深度解析:LoRA微调 vs 大模型蒸馏 —— 谁才是你的LLM加速神器?
🚀 深度解析:LoRA微调 vs 大模型蒸馏 —— 谁才是你的LLM加速神器?
摘要:在LLM(大语言模型)落地的过程中,“资源”与“效果”的平衡永远是核心痛点。面对庞大的基座模型,我们通常有两种优化路径:一种是让大模型“专精”于某项任务(LoRA微调),另一种是把大模型的能力“压缩”到小模型中(模型蒸馏)。
本文将从原理、架构、优缺点及应用场景全方位对比这两大技术,助你在实际项目中做出最正确的选择。
📖 一、背景:为什么我们需要它们?
由GPT-4、Llama 3等引领的基座模型虽然强大,但在实际应用中面临两个问题:
- 通用性 vs. 专业性:基座模型是通才,但在垂直领域(如医疗、法律、公司内部知识库)表现不够精准。
- 部署成本:动辄几十B(百亿)参数的模型,推理延迟高、显存占用大,难以在边缘设备或实时业务中落地。
LoRA 和 蒸馏 正是为了解决上述问题而诞生的两把“利剑”。
🛠️ 二、LoRA (Low-Rank Adaptation) —— 极低成本的“外挂”
1. 核心概念
LoRA(低秩自适应)并不是去改变大模型原本庞大的参数权重,而是假设模型在适应新任务时,其参数的变化量是“低秩”的。
简单来说,LoRA 冻结 了预训练模型的权重,只在模型的每一层旁边加了两个非常小的矩阵 AAA 和 BBB 来模拟参数的变化。
2. 核心公式
假设预训练权重为 W0W_0W0,微调后的权重为 WWW,则:
W=W0+ΔW=W0+B×A W = W_0 + \Delta W = W_0 + B \times A W=W0+ΔW=W0+B×A
- W0∈Rd×kW_0 \in \mathbb{R}^{d \times k}W0∈Rd×k:冻结不动。
- B∈Rd×r,A∈Rr×kB \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}B∈Rd×r,A∈Rr×k:这是我们需要训练的参数。
- rrr:秩(Rank),通常 r≪dr \ll dr≪d(例如 r=8r=8r=8 或 161616),这使得训练参数量减少了几千倍。
3. LoRA 架构图
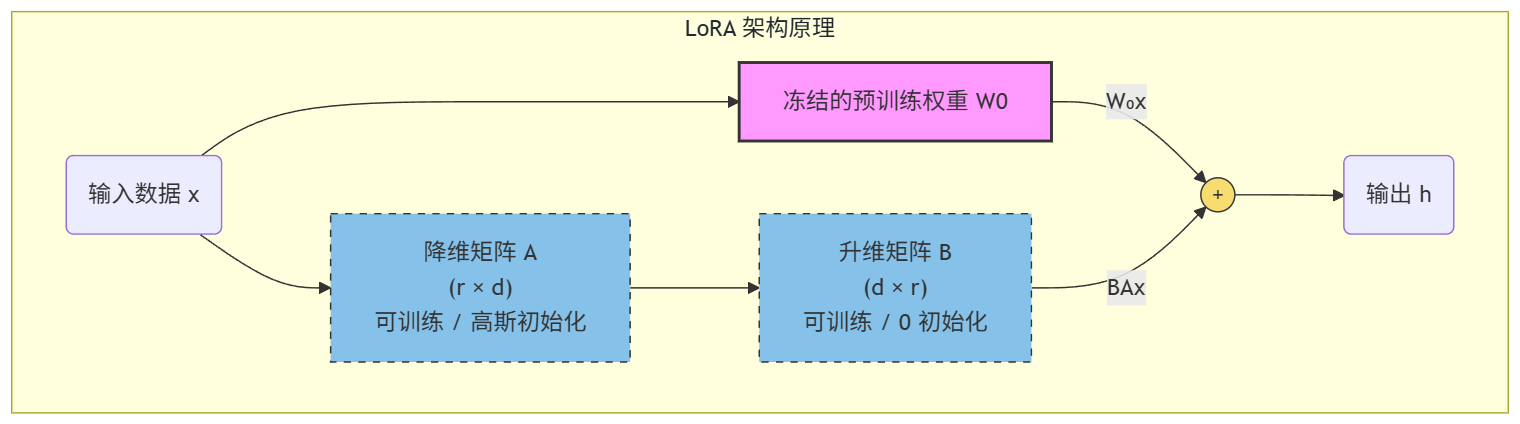
4. LoRA 的特点
- 训练显存极低:甚至可以在消费级显卡(如RTX 4090)上微调7B/13B模型。
- 不破坏基座能力:因为原权重冻结,不会出现“灾难性遗忘”。
- 推理无额外延迟:推理时,可以将 B×AB \times AB×A 的结果加回 W0W_0W0 中(Weight Merging),模型结构不变。
- 灵活切换:针对不同任务训练不同的LoRA包,运行时动态挂载即可。
🧪 三、模型蒸馏 (Knowledge Distillation) —— 师徒传承
1. 核心概念
知识蒸馏(KD)是一种模型压缩技术。它的核心思想是:让一个轻量级的“学生模型”(Student),去模仿一个强大的“老师模型”(Teacher)的行为。
老师模型不仅仅告诉学生“正确答案是什么”(Hard Label),还通过输出概率分布告诉学生“其他答案像不像”(Soft Label/Logits),这就是所谓的“暗知识”(Dark Knowledge)。
2. 核心机制
蒸馏的损失函数通常由两部分组成:
Loss=α×Lsoft(T,S)+(1−α)×Lhard(GT,S) Loss = \alpha \times L_{soft}(T, S) + (1-\alpha) \times L_{hard}(GT, S) Loss=α×Lsoft(T,S)+(1−α)×Lhard(GT,S)
- TTT: 老师模型的输出(Logits / 温度缩放后的概率)。
- SSS: 学生模型的输出。
- GTGTGT: 真实标签(Ground Truth)。
- LsoftL_{soft}Lsoft: 学习老师的思考方式(通常用KL散度)。
- LhardL_{hard}Lhard: 学习标准答案(通常用交叉熵)。
3. 蒸馏架构图
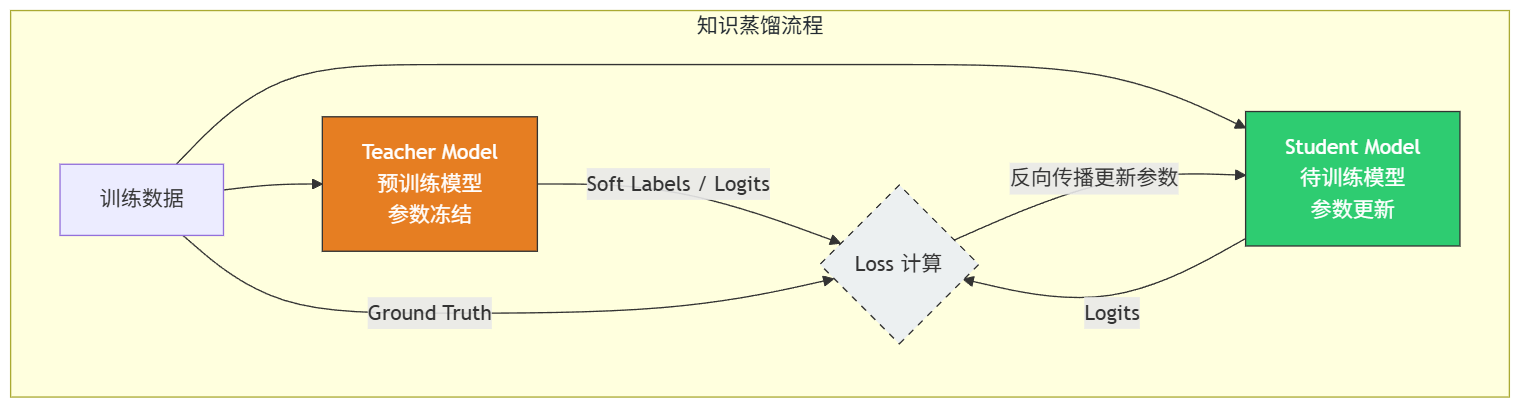
4. 蒸馏的分类(在大模型时代)
- 白盒蒸馏:能拿到老师模型的权重和Logits(如本地部署的Llama-70B蒸馏给TinyLlama)。
- 黑盒蒸馏:只能拿到老师的生成结果(如利用GPT-4生成的SFT数据去微调一个小模型)。目前这是最主流的“蒸馏”方式。
⚔️ 四、深度对比:LoRA vs 蒸馏
为了方便大家决策,我整理了以下详细对比表:
| 维度 | LoRA 微调 | 模型蒸馏 (Distillation) |
|---|---|---|
| 核心目标 | 适配:让模型学会特定领域的知识或风格。 | 压缩:在保持性能的前提下减小模型体积,提升速度。 |
| 模型尺寸 | 保持不变(推理时参数量 = 基座模型)。 | 变小:学生模型通常远小于老师模型。 |
| 推理速度 | 无变化(除非使用量化)。 | 显著提升(小模型推理本来就快)。 |
| 训练成本 | ⭐ 低:仅训练极少量参数,单卡可跑。 | ⭐⭐⭐ 高:通常需要重新训练整个学生模型。 |
| 对基座的要求 | 需要一个较好的基座模型进行微调。 | 需要一个超强的老师模型和一个待训练的学生结构。 |
| 知识来源 | 来源于标注好的数据集(SFT数据)。 | 来源于老师模型的预测分布 + 原始数据。 |
| 适用场景 | 垂直领域问答、角色扮演、风格迁移。 | 移动端部署、实时性要求高、降本增效。 |
📸 五、图解:一目了然的区别
为了更直观地理解,我们可以把基座模型比作一本厚厚的百科全书。
1. LoRA 是“贴便利贴”
- 我们不想重写百科全书(太累)。
- 我们在某些页面贴上便利贴(LoRA权重),上面写着最新的修正或特定领域的笔记。
- 结果:书还是一样厚,但读的时候结合便利贴,能处理特定问题了。
2. 蒸馏是“编写简明读本”
- 有一位读懂了全书的教授(Teacher)。
- 教授指导学生写一本《精华版口袋书》(Student)。
- 结果:书变薄了,随身携带方便(推理快),虽然丢失了一些冷门细节,但核心考点都掌握了。
🎯 六、选型建议:我该怎么选?
🟢 选 LoRA 的情况:
- 算力有限:手里只有几张消费级显卡,买不起A100/H100集群。
- 追求效果上限:你拥有一个很强的基座(如Llama-3-70B),希望它在法律领域表现更好,而不是让它变小。
- 多任务切换:同一个基座模型,早上跑客服业务(挂载LoRA A),下午跑代码助手(挂载LoRA B)。
🔵 选 蒸馏 的情况:
- 极端追求推理速度:业务需要毫秒级响应(如输入法联想、实时语音对话)。
- 端侧部署:需要在手机、车载芯片、机器人等算力受限设备上运行。
- 降低推理成本:每天调用量上亿次,使用70B模型成本太高,必须压缩到7B或1.5B以内。
💡 七、Pro Tip:成年人不做选择,我全都要!
在最前沿的实践中,LoRA 与 蒸馏 往往是结合使用的:
- 先微调再蒸馏:先用 LoRA 把一个大模型(Teacher)微调成某个领域的专家,然后再把这个专家的能力蒸馏给一个小模型(Student)。
- QLoRA:结合量化技术和LoRA,进一步降低显存门槛。
示例架构:
GPT-4 (生成数据)->Llama-3-70B (LoRA微调为领域专家)->蒸馏 (Distillation)->Qwen-1.5B (端侧部署)
📝 总结
- LoRA 是低成本的技能点加成,解决的是“懂不懂”的问题。
- 蒸馏 是高性能的瘦身计划,解决的是“快不快”和“贵不贵”的问题。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)