用来体现,这种差异可通过令牌级编辑距离有效衡量。
- 自适应应用:如 2 节所述,LLM 补丁中可能仅有部分内容是理想的。因此,若包含所有代码修改的补丁未能修复漏洞,GiantRepair 会自适应地应用部分提取的修改。具体而言,GiantRepair 会尝试在一个补丁中最多应用三个独立修改,以生成数量合理且易于管理的补丁。现有文献及 2 节的激励性示例表明,LLM 在编码相关任务中表现出强大能力,其生成的补丁往往包含有价值的修改。为充分利用 LLM 生成补丁中的指导信息,GiantRepair 会优先选择复杂度最高的修改进行组合 —— 如前所述,这种方式能最大化利用补丁中的有价值信息。
基于上述补丁实例化过程,对于一个 LLM 生成的补丁,GiantRepair 会在抽象补丁框架的基础上生成候选补丁,从而有效限定补丁的搜索空间。
3.3 补丁排序与验证
为优先评估最可能正确的补丁,我们设计了一套补丁排序策略。现有研究 表明,LLM 在代码理解与生成方面具备强大能力。因此,对于 LLM 生成的候选补丁集合,GiantRepair 会优先选择能为补丁生成提供更多新资源的补丁。通过这种方式,可最大化利用 LLM 的代码生成能力,为生成有效修复提供更多与修复相关的信息。具体而言,GiantRepair 会统计补丁中包含的 “Insert ()” 和 “Update ()” 修改数量 —— 因为这两类修改能引入新的程序元素 / 结构,而 “Delete (*)” 无法做到。这类修改数量越多,补丁排名越高。随后,针对每个 LLM 生成的补丁,GiantRepair 通过上述补丁实例化过程构建候选补丁。最后,GiantRepair 会为每个补丁运行相关测试用例,将通过所有测试用例的补丁视为 “可信补丁”—— 这与现有研究的做法一致。在此过程中,GiantRepair 使用 ExpressAPR 框架管理测试运行。与现有研究一致,只有经人工检查确认与开发人员补丁在语义上等价的补丁,才被视为 “正确补丁”。
4 实验设置
4.1 研究问题
为评估 GiantRepair 的有效性,本文旨在回答以下研究问题:
- RQ1:GiantRepair 在提升 LLM 修复真实漏洞的能力方面效果如何?本问题探索 GiantRepair 能否提升现有 LLM 在程序修复任务中的有效性。具体而言,将 GiantRepair 与不同 LLM 集成,验证其是否能比直接使用 LLM 生成的补丁修复更多漏洞。
- RQ2:与当前最先进的 APR 工具相比,GiantRepair 的有效性如何?本问题中,参考现有研究 [20,38,39] 的做法,将 GiantRepair 与现有 LLM 集成,构建独立的 APR 工具,并将其性能与一系列最先进的 APR 工具进行对比。
- RQ3:GiantRepair 中各组件的贡献度如何?本问题探索 GiantRepair 中各组件对其有效性的贡献。具体而言,如 3 节所述,GiantRepair 包含四个主要组件:补丁框架构建、上下文感知型补丁实例化、修改的自适应应用以及补丁排序。对于第一个组件,探索框架构建中各抽象规则(见表 1)对生成正确补丁的贡献;对于后三个组件,通过构建 GiantRepair 的多个变体,分析其有效性。具体细节将在 5.3 节介绍。
4.2 实验对象
实验采用广泛研究的 Defects4J 基准测试集,为验证 GiantRepair 的通用性,同时使用该测试集的 1.2 版本与 2.0 版本。其中,Defects4J v1.2 包含来自 6 个真实项目的 391 个漏洞,Defects4J v2.0 包含来自 11 个真实项目的 438 个漏洞。参考现有研究的做法,向 LLM 提供有漏洞的函数,由其生成候选补丁。选择函数级输入的原因有二:(1)单个函数的代码长度适合当前 LLM 的输入输出限制,且整个函数能为 LLM 提供局部上下文;(2)函数级故障定位比行级故障定位更精确,基于该定位方式的 APR 工具在实际应用中更具实用性。因此,实验中移除了需要跨函数修改的漏洞,最终在评估中使用 Defects4J v1.2 中的 255 个单函数漏洞与 Defects4J v2.0 中的 228 个单函数漏洞。
4.3 基准方法与评价指标
为回答 RQ1,选择四个常用 LLM 作为基准方法,包括两个通用 LLM(GPT-3.5 Turbo 、Llama-2)和两个代码专用 LLM(StarCoder、CodeLlama)。这些 LLM 已在多种软件工程任务中应用,并被证明在 APR 任务中有效。
为回答 RQ2,受篇幅限制,选择 11 个最新且性能最佳的 APR 工具作为对比基准,包括 4 个基于 LLM 的工具(FitRepair、Repilot、GAMMA、AlphaRepair)、5 个基于深度学习的专用工具(Tare、ITER、CURE、Recoder、Hanabi)、1 个基于模板的工具(TBar)以及 1 个基于启发式搜索的工具(SimFix)。这些 APR 工具涵盖了近年来 APR 研究中大部分最先进技术。此外,在 6.1 节中,还将对本文方法与现有 APR 工具的 “独特修复” 能力进行更全面的对比。
本文中,“可信补丁” 指能通过所有测试用例的补丁;“正确补丁” 指经确认与开发人员补丁在语义上等价的可信补丁。参考先前研究,在结果分析中,主要对比各基准方法能正确修复的漏洞数量。此外,还计算生成补丁的 “精度”(正确补丁数量与可信补丁数量的比值)与 “召回率”(正确补丁数量与可修复漏洞总数的比值)。
4.4 实现与配置
基础模型:选择四个现有研究中广泛使用的模型,包括三个开源模型(StarCoderBase,即 StarCoder-15.5B;CodeLlama-7B;Llama-2-13B)和一个闭源模型(GPT-3.5)。这些模型在多项任务中表现出色。前三个开源模型从 HuggingFace下载并部署在本地机器上,闭源模型 GPT-3.5 通过 API 接口调用。对于每个模型,复用 Xia 等人(Automated program repair in the era of large pre trained language models,2023)提出的提示词,并采用模型默认设置生成补丁 ——Top-p 核采样(p=0.95)、温度系数(temperature=0.8)。图 2 展示了实验中使用的提示词模板,具体采用 “两示例(two-shot)” 方式:第一个示例向 LLM 展示修复任务及预期输出格式;第二个示例来自漏洞所属项目,为 LLM 提供相关编码风格参考;最后包含待修复的具体漏洞。对于每个漏洞,一个 LLM 最多生成 200 个补丁。其他基准 APR 工具的实验结果直接复用其对应文献中的数据。
GiantRepair:采用 Java 语言实现,代码量约 22000 行。修复过程中,基于一个 LLM 生成补丁的框架,GiantRepair 最多生成 200 个候选补丁。参考现有研究的做法,为修复单个漏洞设置 5 小时的时间预算。
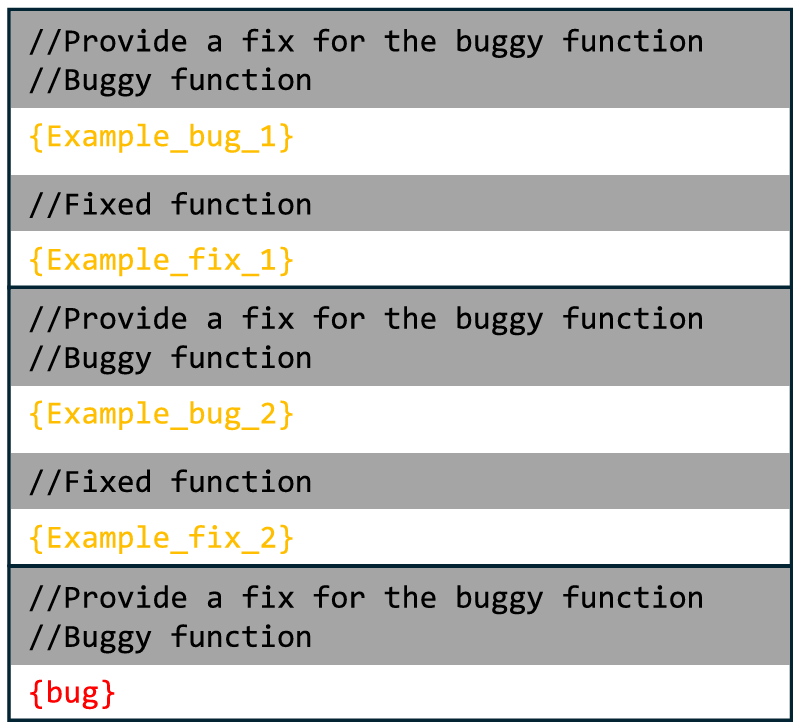
图 2:函数级 APR 的输入提示模板
故障定位:如 1 节所述,实验在 “完美故障定位” 与 “非完美(即自动化)故障定位” 两种场景下全面评估 GiantRepair 的性能。在第一种场景中,给定完美故障定位结果(即明确的漏洞代码行),首先将这些代码行映射到其所属的函数 —— 这一步是必要的,因为如图 2 所示,本文方法以整个有漏洞的函数为输入,而非孤立的漏洞行;随后直接将每个有漏洞的函数输入 LLM,生成补丁。在第二种场景中,参考现有研究的做法,采用基于谱的 Ochiai 算法(由 GZoltar实现)获取漏洞代码行列表;参考现有研究的做法,进一步将这些漏洞行映射到其所属的函数,得到函数级故障定位结果,并将其输入本文方法;随后按照函数排名,尝试为每个函数生成补丁,直至超过时间限制。需要注意的是,部分基准 APR 工具(如 FitRepair、Repilot)在实验中采用更细粒度的 “行级完美故障定位”(即提供漏洞行)—— 尽管这种方式能将补丁空间限定在单行内,精度更高,但由于这些基准工具无法支持函数级故障定位,本文未统一这一配置。这种差异可能导致在与基准工具对比时,低估 GiantRepair 的有效性。
实验环境:实验在本地机器上进行,配置为双 Intel Xeon 6388 CPU、512GB 内存、四块 A800 GPU,操作系统为 Ubuntu 20.04.6LTS。
5 结果分析
5.1 RQ1:GiantRepair 提升 LLM 在 APR 中有效性的整体表现
如 4.1 节所述,为评估本文方法能否更好地利用 LLM 生成的补丁进行程序修复,将 GiantRepair 的修复结果与直接使用 LLM 生成补丁的结果进行对比。具体而言,选择四个不同 LLM 进行对比,以体现本文方法的通用性(见 4.3 节)。实验中,参考现有研究的做法,为 LLM 提供函数级完美故障定位。表 2 展示了各方法能正确修复的漏洞数量,其中 “GiantRepair_GPT-3.5” 表示 GiantRepair 以 GPT-3.5 生成的补丁为输入时的修复结果。
表 2:不同 LLM 的修复结果对比
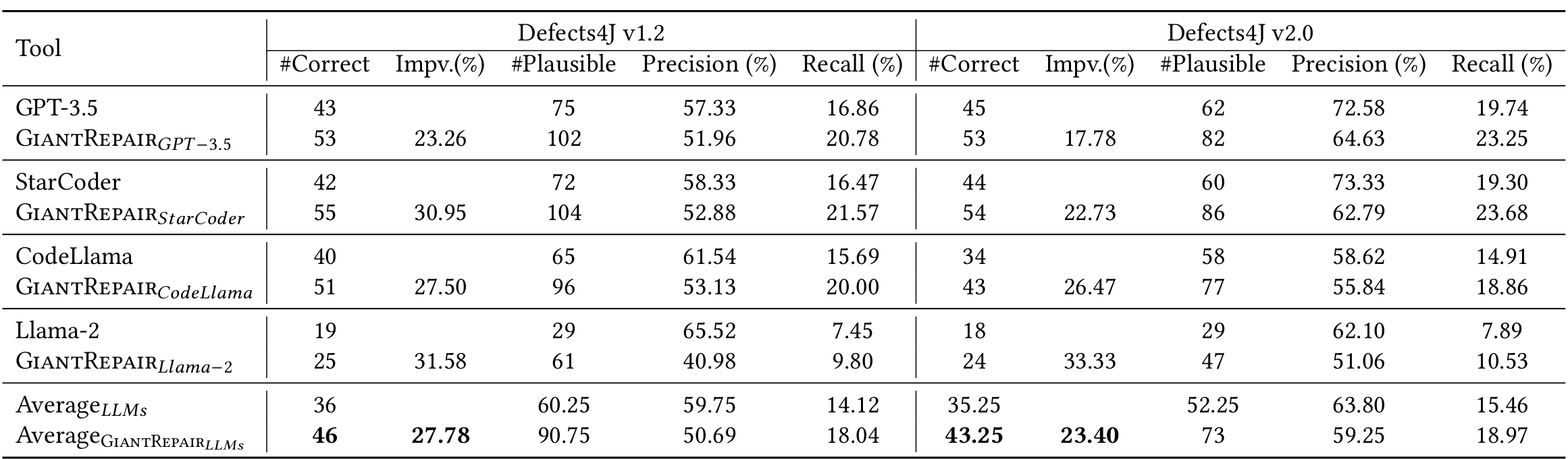
从表中可观察到,与直接使用 LLM 生成的补丁相比,GiantRepair 能显著增加正确修复的漏洞数量。具体而言,在 Defects4J v1.2 数据集上,与四个 LLM 相比,GiantRepair 将正确修复数量分别从 43、42、40、19 提升至 53、55、51、25,相对提升最高达 31.58%,平均提升 27.78%;在 Defects4J v2.0 数据集上,正确修复数量从 45、44、34、18 提升至 53、54、43、24,相对提升最高达 33.33%,平均提升 23.40%。这一结果表明,GiantRepair 在提升不同 LLM 的修复性能方面具有通用性 —— 在不同基准测试集上,对不同模型的提升效果相近。
此外,实验中所选 LLM 的修复性能与现有研究一致:GPT-3.5 > StarCoder > CodeLlama > Llama-2。这表明,LLM 的训练目标对其性能的影响可能大于模型规模。例如,尽管 GPT-3.5 的模型规模远大于 StarCoder,但在实验中二者的修复效果非常接近;而基于 Llama-2 在代码上微调得到的 CodeLlama,在补丁生成方面表现出显著提升。未来将进一步探索这一现象在更广泛范围内的表现。
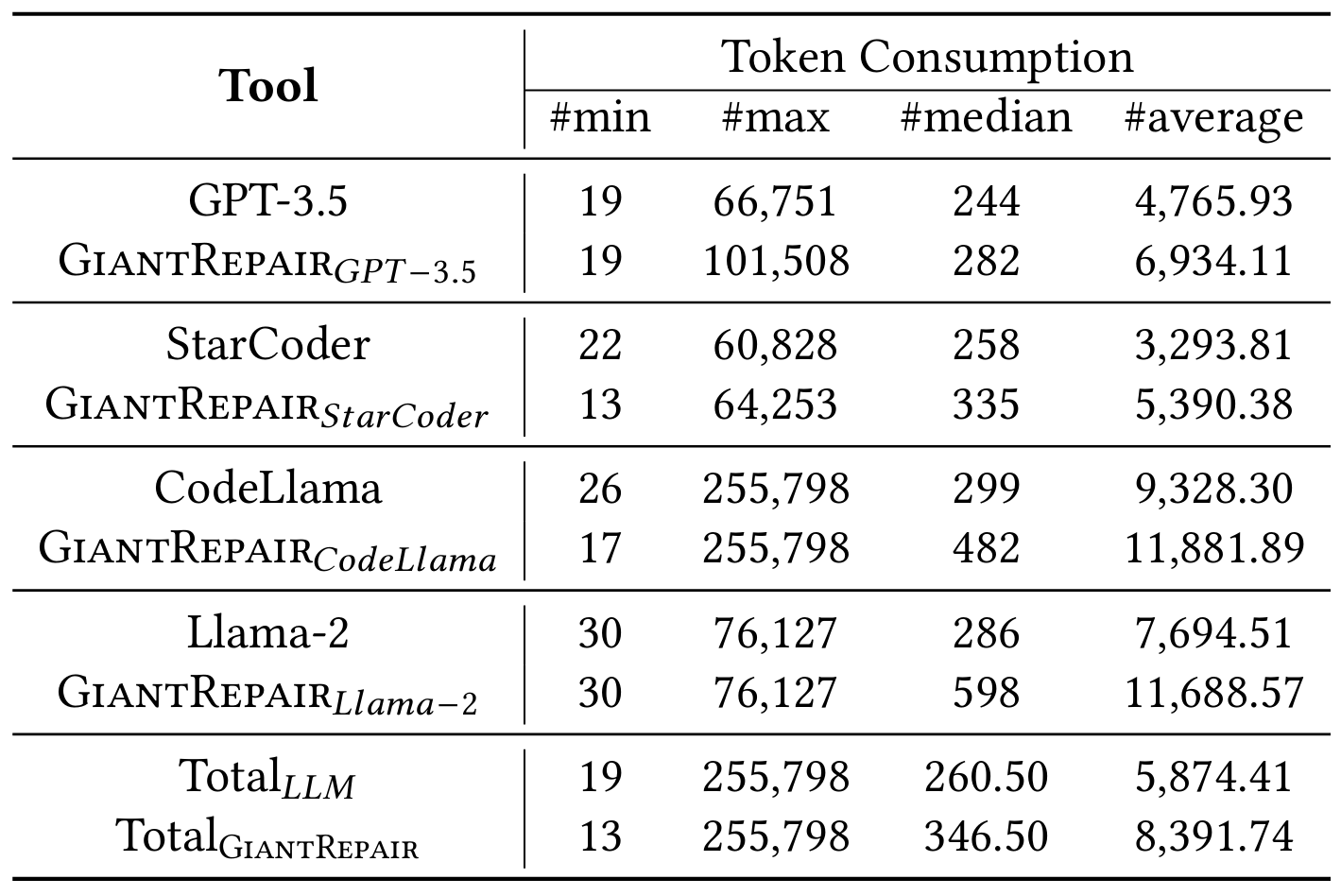
为分析 GiantRepair 在探索补丁空间过程中引入的额外开销,从两个角度进行分析:(1)精度与召回率的平衡。如表 2 所示,尽管 GiantRepair 导致每个 LLM 的补丁精度有所下降,但与正确修复数量的提升相比,这种下降幅度相对较小。Llama-2 的精度下降最为明显,我们认为这是由于其编码能力较弱,提供的指导信息有效性较低。在 Defects4J v1.2 和 v2.0 数据集上,补丁精度平均分别从 59.75%、63.80% 下降至 50.69%、59.25%,下降幅度较小,且与召回率的提升(在两个数据集上分别从 14.12%、15.46% 提升至 18.04%、18.97%)相当,表明 GiantRepair 在精度与召回率之间取得了良好平衡。此外,现有研究 [69] 指出,在调试工具的辅助下,可信补丁不会显著降低开发人员的调试效率;且可进一步结合补丁过滤工具提升补丁精度。(2)令牌与时间消耗。为探索本文方法的开销,进一步分析了 GiantRepair 生成所有正确补丁所需的令牌与时间消耗。如表 3 所示,与直接使用 LLM 相比,GiantRepair 生成一个正确补丁平均仅需额外消耗 2517.33 个输出令牌 —— 根据 GPT-4o 模型的定价,修复一个漏洞平均仅需额外花费 0.025 美元。在时间消耗方面,约 71.67% 的正确补丁能在 0.5 小时内生成,绝大多数(约 93.25%)能在 2 小时内生成。与许多现有方法(修复一个漏洞可能需要约 5 小时)相比,这一执行时间是可接受的。
表 3:GiantRepair 生成正确补丁的令牌消耗
实验还分析了不同 LLM 在该任务中的互补性。图 3 展示了 GiantRepair 与各 LLM 集成时 “独特修复” 的漏洞数量(即仅该组合能修复的漏洞)。结果表明,尽管不同 LLM 的表现存在差异,但它们往往具有互补性 —— 每个 LLM 都能为某些独特漏洞提供有价值的修复指导。例如,修复数量最少的 Llama-2,仍贡献了 3 个独特修复。这表明,在 APR 中应同时考虑代码专用 LLM 与通用 LLM。此外,该结果还启发我们探索:若考虑不同 LLM 间的互补性,GiantRepair 能否进一步提升修复性能?因此,我们将四个 LLM 的修复结果组合,与以所有 LLM 补丁为输入的 GiantRepair 进行对比。结果显示,四个 LLM 组合在两个基准测试集上共修复 141 个漏洞,而 GiantRepair 修复了 171 个漏洞(将在 5.2 节进一步讨论),这表明 GiantRepair 确实能有效利用 LLM 生成的补丁,提升 APR 效果。事实上,即便与最新的 GPT-4 相比,GiantRepair 仍能贡献独特修复,这一结果将在 6.2 节讨论。

图 3 GiantRepair在与不同LLM集成时独特地修复了错误
为体现本文方法的必要性与有效性,下面展示两个案例:在实验设置下,所选 LLM 未能修复这些漏洞,而 GiantRepair 生成了正确补丁。列表 3 和列表 4 分别展示了 LLM 生成的补丁与开发人员补丁。列表 3 中漏洞的根源是 “不允许内联单例获取方法”,因此需要验证内联方法是否为单例(即调用 “getSingletonGetterClassName” 方法)。然而,由于缺乏所用 API 的领域特定知识,LLM 无法生成理想补丁;但 LLM 生成的补丁通过新增 “if 语句检查 callNode”,提供了有意义的修复指导。GiantRepair 利用这一信息,构建补丁框架,并通过静态分析考虑类型约束与上下文,对框架进行实例化,最终成功修复该漏洞。

列表 3:Defects4J 数据集中 Closure-36 漏洞的补丁代码
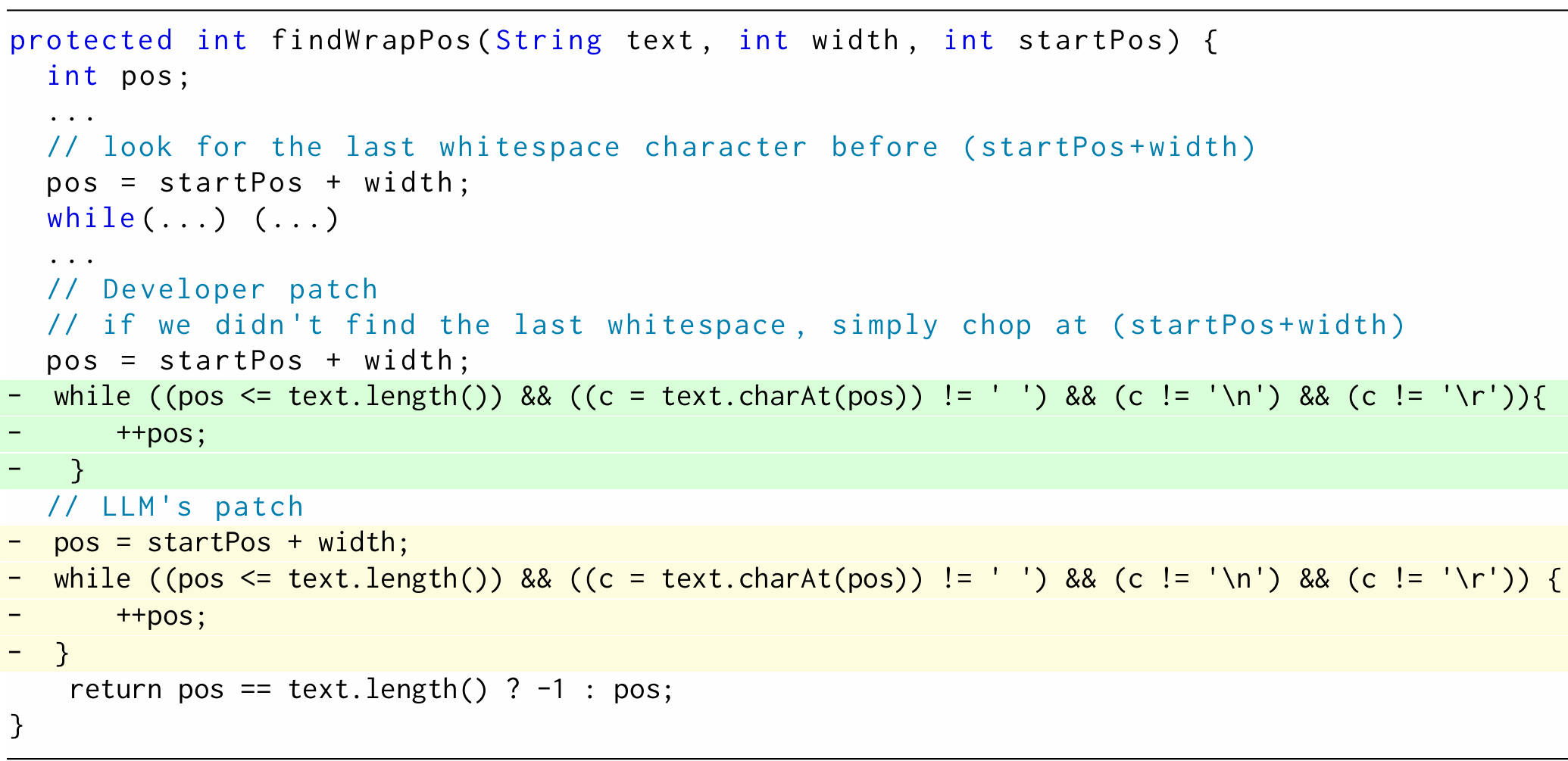
列表 4:Defects4J 数据集中 Cli-32 漏洞的补丁代码
列表 4 展示的有漏洞方法,其功能是从 “startPos” 开始、到 “startPos+width” 结束,在输入文本中查找最后一个空格的位置;若未找到空格,则返回 “startPos+width” 的位置。然而,由于 while 循环错误,有漏洞的代码会在 “startPos+width” 范围之外继续搜索空格。修复该漏洞需删除整个 while 循环语句(如开发人员补丁所示)。但 LLM 生成的补丁在删除 while 循环的同时,还错误删除了 “pos=startPos+width;” 语句,导致修复失败。而 GiantRepair 利用 “自适应补丁实例化方法”,成功生成仅删除 while 循环语句的补丁,修复了漏洞。值得注意的是,删除操作往往容易导致补丁错误,因此现有 APR 方法通常会避免使用删除操作。从这些案例可看出,GiantRepair 能有效利用程序特定知识(如 Closure-36 漏洞中需要调用 “getSingletonGetterClassName ()”)与上下文信息(如为 pos 赋值),修复 LLM 难以处理的漏洞。
5.2 RQ2:与基准方法的有效性对比
(1)完美故障定位下的性能:将本文方法与同样在 “完美故障定位” 假设下评估的最先进 APR 工具进行对比。如 4.4 节所述,GiantRepair 以有漏洞的函数为输入,利用 LLM 生成初始补丁;而基准 APR 工具可能以有漏洞的代码行为输入。表 4 展示了各 APR 工具在 Defects4J v1.2 和 v2.0 数据集上能正确修复的漏洞数量。其中,FitRepair通过同时运行四个 LLM 生成补丁。为公平对比,定义两种配置:“GR_LLM×4_all” 和 “LLM×4_all”。“GR_LLM×4_all” 表示 GiantRepair 以四个 LLM 生成的补丁(即 200×4=800 个补丁)为输入,进行后续补丁生成;“LLM×4_all” 表示不借助 GiantRepair,直接使用这四个 LLM 生成的补丁 —— 该配置显然需要更多计算资源。为与其他基准工具公平对比,还构建了另一个变体 “GR_LLM×4_part”:仅以每个 LLM 生成的前 1/4 补丁(即 50×4=200 个补丁)为输入,与单个 LLM 生成的候选补丁数量相同;相应地,“LLM×4_part” 表示直接使用这 1/4 补丁。
表 4:完美故障定位下的修复结果
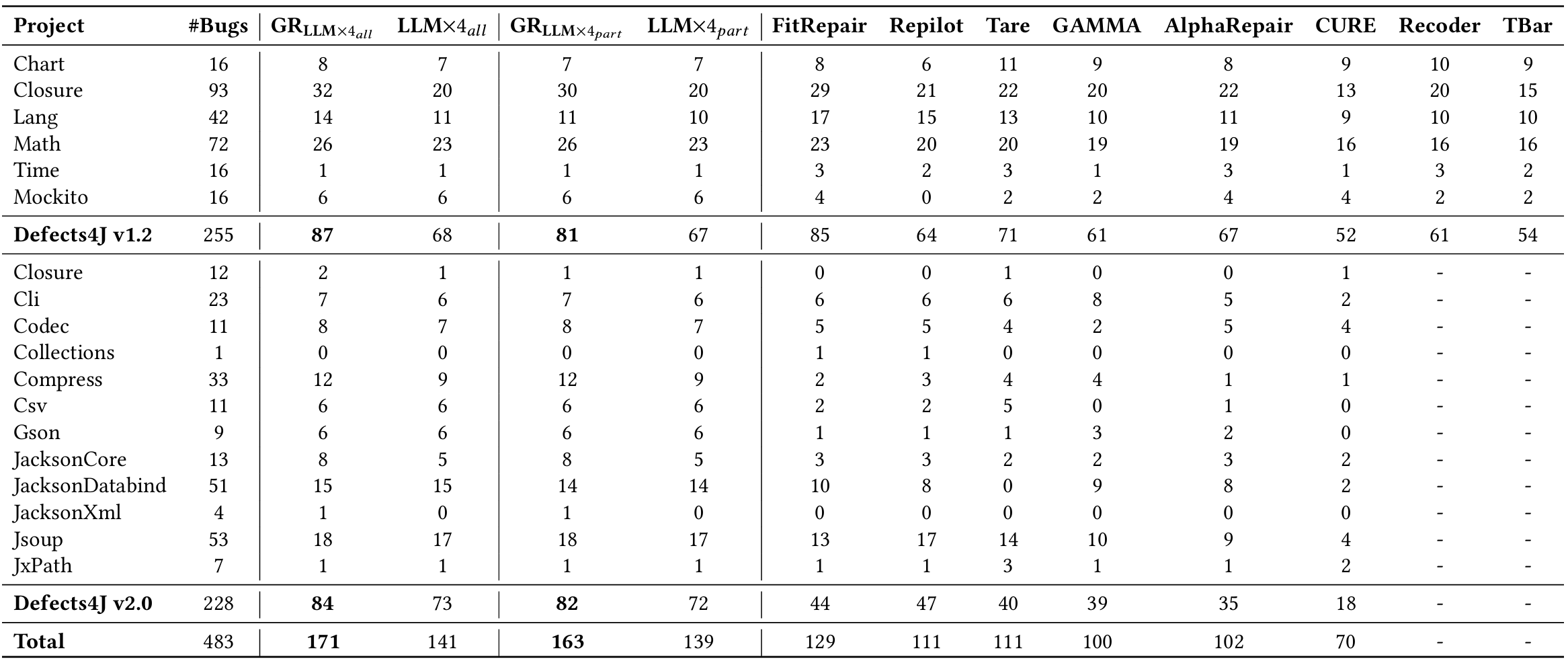
(表中 “GR” 代表本文方法 GiantRepair)
从表中可看出,GiantRepair 不仅比直接使用 LLM 生成的补丁显著提升了正确修复数量,还显著优于所有基准 APR 工具。例如,与性能最佳的 FitRepair 相比,GiantRepair 多修复了 42 个漏洞(171 个 vs. 129 个)。即便仅使用 LLM 生成的前 1/4 补丁,GiantRepair 仍比所有基准方法至少多修复 34 个漏洞(163 个 vs. 129 个)。具体而言,GiantRepair 在不同基准测试集上表现稳定;而基准 APR 工具在 Defects4J v1.2 上的表现往往优于 v2.0,这表明本文方法更具通用性,不易对特定基准测试集过拟合。如 6.3 节所示,在一个先前研究未使用过的新基准测试集上,GiantRepair 仍能有效修复多个漏洞。
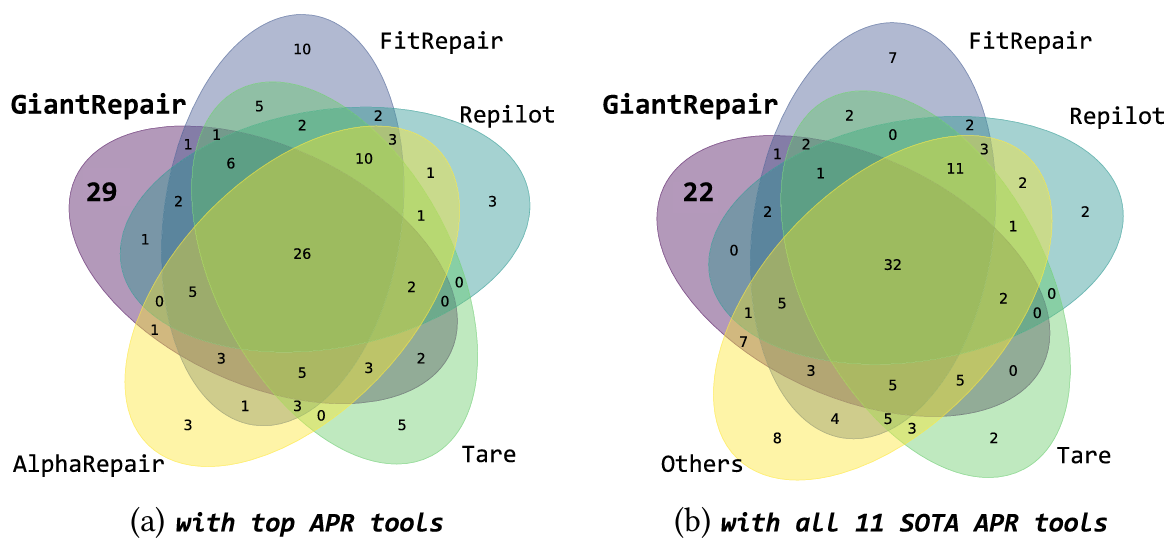
图 4 与在Defects4J v1.2上的SOTA缺陷修复基线模型相比,独特的错误修复
同样,实验还分析了本文方法与基准 APR 工具的互补性。由于并非所有 24 个基准工具都在 Defects4J v2.0 上进行过评估,因此仅在 Defects4J v1.2 上对比它们的修复结果。图 4 展示了不同 APR 工具正确修复漏洞的重叠情况:左图将本文方法与表 4 中排名前 4 的基准 APR 工具对比;右图将本文方法与 4.3 节所述的 11 个最先进 APR 工具对比。从图中可看出,与现有 APR 工具相比,GiantRepair 能修复更多新漏洞。具体而言,即便与所有 11 个最先进基准工具相比,GiantRepair 仍能修复 22 个独特漏洞,体现出其高有效性。例如,除 2 节介绍的两个漏洞外,列表 5 展示的漏洞也是一个仅能被 GiantRepair 修复、而无法被所有基准 APR 工具修复的案例。修复该漏洞需新增一个条件,因此从 LLM 生成补丁中提取的补丁框架(即新增一个方法调用作为条件)能提供有价值的指导,有效缩小潜在补丁的搜索空间。

列表 5:Defects4J 数据集中 Closure-55 漏洞的补丁代码
相比之下,现有 APR 工具往往难以在庞大的搜索空间中找到与正确修复相似的修改。此外,许多现有基于 LLM 的工具仅能修复单行或单代码块漏洞,无法处理需要多行修改的复杂漏洞。为展示 GiantRepair 修复复杂漏洞的能力,对比了 GiantRepair 与其他基于 LLM 的 APR 方法生成补丁的修改代码行数。图 5 展示了不同方法生成补丁的修改行数分布。可观察到,现有基于 LLM 的 APR 工具生成的补丁通常修改少于 3 行代码;而 GiantRepair 生成的补丁平均修改 4.9 行代码,几乎是 Repilot(平均修改 2.53 行)的 1.94 倍。这一结果进一步表明,结合 LLM 与静态分析技术具有良好前景。
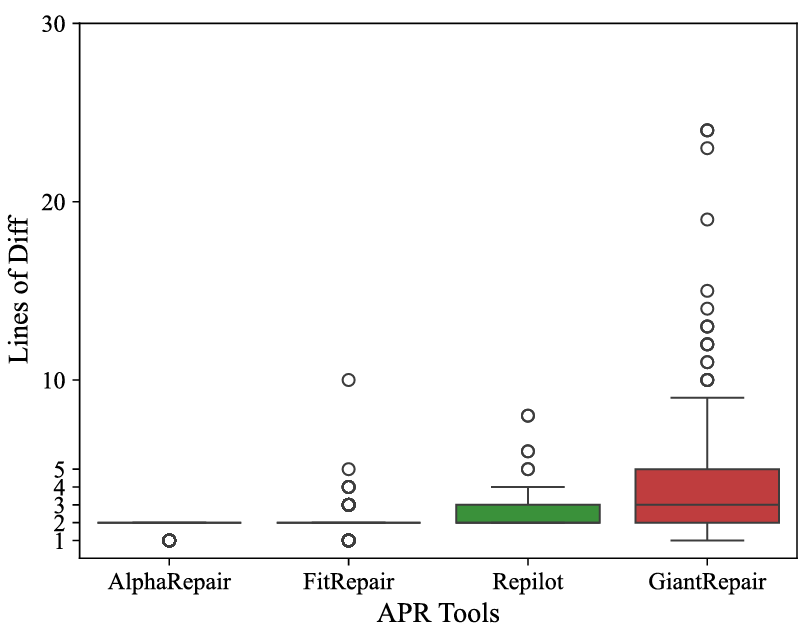
图 5 正确补丁中更改的行数
(2)非完美故障定位下的性能:如 1 节所述,现有研究通常在 “完美故障定位” 假设下评估基于 LLM 的 APR 工具。本实验在更贴近实际的 “非完美故障定位” 场景下进一步评估 GiantRepair,具体采用 4.4 节介绍的自动化故障定位结果,并与同样在此设置下评估的基准方法进行对比。表 5 展示了各方法在 Defects4J v1.2 上的修复结果(所有基准工具均在该数据集上进行过评估),同时还报告了各方法的补丁精度(与基准工具保持一致)。
表 5:非完美故障定位下的修复结果
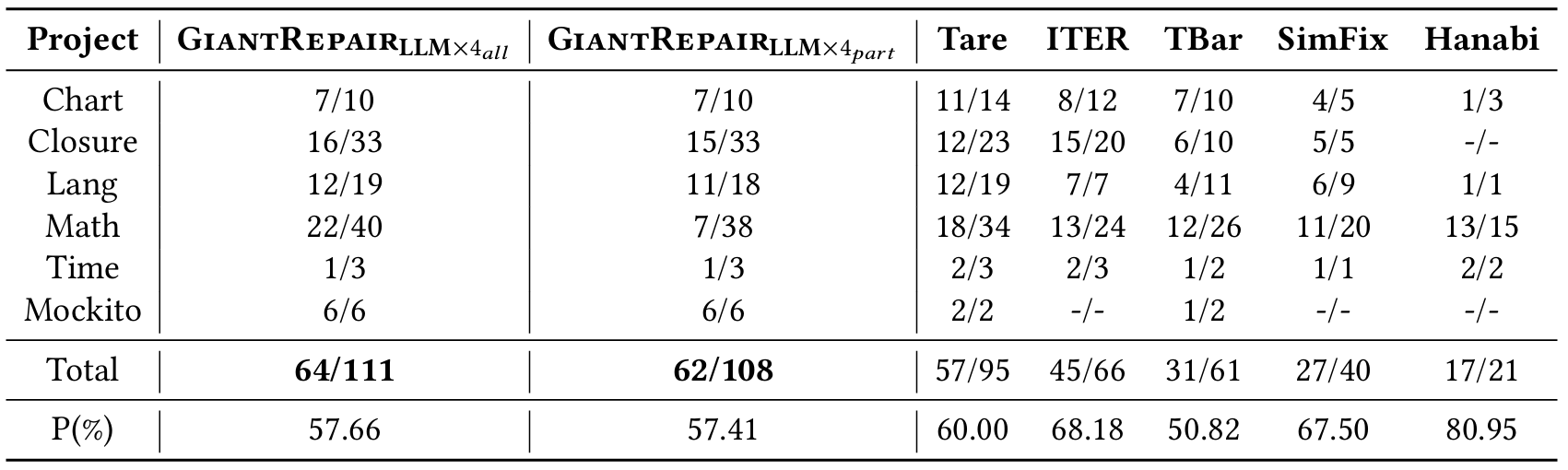
(注:“X/Y” 表示正确补丁数为 X,可信补丁数为 Y)
从结果可得出,在非完美故障定位场景下,GiantRepair 的修复性能仍优于性能最佳的 APR 工具。具体而言,GiantRepair 成功修复了 64 个漏洞,这一数量甚至接近部分基于 LLM 的 APR 工具在 “完美故障定位” 下的修复数量(如 Repilot、AlphaRepair)。部分原因在于,GiantRepair 依赖粗粒度的 “函数级故障定位”—— 这种定位方式比 “行级故障定位” 更易实现。然而,结果也表明,由于测试用例不充分,LLM 强大的代码生成能力可能会增加生成错误补丁(即补丁精度低)的风险。
5.3 RQ3:GiantRepair 各组件的贡献度
本节通过实验分析 GiantRepair 中各组件的贡献度。如 4.1 节所述,构建了 GiantRepair 的多个变体,进行系统性消融实验:
- GIANTREPAIR_w/o-context:将 GiantRepair 中的 “上下文感知型补丁实例化” 替换为随机方法。为更贴近实际场景,并非从整个项目中随机选择代码元素填充框架,而是从当前位置的所有可访问代码元素中随机选择,但不考虑框架中的类型约束。
- GIANTREPAIR_w/o-adaptive:从 LLM 补丁中随机选择修改,而非优先选择粗粒度修改。
- GiantRepair_w/o-rank:按生成顺序评估生成的补丁,而非按与原始漏洞代码的相似度排序。
实验中,选择 GPT-3.5(闭源 LLM)和 StarCoder(开源模型,在表 2 中表现最佳)作为代表性 LLM;为节省时间,消融实验在 Defects4J v1.2(包含 255 个单函数漏洞)上进行。表 6 展示了原始 GiantRepair(使用 GPT-3.5 时记为 “GiantRepair_GPT-3.5”,使用 StarCoder 时记为 “GiantRepair_StarCoder”)及其上述变体的实验结果。
表 6:GiantRepair 各组件的贡献度
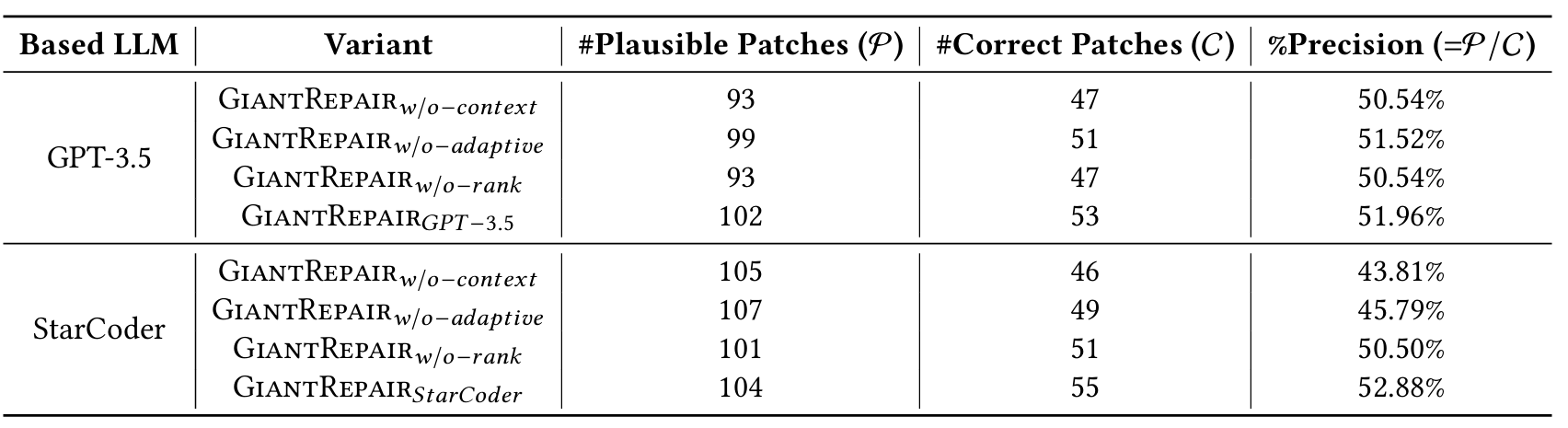
根据实验结果可观察到:(1)GiantRepair 中的每个组件都对整体有效性有显著贡献。结果显示,移除任何一个组件都会导致可信补丁与正确补丁的数量减少。具体而言,“上下文感知型补丁实例化”、“修改的自适应应用”、“补丁排序” 这三个组件,分别为 StarCoder 多贡献了 9 个、6 个、4 个正确修复,为 GPT-3.5 多贡献了 6 个、2 个、6 个正确修复。(2)“上下文感知型补丁实例化” 是 GiantRepair 中最有效的组件。实验发现,在补丁实例化过程中考虑上下文约束,能显著提升 GiantRepair 的修复能力 —— 这再次证明,通过结合静态分析进行补丁生成,可有效提升 LLM 的修复能力。
最后,为探索框架构建中各抽象规则对修复过程的贡献,分析了所有正确补丁中各规则的使用频率,结果如图 6 所示(注:一个修复可能涉及多个相同或不同规则,例如抽象 if 语句时,可能还需要抽象其条件中的中缀表达式)。图中 X 轴代表规则对应的 AST 节点类型。从图中可看出,大多数规则都对最终正确补丁有贡献;其中,除 SimpleName 外,MethodInvocation(方法调用)、InfixExpression(中缀表达式)、IfStatement(if 语句)是最常使用的规则 —— 这与现有研究结论 一致。此外,借助补丁框架,GiantRepair 能够修复需要复杂修改的漏洞(如新增完整的 for 语句)。综上,所有组件对 GiantRepair 的整体性能都至关重要,且其中的抽象规则效果最佳。
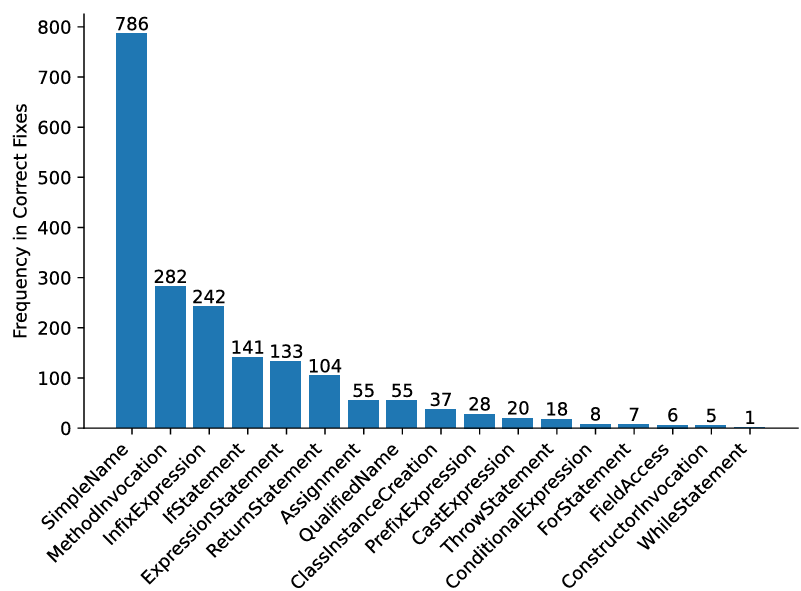
图 6 GiantRepair正确补丁中使用的规则
6 讨论
6.1 与 24 种现有 APR 工具的独特修复能力对比
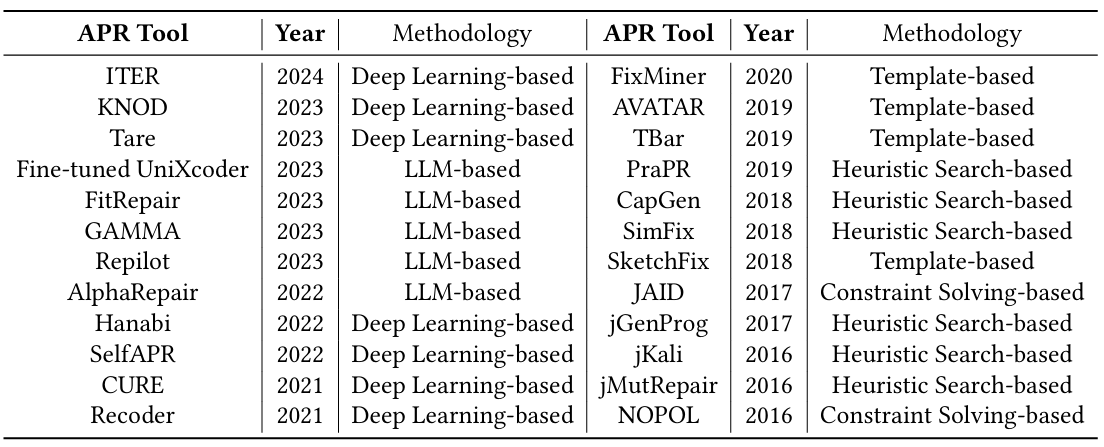
为验证本文方法能否显著推动 APR 研究、修复独特漏洞,本节将 GiantRepair 与 24 种不同 APR 工具进行对比。具体而言,除 4.3 节介绍的 11 种 APR 工具外,其余 13 种工具包括:1 种基于 LLM 的方法(Fine-tuned UniXcoder)、2 种基于深度学习的方法(KNOD、SelfAPR)、5 种基于启发式搜索的方法(PraPR、CapGen、jGenProg、jKali、jMutRepair)、3 种基于模板的方法(FixMiner、AVATAR、SketchFix)以及 2 种基于约束求解的方法(JAID、NOPOL)。这些基准方法涵盖了近年来 APR 工具中使用的大部分技术。与这些多样化的基准方法对比,可增强评估结论的可靠性。所有基准方法的详细信息如表 7 所示。
表 7:用于独特修复能力对比的 APR 工具详情
实验在 Defects4J v1.2 数据集上对比不同 APR 工具正确修复的漏洞(所有对比基准均在该数据集上进行过评估),结果如图 7 所示。从图中可看出,即便与所有 24 种基准工具相比,GiantRepair 仍能修复 20 个独特漏洞,充分体现了其有效性。
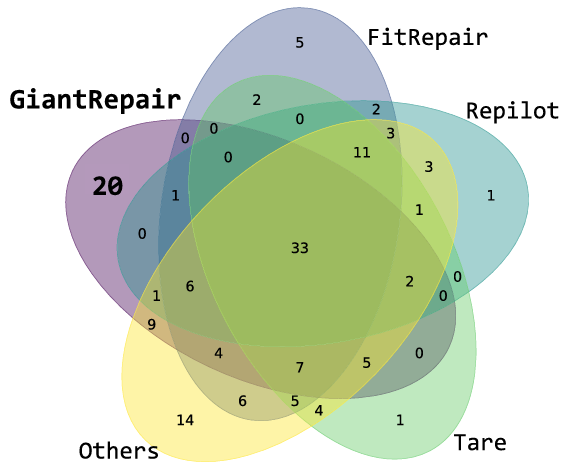
图 7 独特修复漏洞比较
6.2 GiantRepair 与 GPT-4 的对比
如 RQ1 所示,GiantRepair 比直接使用 LLM 生成的补丁能显著增加正确修复数量,包括许多独特修复。但随着时间推移,LLM 的修复能力可能会不断提升。为验证即便与最先进的 LLM 相比,GiantRepair 是否仍能修复独特漏洞,实验使用了性能更强的 LLM。考虑到成本效益,选择 GPT-4o-mini-2024-07-18—— 根据 OpenAI 的评估结果,该 LLM 在 HumanEval 数据集上得分为 87.2,编码能力可与 GPT-4、GPT-4o媲美。对于 Defects4J 数据集中的 483 个单函数漏洞,通过 API 调用 GPT-4o-mini 生成 200 个补丁,配置与提示词均与 4.4 节一致。实验结果显示,GPT-4o-mini 能修复 105 个漏洞(Defects4J v1.2 上51 个,Defects4J v2.0 上 54 个);而仅使用 StarCoder 的 GiantRepair 能修复 109 个漏洞(Defects4J v1.2 上 55 个,Defects4J v2.0 上 54 个)。进一步分析 GiantRepair 成功修复、但四个所选 LLM 均未修复的 30 个漏洞发现,GPT-4o-mini 仅能修复其中 6 个,仍有 24 个漏洞未修复。这表明,即便与最新的 LLM 相比,GiantRepair 仍具有价值。
6.3 数据泄露问题
数据泄露是基于 LLM 的 APR 工具普遍面临的问题。为探究其对实验结论的影响,首先参考现有研究的做法进行人工分析,验证补丁代码是否被用作 LLM 的训练数据。选择 StarCoder 作为代表性模型(因其是唯一公开训练数据的模型),结果显示:在 GiantRepair_StarCoder 生成的 109 个(55+54)正确补丁中,仅 23 个被包含在 StarCoder 的训练数据中。也就是说,绝大多数正确补丁(86/109)是 StarCoder 此前未接触过的,因此其有效性应源于 StarCoder 自身的能力与本文提出的补丁生成方法,而非数据泄露。
此外,为更有力地证明 GiantRepair 的有效性并避免数据泄露,还开展了两项额外实验。第一项实验采用 GrowingBugs 数据集,首先移除该数据集中包含在 StarCoder 训练数据中的项目(剩余 34/250 个项目),再移除这些项目中需要跨函数修改的漏洞(剩余 51/122 个漏洞),最终使用 StarCoder 版本的 GiantRepair 修复这些漏洞,结果成功修复了其中 10 个。第二项实验采用 HumanEval-Java 数据集,该数据集包含 163 个漏洞 —— 通过将 HumanEval 数据集 [85] 中的 Python 代码手动转换为 Java,并故意注入漏洞生成,且在时间上与所选 LLM 无重叠,可有效避免数据泄露。同样使用 StarCoder 版本的 GiantRepair 修复这些漏洞,结果成功修复了 143 个。这些结果进一步证实了本文方法的有效性,同时有效降低了数据泄露对其性能的影响风险。
6.4 局限性
首先,实验仅涉及四种 LLM(GPT-3.5-turbo、Llama-2、StarCoder、CodeLlama)与一种编程语言(Java)。尽管这已能提供有价值的见解,但仍不足以全面展现 GiantRepair 的能力 —— 理论上,GiantRepair 可利用任何生成式 LLM 生成的补丁,应用于多种编程语言。其次,GiantRepair 在时间效率方面存在局限:其补丁生成过程未计入 LLM 生成补丁所需的时间。第三,目前 GiantRepair 仅从单个 LLM 生成的补丁中抽象和实例化代码框架,但实验中发现,部分漏洞的正确修复可能分散在多个补丁中。未来可探索如何整合多个补丁中的有效修复内容,这将是有价值的研究方向。最后,尽管已有研究探索补丁搜索空间,但尚未评估 GiantRepair 与这些方法的性能对比,这也将在未来工作中解决。
6.5 有效性威胁
内部有效性威胁:人工审查所有可信补丁,以识别与参考补丁语义一致的正确补丁,这是本研究内部有效性的一大威胁。参考 APR 领域的常规做法,我们对每个可信补丁进行了细致分析,并公开了所有正确补丁与可信补丁的完整集合。另一内部有效性威胁在于,实验中使用的 LLM 可能以 GitHub 上的开源代码为训练数据,这可能与 Defects4J 数据集存在重叠。为解决这一问题,已在 6.3 节进行了详细讨论,并通过新数据集验证了 GiantRepair 的有效性。
外部有效性威胁:主要外部有效性威胁来自评估所用数据集,GiantRepair 的性能可能无法推广到其他数据集。为缓解这一问题,实验采用了 Defects4J v1.2、Defects4J v2.0 两个不同数据集评估 GiantRepair,结果证实其仍能有效实现最先进性能。未来计划在更多跨编程语言的数据集上评估 GiantRepair,以进一步解决这一威胁。
7 相关工作
略
8 结论
本文提出了一种新型 APR 方法 ——GiantRepair。具体而言,GiantRepair 利用 LLM 生成的补丁构建补丁框架并限定补丁搜索空间,随后通过上下文感知的框架实例化过程,生成适配特定程序的高质量补丁。为评估 GiantRepair 的有效性,开展了两项大规模实验,结果表明:该方法不仅比单纯使用 LLM 能显著提升正确修复数量,还优于最新的最先进 APR 工具。
启发
该方法会识别错误修复与源代码之间的修改,并每个识别出的修改会被抽象为补丁框架用于最终的修复,这种方法似乎可以用于复杂错误或多错误的情况,这种抽象方法或许可以用在学生对代码的每一步的修复中。
BibTex
@article{10.1145/3715004,
author = {Li, Fengjie and Jiang, Jiajun and Sun, Jiajun and Zhang, Hongyu},
title = {Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis},
year = {2025},
issue_date = {September 2025},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {34},
number = {7},
issn = {1049-331X},
url = {https://doi.org/10.1145/3715004},
doi = {10.1145/3715004},
journal = {ACM Trans. Softw. Eng. Methodol.},
month = aug,
articleno = {202},
numpages = {28},
keywords = {Program Repair, Large Language Model, Program Synthesis}
}
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)